






现在有这样一个数据:
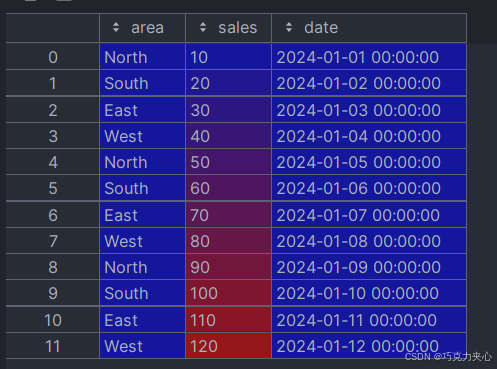
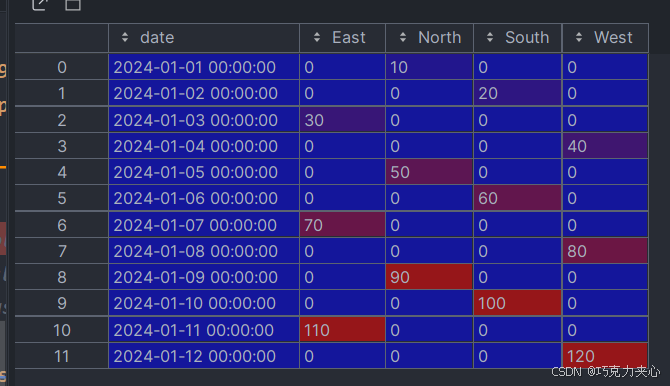
需要将area列进行打横,数据列是sales,转换成这样:
1. 使用DataFrame自带的pivot_table()方法
优点:设计上更加直观和用户友好,提供了直接的参数来指定行、列、值以及聚合函数。对于大多数数据透视的需求,pivot_table 提供了一种更为简洁的方法。
缺点:虽然强大,但在某些高级用例中不如 groupby + unstack 灵活。
import pandas as pd
# 创建示例数据
data = {
'area': ['North', 'South', 'East', 'West'] * 3,
'sales': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120],
'date': pd.date_range(start='2024-01-01', periods=12)
}
df = pd.DataFrame(data)
# pivot_table参数解析
"""
data: DataFrame 类型,这是需要进行透视操作的数据集。
values: 单个或多个列名,这些列将被聚合。例如,如果你想要计算某个数值列的总和或平均值,就需要指定这个参数。
index: 单个或多个列名,这些列将作为透视表的行索引。可以是字符串或字符串列表。
columns: 单个或多个列名,这些列将作为透视表的列索引。可以是字符串或字符串列表。
aggfunc: 聚合函数,用于对 values 中的数据进行聚合操作。可以是单个函数(如 np.sum)、字符串(如 'sum')或函数列表。默认为 np.mean。
fill_value: 用于替换缺失值的值,默认为 None。
margins: 布尔值,是否添加所有值的合计行和列。默认为 False。
dropna: 布尔值,是否从结果中删除包含缺失值的行。默认为 True。
margins_name: 合计行和列的名称,默认为 'All'。
observed: 布尔值,是否忽略未观察到的分类。默认为 False。
"""
df = df.pivot_table(index='date', columns='area', values='sales',fill_value=0).reset_index()
print(df)2. 使用groupby+unstack
优点:提供更大的灵活性,允许你执行更复杂的分组和重塑操作,适合那些超出 pivot_table 能力范围的情况。
缺点:性能取决于具体的数据集和使用的聚合函数。对于非常大的数据集,它可能会因为创建中间结果而消耗更多内存。
import pandas as pd
# 创建示例数据
data = {
'area': ['North', 'South', 'East', 'West'] * 3,
'sales': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120],
'date': pd.date_range(start='2024-01-01', periods=12)
}
df = pd.DataFrame(data)
# unstack 是 pandas 库中的一个方法,它用于将DataFrame的最内层(默认情况下)或指定层级的行索引转换为列索引,从而将数据从长格式转换为宽格式。这个操作有时也被称为“旋转”或“透视”。unstack通常与groupby一起使用,以实现数据的聚合和重塑。
"""
unstack 参数
level:可以是整数或字符串,指明要转换为列的索引级别。如果是整数,则表示级别编号;如果是字符串,则直接给出级别名称。
fill_value:用于替换新生成的DataFrame中缺失值的对象,默认是NaN。如果你希望用特定值代替缺失值,可以指定这个参数。
"""
df = df.groupby(['date','area'])['sales'].sum().unstack(fill_value=0).reset_index()
print(df)3. 使用apply()自定义方法
使用apply()方法实现一种类似于SQL中的case when操作,利用case when 的逻辑进行打横,速度非常快,可定制化极高
import pandas as pd
def split_row_data(row_df, classify):
"""
自定义函数,按照groupby的分类分割每一行数据
:param row_df: 会自动传入每一行的dataframe
:param classify: groupby的类别
:return:
"""
if row_df[col_name] == classify:
return row_df[value_name]
else:
return 0
# 创建示例数据
data = {
'area': ['North', 'South', 'East', 'West'] * 3,
'sales': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120],
'date': pd.date_range(start='2024-01-01', periods=12)
}
df = pd.DataFrame(data)
col_name = 'area'
value_name = 'sales'
col_df = df.groupby(col_name)[value_name].sum()
col_classification = list(col_df.index)
for classification in col_classification:
# axis=1沿着行方向应用函数
df[classification] = df.apply(split_row_data, args=(classification,), axis=1)
# 根据需求选择是否保留打横之前的聚合列
new_cols = [col for col in list(df.columns) if col not in [col_name, value_name]]
print(df[new_cols])
















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









