







 本文探讨了Python在数据挖掘中的数据质量分析,包括缺失值和异常值的处理,如简单统计量、3原则和箱型图分析。同时,介绍了数据特征分析,涉及分布、对比、统计量、周期性、贡献度和相关性分析,帮助理解数据并为建模做准备。
本文探讨了Python在数据挖掘中的数据质量分析,包括缺失值和异常值的处理,如简单统计量、3原则和箱型图分析。同时,介绍了数据特征分析,涉及分布、对比、统计量、周期性、贡献度和相关性分析,帮助理解数据并为建模做准备。
目录
当我们收集到数据后,接下来的问题便是对数据的质量和数量进行检查,看一看收集的数据是否满足之后的建模过程,这里我们从数据质量分析和数据特征分析数据进行探索。
一·数据质量分析
数据质量分析主要是检查我们收集到的数据是否有脏数据,所谓的脏数据就是指不符合要求或不能直接进行数据分析的数据。脏数据包括:缺失值,异常值,不一致的值,重复数据或者带有特殊符号(#,*,¥)的数据。
1.缺失值分析
数据的缺失值主要包括数据纪录的缺失或者每个信息的缺失。
缺失值的产生:1.有些数据无法获取或者获取数据的代价太大,我们不得不丢弃。2.数据被遗漏。3.属性值不存在
缺失值的影响:1.数据挖掘建模阶段将丢失大量有用的数据。2.建模后表现出来的不确定性更加显著。3.包含空值的数据会导致不可靠的输出
2.异常值分析
异常值分析是检验数据是否录入错误,是否有不合理的数据。异常值分析的方法有如下几个。
2.1 简单统计量分析
简单统计量分析就是对变量进行一个描述性的统计,然后看看数据是否在我们的认知中合理,统计量常见的有最大值和最小值。
2.2 3 原则
原则
然后数据服从正态分布,我们就可以用这个原则检查数据是否是异常值,在一个原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值
2.3 箱型图分析
箱型图判断异常值的标准一四分位数和四分位距离为基础,四分位数具有一定的鲁棒性,什么是鲁棒性呢?就是25%的数据可以变得任意远而不会严重扰动四分位数,所有异常值不能对这个标准施加影响。
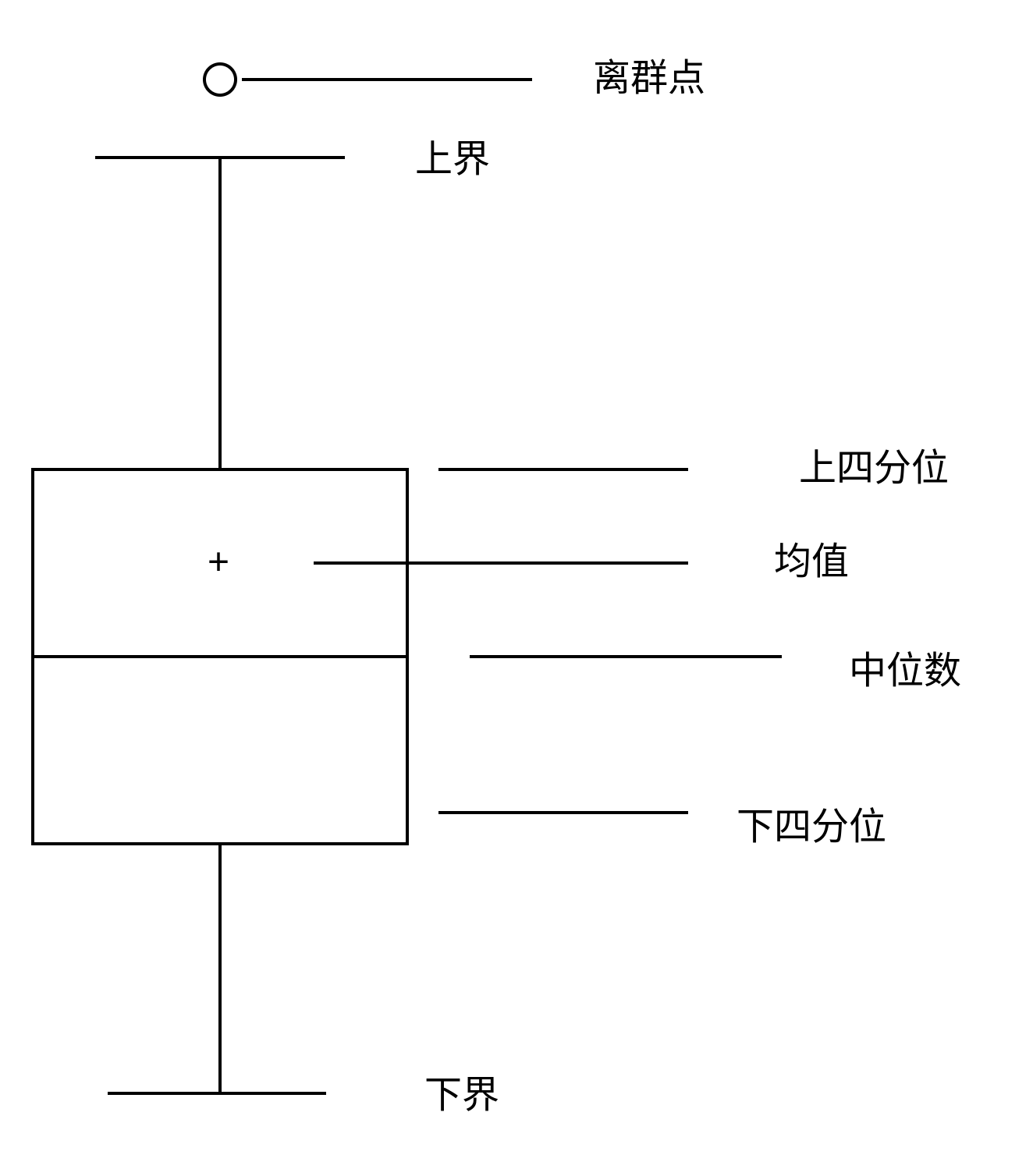
在python中读入数据后,可以用pandas库的describe()方法查看数据,例如:
import pandas as pd
catering_sale = 'catering_sale.xls'
data=pd.read_excel(catering_sale,index_col='日期')
print(data.describe())
print(len(data))
"""
销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











