







聚类
典型无监督学习,旨在通过数据集本身属性发掘内在(分类)规律。
一、聚类及其参数指标
1、聚类任务:无监督学习的一种,试图将数据集中的样本划分为无交并子集“簇”,以为分析数据分布或其他学习任务打下分类基础。
2、性能度量:分为外部和内部指标。外部指标是指和预先给定分类越接近越好,内部指标对分类要求自然是组内越密越好,组间越稀越好。外部指标定义两两样本对的若干集合,表示是否在聚类分类和参考分类中归属与同一簇,由此定义出JC、FMI、RI用来刻画聚类和参考的相似度。内部指标根据样本距离定义簇内中心点、簇内样本间平均距离、簇间中心距、簇间最近距离等,由此定义出DBI、DI用以刻画簇内相对密度(或簇间相对稀疏度)。
3、距离度量:距离一般定义:非负、对称、三角。若属性有序(包括离散有序),常用Minkowski距离即为p-范数,p=2即为欧氏距离,p=1即为曼哈顿距离。若属性无序,常用VDM距离,并整理到Minkowski距离中。若属性重要性不一,加权即可。
二、原型聚类
聚类算法的一种,假设聚类结构能通过一组原型刻画。
1、kMeans:k均值算法,目标为最小化簇内点到均值点的平方误差。采用贪心法,任意选取k个原型向量,遍历所有点,向k个原型邻近合并为k个簇,更新原型为簇均值,再循环操作直到簇结构不变。
2、LVQ学习向量量化:人为设置标签,任选k个带标签原型向量,随机一个样本,将其与最近原型向量对比标签,相同接近,相反远离,足够多轮后将原型最近的一批样本划分为同一簇。
3、高斯混合聚类:认为数据由k个n维高斯分布组成,其按权重α混合形成总体混合高斯分布,若设法求出k个高斯分布参数,即可通过xj相对于第i个高斯分布的后验概率最大确定xj属于第i个聚类。迭代内容为k个高斯分布的参数,优化目标是最大化样本点归属各高斯分布的对数似然概率。

三、密度聚类
聚类算法的一种,假设聚类结构能通过样本分布紧密程度确定。
1、邻域参数:核心对象即为邻域内至少包含MinPts个样本的样本,样本间密度直达即某样本位于核心对象的邻域内,密度可达即存在密度直达的序列,密度相连即存在密度可达的序列。
2、DBSCAN:选出所有核心对象为一集合,以任一核心对象为出发点,找出密度可达所有样本形成聚类簇,再将涉及到的核心对象从集合去除,循环操作。
四、层次聚类
聚类算法的一种,试图再不同层次对数据集划分,形成树形聚类结构。
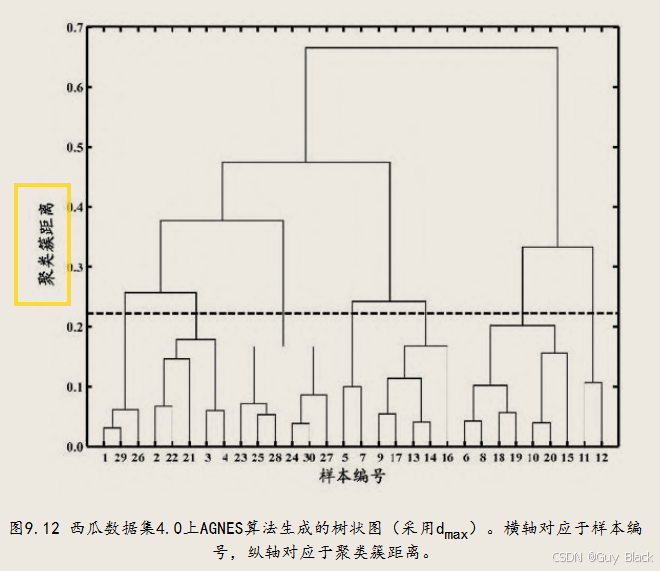
1、AGNES:每个样本视为一个初始簇类,算法每一步找出距离最近的两个簇进行合并 ,直到达到预设簇类个数。层次图如图,常为逐步增加距离合并簇类,形成距离-簇类图,再在某一距离下以虚线划分获得指定个数下的簇类。

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









