







文中
b可理解为begin,m可理解为middle,e可理解为end
1.reverse
reverse(b,e):对索引为[b,e)的元素进行反转,无返回值。
例:
vector<int> v = { 0, 1, 2, 3, 4 };
reverse(v.begin(), v.end());
// v = { 4, 3, 2, 1, 0 }
此函数模板的实现等效于
void reserve(iterator first,iterator last){
while(first!=last&&first!=--last){
iter_swap(first,last);
first++;
}
}
/*
reserve的操作范围是[first,last)
故last最开始就要--
每循环一次,first指向后一个数,last指向前一个数,共移动两项故比较两次
*/2.rotate
rotate(b,m,e):对于每一个整型实数 k (0<=k<(e-b)),将索引为b+k的元素移动到索引为b+((k+(e−m))mod(e−b))的位置上。
上面这段话我看了老半天没看懂
我是这样理解的
rotate的作用是旋转,将[b,m),[m,e)两段数据旋转
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int *m;
for (int i = 0; i < 10; i++) {
cout << a[i] << " ";
}
cout << endl;
m = a + 4;
rotate(a, m, a + 10);
for (int i = 0; i < 10; i++) {
cout << a[i] << " ";
}
cout << endl;
}运行结果:
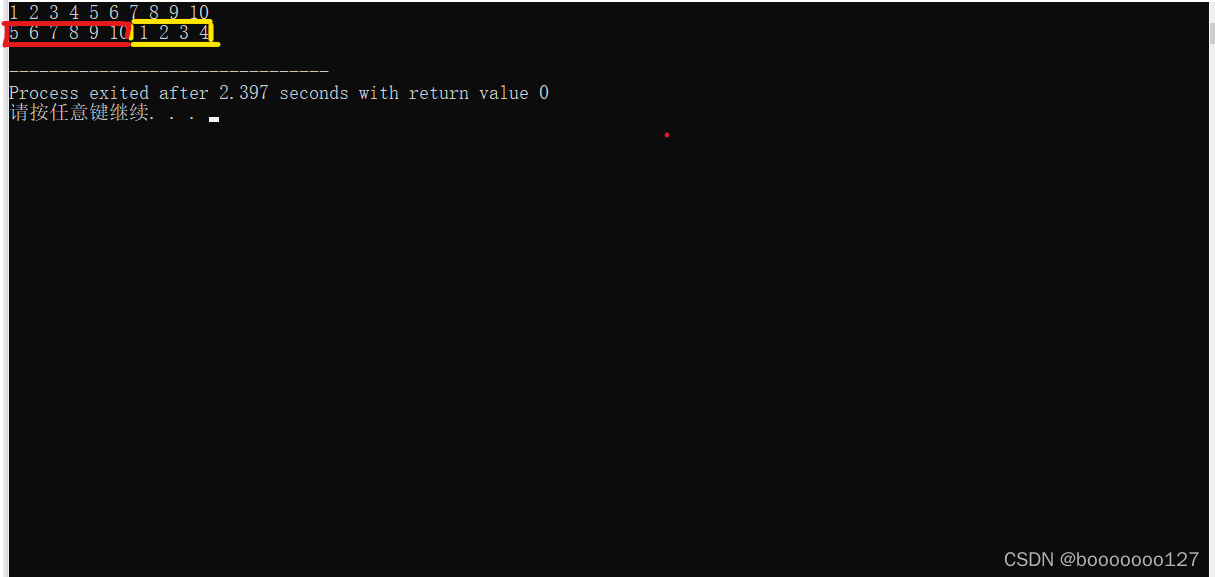
红色包围的和绿色包围的是两段不同的两段数据
3.swap_ranges
swap_ranges(b,e,t):对于所有k(0<=k<(e-b)),交换索引为(b+k)和索引为(t+k)的元素。
和上面介绍的rotate很相似,
swap_ranges(b,e,t):可用于不连续的两段数据,只能交换两段相同长度的数据,长度为b-e,将起始索引为b,长度为b-e的数据段交换到起始索引为t,长度为b-e的数据段上。
rotate(b,m,e):用于连续的两段数据,数据段长度可以不同,将起始索引为b,长度为m-b的数据段交换到起始索引为m,长度为e-m的数据段上。
4.unique
unique(b,e)
返回值为迭代器,迭代器指向的是重复元素的首地址
unique只能将相邻的相同元素移到器尾部
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
int main() {
int s[] = {1, 2, 3, 4, 4, 5, 5, 1, 7, 8};
for (int i = 0; i < 10; i++) {
cout << s[i] << " ";
}
cout << endl;
unique(s, s + 10);
for (int i = 0; i < 10; i++) {
cout << s[i] << " ";
}
cout << endl;
}运行结果: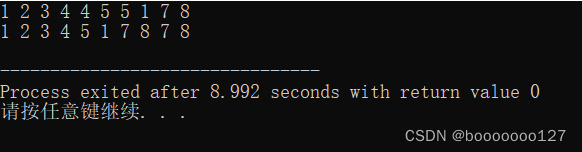
我们可以看到,重复的数没有被删除,而是被移到末尾,
而1虽然重复但是不相邻,故没有被移到末尾。
故一般使用时,我们可以用sort排序后再使用unique,
tips:
因为unique返回值为迭代器指向的是重复元素的首地址
可以用这种方式,在不删除的情况下输出
c=unique(b,e)
for(i=b;i<c;i++){
cout<<*i;
}若要进行删除操作,则可以
vector<int> vecInt = { 1, 2, 4, 8, 2, 2, 3, 4, 5, 8, 10, 2 };
std::sort(vecInt.begin(), vecInt.end()); //利用STL的排序算法实现对vector的排序
vecInt.erase(std::unique(vecInt.begin(), vecInt.end()), vecInt.end());

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









