







 文章探讨了Transformer模型在某些情况下优于卷积神经网络(ConvNet)的原因,并提出通过改进ResNet结构,创建名为ConvNeXt的模型,旨在达到比两者更好的性能。实验中,作者详细介绍了ConvNeXt的Block设计和不同版本的网络配置,如T/S/B/L版本,其计算复杂度与SwinTransformer的对应版本相当。
文章探讨了Transformer模型在某些情况下优于卷积神经网络(ConvNet)的原因,并提出通过改进ResNet结构,创建名为ConvNeXt的模型,旨在达到比两者更好的性能。实验中,作者详细介绍了ConvNeXt的Block设计和不同版本的网络配置,如T/S/B/L版本,其计算复杂度与SwinTransformer的对应版本相当。
目录
仅是个人笔记,代码学习资源来源B站博主霹雳吧啦Wz的个人空间_哔哩哔哩_bilibili
一、 理论知识
论文作者认为可能各种新的架构以及优化策略促使Transformer模型比Conv的效果更好
使用相同的策略去训练卷积神经网络也能达到相同的效果吗?
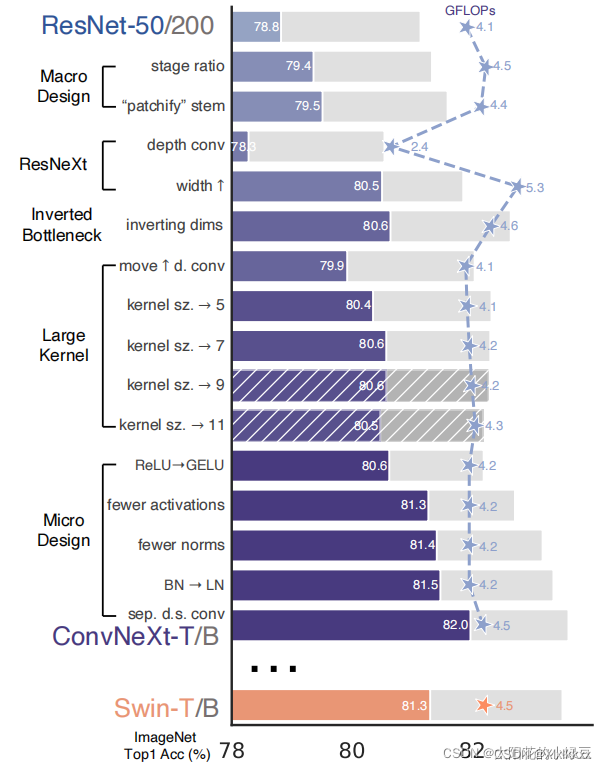
相当于参考Swin-Transformer,改进resnet结构,最终达到比两者都好的效果。
做的实验,一步步改进如下:
1. Block及网络模型
ConvNeXt-T 结构图
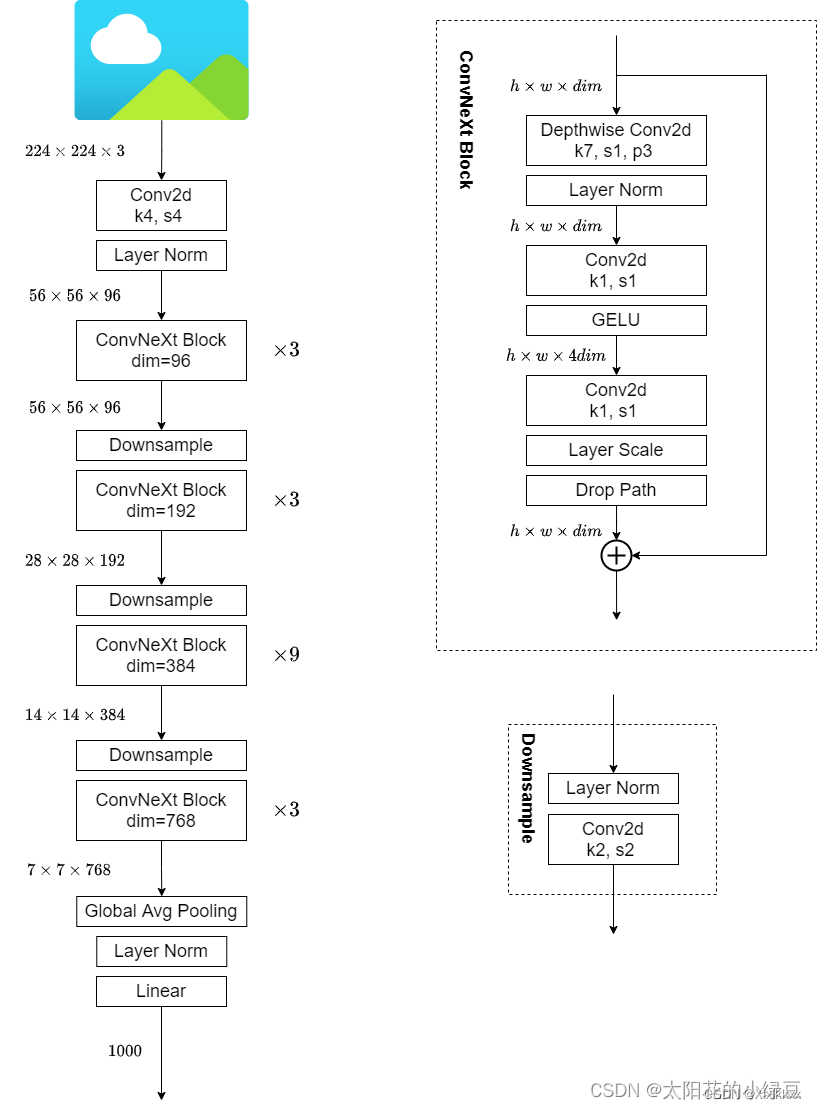
2. 参数配置
ConvNeXt网络有T/S/B/L四个版本,计算复杂度刚好和Swin Transformer中的T/S/B/L相似。
ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
其中C代表4个stage中输入的通道数,B代表每个stage重复堆叠block的次数

















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









