







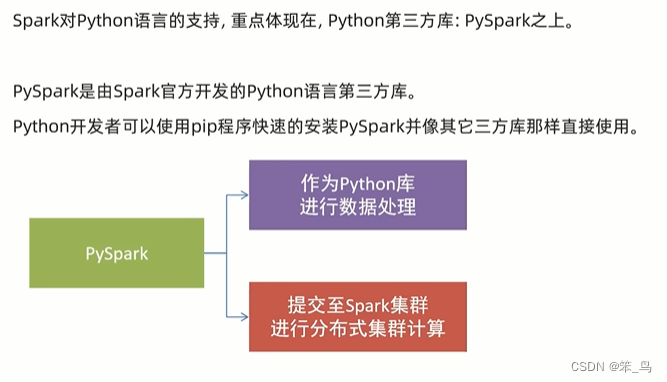
spark是用于大规模数据处理的统一分析引擎
简单来说,spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据
先学Hadoop然后学spark

构建pyspark执行环境入口对象
想要使用pyspark库完成数据处理,首先需要构建一个执行环境入口对象
pyspark的执行环境入口对象是:类sparkcontext的类对象
是写代码的唯一入口

setMaster是设置运行模式
sc是执行环境入口对象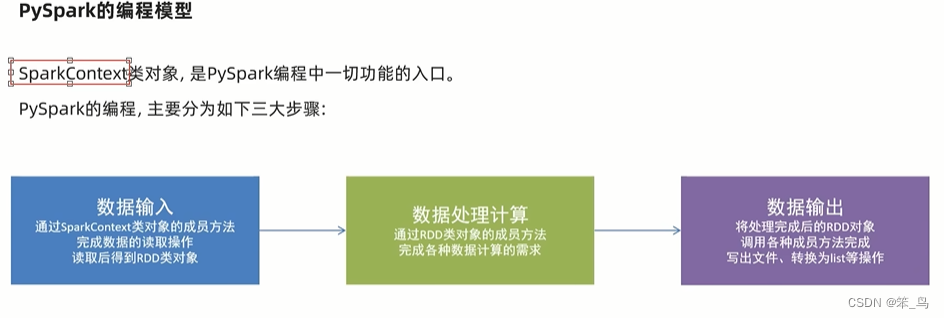


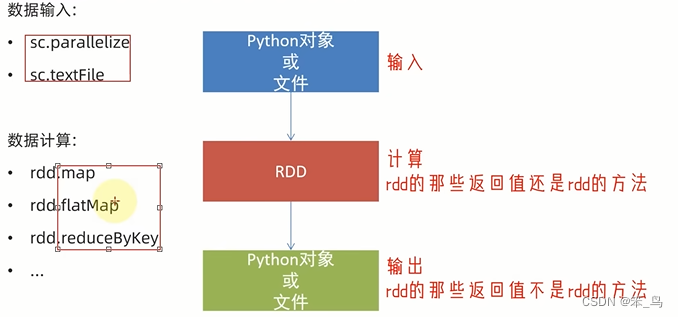
数据输入
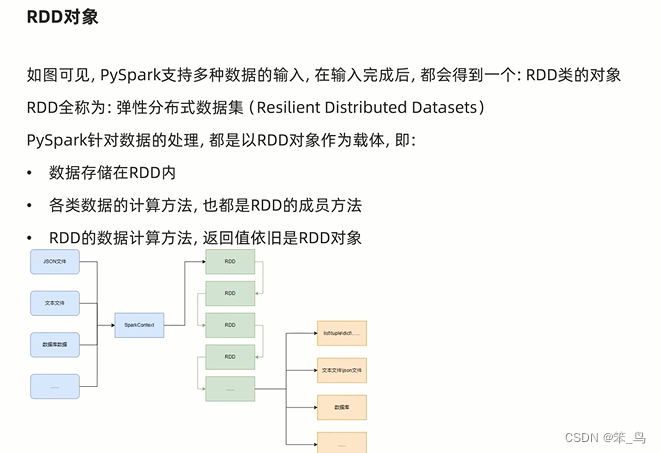
数据输入到spark中会得到RDD对象,RDD是数据集
数据计算是对RDD进行计算

如果要看RDD中有什么内容,需要用collect()方法


数据计算
map方法

map算子即map方法

from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5 )
print(rdd2.collect())
sc.stop()flatmap方法

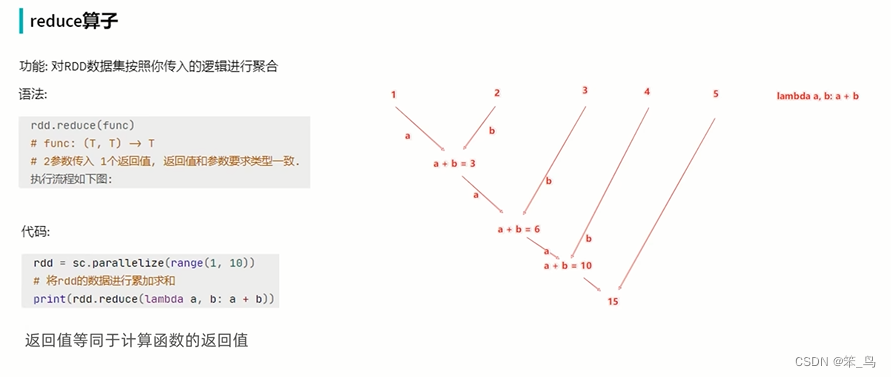
reduceByKey方法

kv型就是二元元组,即每个元素中有两个元素
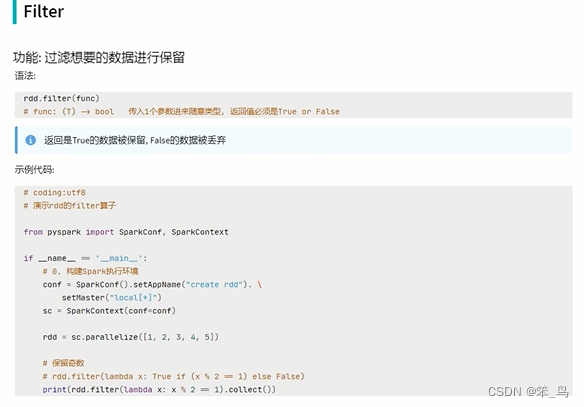
filter方法
distinct方法

sortby方法

数据输出
输出为python对象




输出到文件


















 9058
9058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









