




 本文详细介绍了Python中用于数据探索的关键函数,包括统计特征如均值、方差、标准差、相关系数和协方差,以及数据可视化方法如直方图、饼图、箱型图和对数图。同时,探讨了缺失值和异常值的分析方法,如3σ原则和箱型图。此外,文章还展示了如何利用Pandas和Matplotlib进行数据质量分析和特征分析,强调了数据预处理的重要性。
本文详细介绍了Python中用于数据探索的关键函数,包括统计特征如均值、方差、标准差、相关系数和协方差,以及数据可视化方法如直方图、饼图、箱型图和对数图。同时,探讨了缺失值和异常值的分析方法,如3σ原则和箱型图。此外,文章还展示了如何利用Pandas和Matplotlib进行数据质量分析和特征分析,强调了数据预处理的重要性。
文章目录
Python主要数据探索函数
统计特征函数
统计特征函数用于计算数据的均值、方差、标准差、分位数、相关系数、协方差等,这些统计特征能反映出数据的整体趋势。
sum
功能:计算数据样本的总和(按列计算)
使用格式: D.sum() 按列计算样本D的总和,样本D可为DataFrame或者Series。
mean
功能:计算数据样本的算术平均数
使用格式: D.mean() 按列计算样本D的均值,样本D可为DataFrame或者Series。
var
功能:计算数据样本的方差
使用格式: D.var() 按列计算样本D的方差,样本D可为DataFrame或者Series。
std
功能:计算数据样本的标准差
使用格式: D.std() 按列计算样本D的标准差,样本D可为DataFrame或者Series。
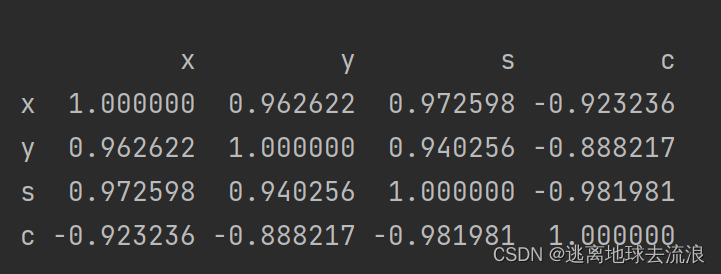
corr
功能:计算数据样本的Spearman(Pearson)相关系数矩阵
import pandas as pd
allDf = pd.DataFrame(
{'x': [0, 1, 2, 4, 7, 10], 'y': [1, 3, 2, 4, 5, 7], 's': [0, 1, 2, 3, 4, 5], 'c': [5, 4, 3, 2, 1, 1]},
index=['p1', 'p2', 'p3', 'p4', 'p5', 'p6'])
print(allDf)
print("-------\n")
corr_matrix = allDf.corr()
print(corr_matrix)
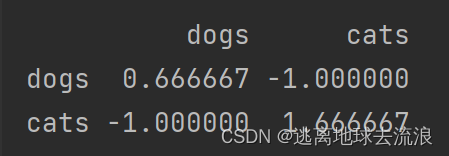
cov
功能:计算数据样本的协方差矩阵
import pandas as pd
df = pd.DataFrame([(1, 2), (0, 3), (2, 0), (1, 1)], columns=['dogs', 'cats'])
print(df)
print("------------\n")
print(df.cov())
Describe
功能:直接给出样本数据的一些基本的统计量,包括均值、标准差、最大
值、最小值、分位数等。
除了上述基本的统计特征外,Pandas还提供了另外一些非常方便实用的计算统计特征的函数,主要用累积计算(cum)和滚动计算(pd.rolling_)。
cum系列函数
是作为DataFrame或Series对象的方法而出现的,命令格式为D.cumsum()。
import pandas as pd
D = pd.Series(range(0, 20))
print(D)
print("------\n")
print(D.cumsum())
rolling_系列
是pandas的函数,不是DataFrame或Series对象的方法,使用格式为pd.rolling_mean(D, k),意思是每k列计算一次均值,滚动计算。
import pandas as pd
D = pd.Series(range(0, 20))
print(D)
print("------\n")
# 移动窗口的大小。使用数值int时,则表示观测值的数量,即向前几个数据。
print(D.rolling(2).sum())
print("------\n")
print(D.rolling(2).mean())
统计作图函数
Python的主要作图库是Matplotlib,而Pandas基于Matplotlib并对某些命令作了简化,因此作图通常是Matplotlib和Pandas相互结合着使用。
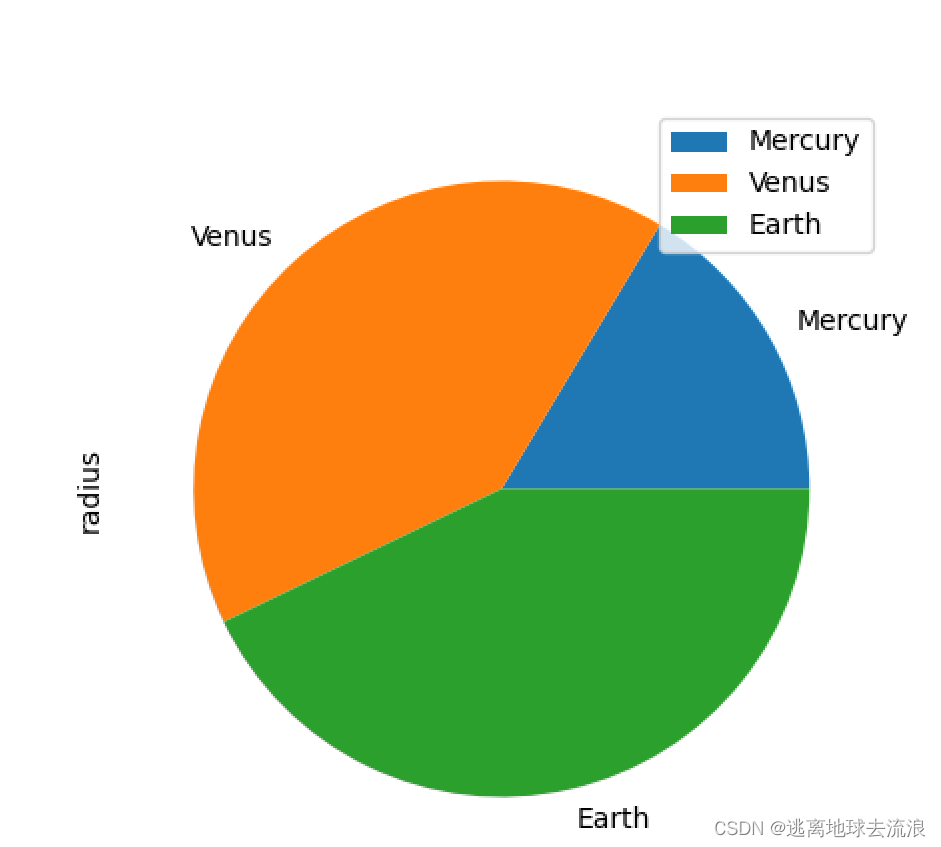
pie
功能:绘制饼型图。
使用格式:plt.pie(size) 使用Matplotlib绘制饼图,其中size是一个列表,记录各个扇形的比例。
import matplotlib.pyplot as plt
import pandas as pd
df = pd.DataFrame({'mass': [0.330, 4.87, 5.97], 'radius': [2439.7, 6051.8, 6378.1]},
index=['Mercury', 'Venus', 'Earth'])
print(df)
df.plot.pie(y='radius', figsize=(5, 5)) # 以radius为占比
plt.show()
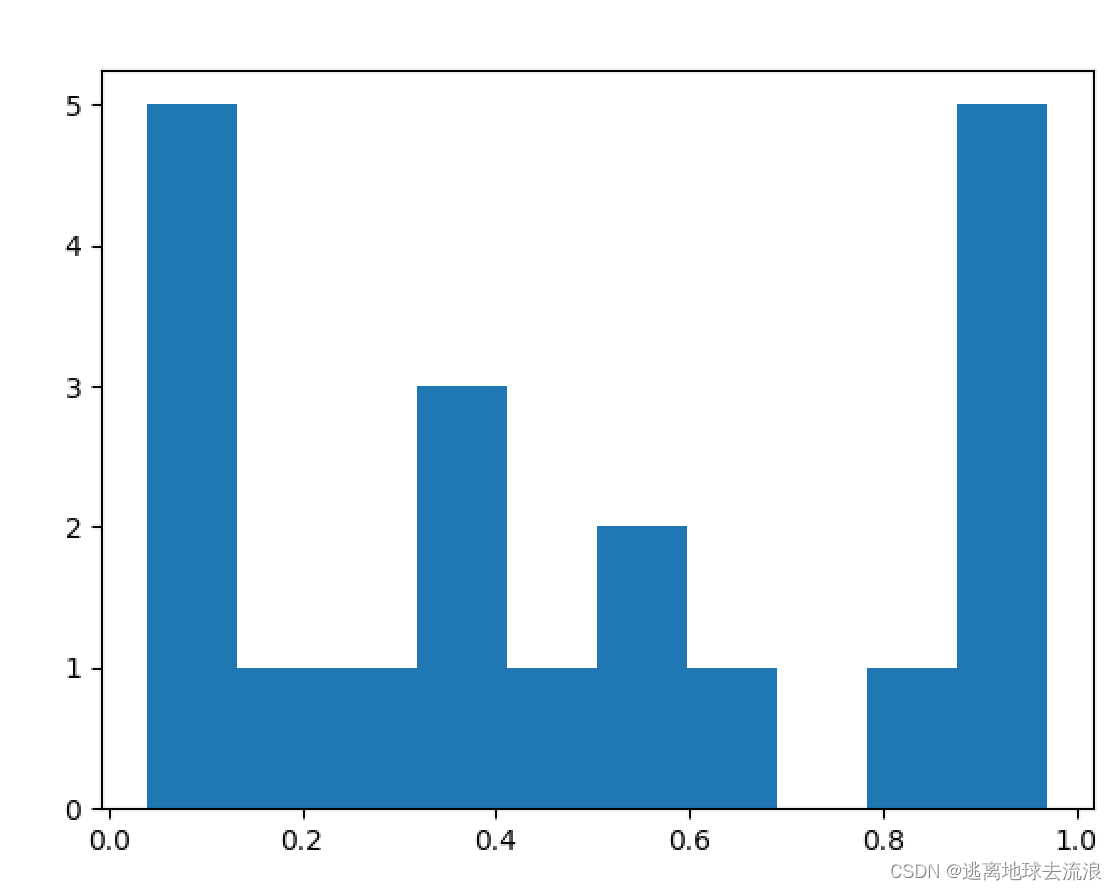
hist
功能:绘制二维条形直方图,可显示数据的分布情形。
使用格式:
Plt.hist(x, y) 其中x是待绘制直方图的一维数组,y可以是整数,表示均匀分为n组;也可以是列表,列表各个数字为分组的边界点(即手动指定分界点)。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
A = np.random.rand(20) # 随机样本取值范围是[0,1)
print(A)
plt.hist(A) # y轴是数据出现的个数
plt.show()
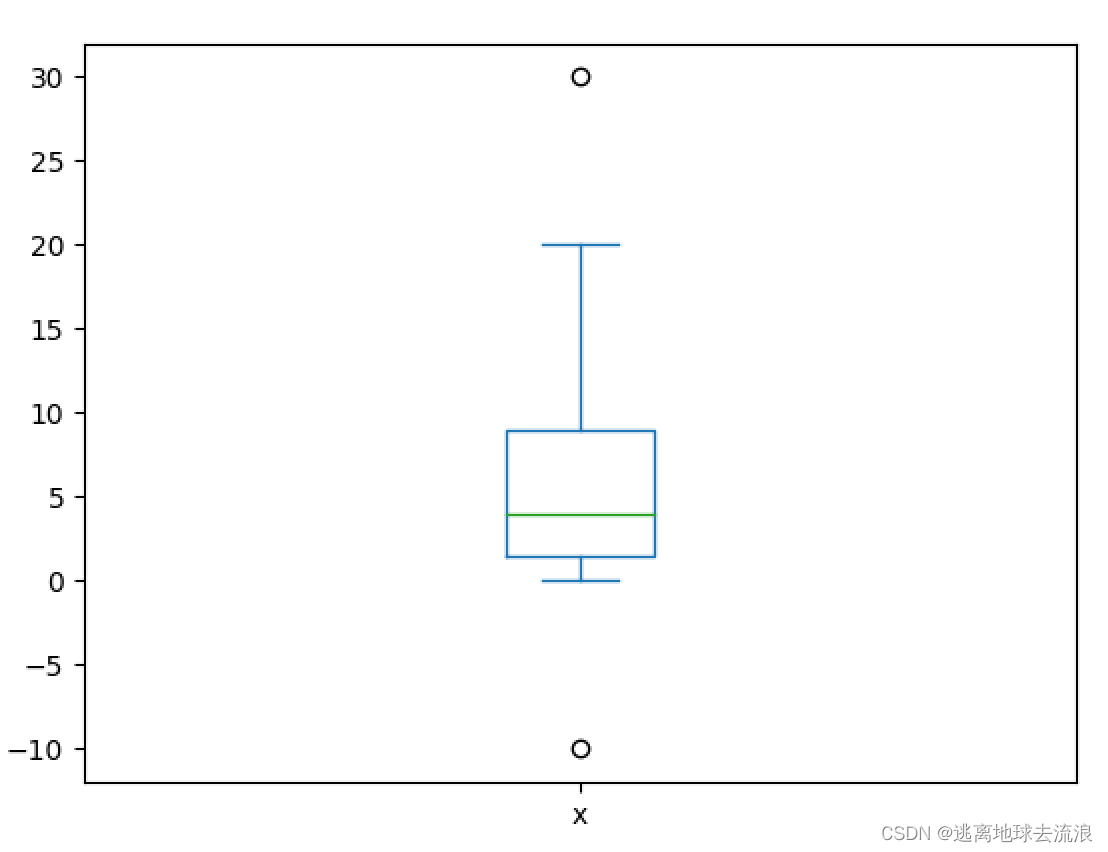
boxplot
功能:绘制样本数据的箱型图。
使用格式: D.boxplot() / D.plot(kind = ‘box’)
有两种比较简单的方式绘 制D的箱型图,其中一种是直接调用DataFrame的boxplot()方法,另外一种是调用 Series 或 者DataFrame的 plot() 方 法, 并 用kind参数指定箱型(box)。
其中,盒子的上、下四分位数和中值处有一条线段。箱形末端延伸出去的直线称为须,表示盒外数据的长度。如果在须外没有数据,则在须的底部有一点,点的颜色与须的颜色相同。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
x = [-10, 0, 1, 2, 3, 4, 6, 8, 10, 20, 30]
df = pd.DataFrame(data={'x': x})
print(df)
df.plot(kind='box')
plt.show()
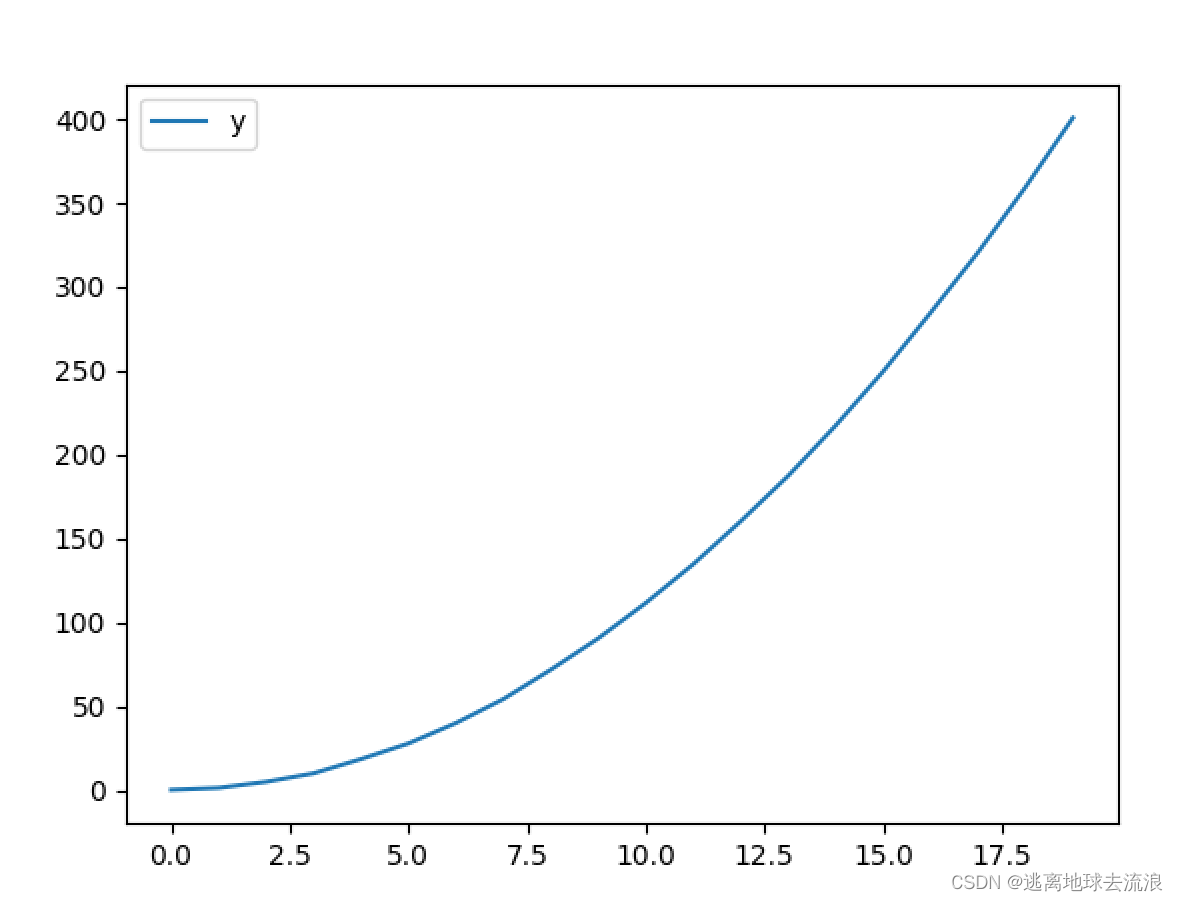
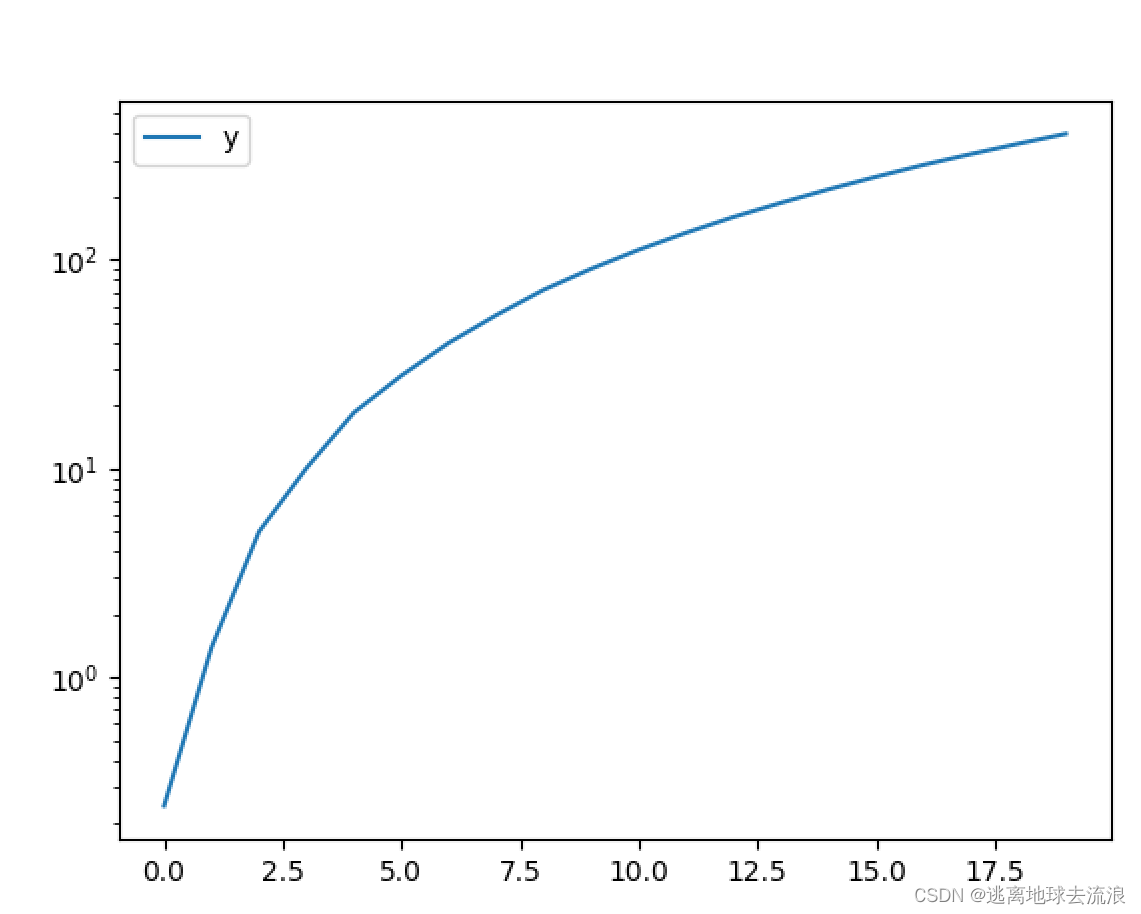
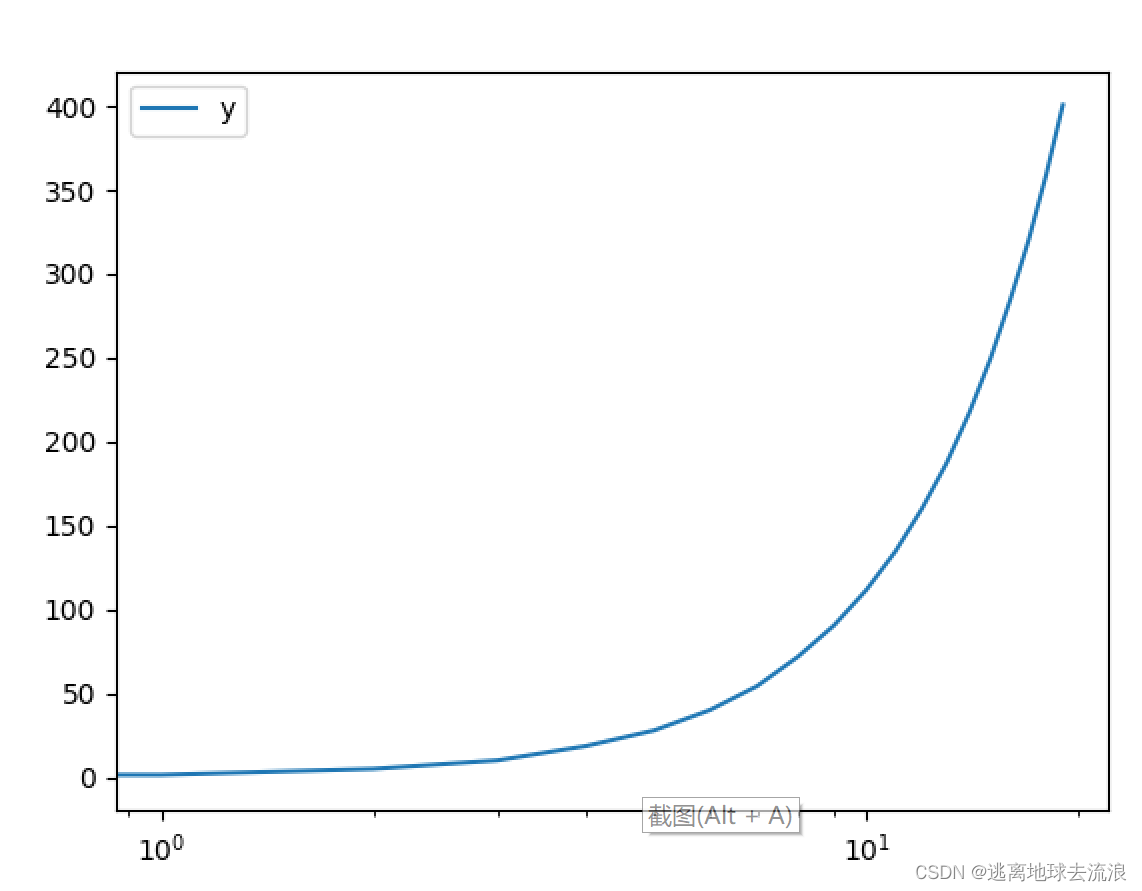
plot(logx = True) / plot(logy =True)
功能:绘制x或y轴的对数图形。
使用格式:
D.plot(logx = True) / D.plot(logy =True) 对x轴(y轴)使用对数刻度(以10为底),y轴(x轴)使用线性刻度,进行plot函数绘图,D为Pandas的DataFrame或者Series。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
x = np.linspace(0, 20, 20)
print(x)
yerr = np.random.rand(20) # 生成【0,1)的随机数
y = x ** 2 + yerr #y=x^2+c
df = pd.DataFrame(data={'y': y})
print(y)
df.plot()
df.plot(logy=True)
df.plot(logx=True)
plt.show()
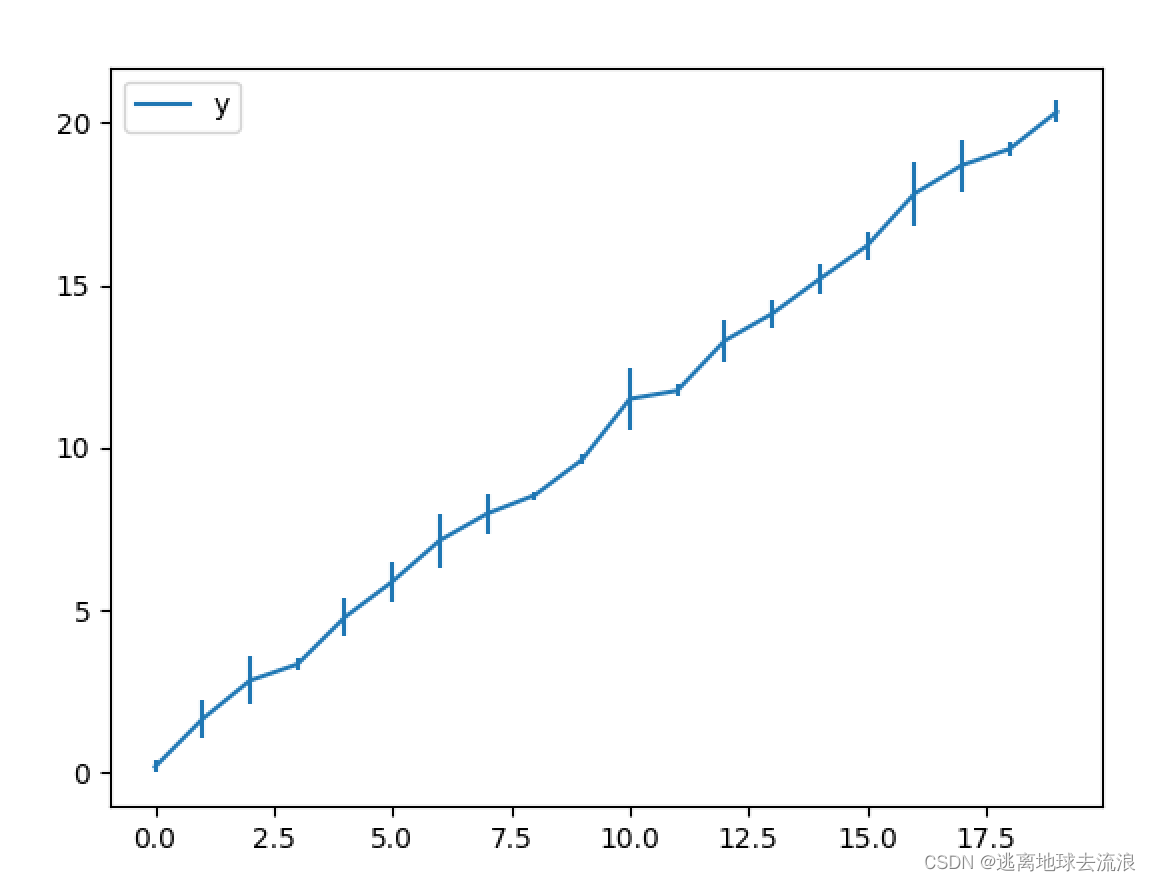
plot(yerr = error)
功能:绘制误差条形图。
使用格式:
D.plot(yerr = error)绘制误差条形图。D为Pandas的DataFrame
或Series,代表着均值数据列,而error则是误差列,此命令在y轴方向画出误差棒图;类似地,如果设置参数xerr = error,则在x轴方向画出误差棒图。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
x = np.linspace(0, 20, 20) # 创建等差数列,start,end,num
print(x)
yer = np.random.rand(20)
print(yer)
y = x + yer
print(y)
df = pd.DataFrame(data={'y': y})
df.plot(yerr=yer) #在y轴方向画出误差棒图
plt.show()
数据质量分析
数据质量分析是数据预处理的前提,是数据挖掘分析结论有效性和准确性的基础,其主要任务是检查原始数据中是否存在脏数据,脏数据一般是指不符合要求,以及不能直接进行相应分析的数据,在常见的数据挖掘工作中,脏数据包括:
• 缺失值
• 异常值
• 不一致的值
• 重复数据及含有特殊符号(如#、¥、*)的数据
缺失值
缺失值产生的原因
1、有些信息暂时无法获取,或者获取信息的代价太大。
2、有些信息是被遗漏的。可能是因为输入时认为不重要、忘记填写或对数据理解错误等一些人为因素而遗漏,也可能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障等机械原因而丢失。
3、属性值不存在。在某些情况下,缺失值并不意味着数据有错误,对一些对象来说属性值是不存在的,如一个未婚者的配偶姓名、一个儿童的固定收入状况等。
缺失值的影响
1、数据挖掘建模将丢失大量的有用信息
2、数据挖掘模型所表现出的不确定性更加显著,模型中蕴涵的确定性成分更难把握
3、包含空值的数据会使挖掘建模过程陷入混乱,导致不可靠的输出
缺失值分析
对缺失值做简单统计分析:统计缺失值的变量个数,统计每个变量的未缺失数,统计变量的缺失数及缺失率。
异常值
异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称为离群点,异常值的分析也称为离群点的分析。
异常值分析方法主要有:简单统计量分析、3 σ原则、箱型图分析。
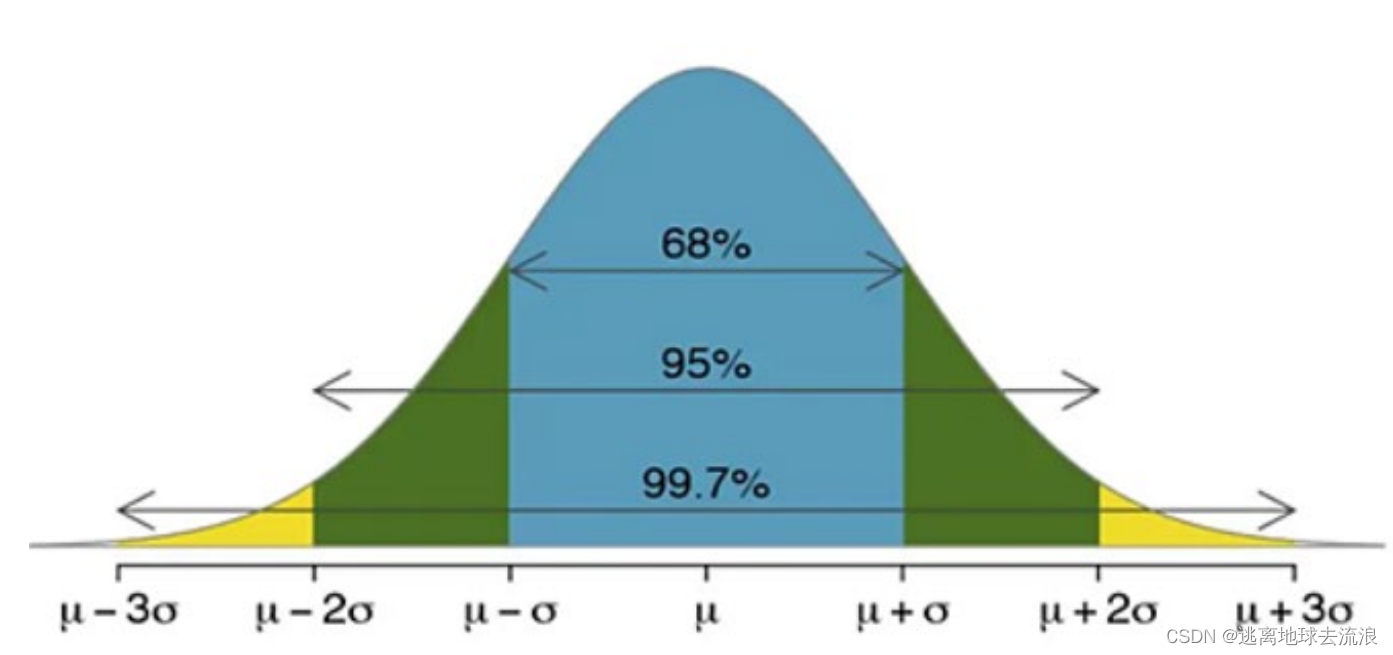
3 σ原则
如果数据服从正态分布,在3σ 原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布的假设下,距离平均值 3σ 之外的值出现的概率最大为 0.003
属于极个别的小概率事件。
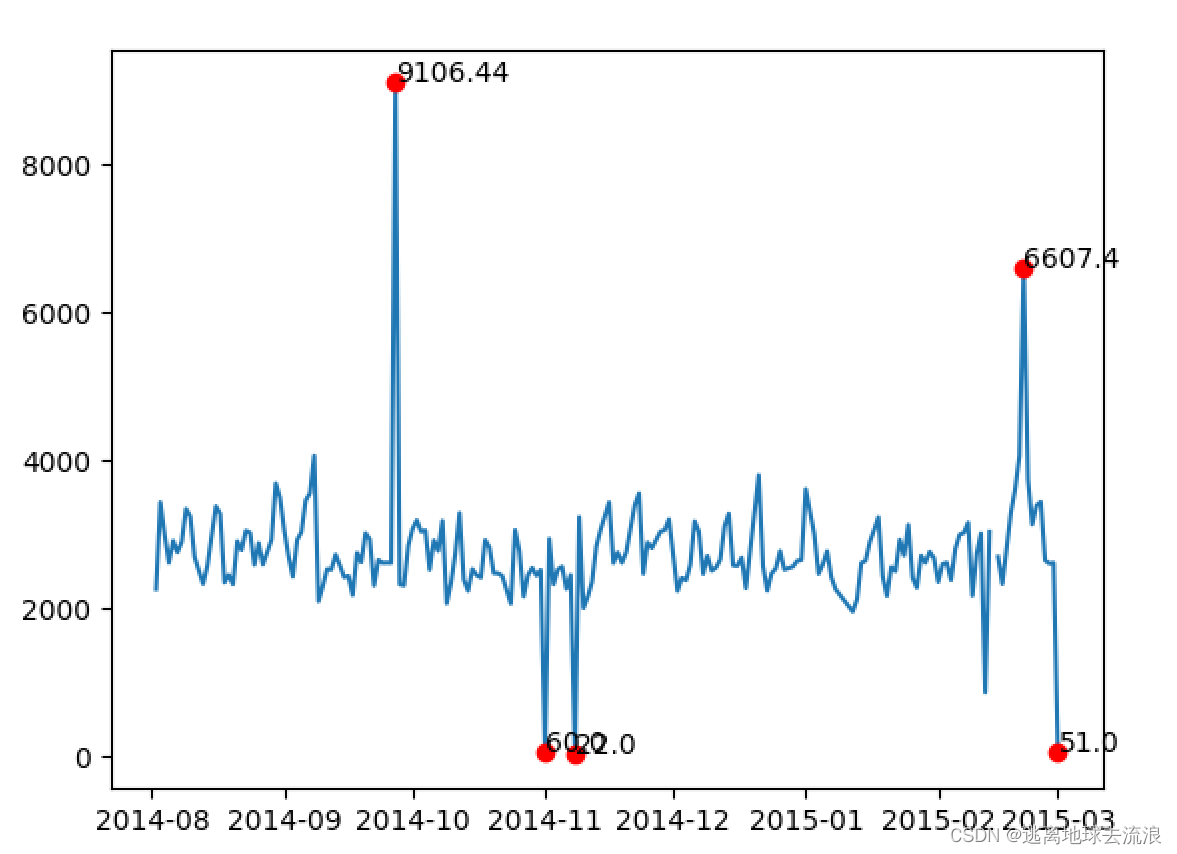
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt # 导入绘图库
n = 3 # n*sigma
catering_sale = 'catering_sale.xls' # 数据路径
data = pd.read_excel(catering_sale) # 读取数据
# print(data) # data 是dataframe类型
data_y = data[u'销量'] # data_y是series类型,加了u之后便成了float
data_x = data[u'日期'] # data_y是series类型,加了u之后便成了datetime
ymean = np.mean(data_y) # 用np的公式求均值
ystd = np.std(data_y) # 用np的公式求标准差
threshold1 = ymean - n * ystd # μ-3σ
threshold2 = ymean + n * ystd # μ+3σ
outlier = [] # 将异常值保存,空列表
outlier_x = []
# 循环0 - len(data_y)-1
for i in range(0, len(data_y)):
if (data_y[i] < threshold1) | (data_y[i] > threshold2):
outlier.append(data_y[i])
outlier_x.append(data_x[i])
else:
continue
print('\n异常数据如下:\n')
print(outlier)
print(outlier_x)
plt.plot(data_x, data_y)
plt.plot(outlier_x, outlier, 'ro')
for j in range(len(outlier)):
plt.annotate(outlier[j], xy=(outlier_x[j], outlier[j]), xytext=(outlier_x[j], outlier[j]))
plt.show()
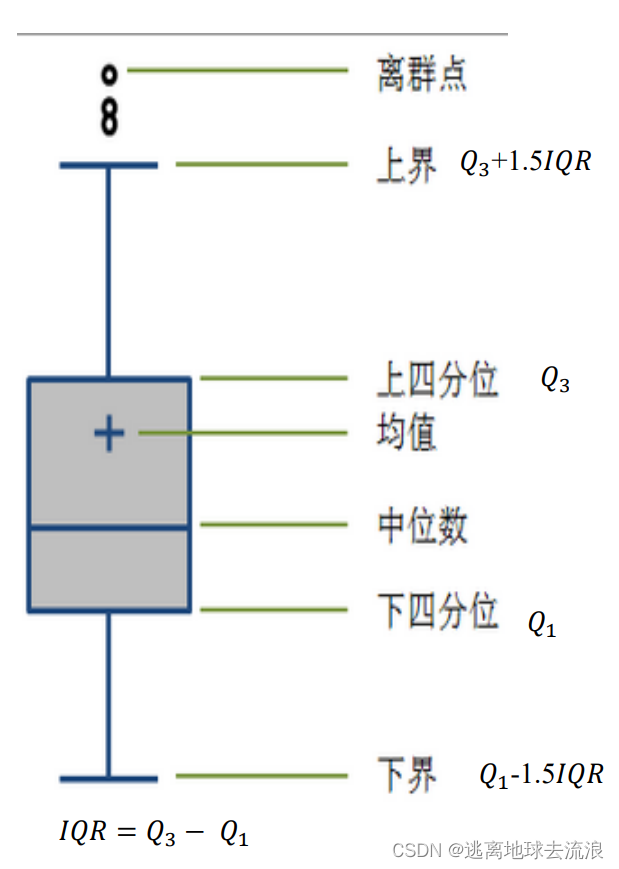
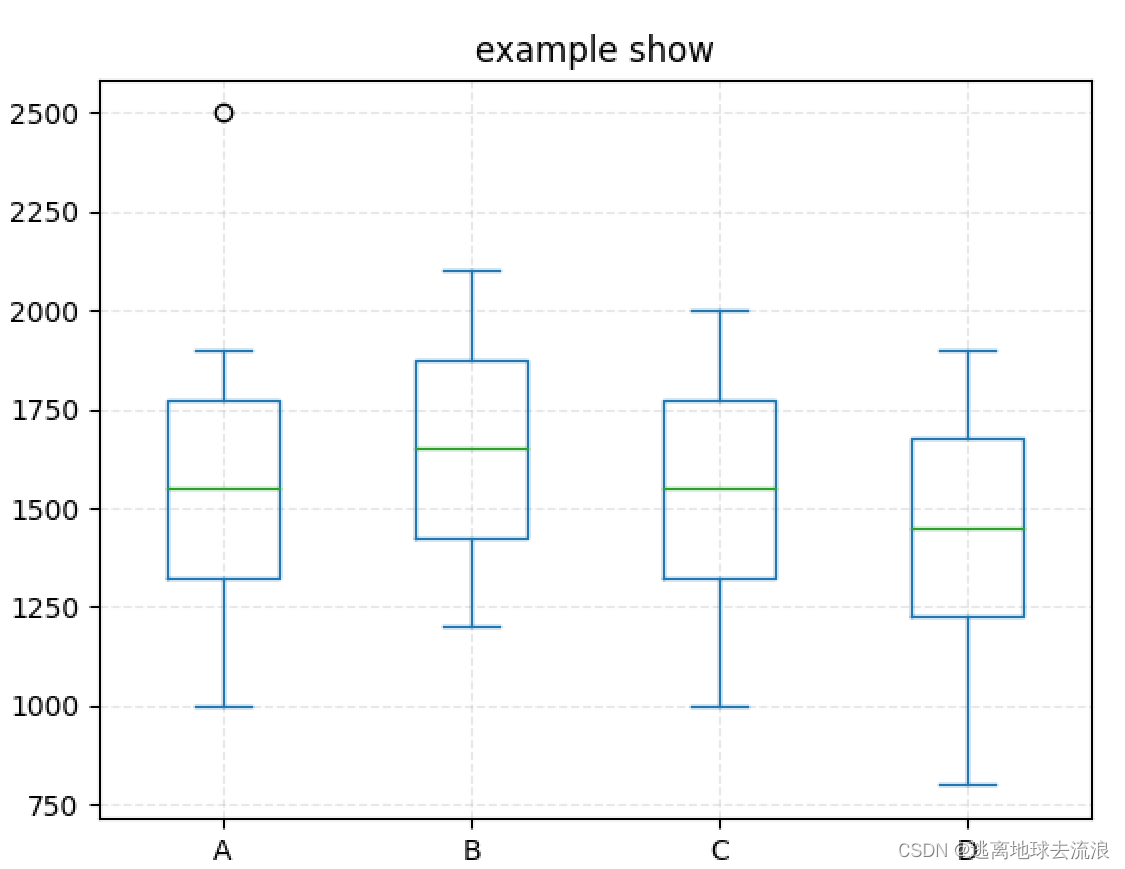
箱型图分析
箱线图是通过数据集的四分位数形成的图形化描述,是非常简单而且效的可视化离群点的一种方法。上下须为数据分布的边界,只要是高于上须,或者是低于下触须的数据点都可以认为是离群点或异常值。
下四分位数:25%分位点所对应的值(Q1)
中位数:50%分位点对应的值(Q2)
上四分位数:75%分位点所对应的值(Q3)
上须:Q3+1.5(Q3-Q1)
下须:Q1-1.5(Q3-Q1)
其中Q3-Q1表示四分位差
import matplotlib.pyplot as plt
import pandas as pd
data = {
'A': [1000, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2500],
'B': [1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100],
'C': [1000, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000],
"D": [800, 1000, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900]
}
df = pd.DataFrame(data)
print(df)
df.plot.box(title="example show")
plt.grid(linestyle="--", alpha=0.3)
plt.savefig('./results_imgs.png', bbox_inches='tight') # 保存png照片
plt.show()
不一致值
一致性分析
在数据挖掘过程中,不一致数据的产生主要发生在数据集成的过程中,可能是由于被挖掘数据是来自于从不同的数据源、重复存放的数据未能进行一致性地更新造成的,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。直接对不一致的数据进行挖掘,可能会产生与实际相违背的挖掘结果。
数据特征分析
对数据进行质量分析以后,接下来就是对数据做特征分析。一般可通过绘制图表、计算某些特征量等手段进行数据的特征分析。
这里主要介绍的特征方法有:
• 分布分析
• 对比分析
• 统计量分析
• 周期性分析
• 贡献度分析
• 相关性分析
相关性分析——计算相关系数
餐饮销量数据和节假日、天气等因素都可能有关系,使用相关性分析可以得到餐饮销量数据和其他因素的相关性,其Python代码如下所示:

在这里插入代码片

















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









