






算法原理:
在线性模型的基础上套一个映射函数来实现分类功能,最终的输出其实是一个概率
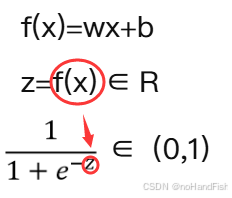
以一个二分类任务为例设正例为1,负例为0;设正例概率为p,则取负例的概率为1-p
损失函数的极大似然推理:
确定概率密度函数:

回想多元函数那届我们为w和x增加维度,便有了下面的式子:
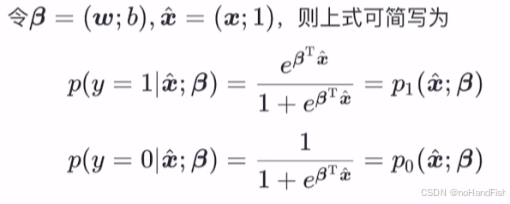
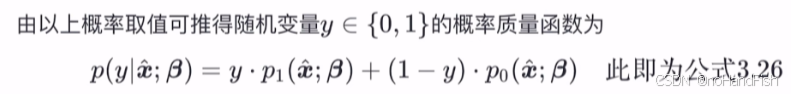
其实只要是满足y取1时,就用p1;y取0时就用p0即可;这是依据我们前一步推导所能想到的。
似然函数:
写出似然函数:
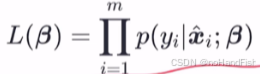
取对数变乘为加:
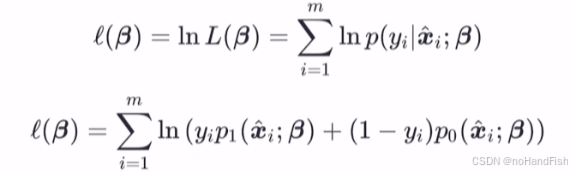
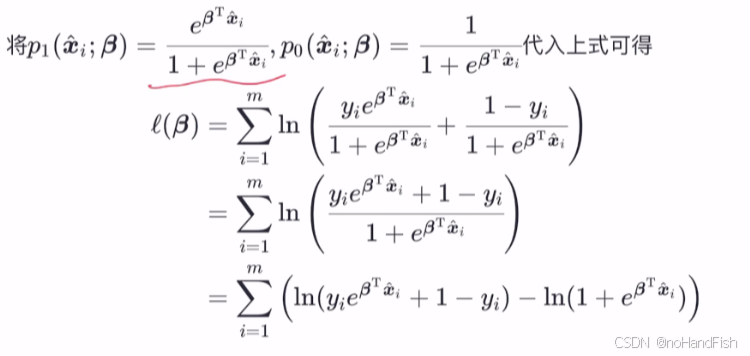

损失函数的信息论推导:
信息论基本概念:

例1:信息熵,若x有两种取值a,b,如果我确定取值一定为a,那么它的信息熵就是很小的;如果取a值的概率为1/2,b值的概率为1/2,则信息熵较高;若a为3/4,b为1/4,则信息熵较一定取a值的情况高,较a的概率为1/2的概率低。


想象极端情况p(x)就是q(x),那么下式值就为0:
![]()
例2:



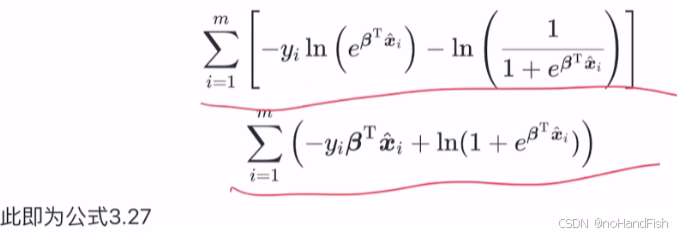
到此两种方法,殊途同归。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









