




论文
代码链接:https://github.com/zhiqi-li/BEVFormer
阅读顺序:我之前在哔哩哔哩上跟着李沐一起读论文,按照他的方法:先看题目(比如这篇文章,它的重点就是Spatiotemporal Transformers,这是我们之前没见过的,肯定是它的特色)然后是看摘要,再看结论,接着扫一眼实验和文中的图、表数据,有了大致了解再决定是否细读。当然,李沐在看文章前还会看一下作者,这一篇我就不看了。
解读
Abstract
这一篇开头先放了一张图,是BEVFormer的简要构架图。一般也会有作者把自己觉得最好看的或是最重要的图放在最前面。
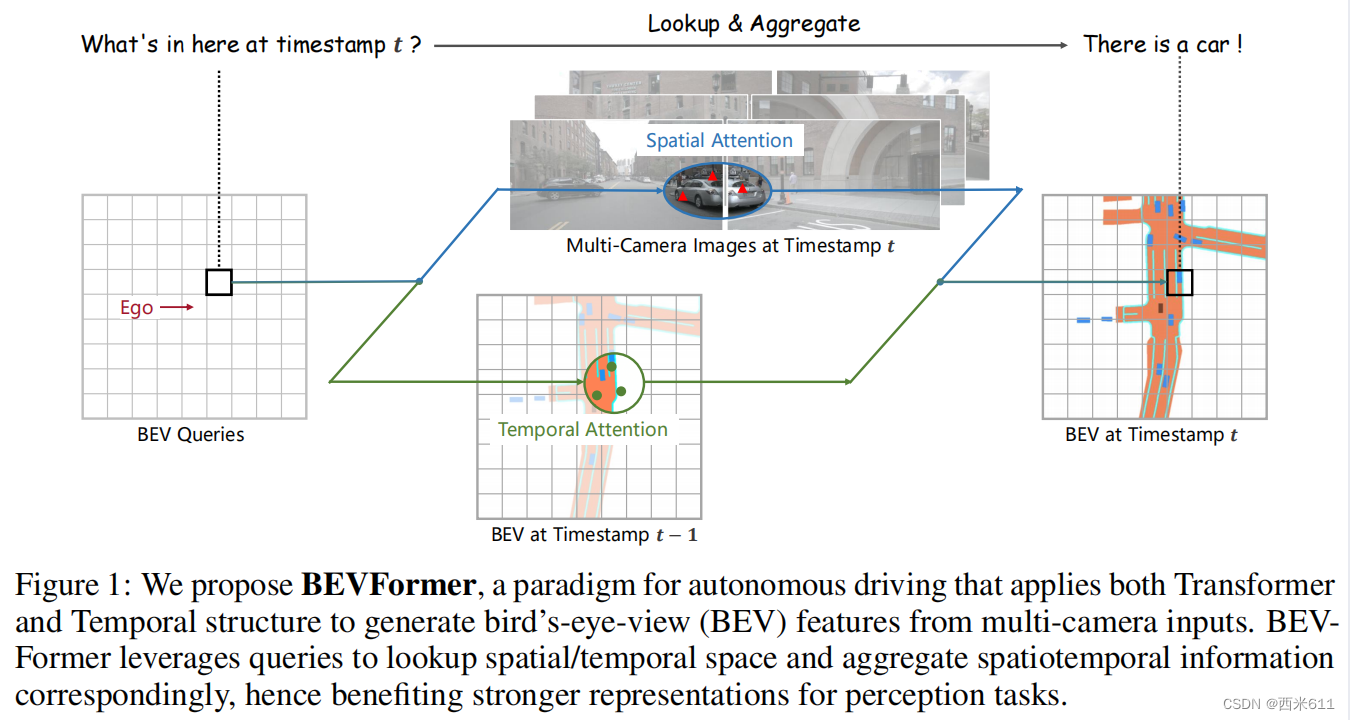
摘要:先说了3D视觉感知任务对自动驾驶系统很重要,作者提出了BEVFormer。BEVFormer使用时空Transformer学习统一的BEV表示以支持多个自主驾驶感知任务。BEVFormer通过预定义的网格形状的BEV queries与空间和时间进行交互,从而利用空间和时间信息。为聚合空间信息,作者设计了一个空间交叉注意力,即每个BEV从摄相机视图中的感兴趣区域中提取空间特征。对于时序信息,他们提出了一种时间自注意力来递归地融合历史BEV信息。最后,作者提到了他们的成果:在nuScenes测试集上,NDS达到了56.9%,比之前最好的高出了9个点,与基于雷达的baseline性能相当。同时,BEVFormer显著提高了低可见度情况下的速度估计精度和物体召回率。
Discussion and Conclusion
作者提出了BEVFormer来从多相机输入生成鸟瞰图特征,BEVFormer可以有效地聚集空间和时间信息,并生成强大的BEV特征,同时支持3D检测和地图分割任务。
局限性:目前,基于相机的方法在效果和效率上仍与基于激光雷达的方法存在特定差距。从2D信息精确推断3D位置对基于相机的方法来说仍是一个长期的挑战。
广泛影响:BEVFormer证明了使用来自多摄相机输入的时空信息可显著提高视觉感知模型的性能。BEVFormer展示的优势对构建更好更安全的自主驾驶系统以及其他系统至关重要。作者相信BEVFormer只是接下来更强大的视觉感知方法的基线,基于视觉的感知系统仍有巨大的潜力有待探索。
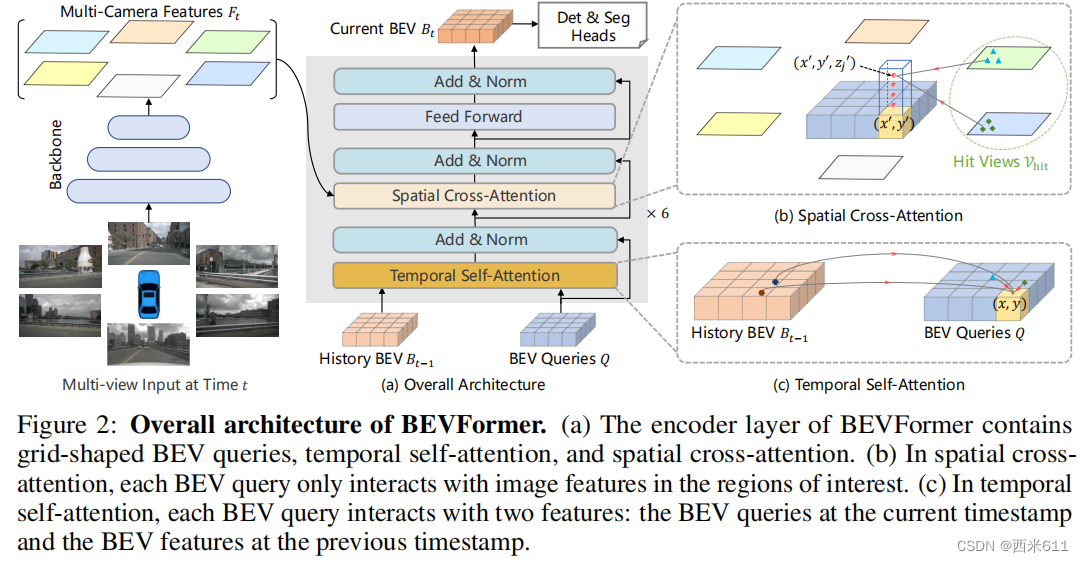
(再整体看一下文章的图:文章第一页最上面的图(图1)是简要框架图,初次看我感觉是通过t-1时刻的BEV和t时刻的多视角相机图像来推断出t时刻的BEV,该过程中利用到了BEV Queries来查询、聚合时空信息;在第四页最上方(图2)是整体框架图,最左边就是多视角图像输入,经过2D backbone得到特征图。中间部分最为重要,其中包含了时间自注意力和空间交叉注意力,还有一些正则和前向,几个层堆叠在一起组成一个块,重复6次,每一层得到当前时刻的BEV后喂入下一层,最后用不同的头做检测和分割;在第八、九页上有表格数据,可以看到不管是测试集还是验证集,相对于其他基于纯相机的模型,BEVFormer对应的NDS和mAP两栏都是最高的)
Introduction
3D空间中的感知对各种应用都至关重要,如自动驾驶、机器人等。尽管基于激光雷达的方法取得了显著进展,但基于相机的方法近年来也已引起广泛关注。除了部署成本较低外,与基于激光雷达的系统相比,摄相机在检测远距离物体和识别基于视觉的道路元素(如交通灯、停车线)方面具有理想的优势。
自动驾驶中对周围场景的视觉感知能够从多相机提供的2D线索中预测3D包围框和语义地图。最直接的方案是基于单目框架和跨摄相机后处理。该框架的缺点是,它分别单独处理不同的视图,无法跨摄相机捕获信息,导致性能和效率低下。
作为单目框架的替代,一个更统一的框架是从多相机图像中提取整体表示。鸟瞰图(BEV)是周围场景的常用表示,因为它清楚地显示了物体的位置和大小,适用于各种自动驾驶任务,如感知和规划。尽管之前的地图分割方法证明了BEV的有效性,但基于BEV的方法在3D物体检测中没有显示出比其他范式的显著优势。根本原因是,3D物体检测任务需要强大的BEV特征来支持精确的3D包围框预测,但从2D平面生成BEV是不适定的。基于深度信息生成BEV特征的BEV框架最为流行,但该范式对深度值或深度分布的精度很敏感。因此,基于BEV的方法的检测性能会受到复合误差的影响,而且不准确的BEV特征可能会严重影响最终性能。因此,我们设计了一种不依赖深度信息的BEV生成方法,可以自适应地学习BEV特征,而不是严格依赖3D先验。Transformer使用注意力机制动态聚合有价值的特征,在概念上满足了我们的需求。
另一个使用BEV特征来完成感知任务的动机是:BEV是一个连接时间和空间的理想桥梁。对于人类视觉感知系统,时间信息在推断物体的运动状态和识别被遮挡物体方面起到了很大作用,而且视觉领域的很多工作已经验证了使用视频数据的有效性。然而,现有的先进的多相机3D检测方法很少发掘时间信息。最大的挑战在于自动驾驶对于时序要求很严格,而且物体在场景中变化很快,所以简单地堆叠跨时间的BEV特征带来了额外的计算花销和干扰信息,这是不理想的。受recurrent neural networks(RNNs)的启发,我们利用BEV特征来递归地传递从过去到现在的时间信息,这与RNN模型的隐藏状态相同精髓。
我们提出了基于Transformer的BEV编码器,叫做BEVFormer,它可以有效地聚合来自多视点摄相机的时空特征和历史BEV特征。由BEVFormer生成的BEV特征以同时支持多个3D感知任务。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









