






一、RNN神经网络算法原理
1、RNN神经网络的基本结构
RNN由输入层(Input Layer)、隐藏层(Hidden Layer)、输出层(OutputLayer)、时间步(Timesteps)。
①输入层:接收一个序列数据(串行输入)。数据形状为(batch_size,timesteps,input_size),其中batch_size为一个批次中的样本数量,timesteps为序列的时间步长,input_size为每个时间步长的输入特征值。
②隐藏层(核心):主要特点是“记忆”功能。隐藏层中每个神经元都有一个反馈连接,将它当前的输出和之前的状态传达到下一个时间步。公式定义为
其中ht为当前时刻的隐藏状态。ht-1是前一个时刻的隐藏状态。xt是当前时刻的输入。Wh是隐藏状态的权重矩阵,Wx是输入的权重矩阵,b是偏置项。f是激活函数。
③输出层:通过隐藏层的状态映射到预测的输出。它的形式取决任务的类型。公式定义为
其中yt是当前时刻的输出。Wo是输出的权重矩阵,bo是输出的偏置项。
④时间步:RNN处理的是一个时间序列数据,也就是处理大量的时间步。每个时间步的输入数据将传递到网络中,通过循环机制,每个时刻的隐藏状态将传递到下一个时刻。
2、RNN的工作原理
当一个时间步到来,RNN会根据当前时间步的输入和前一个时间步的隐藏状态计算出当前时间步的隐藏状态,并将其传递到下一个时间步。此过程是循环的,因此RNN能够捕捉到序列数据的时序依赖性。如下图1.2
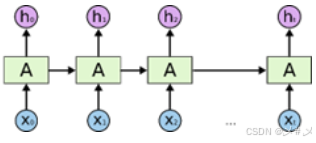
图1.2 RNN神经网络运行图
①RNN神经网络前向(正向)传播:就是上面RNN的基本工作原理。
②RNN神经网络反向传播(重点):1正向传播、2计算损失、3反向传播。
【1】正向传播:首先,进行标准的前向传播,计算出每个时间步的隐藏状态ht和输出yt。
【2】计算损失:在最后时间步t=T,计算网络的损失函数L,如均方误差(MSE)。
【3】反向传播(BPTT):从最后一个时间步T开始,通过反向传播来计算每个时间步的梯度,并将其传递回去更新模型的参数(如权重和偏置)。算法中有大量数学公式推动,此处省略。
3、RNN神经网络的主要特点
①共享权重:RNN在每一个时间步共享相同的权重,也就是说无论处理多长的序列,模型的参数都不会增加。
②循环连接:每个时间步的输出不仅与当前的输入有关,还与前一个时间步的状态(隐藏层输出)有关。
4、RNN的变种
补充:标准的RNN存在一个问题:梯度消失或者梯度爆炸。
①梯度消失:在长序列中,梯度通过每个时间步传递时,可能变得非常小,导致更新变得非常缓慢,甚至无法学习。
②梯度爆炸:当梯度通过多个时间步传递时,可能会逐渐增大,导致权重更新过大,从而使得训练不稳定,甚至无法收敛。
为了解决这就问题,研究者提出了多种变种RNN架构:
【1】LSTM(Long Short-Term Memory):LSTM是一种特殊的RNN变种。LSTM通过门控制机制来控制信息流动,允许它在较长时间内“记住”信息,从而避免了梯度消失问题。
【2】GRU(Gated Recurrent Unit):GRU是一种常见的饿RNN变体,比LSTM简单,也可以有效的解决梯度消失问题。GRU也使用门控制机制来决定那些信息应该传递到下一时刻。
5、LSTM为什么比GRU更受欢迎
尽管GRU在某些场景下更为高效,特别是在需要较少计算的情况下。LSTM由于其更强的建模能力、长时间记忆保持、灵活记忆保持、灵活性和广泛的应用支持,通常更受欢迎。
二、LSTM神经网络算法原理
1、LSTM的基本结构
LSTM是通过三个门(输入门、遗忘门、输出门)和一个单元状态(cell state)来控制信息流:
①输入门(Input Gate):控制当前输入信息对当前单元状态的影响。
②遗忘门(Forget Gate):决定了上一时刻的单元状态中有多少信息需要被遗忘。
③输出门(Output Gate):决定了当前的单元状态Ct中有多少部分将传递下一个时间步的隐藏状态。
2、LSTM的工作原理
LSTM通过四个主要步骤来更新其状态和输出,如下图2.2:
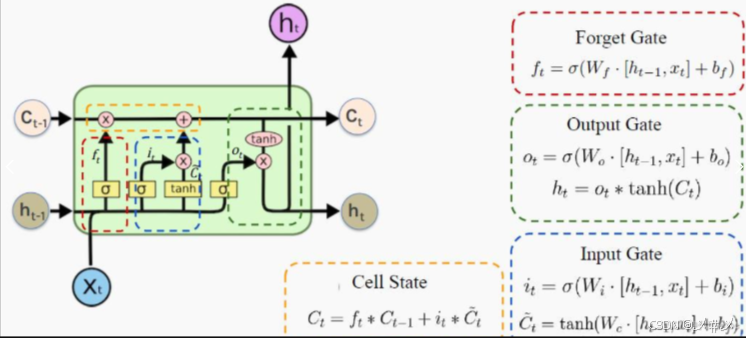
图2.2 LSTM神经网络单元图
(1)遗忘门(Forget Gate)
遗忘门的输入是当前时刻的输入Xt和上一时刻的隐藏状态ht-1,并通过一个sigmoid激活函数来输出一个介于0和1之间的值。这个值表示了保留多少信息,1表示完全保留,0表示完全遗忘。公式如下:
其中,ft是遗忘门的输出,是Sigmoid函数。
(2)输入门(Input Gate)
输入门控制了当前输入xt和上一时刻的隐藏状态ht-1对当前单元状态Ct的影响。首先,输入门使用Sigmoid激活函数决定那些信息被更新,然后通过Tanh激活函数生成候选的更新值(即新的信息)。公式为
其中,it是输入门的输出,Ct是候选单元状态。
(3)更新单元状态(Cell State)
通过遗忘门的输出ft和输入门的输出it,LSTM更新当前的单元状态Ct.遗忘门将上一时刻的单元状态Ct-1进行加权遗忘,输入门则决定了当前时刻的候选更新值Ct对单元状态的贡献。
(4)输出门(Output Gate)
输出门决定了当前时刻的单元状态Ct有多少部分传递到下一时间步的隐藏状态ht。首先,使用Sigmoid激活函数决定输出多少信息,然后将单元状态Ct经过Tanh激活函数处理后,再与输出门的结果相乘,得到最终的隐藏状态ht。公式为
其中,ot是输出门的输出,ht是当前的隐藏状态
三、实战——RNN、LSTM神经网络单特征数据预测
补充:
本项目的编译环境为python==3.8、tensorfiow==2.4.0、keras==2.4.3、numpy==1.19.5、pandas==1.3.5、matplotlib==3.4.2、sklearn==0.0
1、数据读取
这就找一个数据集进行简单的加载数据,并通过print打印查看是否加载成功。如下图3.1
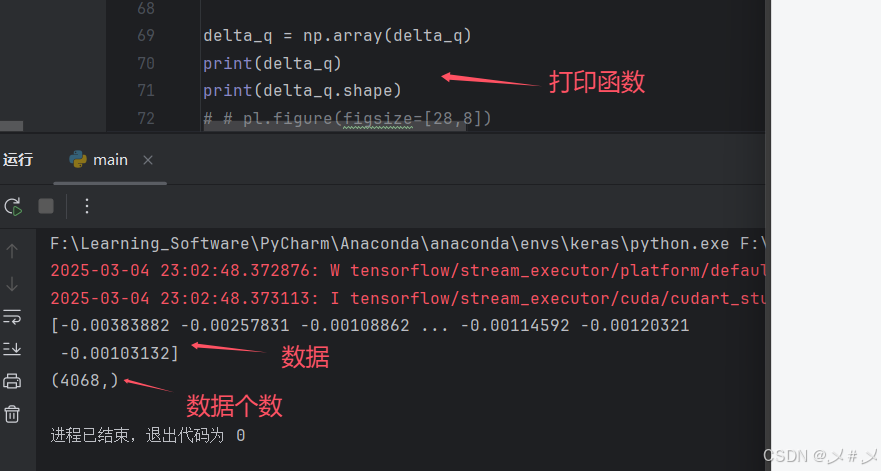
图3.1 加载数据
2、数据预处理
①数据分成测试集和训练集,并将数据进行归一化处理。如下图3.2
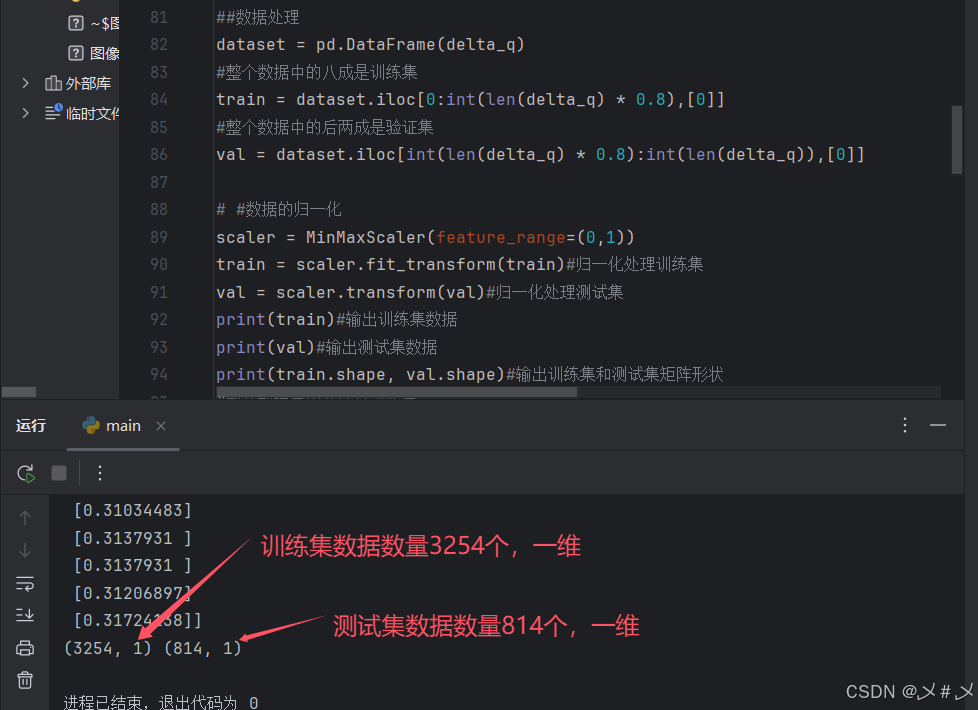
图3.2 数据处理图1
代码如下:
##数据处理
dataset = pd.DataFrame(delta_q)
#整个数据中的八成是训练集
train = dataset.iloc[0:int(len(delta_q) * 0.8),[0]]
#整个数据中的后两成是验证集
val = dataset.iloc[int(len(delta_q) * 0.8):int(len(delta_q)),[0]]
# #数据的归一化
scaler = MinMaxScaler(feature_range=(0,1))
train = scaler.fit_transform(train)#归一化处理训练集
val = scaler.transform(val)#归一化处理测试集
# print(train)#输出训练集数据
# print(val)#输出测试集数据
# print(train.shape, val.shape)#输出训练集和测试集矩阵形状②特征与标签划分
自问:为什么要这样划分特征与标签?
答:LSTM网络的设计目的是捕捉数据中的时间依赖性。通过这样的划分,可以将时间序列数据转化为适合LSTM网络处理的格式,让模型通过学习过去85个时间步的数据来预测下一个时间步的值(通过这样的划分,模型可以学习到时间序列中的时序依赖性,进而预测未来的值)。
将原来数据进行特征与标签的划分,如下图3.2
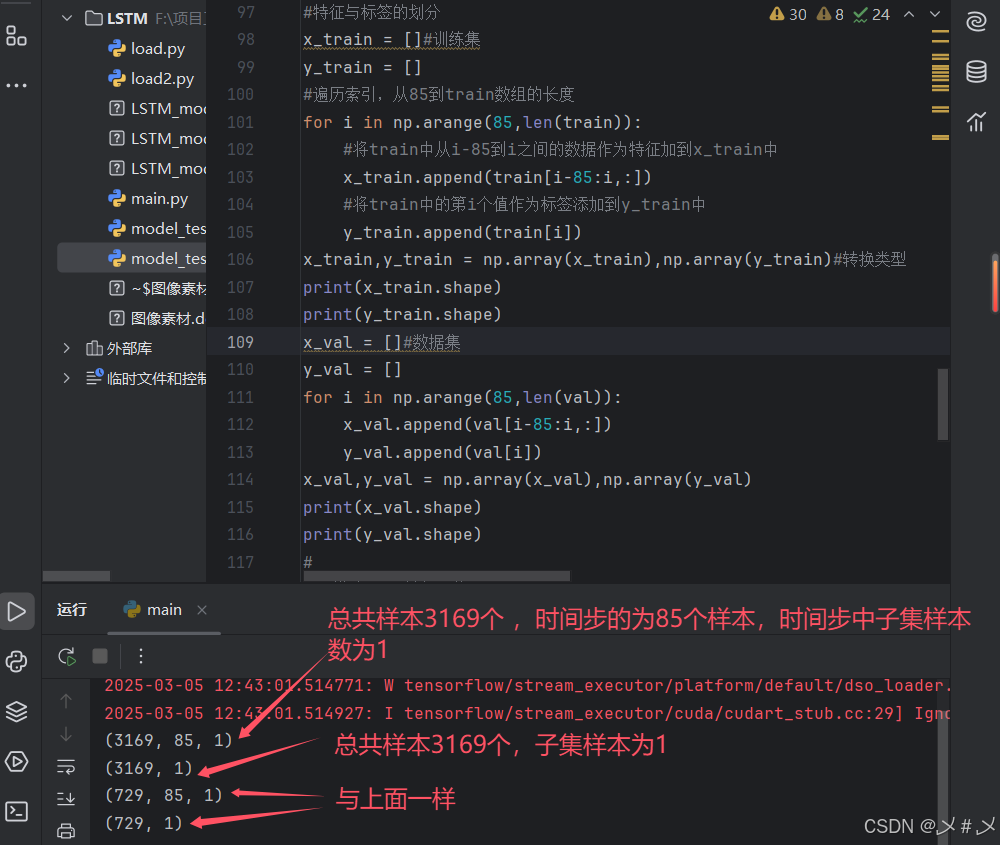
图3.2 数据处理图2
代码如下:
#特征与标签的划分
x_train = []#训练集
y_train = []
#遍历索引,从85到train数组的长度
for i in np.arange(85,len(train)):
#将train中从i-85到i之间的数据作为特征加到x_train中
x_train.append(train[i-85:i,:])
#将train中的第i个值作为标签添加到y_train中
y_train.append(train[i])
x_train,y_train = np.array(x_train),np.array(y_train)#转换类型
# print(x_train)
# print(y_train)
# print(x_train.shape)
# print(y_train.shape)
x_val = []#数据集
y_val = []
for i in np.arange(85,len(val)):
x_val.append(val[i-85:i,:])
y_val.append(val[i])
x_val,y_val = np.array(x_val),np.array(y_val)
# print(x_val.shape)
# print(y_val.shape)3、搭建LSTM神经网络与绘制训练集与测试集的loss图
①导入必要的库(下载并安装库【这里不讲安装库】),本项目中用到的模块。代码如下:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import tensorflow.keras as keras
②搭建LSTM模型,代码如下:
自问:为什么LSTM神经网络训练过程中,该层的输出空间维度为10,为什么不是85?
答:10表示该层的输出空间维度(也称隐藏层的单元数或者神经元数【也就是隐藏层的矩阵维度{一个维度代表一个数据特征}】)。较小的维度可以避免过拟合,使得训练过程更稳定。较小的维度可以减小计算量,从而节约电脑资源。
自问:在history中,为什么还要validation_data=(x_val, y_val),不是都有设置标签验证了吗,为什么还要验证集来验证?
答:在模型训练过程中使用的验证集,目的是为了帮助我们评估模型在训练过程中的泛化能力。在训练过程中使用验证集,用于调节超参数(如学习率、层数、节点数),防止过拟合,帮助判断模型是否能在看不见的数据上做出准确预测。
#搭建LSTM神经网络
#Sequential是定义一个顺序模型,模型中的层会按顺序堆叠
model = Sequential()
#10表示该层的输出空间的维度(也就是说初始化设置10个特征空间),return_s是true表示输出为序列,relu为激活函数
model.add(LSTM(10,return_sequences=True,activation='relu')) #第一层网络
model.add(LSTM(15,return_sequences=False,activation='relu'))#第二层网络
model.add(Dense(10,activation='relu'))#全连接层
#输出层只有一个神经元,通常用于回归任务(预测一个连续值),这里没有指明激活函数,默认线性激活
model.add(Dense(1))#输出层
#选择Adam优化器,0.01是学习率,学习率过大可能无法收敛,过小可能训练速度过慢
#loss=‘mse’ 损失函数为均方误差
model.compile(optimizer=keras.optimizers.Adam(0.01),loss='mse')#优化器
#训练模型 150轮数,64为每个批次的样本数
#validation_data=(x_val,y_val)表示没训练完一个轮次后,在验证集上进行评估,计算验证集的损失
history = model.fit(x_train,y_train,epochs=150,batch_size=64,validation_data=(x_val,y_val))
#模型的保存
model.save("LSTM_model_true.h5")③绘制训练集和测试集的loss值对比图
#绘制训练集和测试集的loss值对比图
#创建一个大小为(12,8)的画布
pl.figure(figsize=[12,8])
#传入训练集的loss和验证集的loss
plt.plot(history.history['loss'],label='train_loss')
plt.plot(history.history['val_loss'],label='val_loss')
#设置图的参数,设置图的名字
plt.title('LSTM神经网络loss值',fontsize=15)
#设置xy轴的刻度值大小
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
#设置xy轴的标签
plt.xticks('loss值',fontsize=15)
plt.yticks('循环次数',fontsize=15)
#设置图例文字大小
plt.legend(fontsize=15)
plt.show()loss图如下3.3
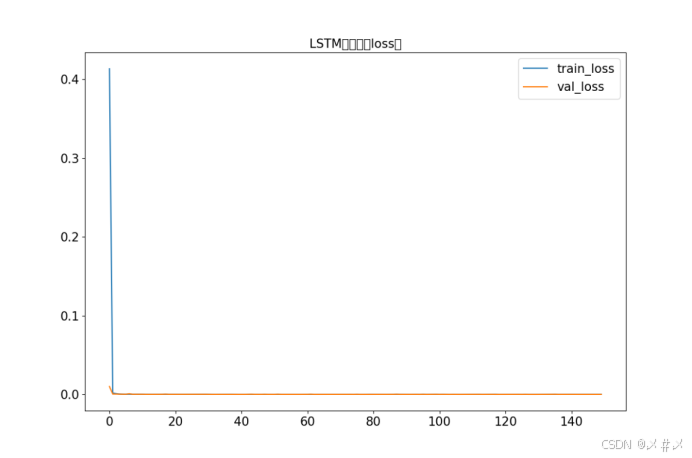
图3.3 LSTM神经网络loss对比图
4、模型的测试与评估
①模型的测试,代码如下(不包含数据加载部分)
#数据处理
dataset1 = pd.DataFrame(delta_q)
delta_q = dataset1.iloc[0:int(len(delta_q)*0.1),[0]]
#数据的归一化
scaler = MinMaxScaler(feature_range=(0,1))
delta_q = scaler.fit_transform(delta_q)
#特征与标签的划分
x_val = []
y_val = []
for i in np.arange(85,len(delta_q)):
x_val.append(delta_q[i-85:i,:])
y_val.append(delta_q[i])
x_val,y_val = np.array(x_val),np.array(y_val)
# print(x_val.shape)
# print(y_val.shape)
model = load_model('LSTM_model_true.h5')
#利用训练好的模型进行测试
predicted = model.predict(x_val)
#反归一化
predicted = scaler.inverse_transform(predicted)
real = scaler.inverse_transform(y_val)
#创建一个大小为(12,8)的画布
pl.figure(figsize=[12,8])
#传入数据
plt.plot(predicted,label='predicted')
plt.plot(real,label='real')
#设置图的参数,设置图的名字
plt.title('LSTM',fontsize=15)
#设置xy轴的刻度值大小
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
#设置xy轴的标签
# plt.xticks('loss值',fontsize=15)
# plt.yticks('循环次数',fontsize=15)
#设置图例文字大小
#设置xy轴的标签
plt.legend(loc='best',fontsize=15)
plt.ylabel('data',fontsize=15)
plt.xlabel('time',fontsize=15)
plt.show()测试图如下3.4
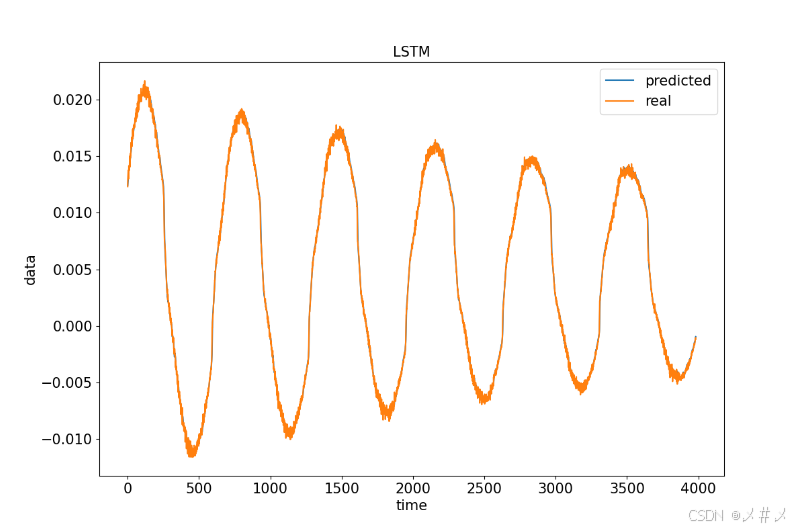
图3.4 全部数据(不是训练集数据)图1
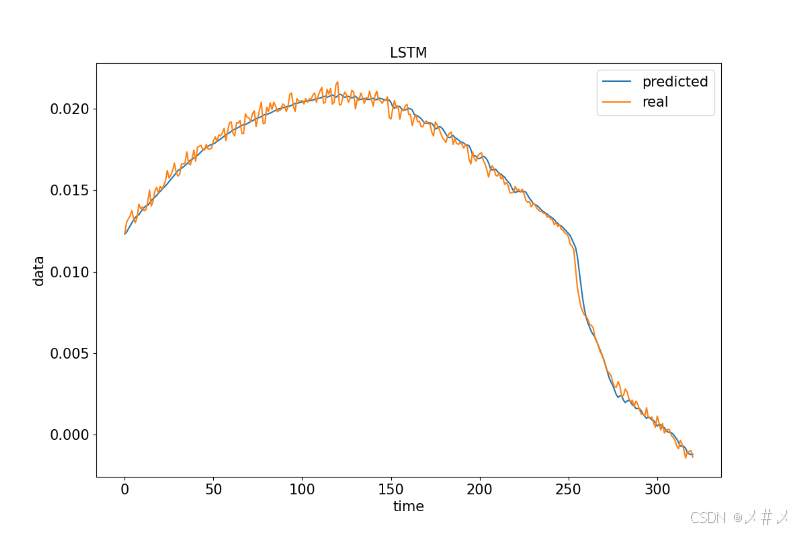
图3.4 局部数据(不是训练集数据)图2
②模型的评估,采用 (决定系数),MAE(平均绝对误差),RMSE(均方根误差)、MAPE(平均绝对百分比误差)代码如下,图如下3.4
(决定系数),MAE(平均绝对误差),RMSE(均方根误差)、MAPE(平均绝对百分比误差)代码如下,图如下3.4
R2 = r2_score(real,predicted)
MAE = mean_absolute_error(real,predicted)
RMSE = np.sqrt(mean_squared_error(real,predicted))
MAPE = np.mean(abs(real - predicted) / real)
print('R2', R2)
print('MAE', MAE)
print('RMSE', RMSE)
print('MAPE', MAPE)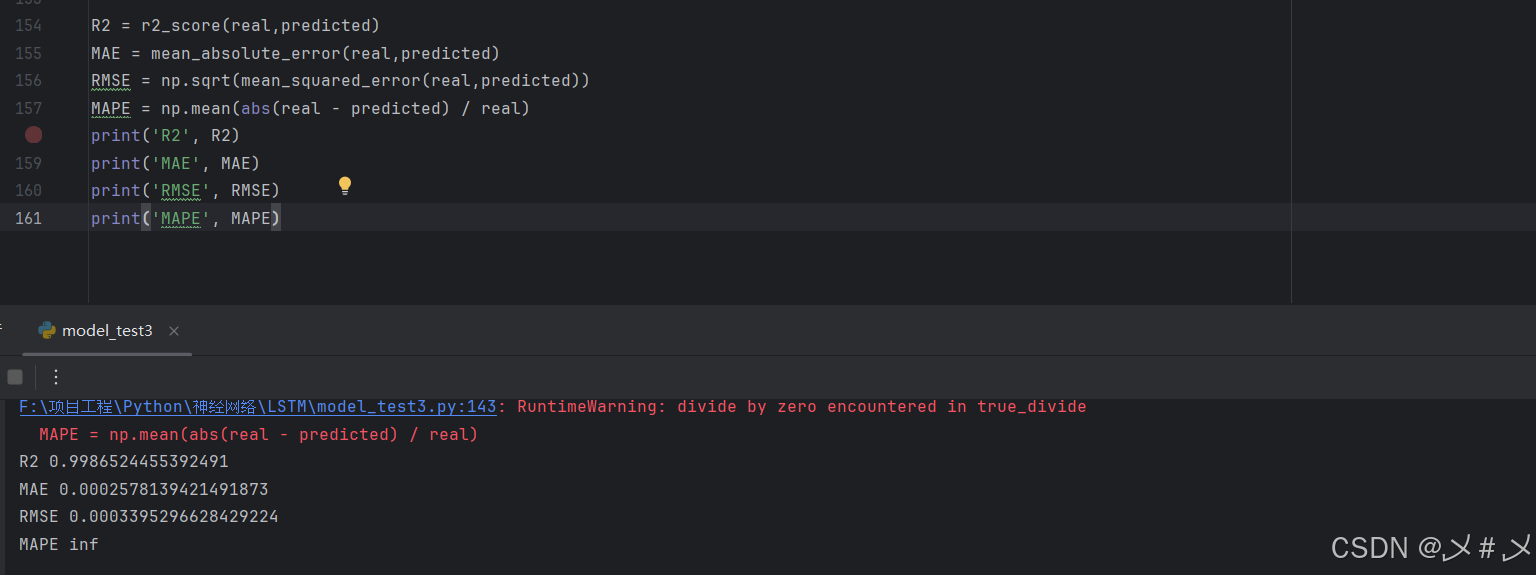
图3.4 模型的性能指标图
四、总结
通过学习RNN、LSTM神经网络,对数据的处理方法有了更多的选择,也认识到算法的美妙之处。通过记录学习过程,使得我有更深刻的学习经历,对该算法有了更深的认识。感谢其他博主和up主的分享使我学习该算法更轻松。

















 3236
3236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









