







U-Net
U-Net: Convolutional Networks for Biomedical Image Segmentation
网络结构
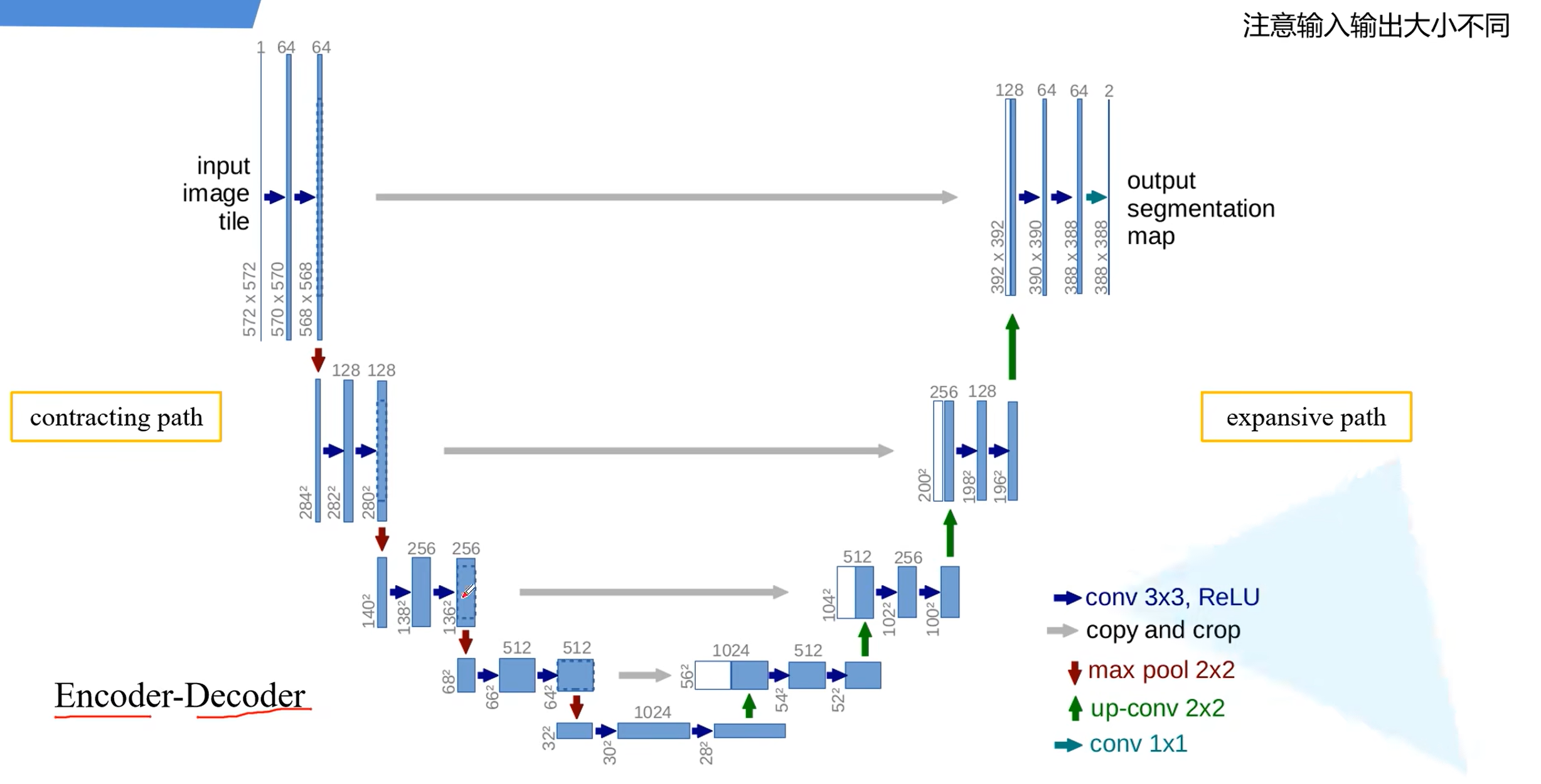
通过图可以很容易看出来网络的组成。
up-conv:转置卷积
注意最后输出的图像大小为388*388与原来不一样大
现在主流的方法,会在卷积层加个padding不改变原图大小卷积后还是保持一致的。
对于大图片分割
如果一次性将一张大图片放进去进行预测,会造成显存爆炸的问题,所以要对原有的图片进行裁剪,再进行分割。
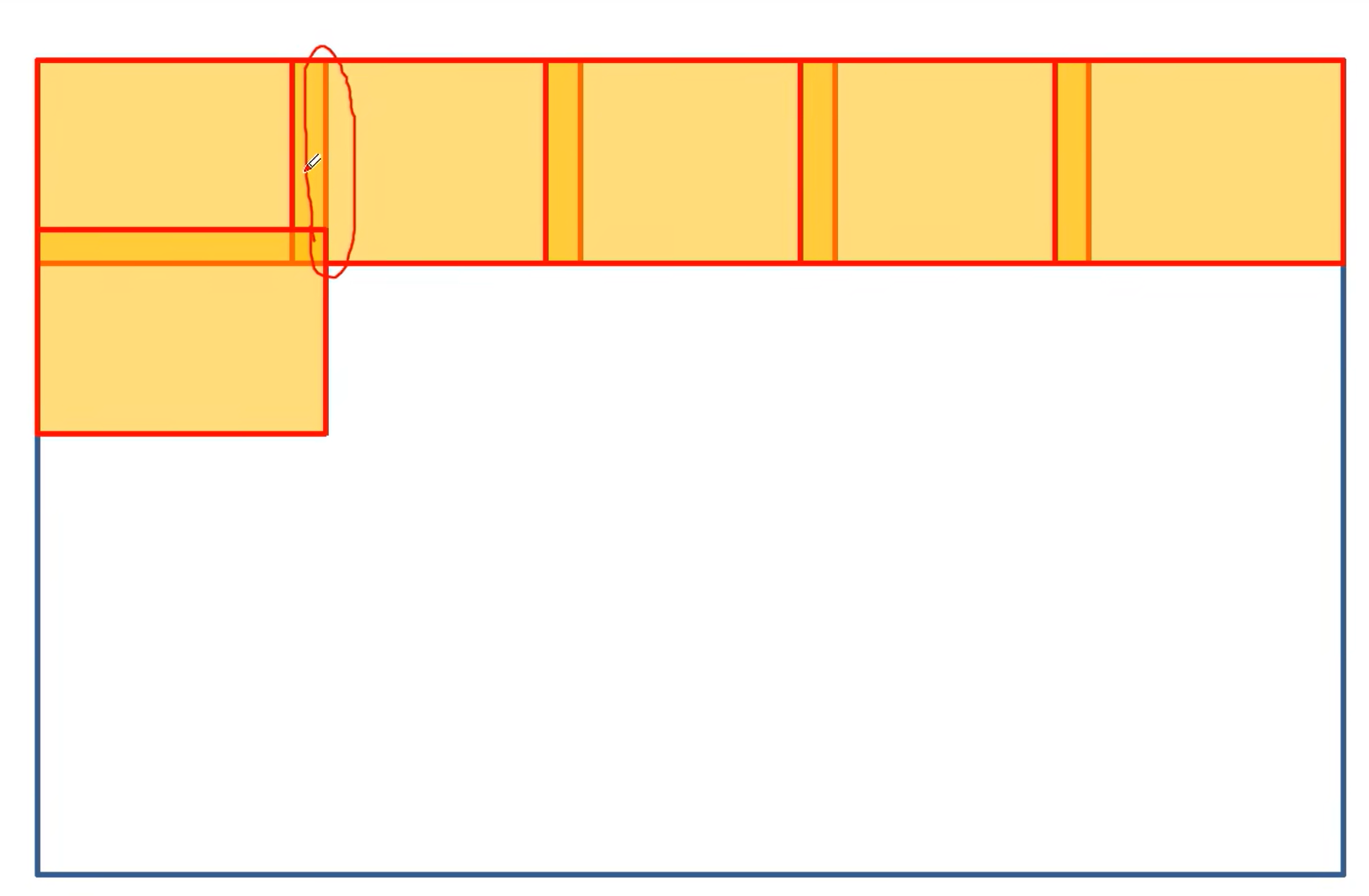
如上图,会对边界区进行重叠预测,这样会更好的处理边界信息。
U2Net
U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
针对SOD(salient object detection)任务——显著性目标检测(只分为前景和后景)
SOD任务:将图片中最吸引人的目标或区域分割出来(二分类任务)

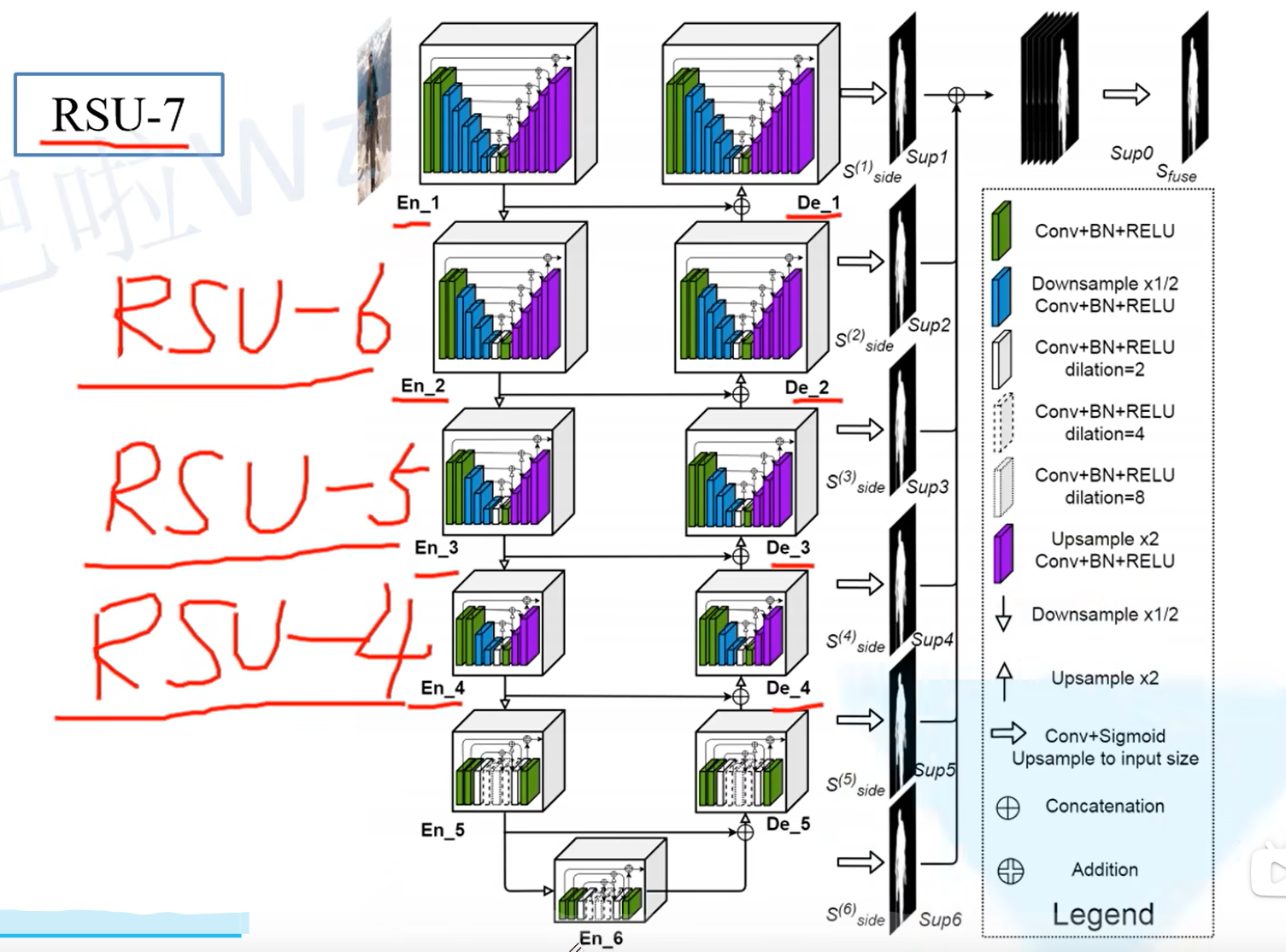
网络结构解析
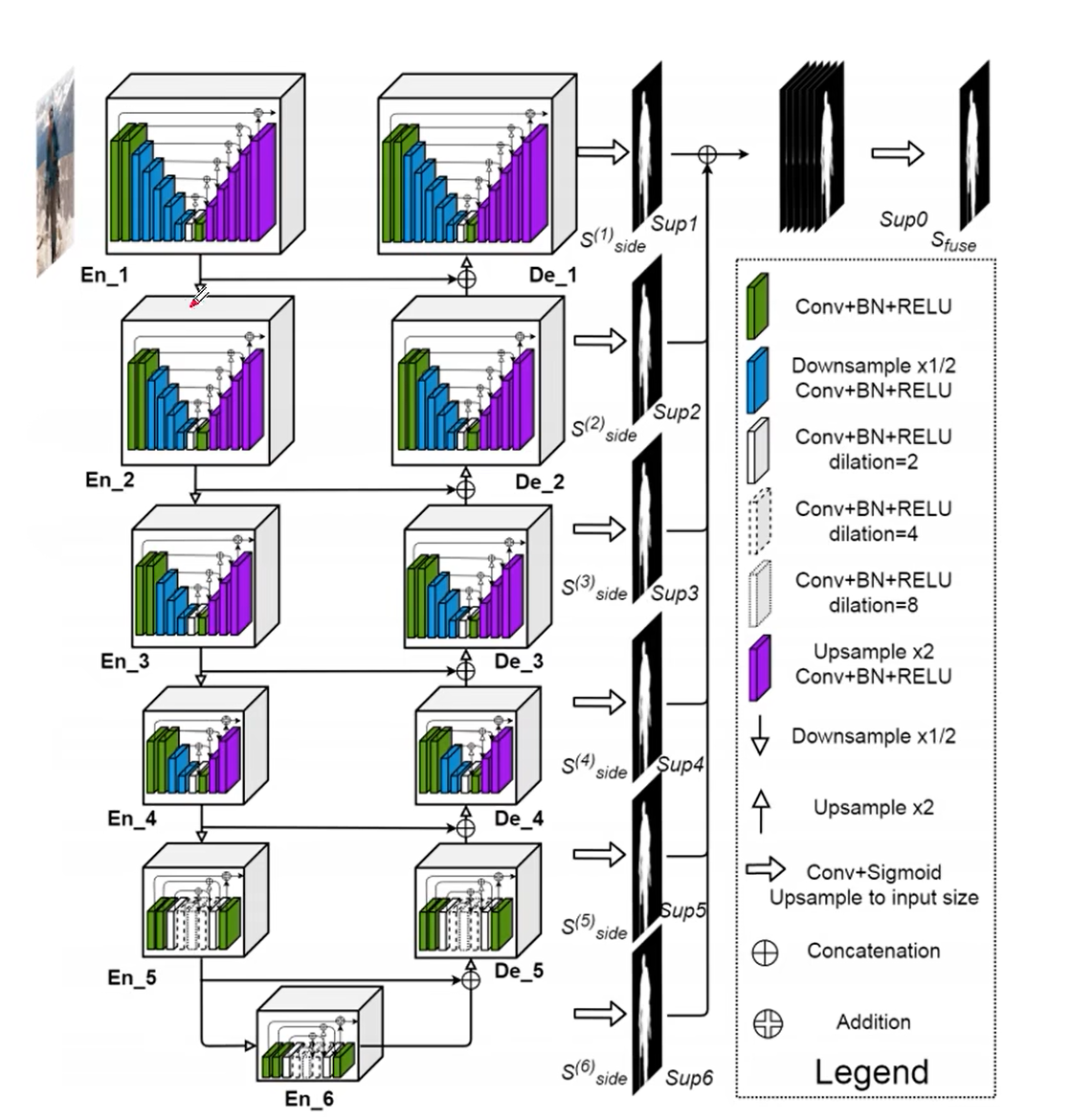
整体结构类似于UNet,在每个小的block中嵌套了Unet网络
在Encoder阶段,每通过一个block后会下采样2倍(maxpool),在Decoder阶段,每通过一个block前会上采样2倍(bilinear)。
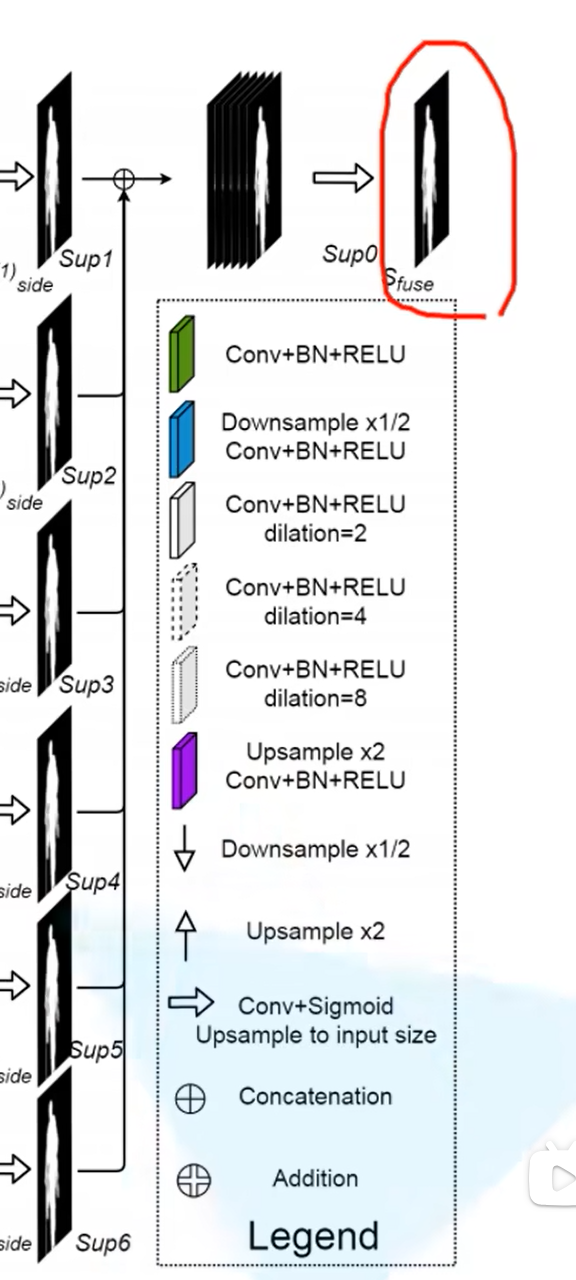
最后将每个阶段输出的预测图相加成最后一个输出图。
详细解析
RSU-7、6、5、4
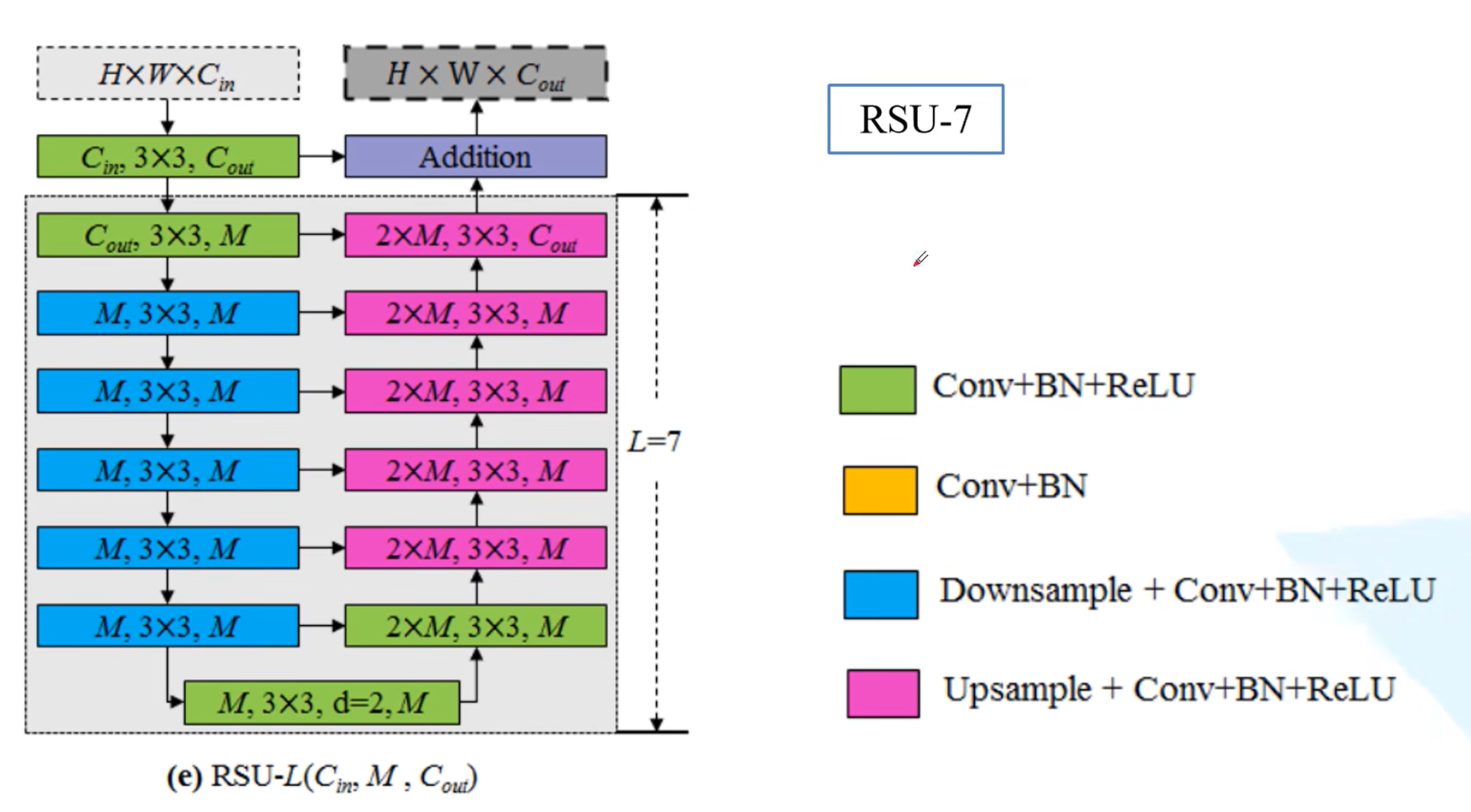
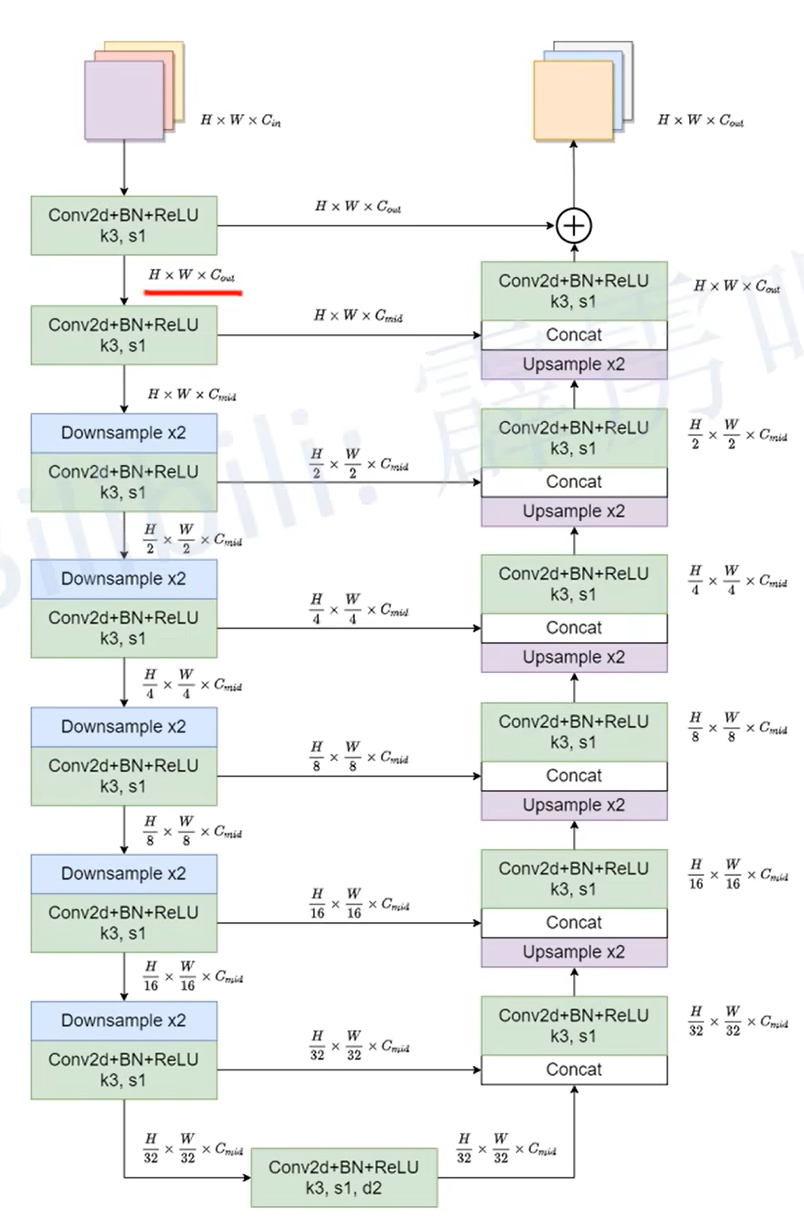
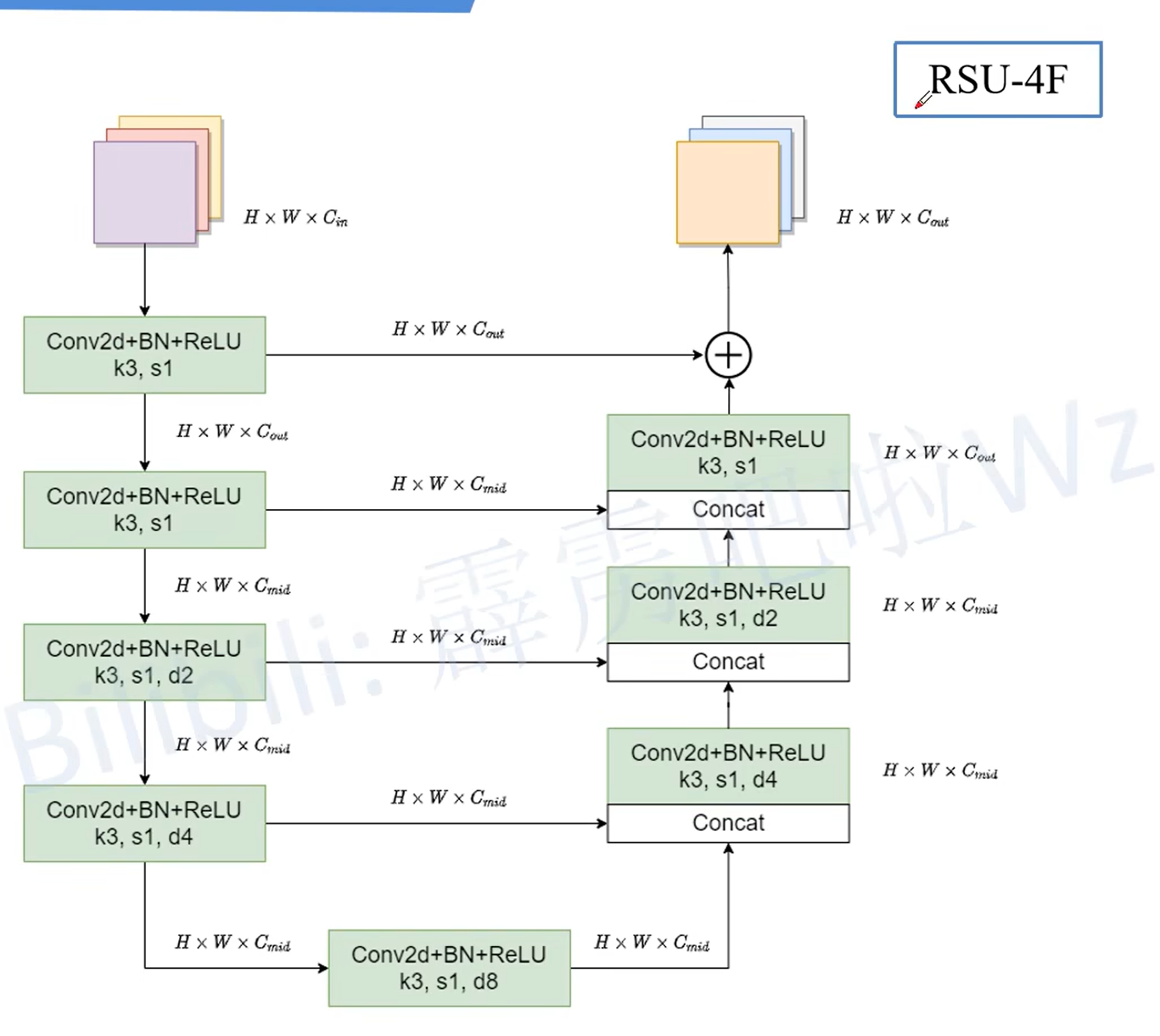
RSU-4F
到这里就不进行下采样了,保留更多的信息。
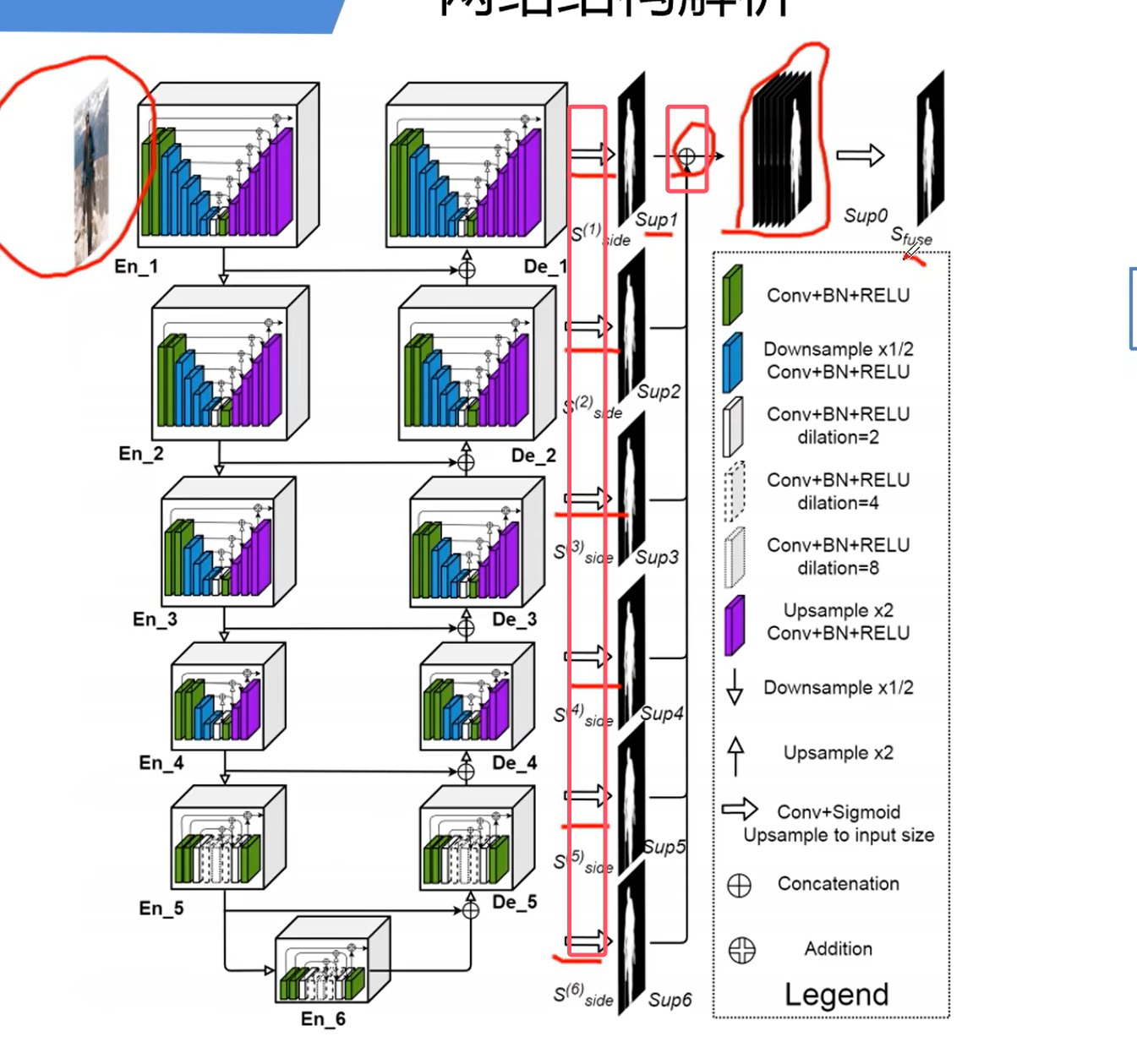
融合
saliency map fusion module
融合多个阶段的预测图得到最终的预测
将每层的输出经过一个3*3的卷积层,kernel个数为1, 再通过双线性插值恢复到原图的大小,然后将6个特征图进行concat拼接,最后通过一个1*1的卷积层和sigmod函数得到最后的预测图
损失计算

前面每层的输出特征图分别损失计算然后求和,并加上融合后的最终输出图的损失计算,权重都为1,相加后得到最终的损失值。

评价指标

数据集




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









