







读入数据并划分数据集
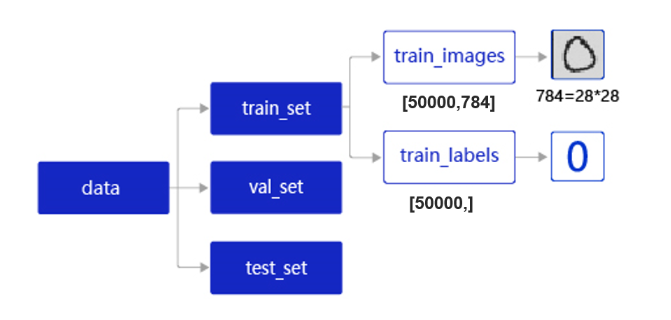
- train_set(训练集):用于确定模型参数。
- val_set(验证集):用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。
- test_set(测试集):用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
train_set包含两个元素的列表:train_images、train_labels。
- train_images:[50 000, 784]的二维列表,包含50 000张图片。每张图片用一个长度为784的向量表示,内容是28*28尺寸的像素灰度值(黑白图片)。
- train_labels:[50 000, ]的列表,表示这些图片对应的分类标签,即0~9之间的一个数字。
这里使用paddle自带的函数就可以自动划分数据集
处理数据
1. 训练样本集乱序
1.1 建立ID集 index_list
1.2 乱序 index_list
1.3 以新顺序读取数据
2. 生成批次数据
2.1 设置batchsize
2.2 数据转变成符合要求的np.array模式
- 数据格式转换(reshape),维数要对应
- 转变成np.array格式
2.3 用Python生成器:yield,减少内存占用
数据不是一次性全部取出,for循环不是一次性全部执行完,而是每次调用只执行一次
- 当函数含有yield,会被系统默认为是一个生成器
- 执行到yield p, 返回p值以及整个生成器处于暂停的状态,并跳出当前函数,执行到调用返回值p的语句
- 当再次执行到这个含有yield的生成器函数时,会自动立即执行到上次暂停的位置继续执行,也就是从yield p这个语句继续执行
# 将数据处理成希望的类型
for i in index_list:
img = np.array(imgs[i]).astype('float32')
label = np.array(labels[i]).astype('float32')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
# 获得一个batchsize的数据,并返回
yield np.array(imgs_list), np.array(labels_list)
# 清空数据读取列表
imgs_list = []
labels_list = []
检验数据有效性
- 机器校验:加入一些校验和清理数据的操作。
- 人工校验:先打印数据输出结果,观察是否是设置的格式。再从训练的结果验证数据处理和读取的有效性。
1. 机器校验
如果数据集中的图片数量和标签数量不等,说明数据逻辑存在问题,可使用assert语句校验图像数量和标签数据是否一致。
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5203
5203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











