







前言
按导师要求学习了一下多目标强化学习,我看的论文是
论文题目:A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation
(一种用于多目标强化学习和策略适应的广义算法)
论文链接:https://arxiv.org/pdf/1908.08342
论文代码:https://github.com/RunzheYang/MORL
复现代码:https://github.com/wild-firefox/FreeRL/tree/main/ENVELOPE_MORL_file
复现结果:环境为gym的deep-sea-treasure-v0环境
一、多目标的意思
这里对此论文的多目标强化学习的学习内容进行阐述,可能对普遍多目标优化问题的一些定义不一样。
引入:论文中的例子
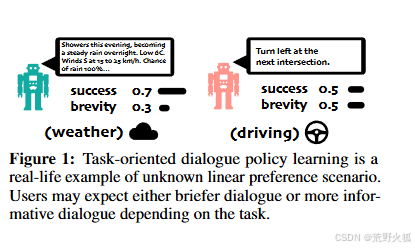
与传统的 RL 相比,传统 RL 的目标是优化标量奖励,而多目标设置中的最佳策略取决于竞争标准之间的相对偏好。例如,考虑一个虚拟助手(图 1),它可以与人类通信以执行特定任务(例如,提供天气或导航信息)。根据用户在成功率或简洁性等方面的相对偏好,代理可能需要遵循完全不同的策略。如果成功是最重要的(例如,提供准确的天气预报),代理人可能会提供详细的回答或询问几个后续问题。另一方面,如果简洁至关重要(例如,在提供turn-by-turn guidance),代理需要找到完成任务的最短方式。
简单来说:
在奖励方面发生了变化,现在要学习一个策略,来适应不同特定偏好权重下的多个奖励的最大化。
在这个深海宝藏这个环境举例:
这个环境如下:
环境链接:https://github.com/Farama-Foundation/MO-Gymnasium
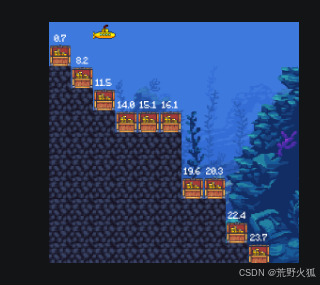
DEFAULT_MAP = np.array(
[
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0.7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[-10, 8.2, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[-10, -10, 11.5, 0, 0, 0, 0, 0, 0, 0, 0],
[-10, -10, -10, 14.0, 15.1, 16.1, 0, 0, 0, 0, 0],
[-10, -10, -10, -10, -10, -10, 0, 0, 0, 0, 0],
[-10, -10, -10, -10, -10, -10, 0, 0, 0, 0, 0],
[-10, -10, -10, -10, -10, -10, 19.6, 20.3, 0, 0, 0],
[-10, -10, -10, -10, -10, -10, -10, -10, 0, 0, 0],
[-10, -10, -10, -10, -10, -10, -10, -10, 22.4, 0, 0],
[-10, -10, -10, -10, -10, -10, -10, -10, -10, 23.7, 0],
]
)
奖励为两方面,1 :当前位置所在的宝藏值,2:-1(每走一步,当前的时间惩罚)
假设权重:[0.5,0.5] , 将此权重点乘此奖励,就得到了此时目标的奖励,然后得到一个满足此条件下的最大奖励,就是此目标的策略
那么多目标RL得到的就是求得所有各个权重下的一个策略,即论文说的:一个域中的整个偏好空间上进行了优化。
二、论文的创新点
(1) 提供具有线性偏好的 MORL 多目标版 Q-Learning 的理论收敛结果。
(2) 展示有效使用深度神经网络将 MORL 扩展到更大的领域。
其中(1)是在前人的基础上,拓展证明了理论收敛。
(2)是说此RL只针对凸包络问题,并解决了凸包络问题的偏好对齐问题,所以此算法的名字也叫ENVELOPE(就是包络的意思)
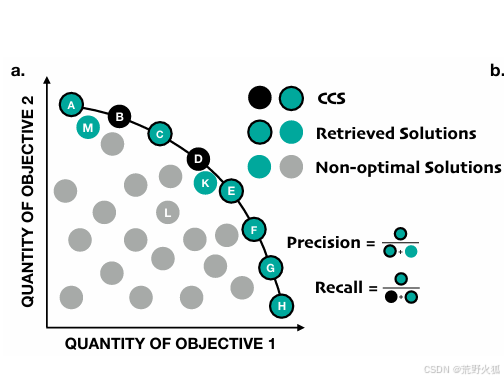
凸包络问题:指的是最后画出来的策略的解的形式是凸的。
类似于下图:
在(2)的解决细节中,使用了类似于事后经验回放的经验池,来使得优先级更大的batch更容易被选择到训练。
在训练过程中,为了使得策略更好学习,使用了同伦优化的方式,逐步将训练的损失函数从简单的损失函数引导到困难的损失函数上,来使得训练更加容易。
三、提出的指标和帕累托前沿图
提出的指标
CR:CoverageRatio(覆盖率)
假设依然在深海宝藏环境:
论文中的定义 CR
模型的解(两个目标)为 reward_vec
由于这里 我们知道环境是什么样,所以所有最优解只会在下面产生
目标的解
time = [-1, -3, -5, -7, -8, -9, -13, -14, -17, -19]
treasure = [0.7, 8.2, 11.5, 14., 15.1, 16.1, 19.6, 20.3, 22.4, 23.7]
precision = 模型(在帕累托上)预测对的解/模型的解的个数
recall = 模型(在帕累托上)预测对的解/目标的解的个数
CR = 2 * precision * recall / (precision + recall)
如何判断模型预测的解是对的呢?
可以这样来看:
首先评估模型时,这里假定权重是[0.5,0.5]
1.我们很容易得到此时的环境最优解是什么(将0.5 x np.array(time)+0.5 x np.array(treasure),得到的列表中,最大的值就是该该环境该目标的最优解,可以使用argmax 得到该序列最大值的索引就可以得到time和treasure的值)
2.模型的最优解是什么,就是在环境上走到done时,累计的reward_vec值,reward_vec[0]就是treasure值,reward_vec[1]就是time值。
看此时两者的time和treasure值是否相等,则说明预测的解的值是对的。
不过,
在原论文的代码中,则是将这个解([-9,16.1])分别乘以当前权重的单位向量(reward * w_e),看在向量空间的绝对值距离是否小于一定值,则判断这个解是对的。依然是下图:precision和recall
AE: Adaptation Error(适应误差)
假设上述的目标reward * w_e = realc_dst
base = np.linalg.norm(realc_dst, ord=2)
那么当前权重的loss = np.linalg.norm( realc_dst - realc , ord=2)/base
那么AE为所有权重(权重个数与解的个数一样)的和。
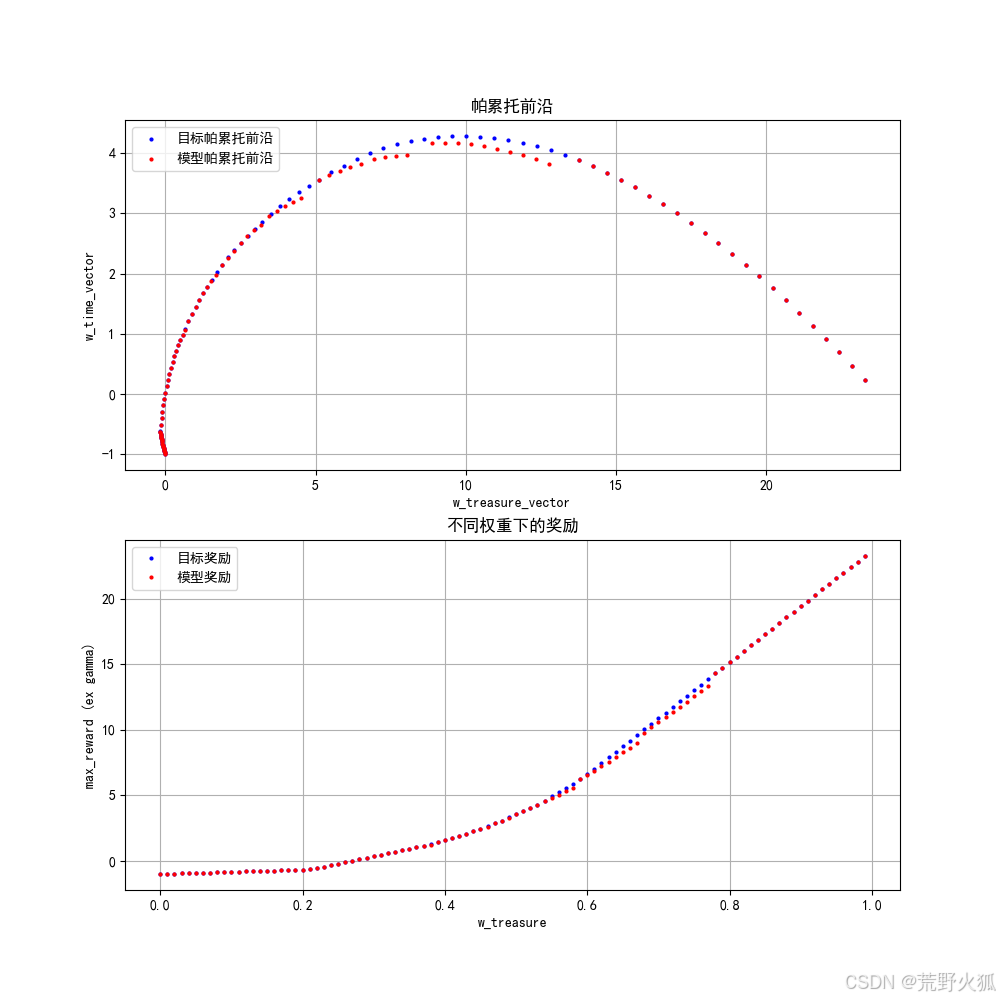
帕累托前沿图
依然是深海宝藏环境
( 由上述 如何判断模型预测的解是对的呢?读完后,可以理解下面这句话)
这里的帕累托前沿图:实际就是在当前reward(解)乘当前权重的单位向量得到的一个二维数组realc_dst
假设
realc_dst为目标数组
realc 为模型得到的数组
将realc[0]作为x,realc[1]作为y 就可以画帕累托前沿图了,这里的目标是两个,所以是二维图,如果是多个目标,则可能画不出图了。
区别:论文中还在每个奖励前乘了gamma折扣率(求取realc的时候),对应各个时间乘以不同折扣率。
由于这个是在评估时乘以,实际上不乘,依然是为找到的最佳reward,所有我代码这里没有乘。
四、复现效果
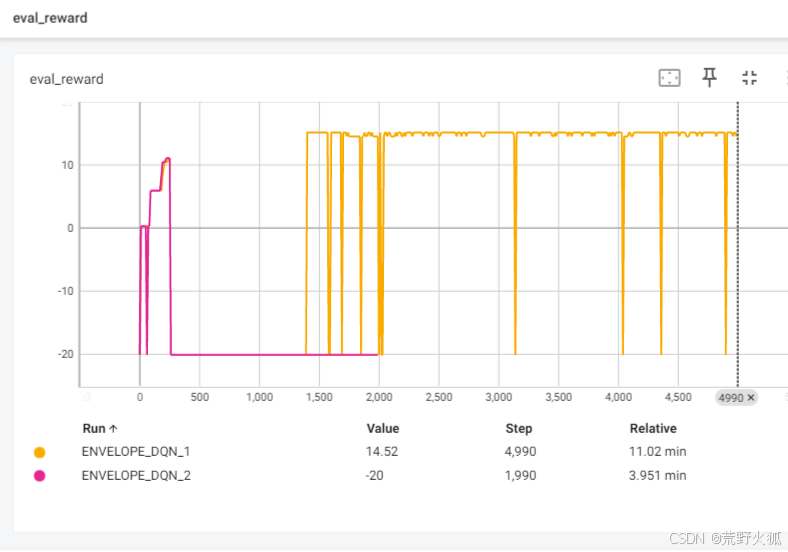
训练曲线
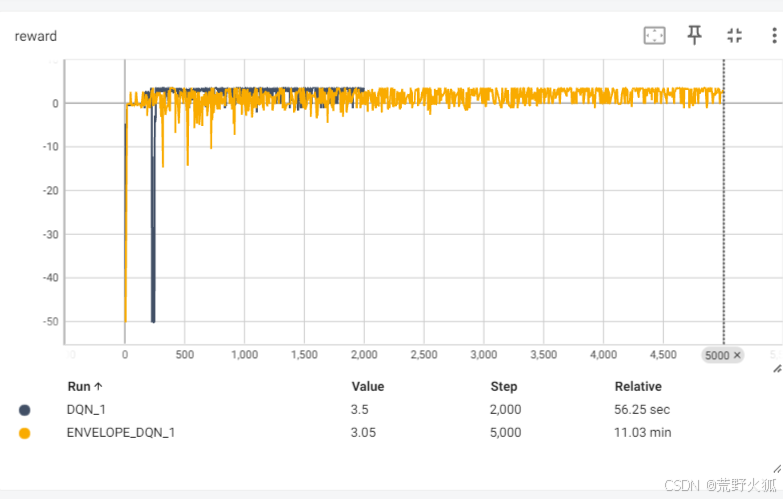
DQN是固定权重[0.5,0.5]训练出的结果,ENVELOPE是在此权重下的训练奖励。
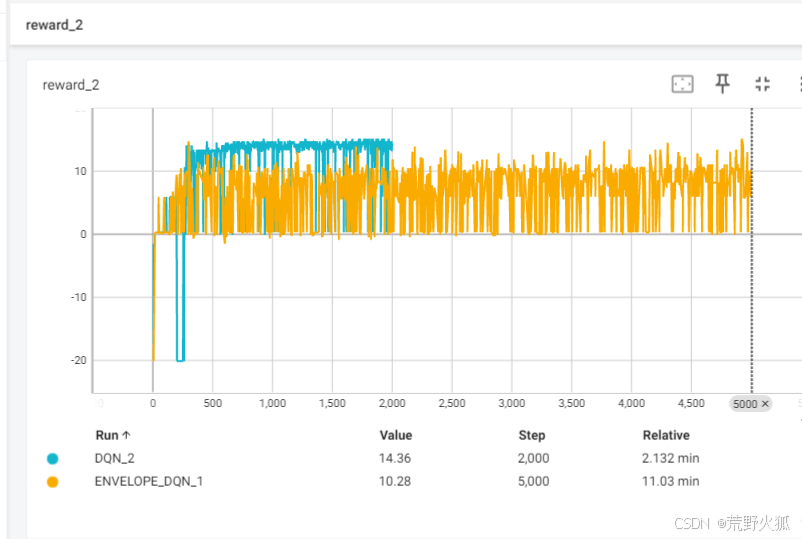
DQN是固定权重[0.8,0.2]训练出的结果,ENVELOPE是在此权重下的训练奖励
发现看此曲线,不容易知道训练情况是否好坏,且原论文代码跑出来的训练结果也是上下波动,所以加入了一个评估的曲线和loss曲线。
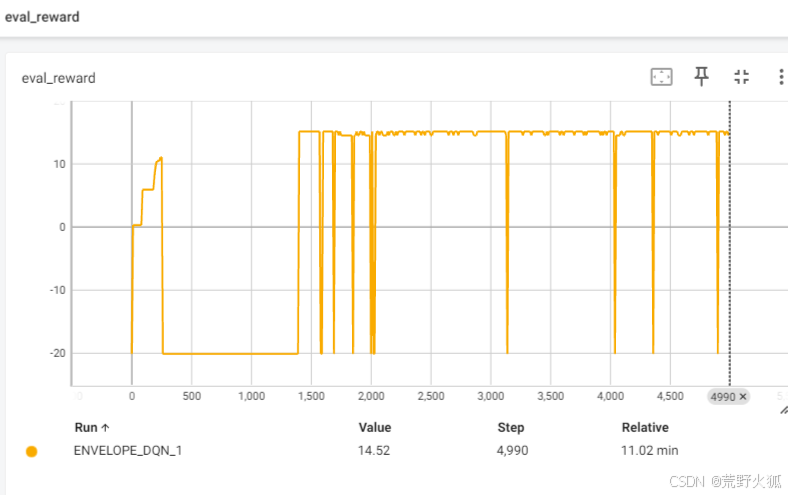
评估曲线:
每当模型经过训练几个episodes后,用此模型进行对固定的权重进行评估,绘制曲线,发现算法一般对[0.5,0.5],就是第一个权重为0.5左右的权重较容易学习到较好的策略,而第一个权重在0.8左右时,难以学习到较好的策略,所以固定的权重为[0.8,0.2]
此时就可以较容易判断模型的好坏,以便于及时终止。
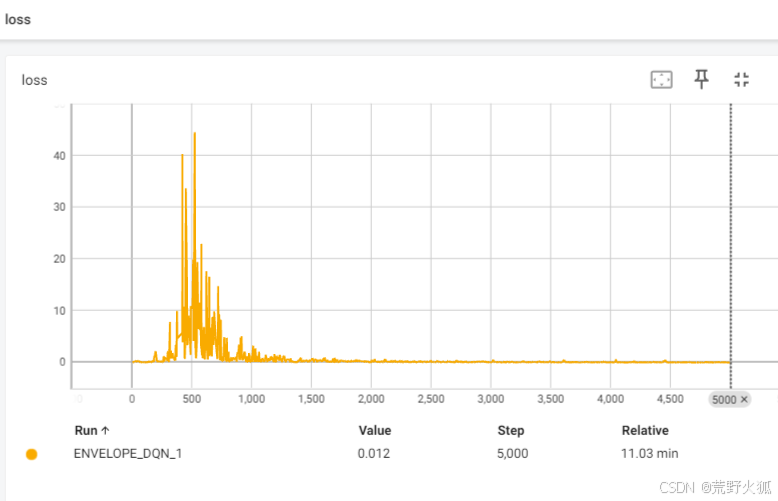
loss曲线:
一般loss曲线没有上述评估曲线看的明显,不过看到loss值一直往上到很夸张的数字时,也较容易判断此时模型的好坏。
在许久的调参下,这个黄色曲线是调出来收敛的一个。
可能敏感的参数:
episodes: 下面黄色是5000,而粉色是2000,其他参数一致。
可能多目标需要更久的学习。
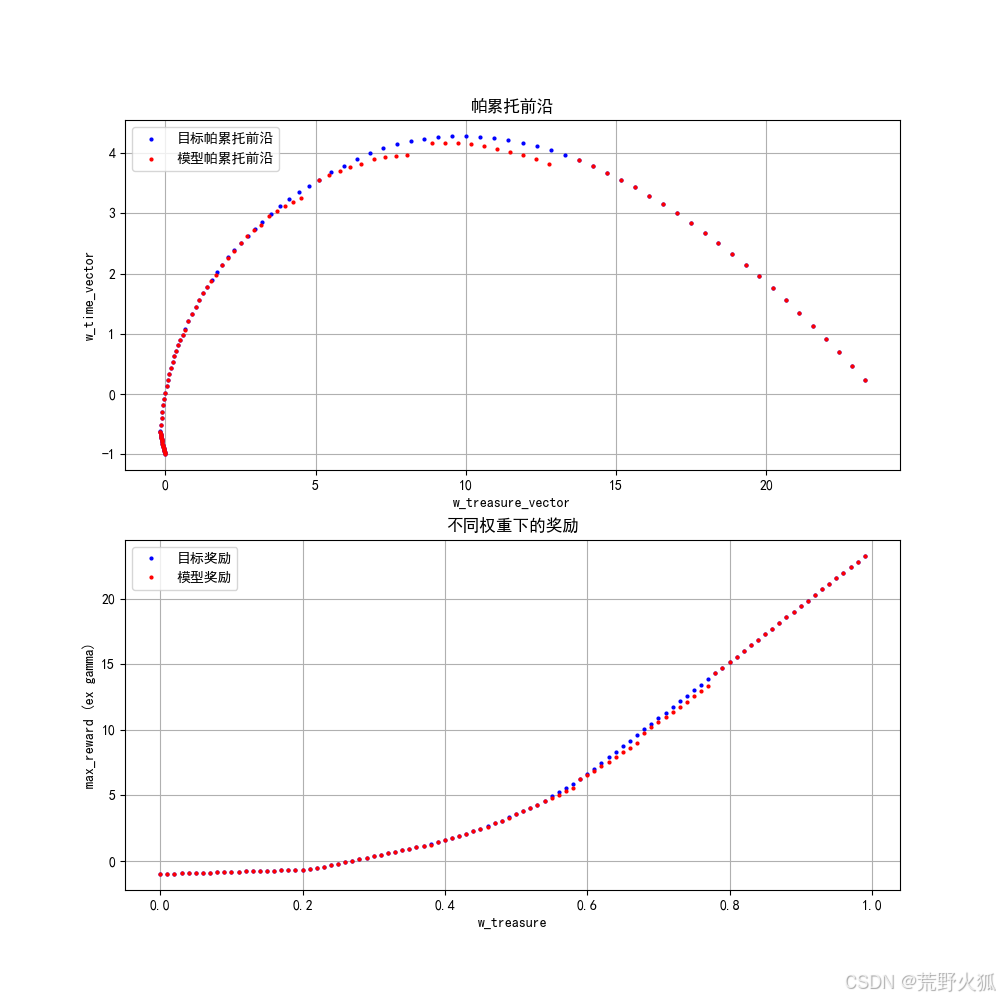
帕累托前沿和提出的指标
可以看出与目标的帕累托前沿还有一点差距
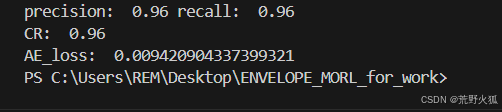
得到的这个结果和论文里的0.98也很相似了。
而训练的不好的情况下,如2000episodes:
则会出现这样的情况
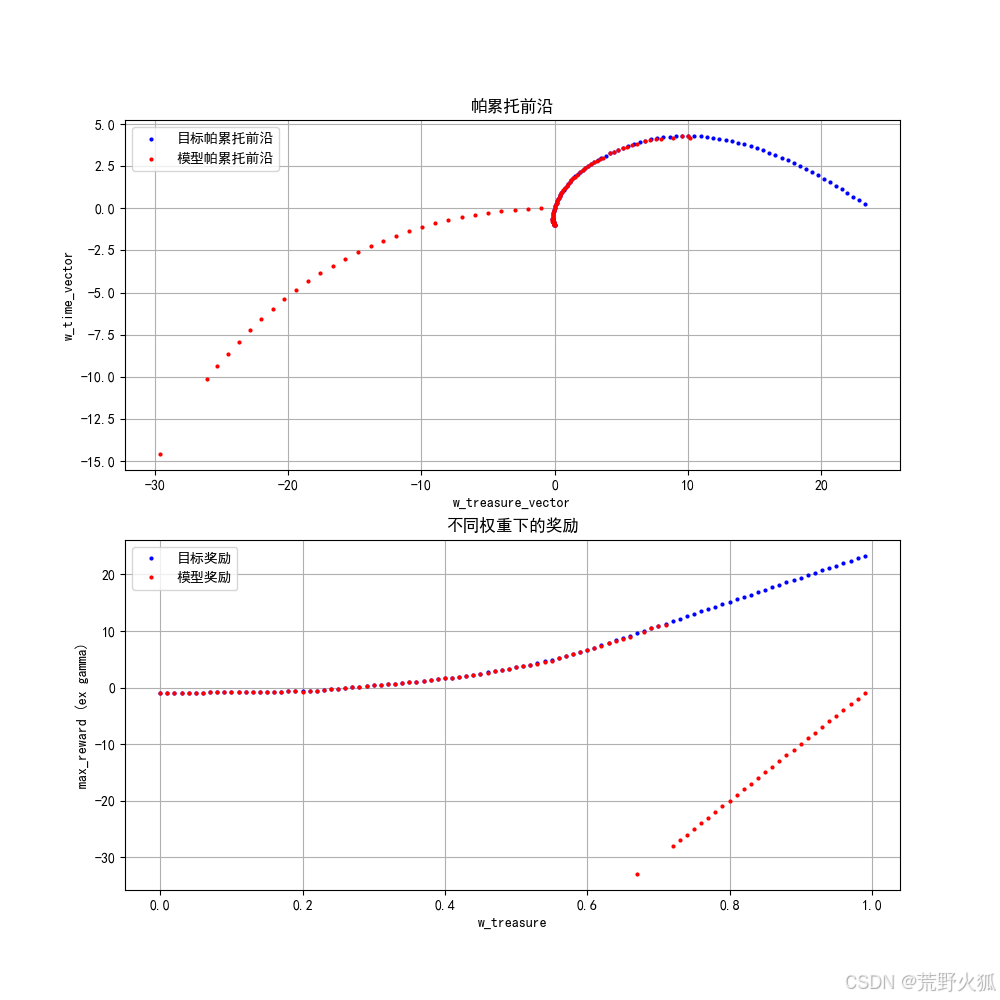

至此算是复现完毕

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









