







前言
对FreeRL库的一些更新记录:
1.由读者私信,说想要实现MAPPO的离散形式,但是在我代码上改后还是不行,在其参考的代码库上MAPPO确实是实现了离散的形式,故探究其代码收敛原因然后稍加改动后实现了MAPPO的离散形式代码。
也借机发现我原来实现MAPPO上的一些逻辑上的bug。
2.另外一个读者在咨询我MADDPG怎么收敛的问题上,我发现了大部分代码在使用MPE环境时都是env.step(),而我是env.step(seed=seed)固定了随机种子,所以我写的代码看着收敛很快,实际上是只对这个固定的随机种子收敛,不一定对所有随机种子收敛,从之前的评估时的曲线也能看出来。
这个是MADDPG的。看着还好一点。
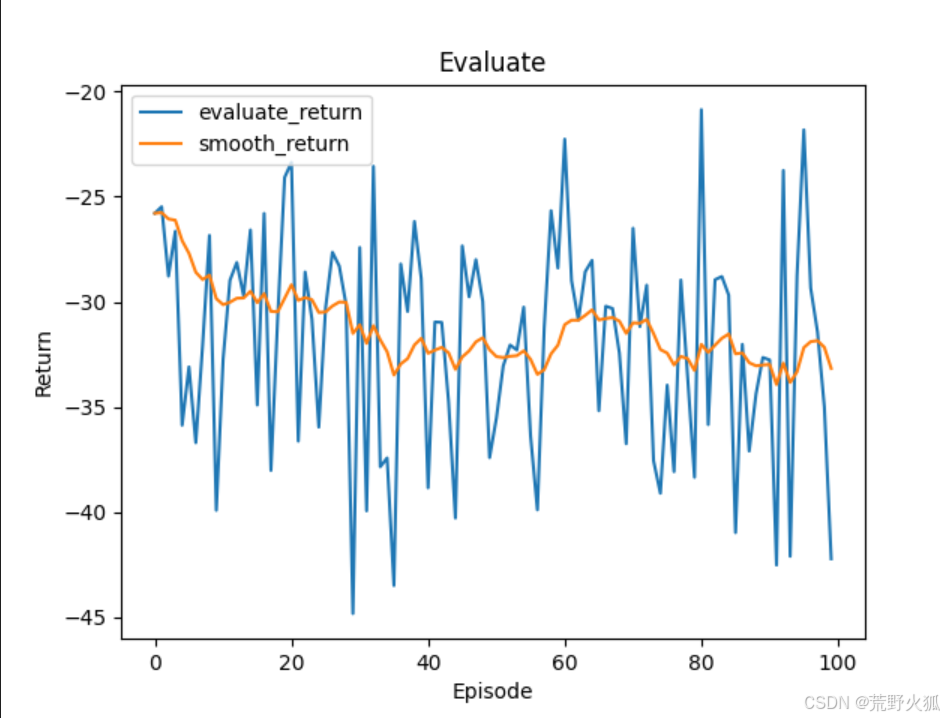
不过 再看MAPPO时,就拉跨了,从而我也看出之前可能实现的有问题。
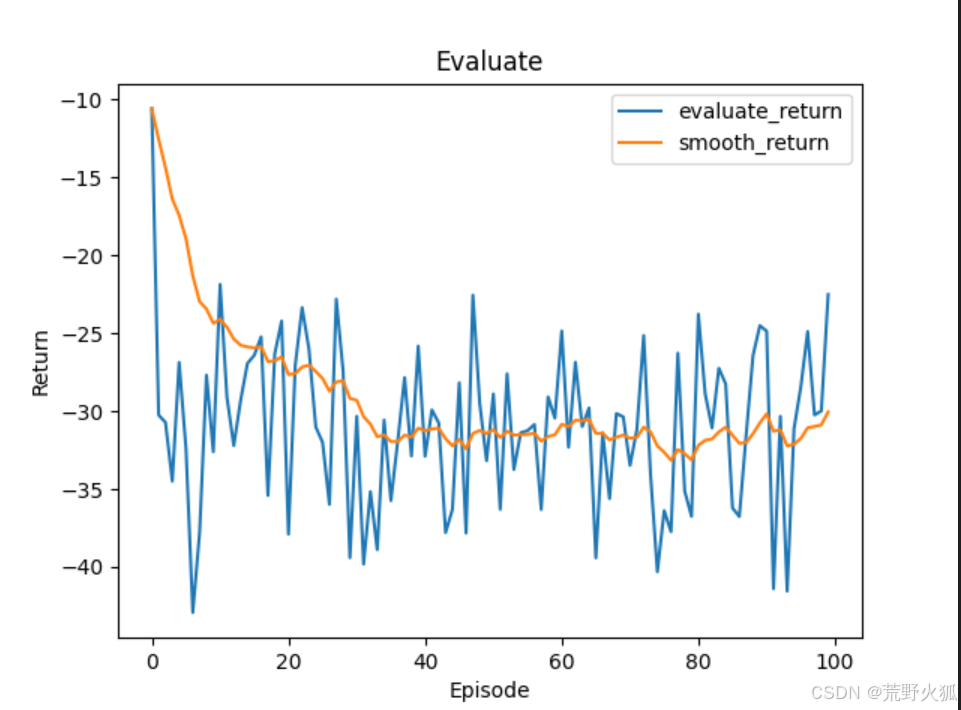
所以这里的更新是以下内容
1.对于MAPPO原来实现的修改和加入MAPPO_discrete的实现
2.对于MADDPG及所有多智能体算法测试env.step()时的效果,若不收敛,找到不收敛的原因或者调参数使之收敛
工作量还是很大的。
修改的部分详见代码库各个的readme部分:https://github.com/wild-firefox/FreeRL
参考的代码:
1.https://github.com/Lizhi-sjtu/MARL-code-pytorch/tree/main/1.MAPPO_MPE (MAPPO_discrete代码 基本纯抄,强烈推荐)
关于MAPPO的bug
重新看了一下参考1实现的逻辑:发现了我的以下bug:
在学习更新(learn函数)时
计算优势值时没有用到所有智能体的奖励,而是只用到了一个当前智能体的奖励。
具体修改如下:将这里一开时计算的每个智能体对应的adv改成计算一个全局的adv。
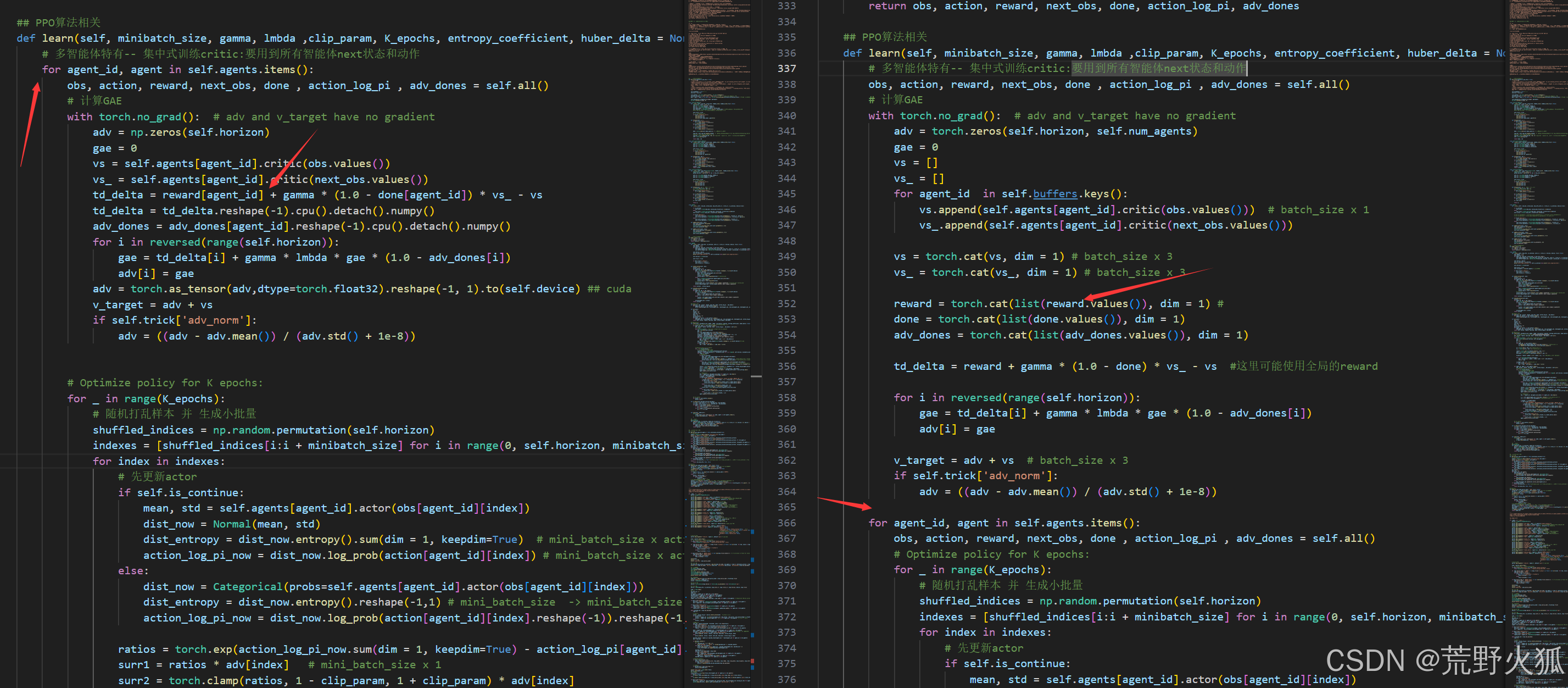
这里的v_target也是需要修改的。
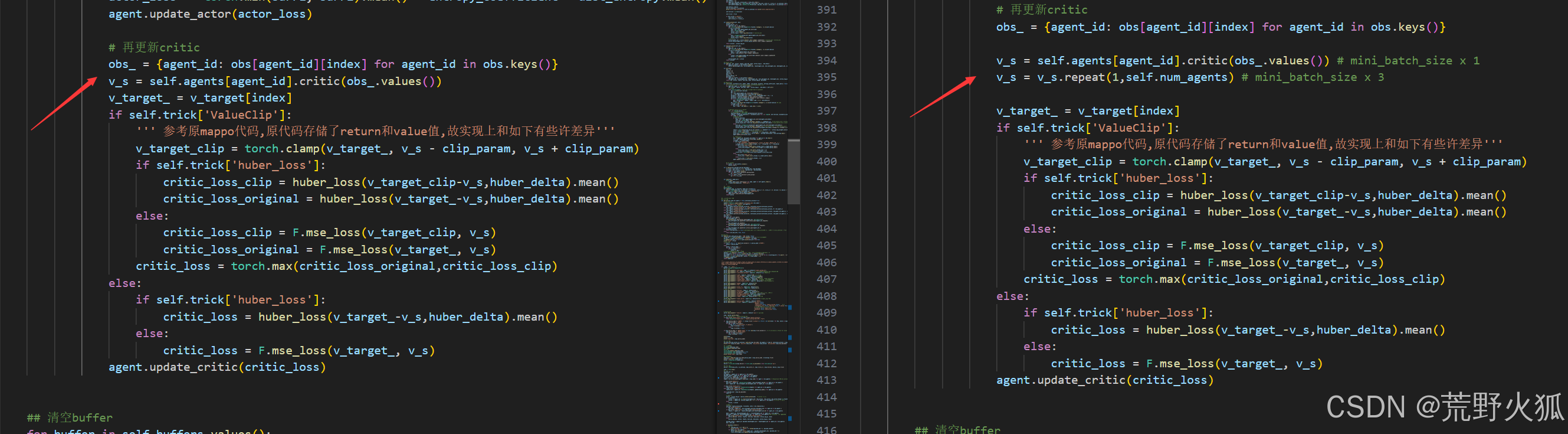
最后实现MAPPO在continue环境下env.step()下的收敛。
MAPPO_discrete的复现
主要对参考1只进行了框架的迁移,加入了cuda可训练版本,去掉了RNN网路和状态加入agent_id的可选项(由知乎上大佬说过,不加也可以),去掉了训练时评估部分,改为训完后单独一个文件评估(即之前的库的框架模式)。
同参数下,复现结果如下:
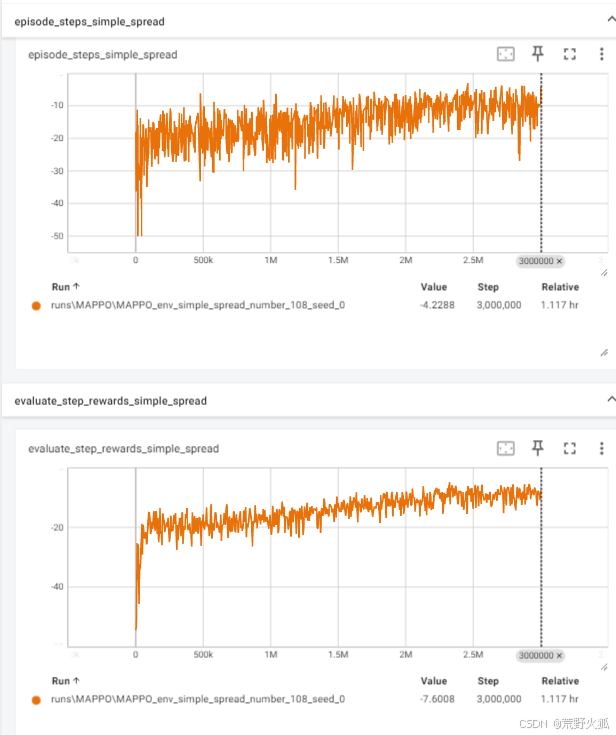
原代码:横坐标为step,第一张图为训练的图,第二张图为评估的图。(代码中是每隔5000步评估3次取平均,所以曲线相对平缓)
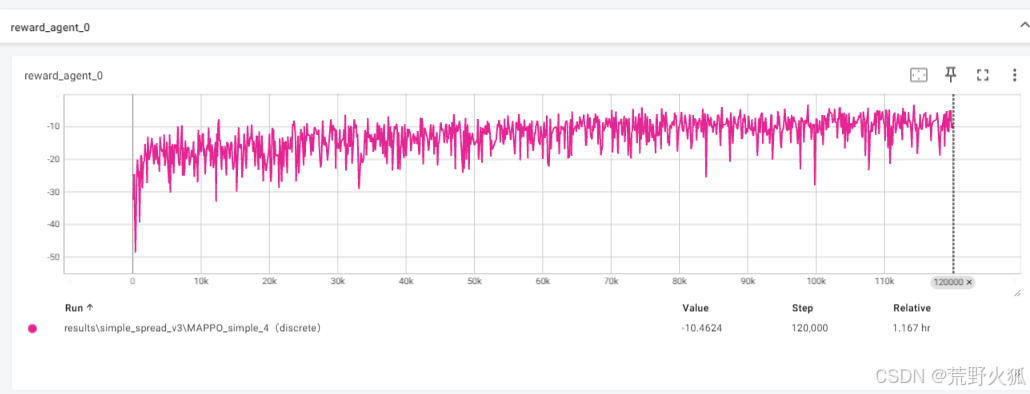
复现代码:未加评估,效果如下,与上面几乎相同。
环境不固定种子的鲁棒性问题
解决了上述MAPPO的bug后,再测试了之前写过的所有代码,发现算法应该是没有问题的。
经过测试,总结了如下学习率。
(环境为Pettingzoo的simple_spread_v3)
MARL的学习率总结:AC学习率一致(针对env.step(),智能体个数为3的情况下,其他未提到的学习率均不收敛/收敛不明显)
注:具体详见各个MARL的库的readme.md,简单固定种子环境下,1e-3均能收敛(MAT是5e-4除外)
MADDPG / MATD3: 5e-4 continue
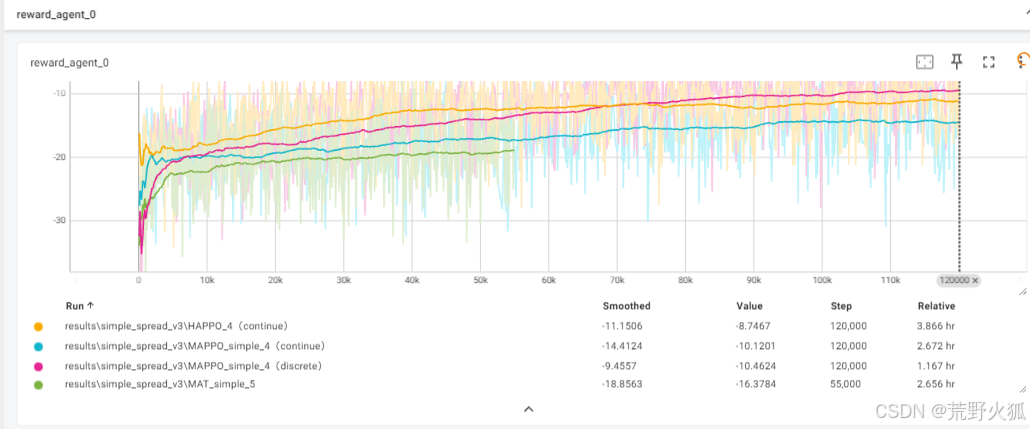
MAPPO:5e-4 continue
MAPPO_discrete:1e-3/5e-4 continue
HAPPO:1e-4 continue
MAT:1e-4 continue
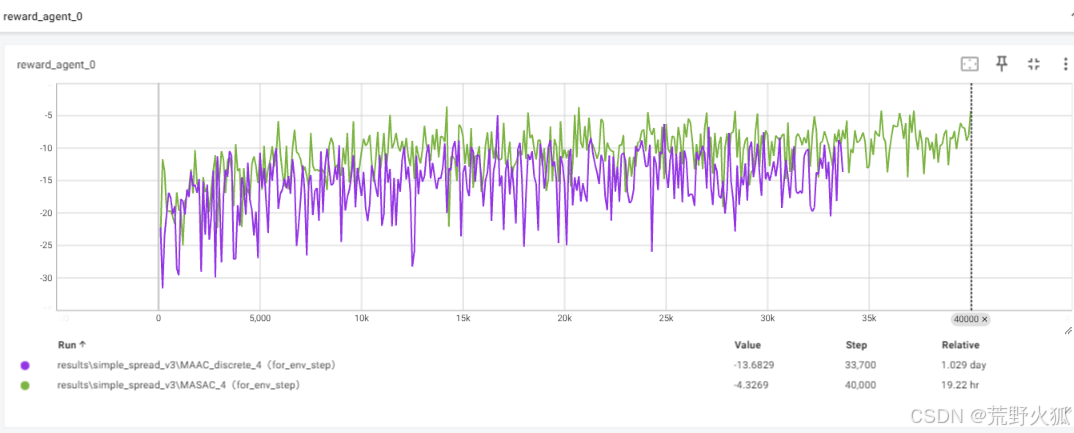
MASAC:1e-4 continue
MAAC_discrete:5e-4 discrete
展示效果:
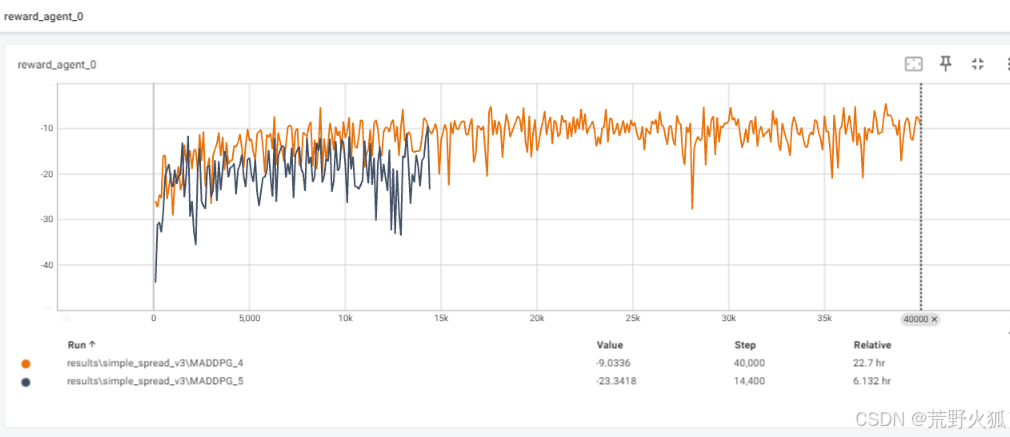
MAPPG: _4的其他参数也改过(具体见此文件夹的readme),_5只改了学习率
MATD3应该和MADDPG效果差不多,并未实验。
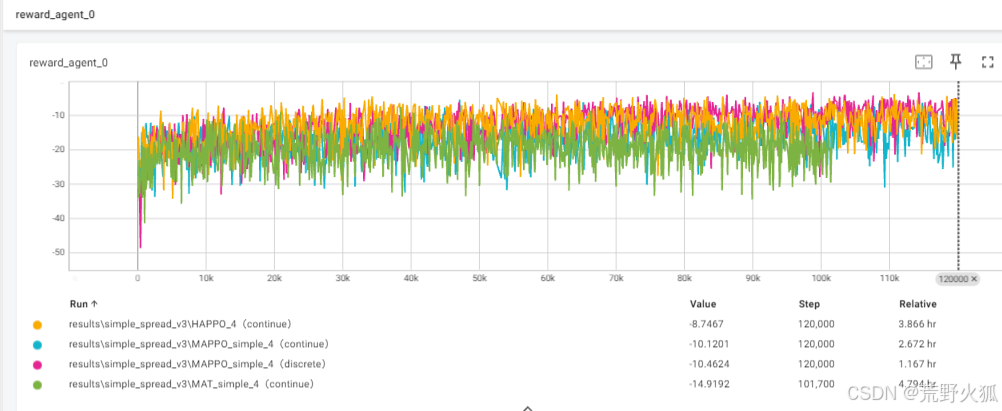
PPO系列展示效果
SAC系列展示效果:
补充
1.对于MAT的复现效果不及其他,可能是对对代码还不够深入了解清楚,对于离散域的环境在效果上也不行。
2.此库复现算法的效果可能不及原论文,更推荐阅读和尝试原论文的代码。

















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









