







特征工程
特征工程在机器学习中占据核心地位,它涉及从原始数据中提取有价值的信息,以优化和提高模型的性能。本节旨在深入探讨特征工程的基础理论和实践应用。
特征工程的重要性
特征工程是构建机器学习模型过程中的关键步骤。优质的特征不仅可以显著提高模型的性能,还能减少所需的数据量,从而在处理复杂数据时提高效率和准确性。
特征工程的一般做法
在进行特征工程时,首先需要识别并分类数据特征的类型。主要类型包括连续特征、离散特征、序列特征和多模态特征。本节将主要聚焦于连续特征和离散特征的处理方法。
连续特征的特征工程
连续特征通常是数值型的,可以再任意两个值之间取无数个数值。常见的连续特征处理方法包括:
- 特征间的二元数学运算:例如,通过特征的加、减、乘、除来创建新的特征。例如,若有特征表示房屋的宽度和长度,可以通过它们的乘积来创建一个表示面积的新特征。
- 单个特征的处理:
- 标准化:调整特征数据,使其均值为 0,标准差为 1,有助于加速学习算法的收敛,公式:
。
- 归一化:将特征缩放到给定的最小值和最大值之间,常用于将特征值限制在 0 和 1 之间,公式:
- 其他数学变换:如对数变换,有助于处理偏态分布的数据。
- 离散化:将连续特征分割成若干区间,转换为离散特征。常见方法包括等频(每个区间含有相同数量的点)和等距(每个区间长度相同)。
- 标准化:调整特征数据,使其均值为 0,标准差为 1,有助于加速学习算法的收敛,公式:
离散特征的特征工程
离散特征通常是分类,表示为一组有限的类别。处理离散特征的重用方法包括:
- 特征对的处理:
- 特征交叉:结合两个或多个特征创建新特征,例如,结合“城市”和“职业”特征来预测收入。
- Group特征:根据一个或多个特征进行分组,然后对每组进行汇总统计,如计算平均值、最大值或计数。
- 单个特征的处理:
- 标签编码(Label Encoding):将类别标签转换为序列数字。
- 独热编码(One-Hot Encoding):为每个类别创建一个新的二进制特征。
- 目标编码(Target Encoding):基于目标变量的平均值对类别进行编码。
- 计数编码(Count Encoding):基于每个类别出现的频率进行编码。
特征工程实践
import pandas as pd
import numpy as np
from faker import Faker
from datetime import datetime, timedelta
from tqdm import tqdm
from sklearn.preprocessing import OneHotEncoder
from category_encoders.hashing import HashingEncoder
# 设置要显示的行数和列数
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 50)# 初始化工具
fake = Faker()
np.random.seed(42)
# 生成100行数据
data = {
# 用户信息
"user_id": [fake.uuid4()[:8] for _ in range(100)], # 8 位用户标识
"age": np.random.randint(18, 70, 100), # 用户年龄
"gender": np.random.choice(["M", "F", "Other"], 100, p=[0.45, 0.5, 0.05]), # 性别分类
"membership_status": np.random.choice(["Active", "Inactive"], 100, p=[0.7, 0.3]), # 会员状态
# 产品信息
"product_id": [f"P{str(i).zfill(5)}" for i in range(1000, 1100)], # 产品唯一 ID
"category": np.random.choice(["Tops", "Bottoms", "Dresses", "Outerwear", "Accessories"], 100), # 商品分类
"color": np.random.choice(["Red", "Black", "White", "Blue", "Beige"], 100), # 商品颜色
"size": np.random.choice(["XS", "S", "M", "L", "XL"], 100), # 商品尺码
"price": np.round(np.random.uniform(19.9, 199.9, 100), 2), # 商品价格
# 交易行为
"purchase_date": [fake.date_between(start_date='-1y', end_date='today') for _ in range(100)], # 购买日期
"quantity": np.random.randint(1, 4, 100), # 购买数量
"sales_channel": np.random.choice(["Online", "In-store"], 100, p=[0.6, 0.4]), # 销售渠道
"promo_code": np.random.choice(["SPRING20", "SUMMER15", "None"], 100, p=[0.3, 0.2, 0.5]), # 销售代码
# 交互特征
"rating": np.random.randint(1, 6, 100), # 用户评分(1-5)
"return_flag": np.random.choice([0, 1], 100, p=[0.85, 0.15]), # 退货标志
"region": np.random.choice(["NA", "EU", "APAC"], 100, p=[0.4, 0.4, 0.2]) # 销售地区
}
# 创建DataFrame
df = pd.DataFrame(data)
# 添加价格相关性逻辑
df.loc[df['category'] == "Accessories", "price"] = np.round(df["price"] * 0.6, 2)
df.loc[df['category'] == "Outerwear", "price"] = np.round(df["price"] * 1.3, 2)
# 保存数据
df.to_csv("hm_style_data.csv", index=False)
print("生成数据示例:")
df.head()
连续特征的特征工程实践
# 连续特征
def num_add(df, f1, f2):
# add
df[f'{f1}_add_{f2}'] = df[f1] + df[f2]
return df
def num_mul(df, f1, f2):
# mul
df[f'{f1}_mul_{f2}'] = df[f1] * df[f2]
return df
def num_div(df, f1, f2):
# div
df[f'{f1}_div_{f2}'] = df[f1] / (df[f2] + df[f2].mean()) # 加一个平滑,防止 f2 取值为 0
return df
def num_log(df, f):
# log
df[f'log_{f}'] = np.log(1 + df[f])
return df
def num_bin(df, f, num_bins=10, bin_type='cut'):
# bin
if bin_type == 'cut':
df[f'{f}_bin_{num_bins}'] = pd.cut(df[f], num_bins, labels=False) # 按数值范围均匀分箱,等距
else:
df[f'{f}_bin_{num_bins}'] = pd.qcut(df[f], num_bins, labels=False) # 按样本分位数分箱,等频
return dfdf = num_bin(df, 'age', 10, bin_type='qcut')
df.head()
离散特征的特征工程实践
# 离散变量特征工程
def one_hot_enc(df, f):
# one-hot
enc = OneHotEncoder()
enc.fit(df[f].values.reshape(-1, 1))
one_hot_array = enc.transform(df[f].values.reshape(-1, 1)).toarray()
df[[f'{f}_one_hot_{i}' for i in range(one_hot_array.shape[-1])]]= one_hot_array
return df
def hash_enc(df, f_list, n_components=8):
# hash enc
ce_encoder = HashingEncoder(cols=f_list, n_components=n_components).fit(df) # hash_method='md5' # 哈希算法(可选:'md5', 'sha1', 'sha256')
df = ce_encoder.transform(df)
df.rename(columns=dict(zip([f'col_{i}' for i in range(n_components)], [f'hash_enc_{i}' for i in range(n_components)])), inplace=True)
return df
def count_enc(df, f):
# count enc
map_dict = dict(zip(df[f].unique(), range(df[f].nunique())))
df[f'label_enc_{f}'] = df[f].map(map_dict).fillna(-1).astype('int32')
df[f'{f}_count'] = df[f].map(df[f].value_counts())
return df
def cross_enc(df, f1, f2):
# cross enc
print('====================================== {} {} ======================================'.format(f1, f2))
if f'{f1}_count' not in df.columns:
df = count_enc(df, f1)
if f'{f2}_count' not in df.columns:
df = count_enc(df, f2)
df[f'{f1}_{f2}'] = df[f1].astype('str') + '_' + df[f2].astype('str')
df = count_enc(df, f'{f1}_{f2}')
df[f'{f1}_{f2}_count_div_{f1}_count'] = df[f'{f1}_{f2}_count'] / (df[f'{f1}_count'] + df[f'{f1}_count'].mean())
df[f'{f1}_{f2}_count_div_{f2}_count'] = df[f'{f1}_{f2}_count'] / (df[f'{f2}_count'] + df[f'{f2}_count'].mean())
del df[f'{f1}_{f2}']
return df
def group_stat(df, cat_fea, num_fea):
for stat in tqdm(['min', 'max', 'mean', 'median', 'std', 'skew']):
df[f'{cat_fea}_{num_fea}_groupby_{stat}'] = df.groupby(cat_fea)[num_fea].transform(stat)
return dfdf = one_hot_enc(df, 'region')
df[[f'region_one_hot_{i}' for i in range(df['region'].nunique())]].head()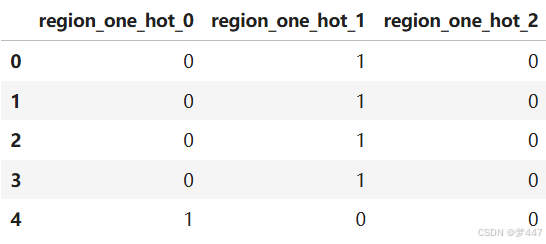
df = hash_enc(df, ['category', 'color', 'size'])
df[[f'hash_enc_{i}' for i in range(8)]].head()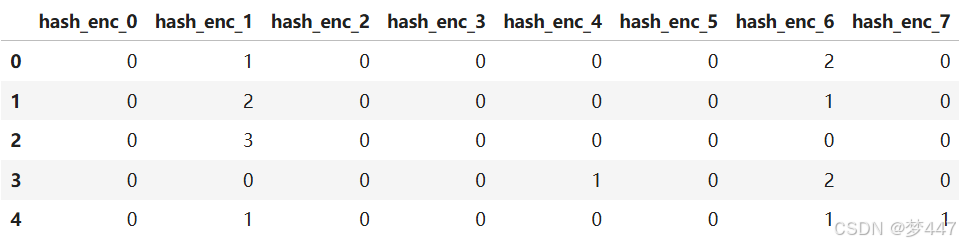
# 离散特征编码
cate_fea_list = ['user_id','product_id','sales_channel', 'promo_code']
# label enc & count enc
for col in tqdm(cate_fea_list):
df = count_enc(df, col)![]()
# 交叉特征
df = cross_enc(df, 'user_id', 'product_id')
df = cross_enc(df, 'user_id', 'promo_code')
df = cross_enc(df, 'age', 'product_id')![]()
# group 特征
df = group_stat(df, 'user_id', 'price')
df = group_stat(df, 'age', 'price')![]()
df.info()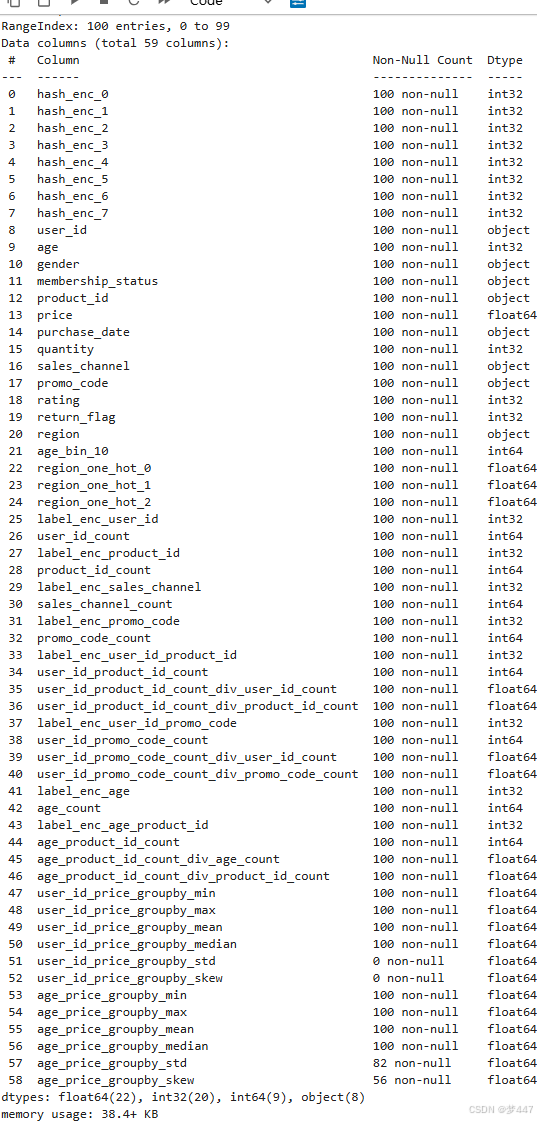


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









