







目录
3.confusion_matrix_normalized.png
在翻阅了各种博客,询问他人之后,发现对于 labels_correlogram.jpg 的介绍非常不清晰。身边的人也几乎不理解它是做什么用的,如何去分析。因此写下本篇博客。在本文,我对一些易混淆内容进行了补充性描述。
持续更新中
模型:Yolov8s.pt
训练类别:13
训练结果目录
0.知识点
| Actual P | Actual N |
------------|---------------|---------------|
Predicted P | TP | FP |
------------|---------------|---------------|
Predicted N | FN | TN |
命名规则:(验证是否正确True/False)(预测值)
TP:预测为P,实际为P,预测正确
FP:预测为P,实际为N,预测错误
FN:预测为N,实际为P,预测错误
TN:预测为N,实际为N,预测正确
P : Precision(精确率) = TP / (TP + FP),预测为P的样本中有多少真实为P(减少误诊)
R : Recall (召回率)= TP / (TP + FN),真实P样本中有多少被正确检出(减少漏诊)
Specificity (特异度)= TN / (TN + FP ),真实N样本中有多少被正确排除
F1 = 2*P*R / P + R ,平衡精确率与召回率的综合指标
x:水平位置,y:垂直位置。举例:无人机一般 y < 0.2(图像上方20%区域内)
width、height 可以理解为像素大小
在训练结果分析中,这些参数都经过了归一化,范围在0~1之间
1.weights
weights目录下只有两个文件:
best.pt文件是训练过程中获得的,表现最好的权重文件。
last.pt是训练过程中最后一次获得的权重文件。
其中,best.pt用于模型推理部署(实际中使用的模型),last.pt用于下一次推理使用(机器使用的模型,可以从上一次训练的位置继续训练)
2.args.yaml
训练参数文件
task: detect
mode: train
model: 保密,有我大名
data: 保密,有我大名
epochs: 200
time: null
patience: 100
batch: 128
imgsz: 512
save: true
save_period: -1
cache: false
device: 0
workers: 8
project: 保密
name: 保密
exist_ok: false
pretrained: 保密
optimizer: auto
verbose: true
seed: 0
deterministic: true
single_cls: false
rect: false
cos_lr: false
close_mosaic: 10
resume: false
amp: true
fraction: 1.0
profile: false
freeze: null
multi_scale: false
overlap_mask: true
mask_ratio: 4
dropout: 0.0
val: true
split: val
save_json: false
save_hybrid: false
conf: null
iou: 0.7
max_det: 300
half: false
dnn: false
plots: true
source: null
vid_stride: 1
stream_buffer: false
visualize: false
augment: false
agnostic_nms: false
classes: null
retina_masks: false
embed: null
show: false
save_frames: false
save_txt: false
save_conf: false
save_crop: false
show_labels: true
show_conf: true
show_boxes: true
line_width: null
format: torchscript
keras: false
optimize: false
int8: false
dynamic: false
simplify: true
opset: null
workspace: null
nms: false
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5
cls: 0.5
dfl: 1.5
pose: 12.0
kobj: 1.0
nbs: 64
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
bgr: 0.0
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
copy_paste_mode: flip
auto_augment: randaugment
erasing: 0.4
crop_fraction: 1.0
cfg: null
tracker: botsort.yaml
save_dir: 保密
解释主要参数含义:
task:detect 任务类型为检测
mode:train 运行模式为训练
model 文件中主要参数是nc值,nc(Number of Classes),有多少类别就修改为几。
data 为数据主路径、训练集路径、验证集路径、测试集路径(可忽略),和标签类别名称。
epochs 训练轮数
batch:128 每次训练取128张图像为一轮
imgsz 训练过程中输入的图像大小为512*512
seed 随机种子(用于确保训练可复现)
lr0 初始学习率
lrf 最终学习率衰减系数 (lr=lr0*lrf)
device 使用几号GPU
3.confusion_matrix_normalized.png
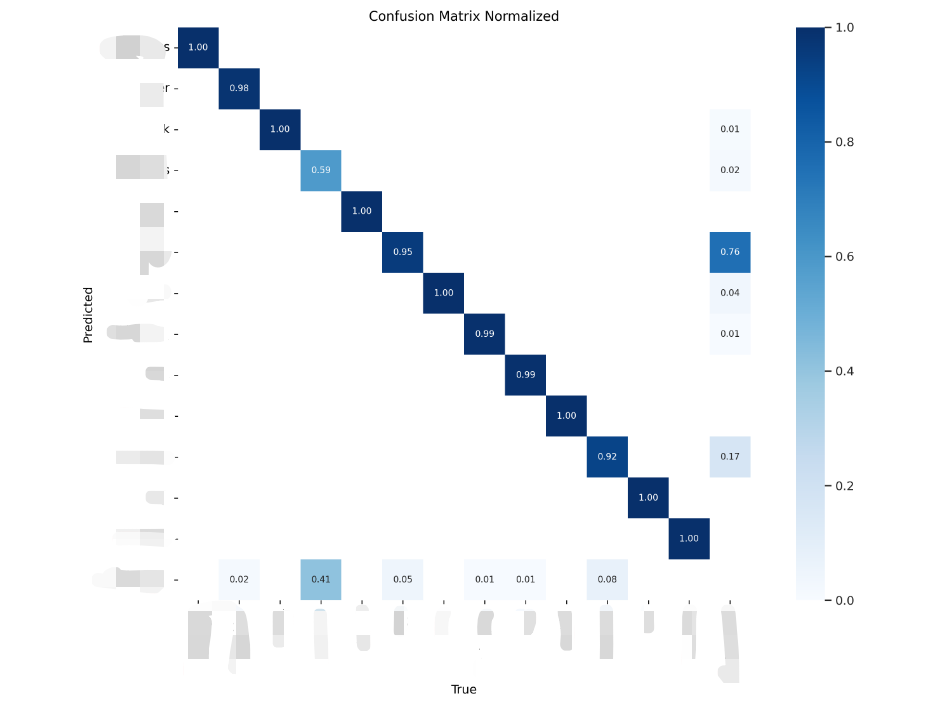
实际值和预测值识别准确率
4.confusion_matrix.png
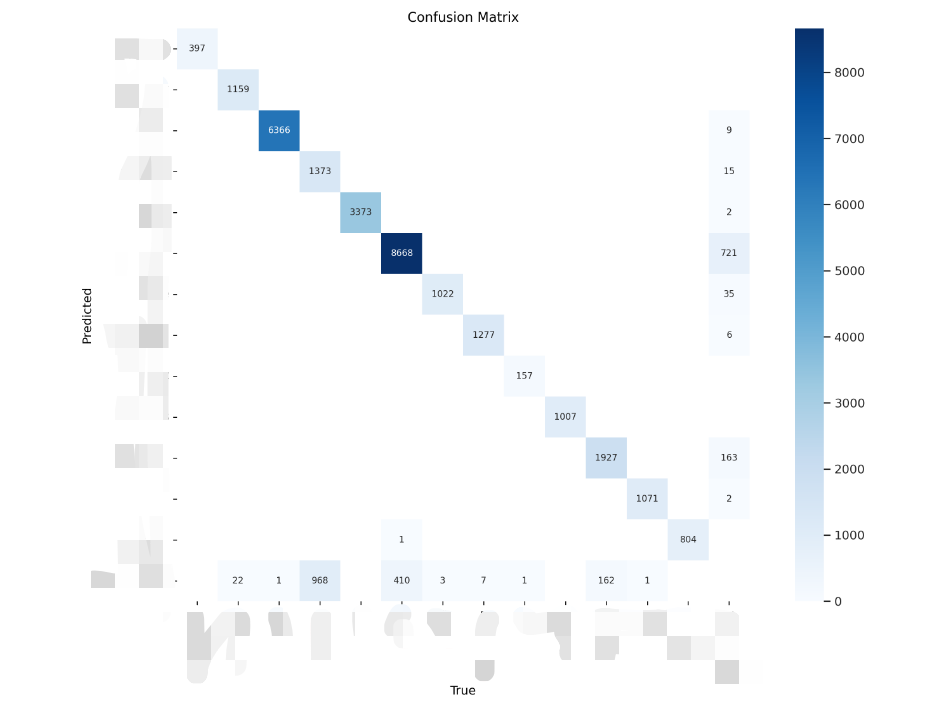
实际值和预测值识别准确数
5.F1_curve.png
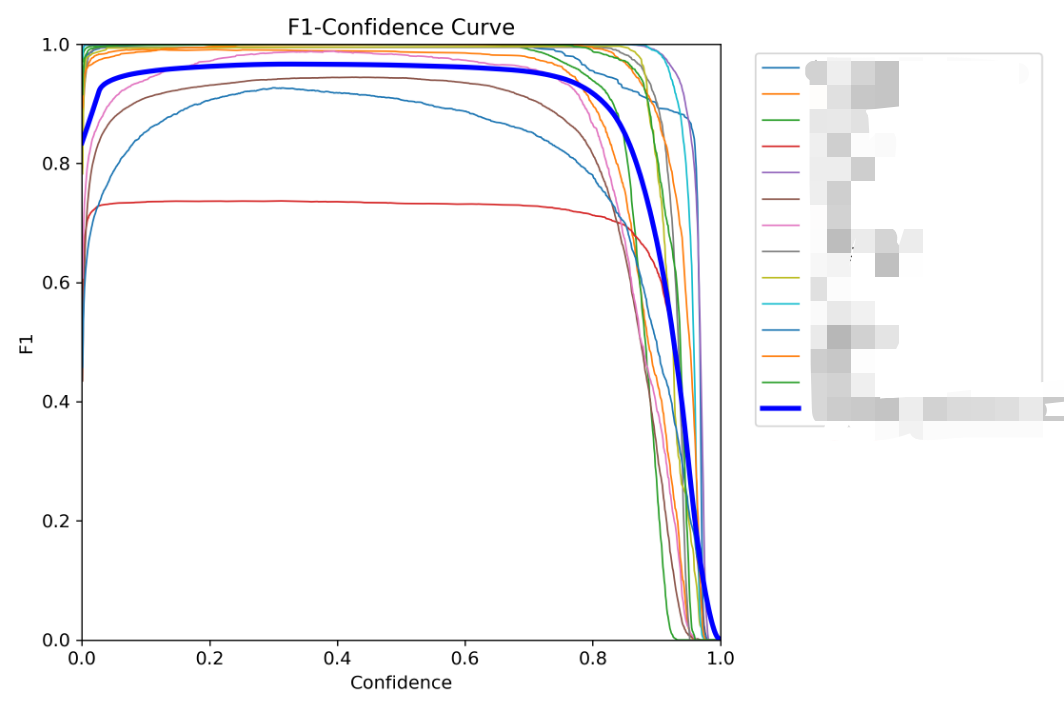
F1 = 2*P*R / P + R ,平衡精确率与召回率的综合指标
6.labels_correlogram.jpg
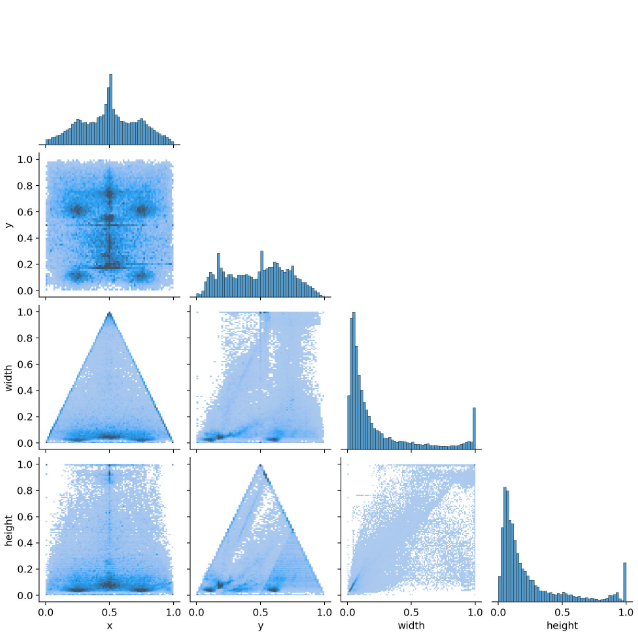
可以通过这张图直观看到数据标签分布情况:哪些标签之间具有较强的相关性,有助于优化模型的训练和预测效果。如果我们发现某些标签之间的相关性过强,可以考虑将它们合并成一个标签,从而简化模型并提高效率。
颜色表示相关性的强弱,颜色越深表示相关性越高。
横纵坐标数值范围表示归一化后的相关性或分布强度。
x轴为水平位置,y轴为垂直位置。举例:无人机一般 y < 0.2(图像上方20%区域内)。
width、height意为像素大小
注意:图中有用的一共就四个图表。
(x,y):中心点分布图。展示目标中心点在图像中的分布,帮助识别目标常出现的位置区域。
- 大量目标靠近边缘 → 考虑标注框是否被截断
- 中心区域目标稀疏 → 需增加该区域样本
(y,width):垂直关系和宽度关系图。分析目标在不同垂直位置时的宽度变化,验证近大远小的透视规律:y值越大(位置越靠下),width通常越大。
- 高位宽目标(y<0.3且width>0.3)→ 可能是飞鸟误标
- 低位窄目标(y>0.8且width<0.1)→ 需检查小目标漏检
(width,height):宽度高度关系图。
- width/height>3 → 可能为错误拉长的标注框
- width≈height且值过大 → 可能误标整个画面为主体
(y,height):垂直关系与高度关系图。图中 y=0.6且height非常小,同时width可以看到也非常小,意味着图像中下部分有大量小检测框,可能是落叶数据集过多导致。
- 若某y区间高度分布单一 → 需添加尺度扰动增强
- 高空目标高度方差小 → 可针对性压缩标注误差阈值
7.labels.jpg
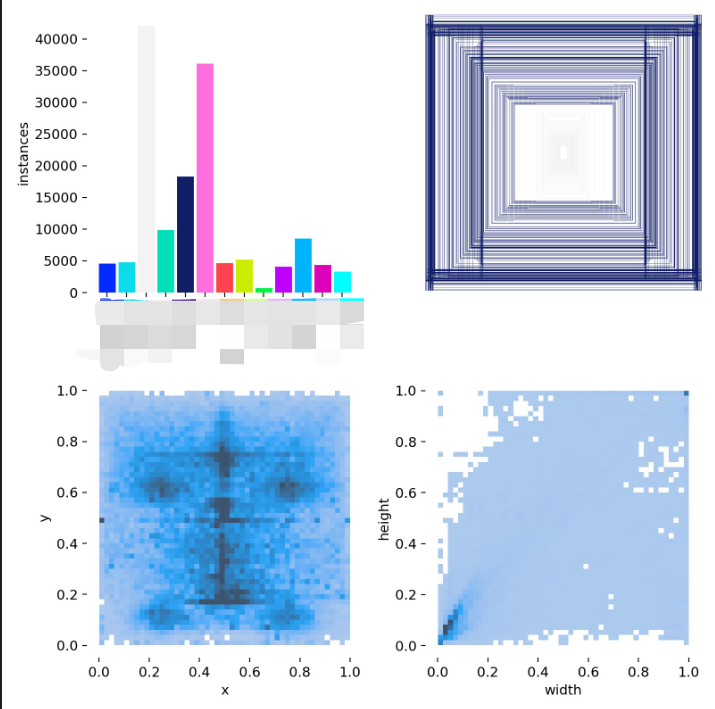
左上图:数据分布情况,可以看到图中dock和leaf的标签数据量远超其它数据集,可能会导致模型识别偏向识别dock和leaf,可能会导致其它小数量集的类别很难建模和识别。
右上图:检测框的尺寸和数量
左下图:检测框中心点相对于全图的位置
右下图:检测框占整幅图的大小
8.P_curve.png
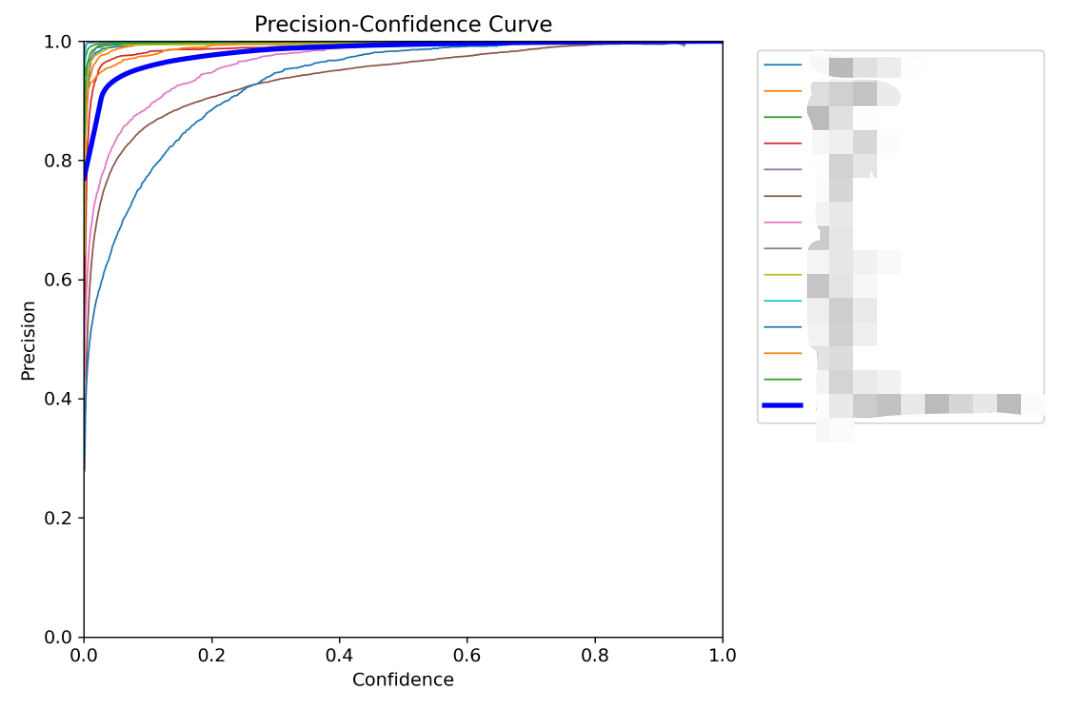
P 曲线,其中 P 为精确率:预测的样本中有多少是实际真实的。
9.PR_curve. png
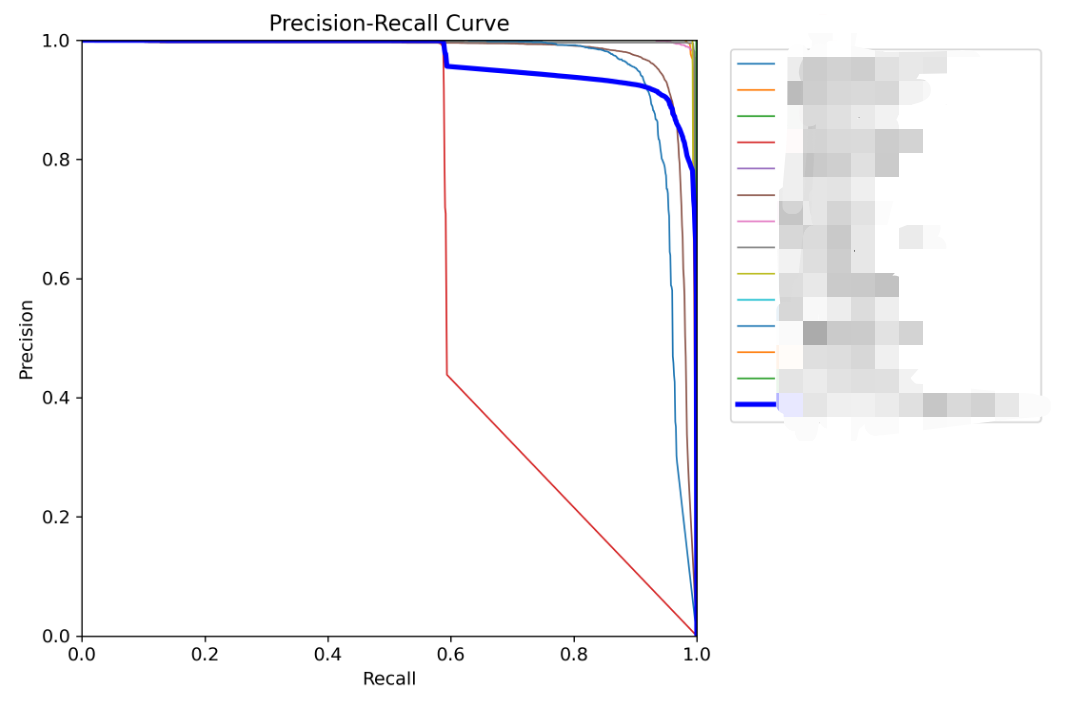
PR 曲线, 即精确率 - 召回率曲线。是评估训练模型的性能指标。
精确率:模型预测为正类的样本中实际为正类的比例
召回率:实际为正类的样本中被正确预测的比例。
越靠近右上角,代表性能越高。
当出现快速下降时,需要检查样本质量。
10.R_curve.png
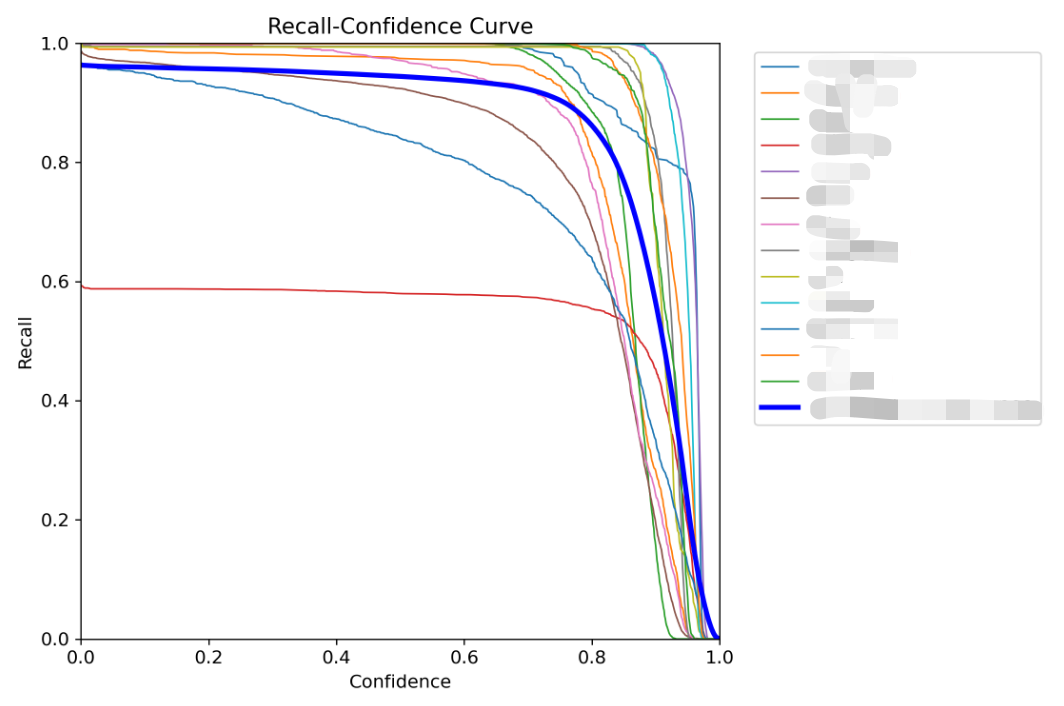
R 曲线,召回率曲线,实际为正类的样本中被正确预测的比例。
11.results.csv
放一丢丢..太多了
epoch,time,train/box_loss,train/cls_loss,train/dfl_loss,metrics/precision(B),metrics/recall(B),metrics/mAP50(B),metrics/mAP50-95(B),val/box_loss,val/cls_loss,val/dfl_loss,lr/pg0,lr/pg1,lr/pg2
1,274.778,3.48685,5.23751,2.84181,0.00098,0.08904,0.00058,0.00017,4.02334,inf,19.6383,0.00332773,0.00332773,0.00332773
2,430.11,2.08612,3.07477,1.82182,0.56143,0.6054,0.59612,0.37044,1.39146,1.50964,1.34317,0.00662809,0.00662809,0.00662809
3,584.761,1.22649,1.33372,1.20918,0.79997,0.72684,0.80048,0.55994,1.04828,0.9956,1.1053,0.00989545,0.00989545,0.00989545
4,738.261,1.00079,0.92408,1.08493,0.89965,0.83716,0.88896,0.69699,0.8405,0.68717,0.97734,0.0098515,0.0098515,0.0098515
5,891.267,0.88013,0.75631,1.03173,0.93169,0.87794,0.91631,0.73602,0.72515,0.58314,0.92421,0.009802,0.009802,0.009802主要观察 metrics/mAP50(B) 和 metrics/mAP50-95(B)
1.mAP50(B):、在 IoU(交并比)阈值为 0.5 时,所有类别(或指定类别组B)的平均精度
- 对每个类别分别计算精确率-召回率曲线(PR曲线)
- 计算曲线下面积(AP值)
- 对所有类别的 AP 值取平均(若标注(B)则限定特定类别组)
- 强调“检测率”
2.mAP50-95(B):在 IoU 阈值从 0.5 到 0.95(步长0.05)区间内,取10个阈值点计算的 mAP 平均值
- 分别在 IoU=0.5, 0.55, 0.6,...,0.95 时计算 AP
- 对所有阈值点的 AP 值取平均
- 强调“精度”
当 mAP50 高但 mAP50-95 低时,模型存在定位偏差(框位置不准但分类正确)
当两者均低 —> 需检查数据质量或模型结构
12.results.png
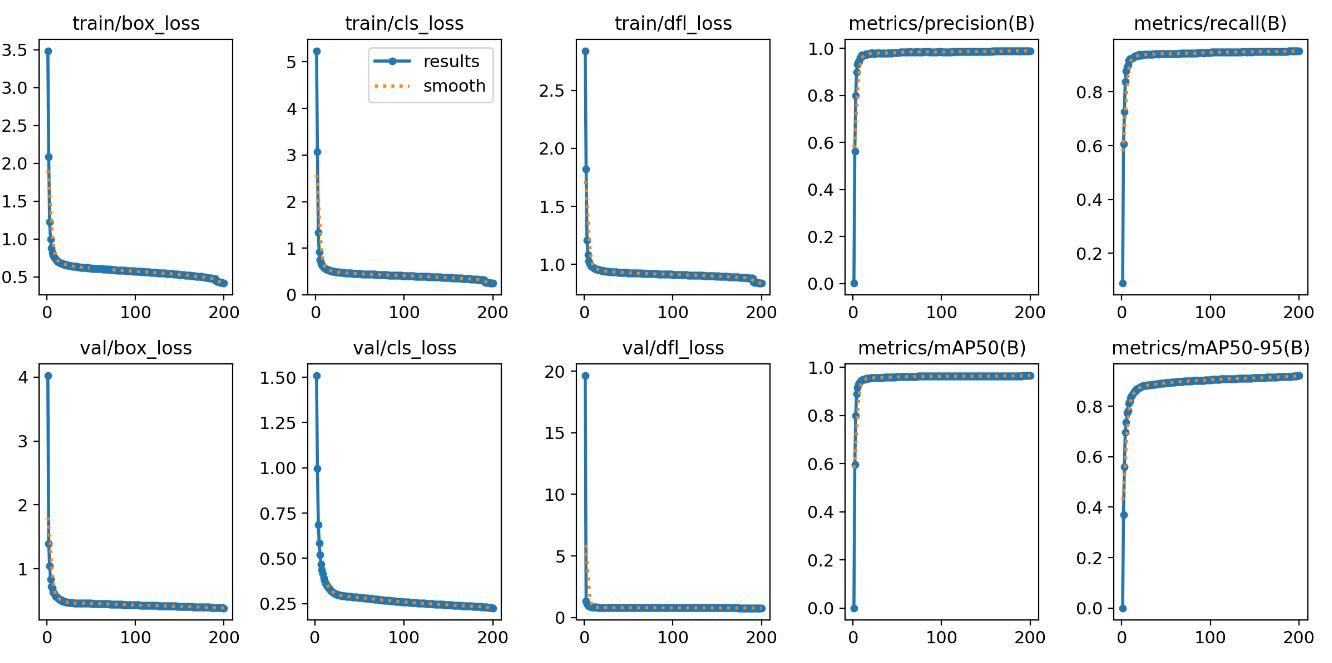
results.csv的图表形式

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}