







凸优化
Theory I: Fundamentals
1. Introduction
首先,一个凸优化问题具有以下基本形式:
min
x
∈
D
f
(
x
)
\min_{{x \in D}} f(x)
x∈Dminf(x)约束条件为:
g
i
(
x
)
≤
0
,
i
=
1
,
2
,
…
,
m
g_i(x) \leq 0, \quad i = 1, 2, \dots, m
gi(x)≤0,i=1,2,…,m
h
j
(
x
)
=
0
,
j
=
1
,
2
,
…
,
r
h_j(x) = 0, \quad j = 1, 2, \dots, r
hj(x)=0,j=1,2,…,r
其中,
f
f
f 和
g
i
g_i
gi 都是凸函数的,且
h
j
h_j
hj是仿射变换。
凸优化问题有一个良好的性质:对于一个凸优化问题来说,任何局部最小值都是全局最小值。凸优化问题是优化问题中被研究得比较成熟的,也是非凸优化的基础,许多非凸优化问题也被局部拟为凸优化问题求解。
2.Convexity I: Sets and functions
1. 凸集
定义:一个集合 $C \subseteq \mathbb{R}^n $是凸集,如果对任意 $ x, y \in C $ 都有
t
x
+
(
1
−
t
)
y
∈
C
,
其中
0
≤
t
≤
1
t x + (1 - t) y \in C, \quad \text{ 其中 } 0 \leq t \leq 1
tx+(1−t)y∈C, 其中 0≤t≤1
任何凸集的线性组合仍然是凸集,所有凸集的集合称为凸包。空集、点、线、球体(如范数球体
{
x
:
∥
x
∥
≤
r
}
\{x : \|x\| \leq r\}
{x:∥x∥≤r})、超平面、半空间、仿射空间、多面体等都是凸集。
图中左边的多边形表示的是一个凸集,因为它满足上述条件,即两点之间的线段都在这个集合内;而右边的形状不是凸集,因为连接某些点的线段部分不在这个集合内。
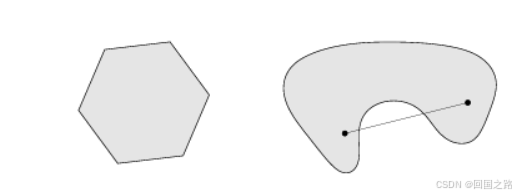
2. 凸锥
一个集合 C ⊆ R n C \subseteq \mathbb{R}^n C⊆Rn 被称为锥, 且当且仅当对于集合中的任意点 x ∈ C x \in C x∈C, 乘以一个非负标量 t ≥ 0 t \geq 0 t≥0 后的点 t x tx tx 仍然属于集合 C C C。
x ∈ C ⟹ t ⋅ x ∈ C for all t ≥ 0 x \in C \implies t \cdot x \in C \quad \text{for all} \quad t \geq 0 x∈C⟹t⋅x∈Cfor allt≥0
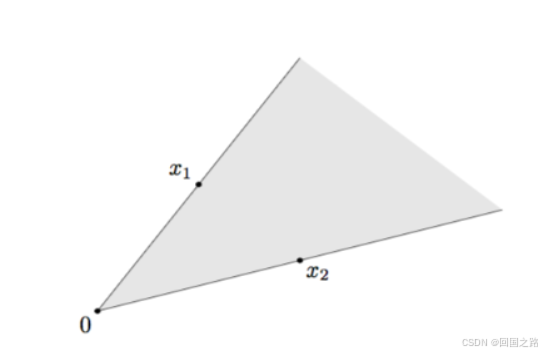
一个凸锥是既是锥又是凸集的集合。也就是说,对于集合中的任意两个点,任意非负权重的线性组合仍然位于集合内:
x
1
,
x
2
∈
C
⟹
t
1
x
1
+
t
2
x
2
∈
C
for all
t
1
,
t
2
≥
0
x_1, x_2 \in C \implies t_1 x_1 + t_2 x_2 \in C \quad \text{for all} \quad t_1, t_2 \geq 0
x1,x2∈C⟹t1x1+t2x2∈Cfor allt1,t2≥0
凸锥的实例如下图:
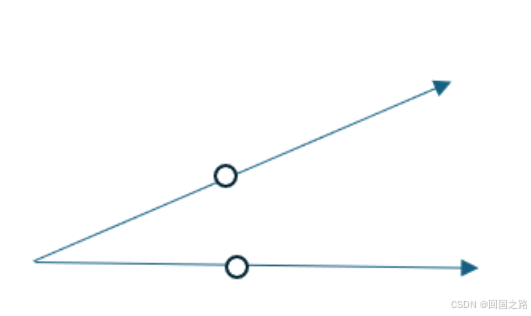
但是,是否可以举一个例子,使得集合
C
C
C为锥,但不是凸锥呢?如下图,如果两条直线组成的锥,分别从直线上选两点,则亮点的线性组合不一定在这两条直线上。
3. 凸锥的性质
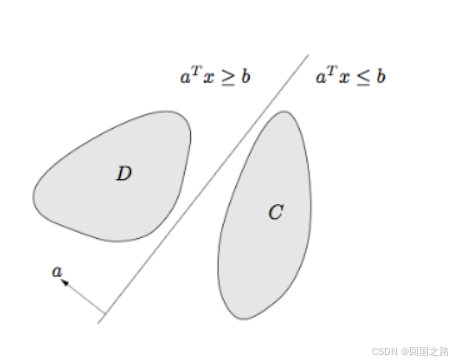
(1)Separating hyperplane理论:两个不相交的凸集之间必然存在一个分割超平面,使得两个凸集可以分开。即如果 C C C 和 D D D 都是非空凸集,且 C ∩ D = ∅ C \cap D = \varnothing C∩D=∅,则必然存在 a , b a, b a,b 使得
C ⊆ { x : a T x ≤ b } 和 D ⊆ { x : a T x ≥ b } . C \subseteq \{x : a^T x \leq b\} \quad \text{和} \quad D \subseteq \{x : a^T x \geq b\}. C⊆{x:aTx≤b}和D⊆{x:aTx≥b}.
如下图:
(2) Supporting hyperplane 理论: 凸集边界上的一点必然存在一个支撑超平面穿过该点,即如果 C C C 都是非空凸集, x 0 ∈ b d ( C ) x_0 \in bd(C) x0∈bd(C),那么必然存在一个超平面 a a a,使得 C ⊆ { x : a T x ≤ a T x 0 } C \subseteq \{ x : a^T x \leq a^T x_0 \} C⊆{x:aTx≤aTx0},如下图:
4.Preserving Convexity
(1)交集(Intersection):凸集的交集仍然是凸集
(2)对凸集进行缩放和平移后,结果仍然是凸的。即如果
C
C
C是凸集,那么对于
∀
a
,
b
\forall a, b
∀a,b,
a
C
+
b
=
{
a
x
+
b
:
x
∈
C
}
aC + b = \{ ax + b : x \in C \}
aC+b={ax+b:x∈C}
(3)仿射变换后的集合仍然是凸的。即如果
f
(
x
)
=
A
x
+
b
f(x) = Ax + b
f(x)=Ax+b 且
C
C
C 是凸集,那么:
f
(
C
)
=
{
f
(
x
)
:
x
∈
C
}
f(C) = \{ f(x) : x \in C \}
f(C)={f(x):x∈C}
(4)凸集的仿射逆映射仍然是凸集。如果
D
D
D 是凸集且
f
(
x
)
=
A
x
+
b
f(x) = Ax + b
f(x)=Ax+b,那么:
f
−
1
(
D
)
=
{
x
:
f
(
x
)
∈
D
}
f^{-1}(D) = \{ x : f(x) \in D \}
f−1(D)={x:f(x)∈D}
5.凸函数
定义: 假设函数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R,其定义域 (domain) $ \text{dom}(f) \subseteq \mathbb{R}^n$ 是一个凸集,函数 f f f 被称为凸函数,如果对于所有 x , y ∈ dom ( f ) x, y \in \text{dom}(f) x,y∈dom(f) 和任意的 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1],都有:
f ( t x + ( 1 − t ) y ) ≤ t f ( x ) + ( 1 − t ) f ( y ) f(tx + (1 - t)y) \leq t f(x) + (1 - t) f(y) f(tx+(1−t)y)≤tf(x)+(1−t)f(y)
这个不等式意味着,函数图像上的任何两点之间的连线都高于函数。具体表现为下图:

与凸函数相反,凹函数(Concave Function) 满足的条件是:
f ( t x + ( 1 − t ) y ) ≥ t f ( x ) + ( 1 − t ) f ( y ) f(tx + (1 - t)y) \geq t f(x) + (1 - t) f(y) f(tx+(1−t)y)≥tf(x)+(1−t)f(y)
换句话说,凹函数的图像位于直线段的上方。这意味着,对于凹函数,连线两点之间的直线会位于曲线的下方。
严格凸函数(Strictly Convex):函数 f f f 被称为 严格凸 (strictly convex),如果对于任意 x ≠ y x \neq y x=y 和 t ∈ ( 0 , 1 ) t \in (0, 1) t∈(0,1),满足:
f ( t x + ( 1 − t ) y ) < t f ( x ) + ( 1 − t ) f ( y ) f(tx + (1 - t)y) < t f(x) + (1 - t) f(y) f(tx+(1−t)y)<tf(x)+(1−t)f(y)
强凸函数(Strongly Convex): 函数 f f f 被称为强凸 (strongly convex),如果存在一个参数 m > 0 m > 0 m>0,使得:
f ( x ) − m 2 ∥ x ∥ 2 2 f(x) - \frac{m}{2} \|x\|_2^2 f(x)−2m∥x∥22
是一个凸函数。
强凸函数相对于严格凸函数的一个更强的要求是,它的凸性至少像一个二次函数(quadratic function)一样
6.凸函数性质
1.Epigraph characterization: 一个函数 f f f 是凸函数,当且仅当它的上图表(epigraph)是凸集。
上图表(epigraph)定义为:
epi ( f ) = { ( x , t ) ∈ dom ( f ) × R : f ( x ) ≤ t } \text{epi}(f) = \{ (x, t) \in \text{dom}(f) \times \mathbb{R} : f(x) \leq t \} epi(f)={(x,t)∈dom(f)×R:f(x)≤t}
这意味着上图表是由所有点 ( x , t ) (x, t) (x,t) 组成的集合,其中 t t t 是函数值 f ( x ) f(x) f(x) 的上界。
%% [markdown]
2.Convex sublevel sets:如果函数
f
f
f 是凸函数,那么它的下水平集(sublevel set)
{
x
∈
dom
(
f
)
:
f
(
x
)
≤
t
}
\{ x \in \text{dom}(f) : f(x) \leq t \}
{x∈dom(f):f(x)≤t}也是凸的。反之则不成立。
3.First-order Characterization:如果函数 f f f 是可微的,那么函数 f f f 是凸的,当且仅当它的定义域 dom ( f ) \text{dom}(f) dom(f) 是凸的,且满足以下条件:
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) f(y) \geq f(x) + \nabla f(x)^T (y - x) f(y)≥f(x)+∇f(x)T(y−x)
对于所有
x
,
y
∈
dom
(
f
)
x, y \in \text{dom}(f)
x,y∈dom(f)。
解释:函数
f
f
f 在任意点
x
x
x 的梯度
∇
f
(
x
)
\nabla f(x)
∇f(x) 描述了该点的切线方向。凸性要求在所有点
x
x
x 和
y
y
y 之间,函数值始终大于或等于切线的值。
4.Second-order characterization: 如果函数 f f f 是二阶可微的,那么函数 f f f 是凸的,当且仅当它的定义域 dom ( f ) \text{dom}(f) dom(f) 是凸的,且满足:
∇ 2 f ( x ) ⪰ 0 \nabla^2 f(x) \succeq 0 ∇2f(x)⪰0
对于所有 x ∈ dom ( f ) x \in \text{dom}(f) x∈dom(f),其中 ∇ 2 f ( x ) \nabla^2 f(x) ∇2f(x) 表示函数 f f f 的海森矩阵 (Hessian matrix)。
5.Jensen’s inequality:如果 f f f 是凸函数,且 X X X 是定义在 dom ( f ) \text{dom}(f) dom(f) 上的随机变量,那么:
f ( E [ X ] ) ≤ E [ f ( X ) ] f(\mathbb{E}[X]) \leq \mathbb{E}[f(X)] f(E[X])≤E[f(X)]
其中 E [ X ] \mathbb{E}[X] E[X] 是随机变量 X X X 的期望值。
7.凸函数变换
当我们对一些凸函数进行特定的操作时,结果仍然是凸函数。
(1)Nonnegative linear combination:如果 f 1 , f 2 , … , f m f_1, f_2, \dots, f_m f1,f2,…,fm 是凸函数,那么它们的非负线性组合:
a 1 f 1 + a 2 f 2 + ⋯ + a m f m a_1 f_1 + a_2 f_2 + \dots + a_m f_m a1f1+a2f2+⋯+amfm
也是凸的,只要系数 a 1 , a 2 , … , a m ≥ 0 a_1, a_2, \dots, a_m \geq 0 a1,a2,…,am≥0。
(2)Pointwise maximization:如果对于每个 s ∈ S s \in S s∈S,函数 f s ( x ) f_s(x) fs(x) 是凸函数,那么定义:
f ( x ) = max s ∈ S f s ( x ) f(x) = \max_{s \in S} f_s(x) f(x)=s∈Smaxfs(x)
则 f ( x ) f(x) f(x) 也是凸的。这里,集合 S S S 可以是有限集或无限集。
(3)Partial minimization:如果 g ( x , y ) g(x, y) g(x,y) 是关于 x x x 和 y y y 的凸函数,且 C C C 是凸集,那么函数:
f ( x ) = min y ∈ C g ( x , y ) f(x) = \min_{y \in C} g(x, y) f(x)=y∈Cming(x,y)
也是凸的。
(4)Affine composition:如果函数 f f f 是凸的,那么仿射组合 g ( x ) = f ( A x + b ) g(x) = f(Ax + b) g(x)=f(Ax+b) 也是凸的。
8.Vector composition
考虑复合函数:
f ( x ) = h ( g ( x ) ) = h ( g 1 ( x ) , g 2 ( x ) , … , g k ( x ) ) f(x) = h(g(x)) = h(g_1(x), g_2(x), \dots, g_k(x)) f(x)=h(g(x))=h(g1(x),g2(x),…,gk(x))
其中:
- g : R n → R k g : \mathbb{R}^n \rightarrow \mathbb{R}^k g:Rn→Rk 是一个多元向量函数;
- h : R k → R h : \mathbb{R}^k \rightarrow \mathbb{R} h:Rk→R 是一个标量函数;
- f : R n → R f : \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R 是我们要判断凸性或凹性的目标函数。
函数的凸性或凹性条件
根据 h h h 和 g g g 的不同凸凹性质,复合函数 f f f 的凸性或凹性遵循以下规则:
-
f f f 是凸的:
- 当 h h h 是凸的且在每个变量上非递减,而且 g g g 是凸函数时,复合函数 f ( x ) f(x) f(x) 是凸的。
-
f f f 是凸的:
- 当 h h h 是凸的且在每个变量上非递增,而且 g g g 是凹函数时,复合函数 f ( x ) f(x) f(x) 也是凸的。
-
f f f 是凹的:
- 当 h h h 是凹的且在每个变量上非递减,而且 g g g 是凹函数时,复合函数 f ( x ) f(x) f(x) 是凹的。
-
f f f 是凹的:
- 当 h h h 是凹的且在每个变量上非递增,而且 g g g 是凸函数时,复合函数 f ( x ) f(x) f(x) 也是凹的。
Convexity II: Optimization basics
1.Optimization terminology
一个典型的 凸优化问题 可以写成以下形式:
min x ∈ D f ( x ) subject to g i ( x ) ≤ 0 , i = 1 , … , m , A x = b \min_{x \in D} f(x) \quad \text{subject to} \quad g_i(x) \leq 0, \quad i = 1, \dots, m, \quad Ax = b x∈Dminf(x)subject togi(x)≤0,i=1,…,m,Ax=b
其中:
- f ( x ) f(x) f(x) 是目标函数,我们希望最小化这个函数。
- g i ( x ) g_i(x) gi(x) 是不等式约束函数,要求 g i ( x ) ≤ 0 g_i(x) \leq 0 gi(x)≤0,每个 g i ( x ) g_i(x) gi(x) 都是凸的。
- A x = b Ax = b Ax=b 是等式约束。
- D D D 是优化变量 x x x 的定义域,通常是 f ( x ) f(x) f(x) 和 g i ( x ) g_i(x) gi(x) 的共同定义域。
可行解、最优解和次优解
-
Optimal: 如果 x x x 是可行点,并且 f ( x ) = f ∗ f(x) = f^* f(x)=f∗,则称 x x x 为最优解(optimal solution),也可以称为解(solution)或极小值点(minimizer)。
-
ϵ \epsilon ϵ-suboptimal: 如果 x x x 是可行点,并且 f ( x ) ≤ f ∗ + ϵ f(x) \leq f^* + \epsilon f(x)≤f∗+ϵ,则称 x x x 为 ϵ \epsilon ϵ-次优解(e-suboptimal),这里的 ϵ \epsilon ϵ 表示我们允许解比最优值略差。
-
Active constraint: 如果在某个可行点 x x x,约束 g i ( x ) = 0 g_i(x) = 0 gi(x)=0,则称该约束 g i ( x ) g_i(x) gi(x) 在点 x x x 处是“活跃的”(active)。活跃约束表明解刚好处于该约束的边界上。
凸优化问题的等价转换
凸优化问题的 最小化问题 可以等价地表示为 最大化问题。具体地:
min x f ( x ) subject to g i ( x ) ≤ 0 , A x = b \min_x f(x) \quad \text{subject to} \quad g_i(x) \leq 0, \quad Ax = b xminf(x)subject togi(x)≤0,Ax=b
可以等价地转换为:
max x − f ( x ) subject to g i ( x ) ≤ 0 , A x = b \max_x -f(x) \quad \text{subject to} \quad g_i(x) \leq 0, \quad Ax = b xmax−f(x)subject togi(x)≤0,Ax=b
2.解集(Solution Set)
凸优化问题的解集
设 X opt X_{\text{opt}} Xopt 为凸优化问题的所有解的集合,定义为:
X opt = arg min f ( x ) subject to g i ( x ) ≤ 0 , A x = b X_{\text{opt}} = \arg \min f(x) \quad \text{subject to} \quad g_i(x) \leq 0, \quad Ax = b Xopt=argminf(x)subject togi(x)≤0,Ax=b
这是问题的解集,包含了所有满足约束条件并且使目标函数 f ( x ) f(x) f(x) 达到最小值的点。
解集
X
opt
X_{\text{opt}}
Xopt是一个凸集
如果目标函数
f
f
f是严格凸的,那么解是唯一的
Examples:
(1)Lasso 问题定义:Lasso 问题是用于 稀疏线性回归 的一种优化问题。其标准形式为:
min β ∥ y − X β ∥ 2 2 subject to ∥ β ∥ 1 ≤ s \min_{\beta} \| y - X\beta \|_2^2 \quad \text{subject to} \quad \|\beta\|_1 \leq s βmin∥y−Xβ∥22subject to∥β∥1≤s
其中:
- y ∈ R n y \in \mathbb{R}^n y∈Rn 是观测向量。
- X ∈ R n × p X \in \mathbb{R}^{n \times p} X∈Rn×p 是设计矩阵或特征矩阵。
- β ∈ R p \beta \in \mathbb{R}^p β∈Rp 是回归系数向量(我们要优化的变量)。
- ∥ y − X β ∥ 2 2 \|y - X\beta\|_2^2 ∥y−Xβ∥22 是目标函数,即拟合误差的平方和。
-
∥
β
∥
1
≤
s
\|\beta\|_1 \leq s
∥β∥1≤s 是
β
\beta
β 的
ℓ
1
\ell_1
ℓ1 范数约束,这个约束鼓励稀疏解(即很多系数为零)。
(2)凸性分析
目标函数的凸性:
目标函数
∥
y
−
X
β
∥
2
2
\| y - X\beta \|_2^2
∥y−Xβ∥22 是二次函数,二次函数是凸函数。因此目标函数是 凸的。
约束的凸性:
约束
∥
β
∥
1
≤
s
\|\beta\|_1 \leq s
∥β∥1≤s 是关于
β
\beta
β 的
ℓ
1
\ell_1
ℓ1 范数约束。
ℓ
1
\ell_1
ℓ1 范数是一个凸函数,因此约束也是 凸的。
结论:
由于目标函数和约束都是凸的,因此这个 Lasso 问题是一个 凸优化问题。
(3)SVM 问题的定义:支持向量机是一个用于分类问题的优化模型,其目标是通过最大化类间的间隔来找到最优的分离超平面。SVM 的优化问题可以写作:
min β , β 0 , ξ 1 2 ∥ β ∥ 2 2 + C ∑ i = 1 n ξ i \min_{\beta, \beta_0, \xi} \frac{1}{2} \|\beta\|_2^2 + C \sum_{i=1}^{n} \xi_i β,β0,ξmin21∥β∥22+Ci=1∑nξi
其中:
- β \beta β 是分类器的权重向量。
- β 0 \beta_0 β0 是偏置(截距)。
- ξ i \xi_i ξi 是松弛变量,用于处理无法被正确分类的样本。
- C C C 是正则化参数,用于平衡分类误差和间隔的最大化。
约束条件:
-
ξ i ≥ 0 \xi_i \geq 0 ξi≥0,即松弛变量必须非负,用于衡量误分类的程度。
-
y i ( x i T β + β 0 ) ≥ 1 − ξ i y_i (x_i^T \beta + \beta_0) \geq 1 - \xi_i yi(xiTβ+β0)≥1−ξi,该约束表示每个样本的正确分类条件。对于每个样本 i i i,若它是正确分类的,则 ξ i \xi_i ξi 会很小;若被错误分类, ξ i \xi_i ξi 会增大,表示分类的误差。
3.局部最优解即是全局最优解
(1) 局部最优解 (locally optimal point):对于一个凸优化问题,如果某个可行点 x x x 是局部最优解,表示在某个范围 R > 0 R > 0 R>0 内,对于所有与 x x x 距离小于 R R R 的可行点 y y y,函数值满足:
f ( x ) ≤ f ( y ) f(x) \leq f(y) f(x)≤f(y)
换句话说,在这个局部区域内,没有其他可行点 y y y 比 x x x 的函数值更小。
凸优化和非凸优化对比:
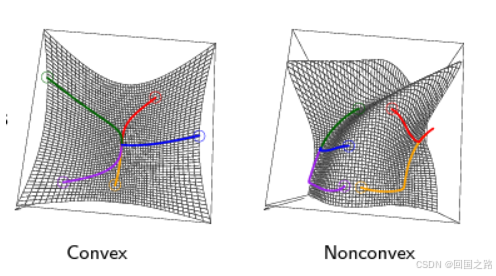
-
左图 (Convex): 展示了一个凸函数的图像。由于函数是凸的,局部最优点(图中的最低点)也是全局最优点。这表明凸优化问题只会有一个“谷底”,所有的最优点都在全局范围内成立。
-
右图 (Nonconvex): 展示了一个非凸函数的图像。非凸函数可能存在多个局部最优点,但这些局部最优点并不一定是全局最优点。在非凸问题中,可能会有多个局部低谷,而全局最优点位于其中的一个低谷中。
3.Rewriting constraints
带约束优化问题:
min x f ( x ) subject to g i ( x ) ≤ 0 , i = 1 , … , m , A x = b \min_x f(x) \quad \text{subject to} \quad g_i(x) \leq 0, \quad i = 1, \dots, m, \quad Ax = b xminf(x)subject togi(x)≤0,i=1,…,m,Ax=b
我们可以将这个问题重新表述为:
min x f ( x ) subject to x ∈ C \min_x f(x) \quad \text{subject to} \quad x \in C xminf(x)subject tox∈C
其中,可行域 C C C 被定义为:
C = { x : g i ( x ) ≤ 0 , i = 1 , … , m , A x = b } C = \{x : g_i(x) \leq 0, \quad i = 1, \dots, m, \quad Ax = b\} C={x:gi(x)≤0,i=1,…,m,Ax=b}
可以引入了**指示函数 I C ( x ) I_C(x) IC(x) **来表示集合 C C C 的约束。指示函数的定义为:
I C ( x ) = { 0 , if x ∈ C ∞ , if x ∉ C I_C(x) = \begin{cases} 0, & \text{if } x \in C \\ \infty, & \text{if } x \notin C \end{cases} IC(x)={0,∞,if x∈Cif x∈/C
这意味着:
- 如果 x x x 在可行域 C C C 内,那么指示函数 I C ( x ) = 0 I_C(x) = 0 IC(x)=0,不会对优化目标造成任何影响。
- 如果 x x x 不在可行域 C C C 内,指示函数 I C ( x ) = ∞ I_C(x) = \infty IC(x)=∞,确保该点永远不会成为最优解,因为目标函数值会非常大。
因此,我们可以将原来的优化问题进一步转换为无约束形式:
min x f ( x ) + I C ( x ) \min_x f(x) + I_C(x) xminf(x)+IC(x)
4.一阶最优条件
优化问题的目标是最小化一个可微的目标函数
f
(
x
)
f(x)
f(x),条件是解
x
x
x 必须在一个可行集合
C
C
C 内。
一个点
x
x
x 是最优解,当且仅当它满足以下条件:
∇ f ( x ) T ( y − x ) ≥ 0 对于所有 y ∈ C \nabla f(x)^T (y - x) \geq 0 \quad \text{对于所有 } y \in C ∇f(x)T(y−x)≥0对于所有 y∈C
换句话说,从当前点
x
x
x 起的所有可行方向都与梯度方向对齐。当最优化问题是无约束时,该条件简化为
∇
f
(
x
)
=
0
\nabla f(x) = 0
∇f(x)=0。
这意味着在无约束优化中,最优解处的梯度为零,也就是说,在该点上函数没有任何方向的上升或下降趋势。
Canonical problem forms
1. 线性规划 (Linear Program):
-
定义:线性规划是指目标函数和约束条件都为线性函数的优化问题。
-
形式:
min x c T x subject to D x ≤ d , A x = b \min_x c^T x \quad \text{subject to} \quad Dx \leq d, \quad Ax = b xmincTxsubject toDx≤d,Ax=b
其中,
c
c
c 是目标函数的系数向量,
D
D
D 和
A
A
A 是约束条件的系数矩阵。
Example :基追踪(Basis Pursuit)
-
问题描述:在欠定线性系统中,寻找稀疏解,即找到最少非零元素的解。
-
非凸形式:
min β ∥ β ∥ 0 subject to X β = y \min_{\beta} \|\beta\|_0 \quad \text{subject to} \quad X\beta = y βmin∥β∥0subject toXβ=y
其中 ∥ β ∥ 0 \|\beta\|_0 ∥β∥0 表示 β \beta β 向量中非零元素的个数。
ℓ 1 \ell_1 ℓ1 近似 (Basis Pursuit):由于 ℓ 0 \ell_0 ℓ0 范数是非凸的,实际问题中常使用 ℓ 1 \ell_1 ℓ1 范数来近似求解稀疏问题。
min β ∥ β ∥ 1 subject to X β = y \min_{\beta} \|\beta\|_1 \quad \text{subject to} \quad X\beta = y βmin∥β∥1subject toXβ=y
这里的 ∥ β ∥ 1 \|\beta\|_1 ∥β∥1 是 β \beta β 向量的 ℓ 1 \ell_1 ℓ1 范数,即所有元素绝对值之和。
2. 凸二次规划 (Convex Quadratic Program):
-
定义:凸二次规划是目标函数包含一个二次项,且约束条件为线性的优化问题。
-
标准形式:
min x c T x + 1 2 x T Q x subject to D x ≤ d , A x = b \min_x c^T x + \frac{1}{2} x^T Q x \quad \text{subject to} \quad Dx \leq d, \quad Ax = b xmincTx+21xTQxsubject toDx≤d,Ax=b
其中:
-
c T x c^T x cTx 是线性部分, 1 2 x T Q x \frac{1}{2} x^T Q x 21xTQx 是二次项。
-
Q Q Q 是一个半正定矩阵,保证问题是凸的。
-
D x ≤ d Dx \leq d Dx≤d 和 A x = b Ax = b Ax=b 是线性约束条件。
-
凸性:当 Q ⪰ 0 Q \succeq 0 Q⪰0(即 Q Q Q 是正半定矩阵)时,问题是凸优化问题。
Example :支持向量机(Support Vector Machines, SVM)
-
问题描述:SVM 的目标是找到一个最优的超平面来分离两个类别的数据点。
-
形式:
min β , β 0 , ξ 1 2 ∥ β ∥ 2 2 + C ∑ i = 1 n ξ i subject to ξ i ≥ 0 , y i ( β T x i + β 0 ) ≥ 1 − ξ i \min_{\beta, \beta_0, \xi} \frac{1}{2} \|\beta\|_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{subject to} \quad \xi_i \geq 0, \quad y_i(\beta^T x_i + \beta_0) \geq 1 - \xi_i β,β0,ξmin21∥β∥22+Ci=1∑nξisubject toξi≥0,yi(βTxi+β0)≥1−ξi
Example :Lasso回归
- 形式1:带约束形式:
min β ∥ y − X β ∥ 2 2 subject to ∥ β ∥ 1 ≤ s \min_{\beta} \|y - X\beta\|_2^2 \quad \text{subject to} \quad \|\beta\|_1 \leq s βmin∥y−Xβ∥22subject to∥β∥1≤s
-
s s s 是一个调节参数,控制稀疏性。
-
形式2:拉格朗日形式:
min β 1 2 ∥ y − X β ∥ 2 2 + λ ∥ β ∥ 1 \min_{\beta} \frac{1}{2} \|y - X\beta\|_2^2 + \lambda \|\beta\|_1 βmin21∥y−Xβ∥22+λ∥β∥1
- λ ≥ 0 \lambda \geq 0 λ≥0 是一个调节参数,权衡误差和稀疏性。
3.半定规划 (Semidefinite Program, SDP):
-
定义:半定规划是一类优化问题,目标是最小化线性目标函数,并且约束条件涉及矩阵的正半定性。
-
一般形式:
min x c T x subject to x 1 F 1 + x 2 F 2 + ⋯ + x n F n ⪯ F 0 , A x = b \min_x c^T x \quad \text{subject to} \quad x_1 F_1 + x_2 F_2 + \cdots + x_n F_n \preceq F_0, \quad Ax = b xmincTxsubject tox1F1+x2F2+⋯+xnFn⪯F0,Ax=b
其中:
- F j ∈ S d F_j \in S^d Fj∈Sd 表示对称矩阵,且 S d S^d Sd 是 d × d d \times d d×d 对称矩阵的空间。
- ⪯ \preceq ⪯ 表示矩阵的部分序关系,即 F 0 − ( x 1 F 1 + ⋯ + x n F n ) F_0 - (x_1 F_1 + \cdots + x_n F_n) F0−(x1F1+⋯+xnFn) 是正半定矩阵(所有特征值非负)。
- A ∈ R m × n , c ∈ R n , b ∈ R m A \in \mathbb{R}^{m \times n}, c \in \mathbb{R}^n, b \in \mathbb{R}^m A∈Rm×n,c∈Rn,b∈Rm 是线性约束和目标函数的系数矩阵和向量。
4.锥规划(Conic Programming)
5.二阶锥规划(Second-Order Cone Programming, SOCP)
QP 是二阶锥规划(SOCP)的特例

















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









