









文章目录
前言
从接触强化学习起,就一直知道强化学习可以打游戏,什么alphago,打星际争霸,后来知道大部分环境是专门写的用来供强化学习做实验的,是可以直接从环境中读取一些关键信息,并不是像人一样,只把当前在游戏中看到的图片当做当前的状态(当然,现在已经有研究这种的agi了)
于是这里想使用强化学习来非侵入式打游戏。
这里的非侵入式就是不读取游戏里的内存状态,而是像人一样打游戏。
当然这样游戏也就不会判断你在作弊了。
ps:正好今天写博客三周年,纪念一下
参考:
1.https://github.com/analoganddigital/DQN_play_sekiro(DQN玩只狼,其中这个博主应该也没有训练到完全打过,只是给出了方法步骤)
2.https://gist.github.com/karpathy/a4166c7fe253700972fcbc77e4ea32c5(130行numpy玩atari的pong)
大多数我搜索到的用强化学习玩像素小鸟基本都是直接得到小鸟的直接距离管道的状态,就像是访问到游戏里的内存,这个不是我目前想实现的。
最终实现:用PPO玩像素小鸟
代码开源在:https://github.com/wild-firefox/FreeRL_for_play/tree/main/play_FlappyBird(欢迎star)
这里的像素小鸟游戏:微信小程序:像素小鸟Pro
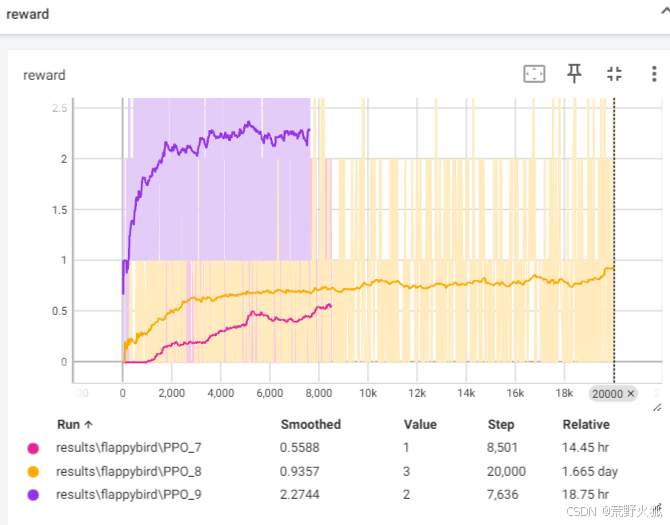
由于训练时不能使用笔记本,且训练时长非常耗时,加上我笔记本屏幕本来就有点问题,屏幕会10min左右来一次屏闪,估计会导致训练更加困难,这里我仅展示我训练最长的一次收敛情况,若是有兄弟有兴趣训练完这个项目,可以在评论区找我。
总共训练时长73.16h,中间有点意外情况,所以是8在7上的模型训,9在8上的模型训,总共加起来的时长,最终效果是1.22的奖励。(最后一个看起来高于2,是因为最后一个启动训练时没有重新进行preparation.py,导致的一开始奖励值就是1所致)
测试视频:https://wild-firefox.github.io/projects
一、打atari游戏(以Pong游戏为例)
代码实现在:https://github.com/wild-firefox/FreeRL_for_play/tree/main/first_game_pong
首先从基础的开始玩起,一开始我也是直接照着参考1,直接开始训练像素小鸟,但是怎么也不收敛,一直很苦恼,后来决定先从简单的像素游戏atari游戏玩起,这个训练完了,才能一步一步将方法引入到像素小鸟,最终实现收敛。
环境介绍
使用的环境
import gymnasium as gym
import ale_py
gym.register_envs(ale_py)
atari环境:https://ale.farama.org/
应该只要下载pip install ale_py就行,如果你事先下载过完整版的pip install gymnasium[all]的话,这个环境配置简单的。
参考2的实现:
参考2这个130行numpy的实现是个非常好的reinforce算法实现,没有使用任何其他的框架。如pytorch,从中也可以学习到一些算法的原理(有些往往被当成pytorch里的函数直接调用了)。
环境是atari的pong环境:训练右边的agent来打败左边的规则ai。
奖励:使对方接不到小球则+1,自己接不到则-1,其他则为0。
动作:原atari可以执行的动作有6个,这里只选取其中两个:向上和向下。
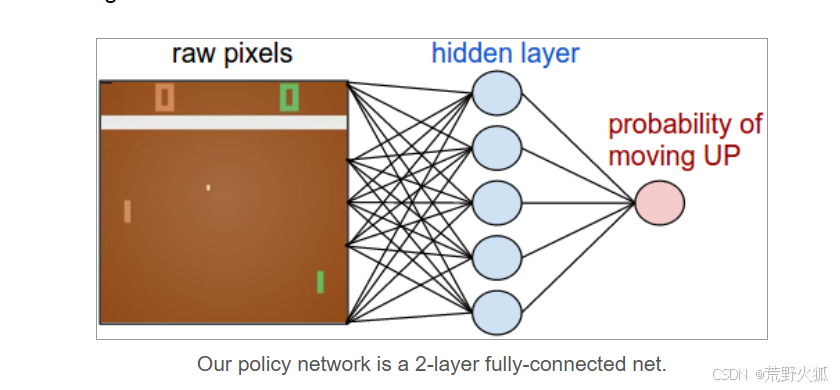
图摘自参考2作者的博客
作者最终是在当时的(2016年)Mac上跑了三天达到了与人一样的水平,(展示gif的成果是8:21),也就是最终return是13。
环境是每秒60帧,输出的状态是210x160x3的图。
参考2这个速度还是在atari这个游戏是已经封装好了,不需要有显示,直接读取每一帧(不需要真的渲染出来玩)的情况下的收敛速度。
收敛思路
obs
作者对状态进行了修改:
操作:
1:将图中上方发分数和下面的白边裁剪,
2.然后以步长为2取像素点,
3.再取一个通道(转为灰度图)
4.将灰度图背景上是两ai和球的部分取成黑色。
5.将不是0的给1 ,不是黑色的取成1(相当于也进行了归一,255是白除以255就是1)
作者使用如下代码
def prepro(I):
""" prepro 210x160x3 uint8 frame into 6400 (80x80) 1D float vector """
I = I[35:195] # crop
I = I[::2,::2,0] # downsample by factor of 2
I[I == 144] = 0 # erase background (background type 1)
I[I == 109] = 0 # erase background (background type 2)
I[I != 0] = 1 # everything else (paddles, ball) just set to 1
return I.astype(np.float32).ravel() # 展平
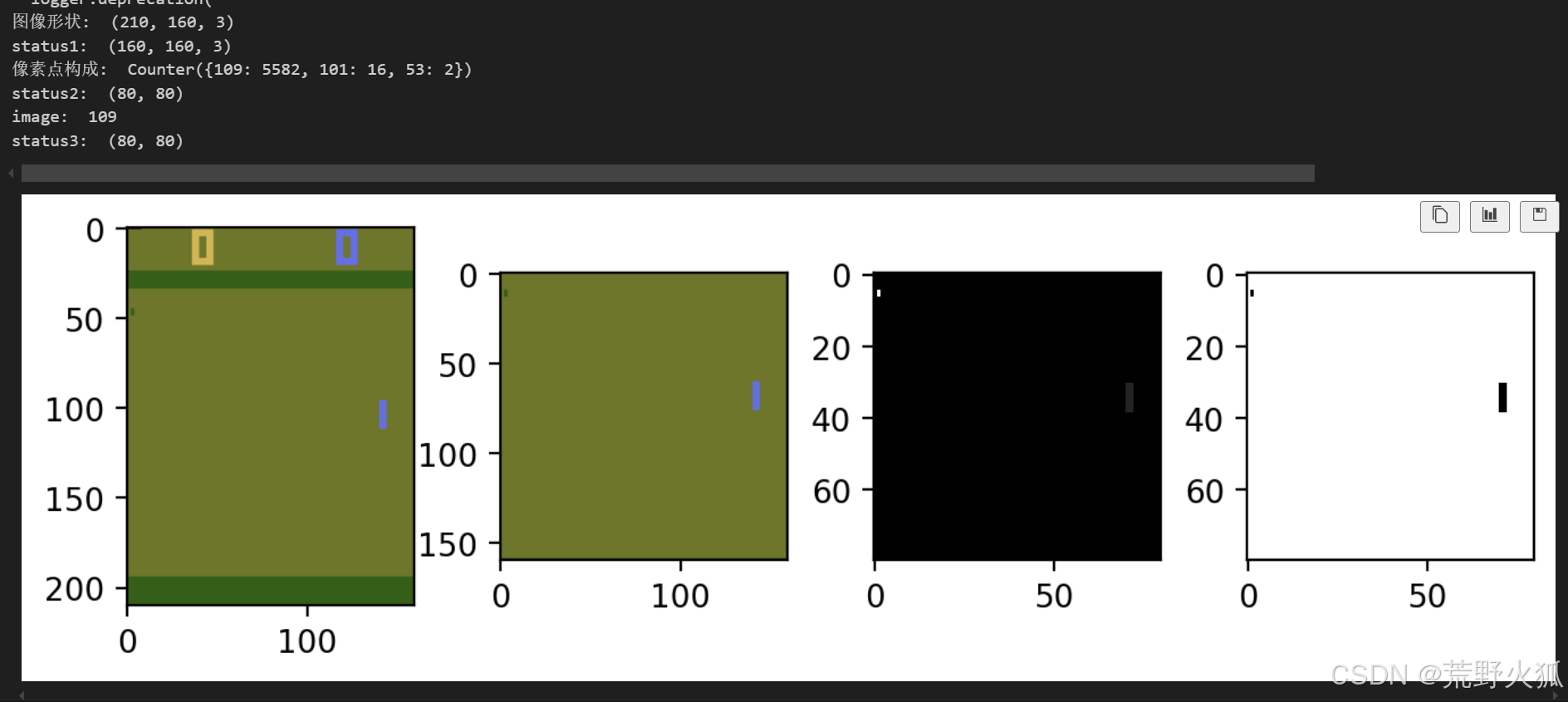
最终如下,第一个obs效果如下:
第一张图为原始图,第二张图是裁剪后([35:195]),第三张图是灰度图和下采样([::2,::2,0]),第四张图将不重要的部分去掉。最后将这个图展成1维
使用如下代码得到下图中间结果图
(此代码参考:https://blog.youkuaiyun.com/qq_41188247/article/details/127857166)
import gymnasium as gym
import ale_py
import matplotlib.pyplot as plt
from collections import deque,Counter
def show_image(status):
print("图像形状: ",status.shape)
status1=status[35:195] #[2:196 ,6:] #裁剪有效区域 #
print("status1: ",status1.shape)
status2 = status1[::2, ::2, 0] #下采样,缩减 # 0 表示只取一个通道
# 观察我们的像素点构成
def see_color(status):
allcolor=[]
for i in range(70):
allcolor.extend(status[i])
dict_color=Counter(allcolor)
print("像素点构成: ",dict_color)
see_color(status2)
# 观察好像素点后,擦除背景
def togray(image_in):
image=image_in.copy()
print("image: ",max(image.flatten()))
image[image == 144] = 0 # 擦除背景 (background type 1)
image[image == 109] = 0 # 擦除背景
image[image != 0] = 1 # 转为灰度图,除了黑色外其他都是白色
return image
print("status2: ",status2.shape)
status3=togray(status2)
print("status3: ",status3.shape)
# 可视化我们的操作中间图
def show_status(list_status):
fig = plt.figure(figsize=(8, 32), dpi=200)
plt.subplots_adjust(left=None, bottom=None, right=None, top=None,wspace=0.3, hspace=0)
for i in range(len(list_status)):
plt.subplot(1,len(list_status),i+1)
plt.imshow(list_status[i],cmap=plt.cm.binary)
plt.show()
show_status([status,status1,status2,status3])
return status3
gym.register_envs(ale_py)
env = gym.make('Pong-v0')#('ALE/Freeway-v5')
obs, info = env.reset(seed=0)
sta = show_image(obs)
然而作者并不仅仅将这个图直接当作obs输入,而是将输入表示为
第一帧为obs输入全为0的图,展成1维,将当前帧赋给上一帧
第二帧为obs输入为当前帧减去上一帧的图(展成1维)
第三帧同上
作者代码如下
cur_x = prepro(observation)
x = cur_x - prev_x if prev_x is not None else np.zeros(D)
prev_x = cur_x
aprob, h = policy_forward(x)
使用如下代码:
import numpy as np
import matplotlib.pyplot as plt
import time
import gymnasium as gym
import ale_py
gym.register_envs(ale_py)
env = gym.make("Pong-v0")
observation ,info = env.reset()
prev_x = None # used in computing the difference frame
xs,hs,dlogps,drs = [],[],[],[]
running_reward = None
reward_sum = 0
episode_number = 0
def prepro(I):
""" prepro 210x160x3 uint8 frame into 6400 (80x80) 1D float vector """
I = I[35:195] # crop
I = I[::2,::2,0] # downsample by factor of 2
I[I == 144] = 0 # erase background (background type 1)
I[I == 109] = 0 # erase background (background type 2)
I[I != 0] = 1 # everything else (paddles, ball) just set to 1
return I.astype(np.float32).ravel() # 展平
D = 80 * 80
for i in range(100):
#if render: env.render()
# preprocess the observation, set input to network to be difference image
cur_x = prepro(observation)
# if i > 1:
# print('当前')
# plt.imshow(cur_x.reshape(80,80),cmap=plt.cm.binary)
# plt.show()
# print('上一帧')
# plt.imshow(prev_x.reshape(80,80),cmap=plt.cm.binary)
# plt.show()
x = cur_x - prev_x if prev_x is not None else np.zeros(D)
# print("x: ",x)
# print(max(x))
prev_x = cur_x
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
#
if i> 1 and reward == -1:
print(i)
print('裁剪后')
print(max(x),min(x),type(x))
plt.imshow(x.reshape(80,80),cmap=plt.cm.binary)
plt.show()
#time.sleep(1)
后,可以看到中间效果图如下:
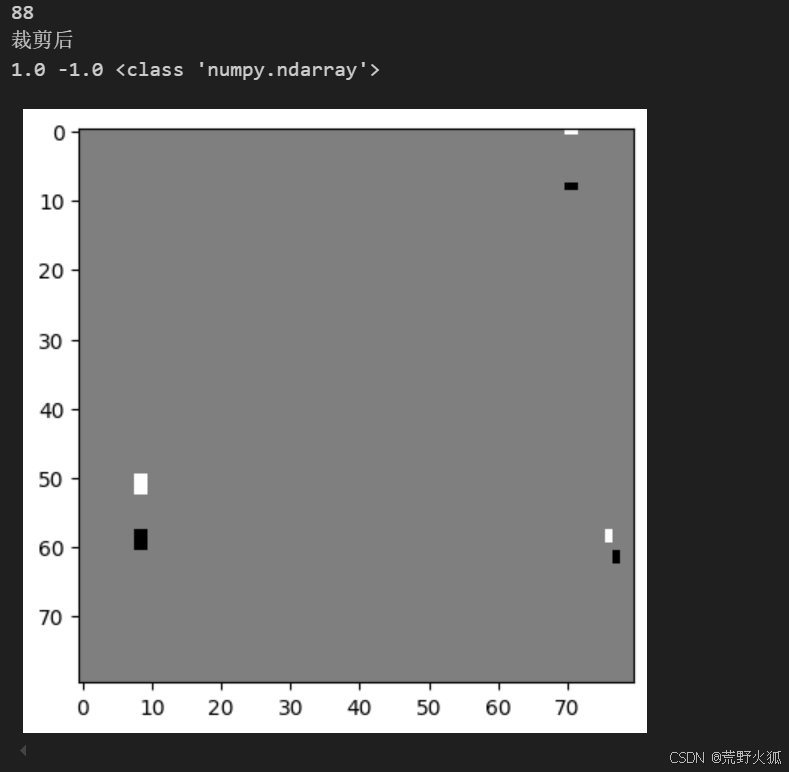
也就是说是这种图展成1维来进行obs输入的。
神经网络
这里神经网络
作者只用了一层200层的权重来来进行学习,甚至没有使用bias,
然后这种情况虽然是在普通的动力学环境摆杆,小山过车这种场景下是常见的,但是在图像上我还是第一次看到。
作者在博客中说,或者可以使用cnn来加速曲线收敛。
复现及优化过程
先优化原本速度
但是现在电脑配置应该是优于当时的环境的,这里我使用我目前的主机使用cpu(i7-14700k)
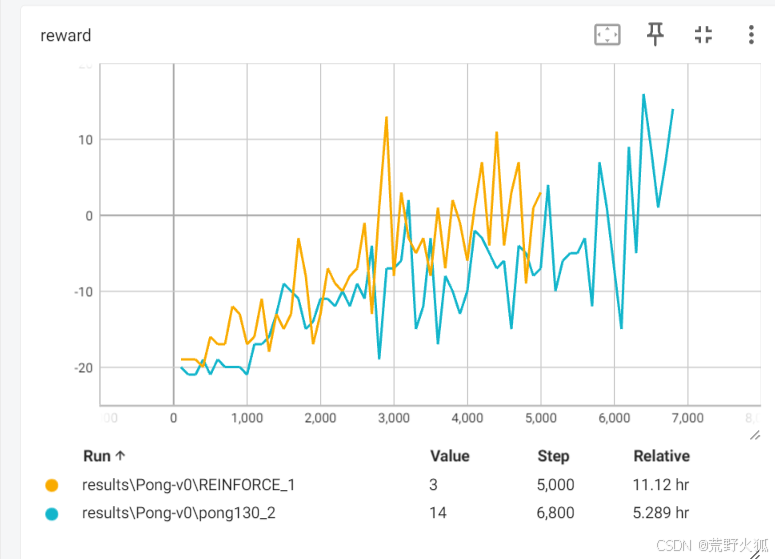
再将作者的代码修改成适用python3.x 版本后(pong130.py),结果如下:(横坐标为episode)
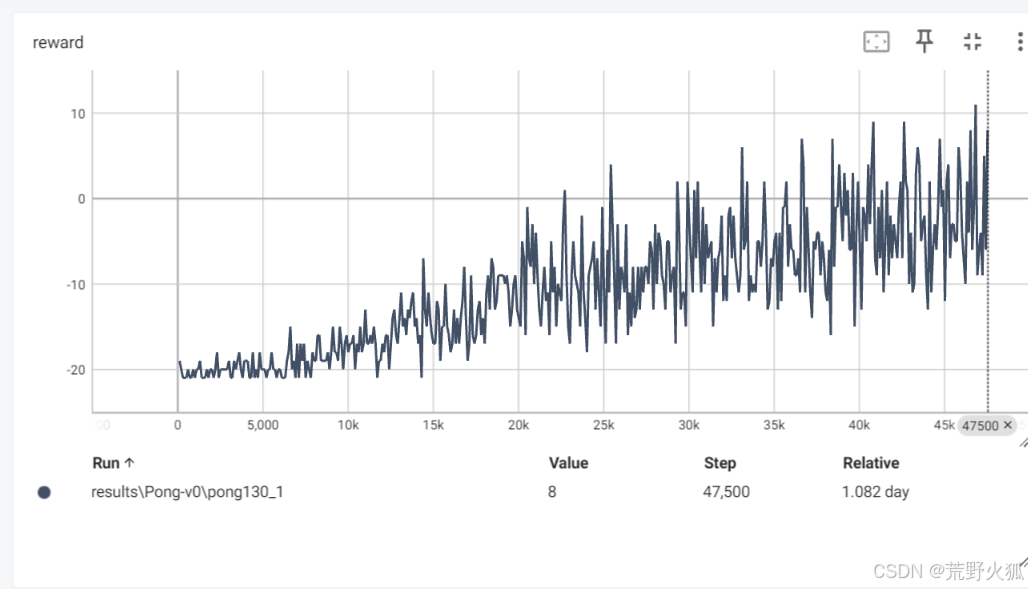
训练了近1天,可以达到近5的return。
看作者github下的评论:进行如下优化。
1.裁剪区域变大 [35:195] -> [35:185] 最终80x80 ->75x80
2.学习率1e-4 ->1e-3
再次进行实验:
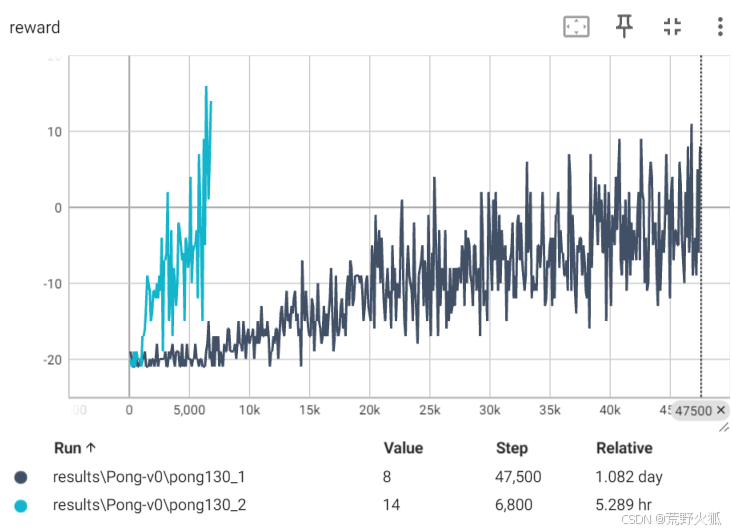
时间和episode均下降了很多,基本实现5h就能达到近10的return。
补充图:
下面是将原本的10个episodes更新1次改成1episodes更新一次后的结果。
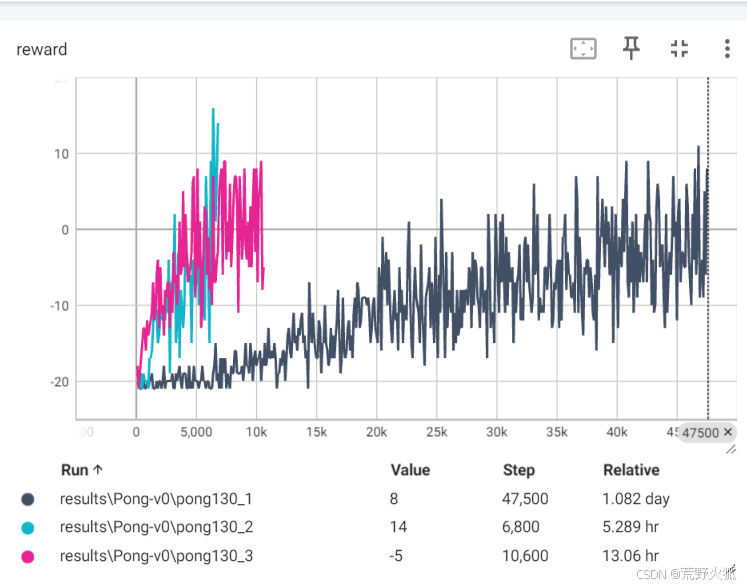
pong130_2的最终效果可见该results\Pong-v0\pong130_2下的gif
改代码复现
由于我习惯使用pytorch框架,并不会写这种numpy,于是将原来的pong130.py改成了pytorch的版本,用的是REINFORCE。
复现有两处不同 :(这里继承了上述的优化)
1.learn_episodes_interval = 10 (更新频率) - >learn_episodes_interval = 1 ,
2.RMSprop - > Adam
原来的代码是使用numpy手动实现梯度下降的,没有pytorch里封装的自动微分,可能会比较快,但是这里的速度还是偏慢
进行如下修改后:
1: 将pong130 修改为此文件 两处不同 learn_episodes_interval = 1 , Adam
2:1基础上 learn_episodes_interval = 10
3. 1基础上 增加bias state初始化默认
4 3基础上 增加1层隐藏层 200
9 改cnn 1e-4
15 改cnn 1e-3 (deepseek改版)
17 改cnn 1e-3 (dqn改版)
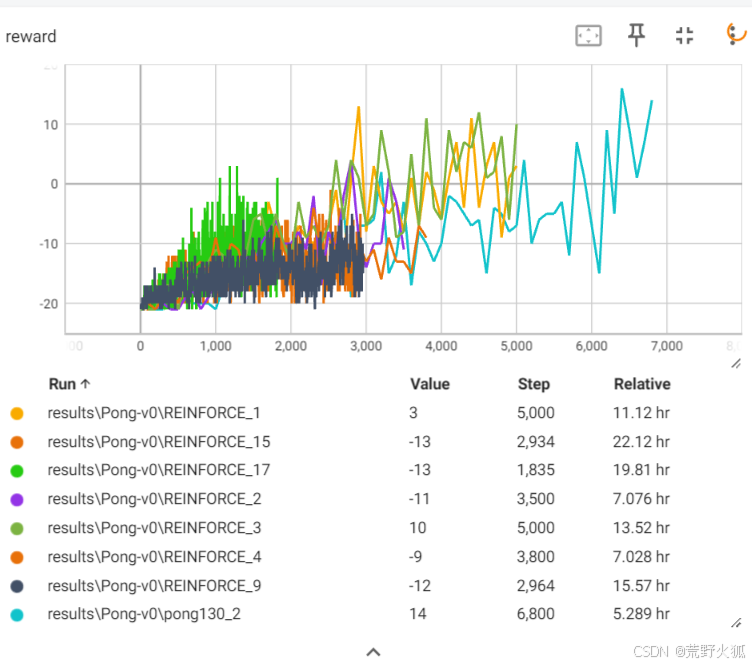
发现,加入cnn效果并不好,加入bias,state初始化默认(3)虽然慢但是效果较好,选择此项。
换算法(REINFORCE -> PPO)
注意:改成PPO算法后 原代码的一个细节被我取消掉了,因为不好修改。
细节:将reward=1或-1时当作当前episodes的done来训练(下图的这一句)
但是还是可以收敛,所以不加也没事,也更加通用。
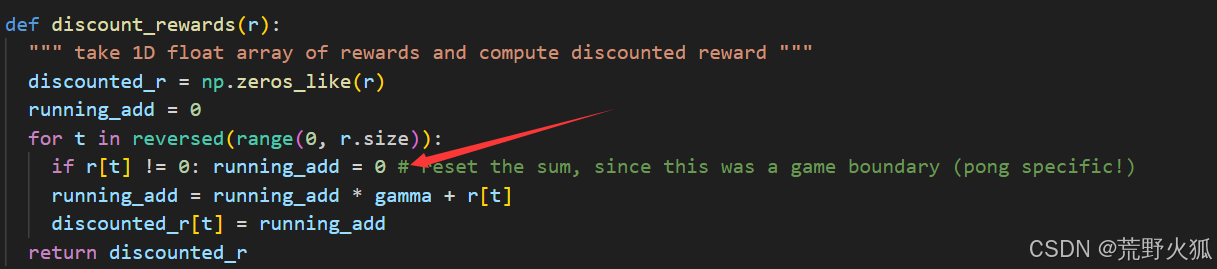
将REINFORCE改成PPO后,效果一下子就拉开了
3: 激活函数relu改成tanh
4: (继承上述优化)
5: 4加上prev_x = cur_x
7: 4 hidden改成400
reward_norm_1:4 加上reward_norm
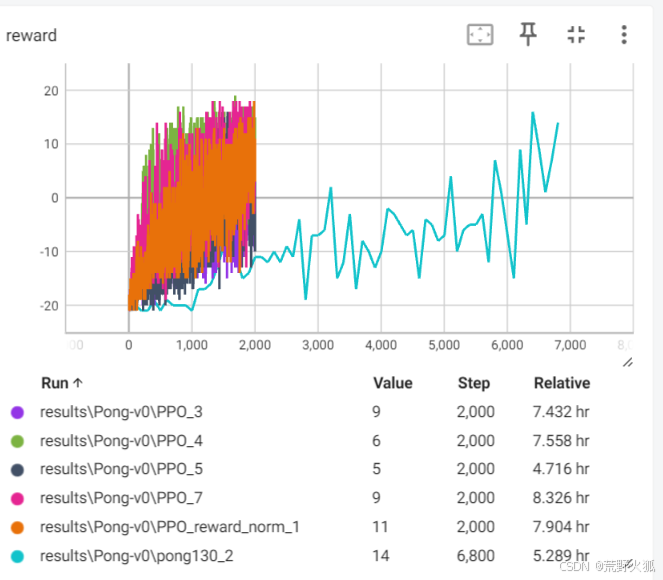
平滑后如下:
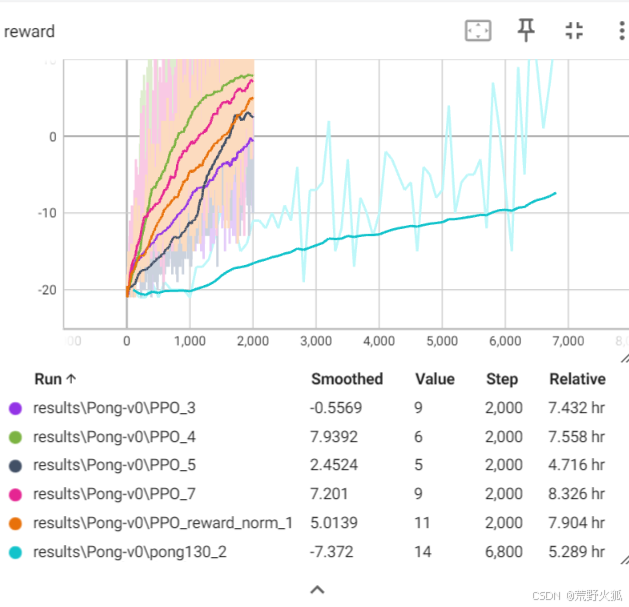
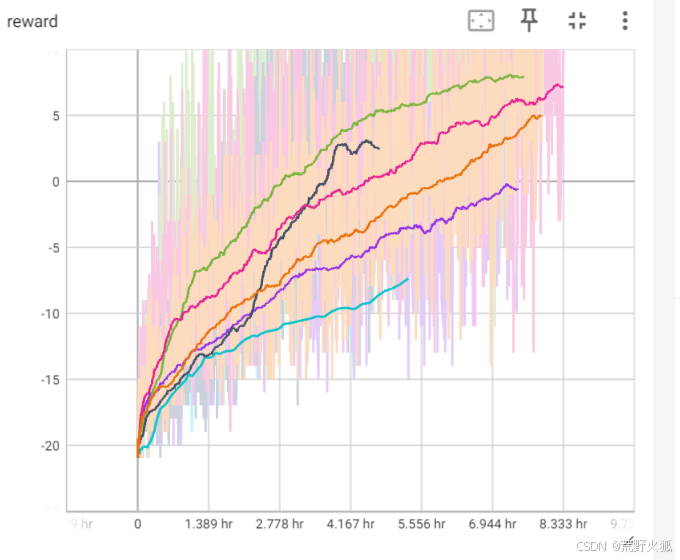
可以看出4还是收敛的较快,速度也可以和上述作者代码优化后的代码相当了,且可以在较少回合数进行快速收敛。
这里有个插曲:所以这里的优化为obs的输入
在进行PPO复刻时,我忘记加入prev_x = cur_x,导致输入的obs只是当前帧和第一帧的差值的一维obs
这里和5进行了比较,确实前期会好一点。
总结优化
1.适当裁剪图像
2.适当减小学习率
3.REINFORCE -> PPO
4.obs两帧差值 -> 当前帧和第一帧差值
5.不使用 cnn
6.默认初始化obs,加入bias
7.一层hidden(不使用两层hidden)
补充
注意:使用cnn的方法也可以收敛,但是实验下来会比较慢,可能是没有堆叠帧的缘故,之前堆叠帧在像素小鸟上实验过,感觉不收敛,后面就没做实验了
以下是使用的三种cnn
(在改代码复现中有展示效果)
9 改cnn 1e-4
15 改cnn 1e-3 (deepseek改版)
17 改cnn 1e-3 (dqn改版)
9:cnn摘自:https://aistudio.baidu.com/projectdetail/1434950
class Policy_CNN(nn.Module):
def __init__(self, obs_dim, action_dim):
super(Policy_CNN, self).__init__()
self.channels = 32
self.kernel_size = 3
self.stride = 2
self.padding = 1
input_channels = obs_dim[0]
h = obs_dim[1]
w = obs_dim[2]
# 修改点1:在每个卷积层后添加BatchNorm
self.conv_layers = nn.Sequential(
# Conv-BN-ReLU 组合
nn.Conv2d(input_channels, self.channels, self.kernel_size, self.stride, self.padding),
nn.BatchNorm2d(self.channels), # 添加BN
nn.ReLU(),
# Conv-BN-ReLU 组合
nn.Conv2d(self.channels, self.channels, self.kernel_size, self.stride, self.padding),
nn.BatchNorm2d(self.channels), # 添加BN
nn.ReLU(),
# Conv-BN-ReLU 组合
nn.Conv2d(self.channels, self.channels, self.kernel_size, self.stride, self.padding),
nn.BatchNorm2d(self.channels), # 添加BN
nn.ReLU(),
# Conv-BN-ReLU 组合
nn.Conv2d(self.channels, self.channels, self.kernel_size, self.stride, self.padding),
nn.BatchNorm2d(self.channels), # 添加BN
nn.ReLU()
)
# 修改点2:调整全连接层初始化
self.fc_input_dim = self._get_conv_output_dim((1, input_channels, h, w))
# 全连接层(添加Dropout可选)
self.linear0 = nn.Linear(self.fc_input_dim, 200)
self.actor = nn.Linear(200, action_dim)
# 初始化权重(BN层不需要特殊初始化)
self._init_weights()
def _get_conv_output_dim(self, input_shape):
with torch.no_grad():
dummy_input = torch.zeros(input_shape)
output = self.conv_layers(dummy_input)
return int(torch.prod(torch.tensor(output.size()[1:]) ))
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d): # 新增BN初始化
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
nn.init.constant_(m.bias, 0.1) # 轻微正偏置
def forward(self, x):
# 前向传播保持不变
x = self.conv_layers(x)
x = x.flatten(start_dim=1) # 更安全的展平方式
x = F.relu(self.linear0(x))
logits = self.actor(x)
probs = F.softmax(logits, dim=-1)
return probs
15:摘自deepseek的回答
class PolicyNet(nn.Module):
def __init__(self,obs_dim, action_dim,):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2),
nn.ReLU(),
nn.Flatten()
)
fc_dim = self._get_conv_output(obs_dim)
print(fc_dim)
self.fc1 = nn.Linear(fc_dim, 256) # 根据实际输出调整维度
self.fc2 = nn.Linear(256, action_dim)
def forward(self, x):
#x = x.view(-1, 1, 75, 80) # 将1D输入转为2D图像 (batch_size, channels, height, width)
x = self.cnn(x)
x = F.relu(self.fc1(x))
return torch.softmax(self.fc2(x),dim=1)
def _get_conv_output(self, shape):
with torch.no_grad():
x = torch.rand(1, *shape)
x = self.cnn(x)
return x.numel()
17:参考dqn原论文的参数
class Policy_CNN(nn.Module):
def __init__(self, obs_dim, action_dim):
super(Policy_CNN, self).__init__()
input_channels = obs_dim[0]
# 修改点1:在每个卷积层后添加BatchNorm
self.conv_layers = nn.Sequential(
nn.Conv2d(input_channels, 32, kernel_size=4, stride=2, padding=1), # 输入通道 -> 32
nn.MaxPool2d(kernel_size=2, stride=2),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), # 32 -> 64
nn.MaxPool2d(kernel_size=2, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), # 64 -> 64
nn.MaxPool2d(kernel_size=2, stride=2),
nn.ReLU()
)
# 修改点2:调整全连接层初始化
#self.fc_input_dim = self._get_conv_output_dim((1, input_channels, h, w))
# 全连接层(添加Dropout可选)
self.linear0 = nn.Linear(64*2*2, 200)
self.actor = nn.Linear(200, action_dim)
# 初始化权重(BN层不需要特殊初始化)
self._init_weights()
def _get_conv_output_dim(self, input_shape):
with torch.no_grad():
dummy_input = torch.zeros(input_shape)
output = self.conv_layers(dummy_input)
return int(torch.prod(torch.tensor(output.size()[1:]) ))
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d): # 新增BN初始化
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
nn.init.constant_(m.bias, 0.1) # 轻微正偏置
def forward(self, x):
# 前向传播保持不变
x = self.conv_layers(x)
x = x.flatten(start_dim=1) # 更安全的展平方式
x = F.relu(self.linear0(x))
logits = self.actor(x)
probs = F.softmax(logits, dim=-1)
return probs
二、非侵入式玩像素小鸟
大体游戏界面:

要点总结
首先在看过参考1中的大佬b站 的讲解后,总结了几个要点:
1.获取键鼠的控制
2.十分迅速的截屏
3.对一些必要特征要进行提取(比方说只狼得对血条的白色像素计算)
4.加入紧急暂停(怕脏图污染,或者有事得用电脑)
5.使用1920x1080的分辨率,或者更小的图来进行读入
(我实战的一些总结)
4.在游戏时不要进行网络的训练,否则会导致游戏操作的延迟。
我进行的操作:
buffer必须改为一个episode,一个episode的存取,在游戏结束后,再进行对episodes的判断来进行是否满足更新条件来进行更新,而不是按照步数step来更新。(当然在一、中我也是这么操作的)
外部操作 (1,2,4)
对于一些截屏和键鼠的操作,基本沿用了参考1的代码,可能后面有大佬合作开源的关于打黑猴的一些截屏操作更加快,这里没做实验放入了(io_utils.py)
暂停的代码也放入了其中。
特征提取(3)
对于像素小鸟上,重新开始游戏的点击位置和过管道的分数变化,是这样设计的,有些部分是多余的,(实验的时候考虑后,没有去掉的) 文件夹images
(下图是手机小程序上截的图,电脑上打开并无右上角的三点,例:第三张)



需要截取和识别的区域:
home:整个游戏界面的截取(实时截取)
restart:(再来一局)的位置的截取(一次性截取)提供鼠标点击位置:
zero:分数界面的截取: (实时截取)
(实时截取)
start:开始结束标记的截取: (实时截取)
(实时截取)
如何判断zero区域的分数变化:(如何判断开始结束标记)
使用以下代码:
观察白色区域的第19行总体白色像素点的变化(借鉴于打只狼)
发现在第19行时,所有的分数变化后,都与上一个分数的白色像素和不同,以此来判断分数变化
这个第19行是试出来的,可以使用以下代码试出
开始结束是使用start.png这个图片所在游戏的位置,在该位置的行列2/3,2/3处的灰度值来判断。
开始是255(白),在结束时是灰,和正常游戏时的灰度值也不一样,位置容易试出。
### 选择窗口
import cv2
from io_utils import grab_screen, get_white_pixel
if __name__ == "__main__":
home_size = (1,56,408,788)
start_window = (202, 430, 219, 459)
zero_window = (144, 116, 262, 154)
start_window_wh = (start_window[2]-start_window[0],start_window[3]-start_window[1])
# start判断位置:2/3位置
start_window_judge = (start_window_wh[1]*2//3,start_window_wh[0]*2//3)
current_white_pixel = 10
cnt=0
while True:
# 捕捉屏幕并转为灰度图像
screen = grab_screen(zero_window)
screen_gray = cv2.cvtColor(screen, cv2.COLOR_BGR2GRAY)
w_p = get_white_pixel(screen_gray)
window = grab_screen(home_size)
if w_p != current_white_pixel:
current_white_pixel = w_p
print(current_white_pixel)
cnt+=1
#cv2.imwrite(f'./screen_analyze/zero_window{cnt}.jpg',window)
print(screen_gray[start_window_judge])
# 显示图像
cv2.imshow("Screen Capture", window)
# 检查用户是否按下 'q' 键以退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 关闭所有 OpenCV 窗口
cv2.destroyAllWindows()
其中
def get_white_pixel(img):
white_pixel_sum = 0
for white_pixel in img[19]:
if white_pixel >= 240:
white_pixel_sum +=1
return white_pixel_sum
环境搭建 (5)和状态,奖励
在这里,由于我主机要进行学习,所以使用了之前的笔记本来进行训练。
屏幕是1920x1080,显示设置缩放为125%
训练的cpu是Intel® Core™ i7-10870H CPU @ 2.20GHz
状态设计:
沿用了之前一、中的所有优化方式:
第一帧的obs输入为全为0的np.array,将经过处理的当前帧赋值给上一帧(prev_x)此后这个prev_x不变
第二帧的obs输入为(当前帧-prev_x),然后经过处理后的一维np.array。
第三帧同第二帧。
这里状态还进行了一个操作:在每一步得到的截屏减去下面这个背景图。
这里与Pong的环境不同,会有背景的干扰,于是先在准备(preparation.py)期间,获得一个背景图:开始后点击一下截屏,将小鸟和zero分数区域涂成背景大部分的灰度,如下显示:background。

上述zero还没涂成背景
奖励设计:
没有过管道时奖励为0,
经过管道后,分数变化时的那帧的奖励为1
关于为什么没有使用失败回到开始页面给-1的奖励:
是因为这个失败的页面的速度非常快,几乎截取不到撞到管道上的那一帧,而是都是失败页面的那一帧,加上这个奖励后,几乎不能收敛,故听取赵鉴大佬的建议(使用每一帧给1,或者只有通过给1),最终使用通过给1取得了收敛的效果。
动作设计:
这里我也只给了两个动作
0:time.sleep(0.2)
1: click ;time.sleep(0.1)
这里我经过以下代码,多次测试,得出一次点击差不多0.1s,这样上述两个动作的运行时间就尽量可以保持一致。
注:上述运行时间保持一致一开始是因为在每一帧都给奖励希望尽量使得生存时间更久,如果不保持一致,可能会造成一直保持速度较快运行的动作来获得高奖励,现在奖励在每一帧不给奖励,可能运行时间保持一致就没有必要了
import pydirectinput
import time
time_ = time.time()
pydirectinput.click()
print(time.time()-time_)
补充:
更新频率我这里并没有使用每一个episode更新一次,而是20episodes更新1次
原因:原始atari一场对局是哪方先达到21分就算这一个episodes结束,且这个游戏是每秒60帧的,所以得到buffer数据会很多,一个episodes也能学到很多东西,这里的一个episodes只有最多15帧的画面,所以这里给到了20个episodes更新1次。
如何使用
默认代码界面不要遮住游戏界面,游戏界面缩小放左上角。
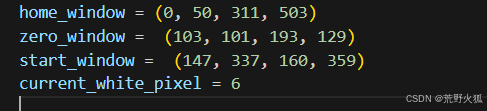
1.了解当前显示器分辨率和显示中的缩放大小。(缩放大小写入preparation.py的scaling_size里)
2.在单人游戏j界面上运行preparation.py(此时鼠标不要乱动),看是否框住了特征提取(3)这几处提及的图片,
(若没有框住或报错,则直接截取当前屏幕上的图替换images文件夹里的这几处照片。
然后将得到的结果粘贴替换环境env_flappybird.py代码的最上方代码,也需要替换define_keys.ipynb上方相关的值,如下所示)
3.在define_keys.ipynb的第一部分总结尝试得出get_white_pixel中img的行数,和start的位置。若发现也可以达到白色像素点变化 / start灰度值的开始和结束的灰度值不一致 ,则可以不变。
在第二部分可以裁剪出自己的obs.shape 然后将其替换掉PPO_atari.py中的值。
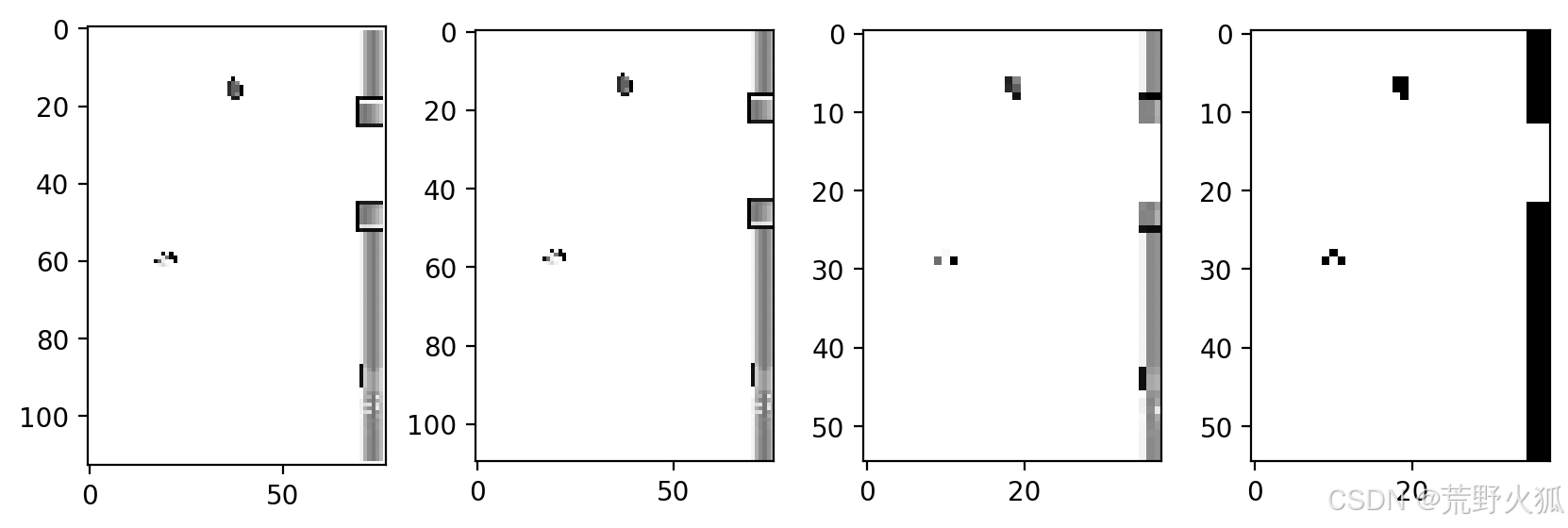
在第三部分是简单的尝试运行demo,也可以看到输入的obs的图片是什么样的。
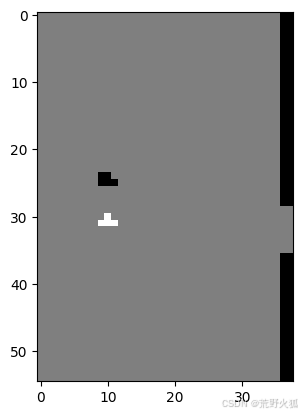
4.上述都成功的话,则可以运行PPO_atari.py的程序了。
如遇紧急情况,在键盘上按一下’t‘即可暂停。此值可在io_utils.py上改,紧急暂停后,还得必须将鼠标放入游戏界面的下半土地部分(防止遮挡关键部分),再按’t’来重新启动程序。
训练结果展示,支持使用tensorboard来展示,数据保存在/results/环境名/算法名 下。
tensorboard --logdir==数据位置
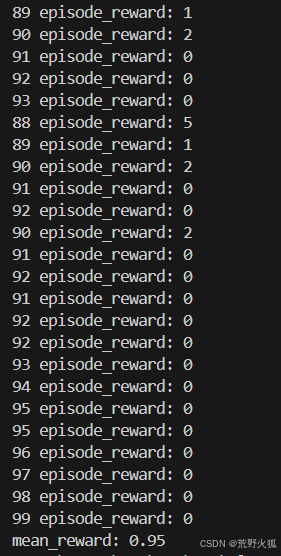
5.最后可以使用eval_flappybird.py来评估最后的效果。
我这里评估了100次游戏,最终的平均得分为0.95。
注意:每次训练时需要重复第2步以保证框选正确,若出现obs对不上的情况,则需要检测第3步(基本第三步不需要检查)
我代码上这些7在6上的修改:
7: 6上改 1.转灰度图方法 cv2.COLOR_BGR2GRAY ->
cv2.COLOR_BGRA2GRAY(发现只改了firststep()1处) 2.zero区域涂成背景 3.hidden 200 ->
100
不修改也可以收敛,所以也可以考虑改回这些参数。
最后祝你游戏愉快。
总结
1.总体来说,得到训练数据即让ai打游戏采样的过程是一个巨大的耗时的过程,所以想训练一个好的agent,起码需要好几天的训练。
2.若是使用cnn来进行特征识别可能收敛还会更久。
3.屏幕截屏和step中的一些操作(减背景图)可能会导致一些延迟来使得收敛变慢。
4.但是使用ai来打这种像素小鸟的即时性的游戏已经可以得到收敛了。
5.希望以后有更加快的收敛的方法实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









