






为什么用了validation set结果在testing set还是过拟合呢
选择最好的模型时, 通常是选择模型在validation set上最高的精度(最低的Loss),

在通过validation set选择model的过程, 其实也是一种training.
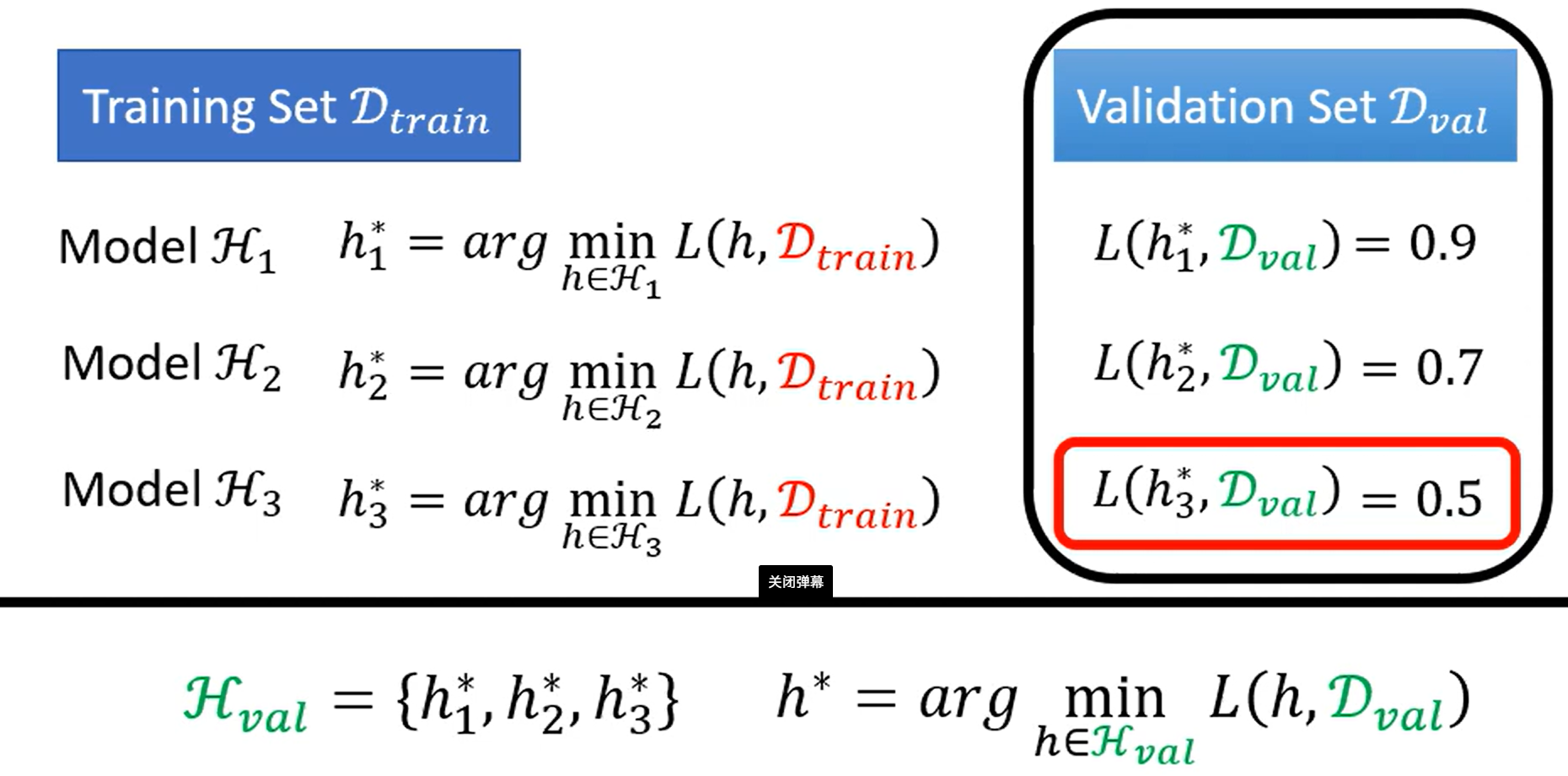

为什么会过拟合呢?
在training上过拟合, 通常有几个因素:
-
training data set is bad (理想和现实差距大)
-
模型复杂程度
-
training data set 的大小
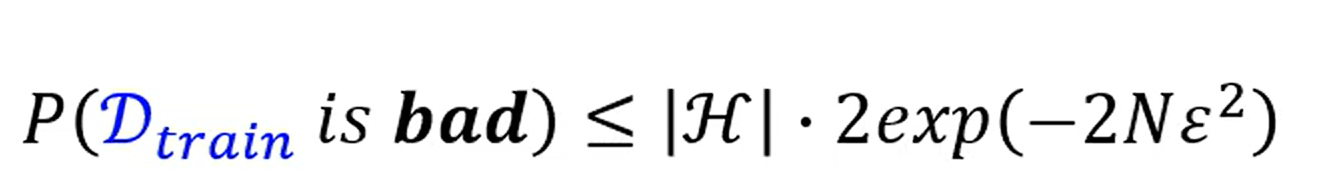
同样的val一个道理


选择最好的模型时, 通常是选择模型在validation set上最高的精度(最低的Loss),
在通过validation set选择model的过程, 其实也是一种training.
为什么会过拟合呢?
在training上过拟合, 通常有几个因素:
training data set is bad (理想和现实差距大)
模型复杂程度
training data set 的大小
同样的val一个道理
 534
2428
534
2428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























