






其他机器学习系列文章见于专题:机器学习进阶之路——学习笔记整理,欢迎大家关注。
1. 密度聚类
密度聚类假设聚类结构能够通过样本分布的紧密程度确定,其主要思想是:通过样本之间是否紧密相连来判断样本点是否属于同一个簇。
这类算法能克服基于距离的算法(如K-Means)只能发现凸聚类的缺点,可以发现任意形状的聚类,且对噪声数据不敏感,但计算密度大暖的计算复杂度大,需要建立空间索引来降低计算量。
2. DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种著名的密度聚类算法。
它的核心思想是:用一个样本点的 ϵ ϵ ϵ领域内的样本数目来表征该样本所在的空间密度,由密度可达关系导出的最大的密度相连样本集合就是聚类得到的一个“簇”。该算法能够把密度足够高的区域划分为“簇”,并且可以在有“噪声”的数据中发现任意形状的聚类。
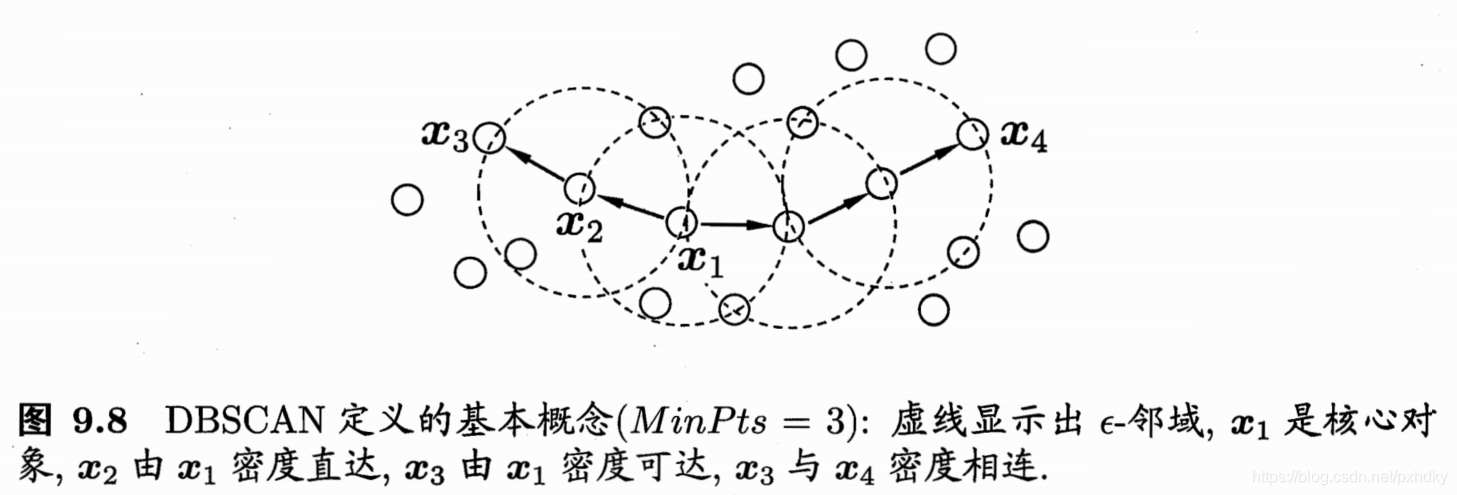
给定数据集 D = { x 1 , x 2 , … , x m } D = \left\{ \boldsymbol { x } _ { 1 } , \boldsymbol { x } _ { 2 } , \dots , \boldsymbol { x } _ { m } \right\} D={x1,x2,…,xm},DBSCAN的一些概念如下:
ϵ ϵ ϵ-邻域:即对于样本点 x j x_j xj,和它的距离在 ϵ ϵ ϵ之内的属于样本集 D D D中的点的集合,即 N ϵ ( x j ) = { x i ∈ D ∣ dist ( x i , x j ) ⩽ ϵ } N _ { \epsilon } \left( \boldsymbol { x } _ { j } \right) = \left\{ \boldsymbol { x } _ { i } \in D | \operatorname { dist } \left( \boldsymbol { x } _ { i } , \boldsymbol { x } _ { j } \right) \leqslant \epsilon \right\} Nϵ(xj)={xi∈D∣dist(xi,xj)⩽ϵ};
核心对象:若 x j x_j xj的 ϵ ϵ ϵ邻域至少包含 M i n P t s MinPts MinPts个样本,即 ∣ N ϵ ( x j ) ∣ ≥ M i n P t s |Nϵ(x_j)|≥MinPts ∣Nϵ(xj)∣≥MinPts,那么 x j x_j xj是一个核心对象;
密度直达:如果 x j x_j xj位于核心对象 x i x_i xi的 ϵ ϵ ϵ邻域内,则称 x j x_j xj由 x i x_i xi密度直达;
密度可达:存在一个样本序列 p 1 , p 2 , ⋯ , p n p_1,p_2,⋯,p_n p1,p2,⋯,pn, x j x_j xj到 p 1 p_1 p1是直达的, p 1 = x i \boldsymbol { p } _ { 1 } = \boldsymbol { x } _ { i } p1=xi, p n = x j \boldsymbol { p } _ { n } = \boldsymbol { x } _ { j } pn=xj,且 p i + 1 p_{i+1} pi+1由 p i p_i pi密度直达,则称 x j x_j xj由 x i x_i xi密度可达;
密度相连:对于样本点 x j x_j xj和 x i x_i xi,若存在点 x k x_k xk使得 x j x_j xj和 x i x_i xi均可由 x k x_k xk密度可达,则称 x j x_j xj和 x i x_i xi密度相连。
基于密度定义,我们将点分为核心点、边缘点和噪声。
- 核心点:也就是核心对象;
- 边缘点:可由某和新对象密度可达的样本点;
- 噪音点:任何既不是核心点,也不是边缘点的样本点;
DBSCAN算法流程:先根据给定的领域参数 ( ϵ , M i n P t s ) ( \epsilon , M i n P t s ) (ϵ,MinPts)找出所有核心对象,然后以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象都被访问过。
3. DBSCAN优缺点
优点:
1. 不需要先给定簇的数目;
2. 可以发现任意形状的簇;
3. 可以发现异常点当做噪声,对异常点不敏感;
缺点:
1. 当数据集密度差异很大时,聚类质量较差;
(非平面几何,不均匀的簇大小)
2. 数据集较大时,聚类收敛时间长;
3. 算法聚类效果依赖于距离公式选取,实际应用中常用欧式距离,但对于高维数据,存在“维数灾难”。
参考文献:

















 1997
1997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









