







Spring MVC的五大核心组件
1. DispatcherServlet
前端控制器,用于统一接受请求并分发,组织处理请求的流程
- 如果是使用web.xml文件配置项目的web环境的项目,需要显示的在web.xml配置它,例如影射的请求路径,并确保它是web容器(例如tomcat)在启动时就初始化的,并在初始化时会加载spring环境。
- 如果是使用spring注解来配置springMVC环境的先买个,则不需要直接配置它,而是通过自定义一个AbstractAnnotationConfigDispatcherServletInitializer的子类来直接配置,例如配置它映射的请求路径
- 如果是使用SpringBoot框架的web项目,甚至可以不需要知道它的存在,默认映射的路径是/*,当然,如果认为由必要的话,也可以配置为其他值。
2. HandlerMapping
它是一个接口,spring MVC框架内置了简单的实现类:SimpleUrlHandlerMapping,用于影射请求路径与处理请求的控制器,但是,在实际应用中,并不会直接使用这个实现,二十使用@RequestMapping注解,或者进阶的@PostMapping、@GetMapping,直接配置请求路径与处理请求的方法的映射关系。
3. Controller
由开发人员创建的,实际处理请求的控制器
- 通常由多个,一般根据需要处理的请求所涉及的核心数据类型来区分,例如与用户相关的请求则创建UserController,与订单相关的请求则创建OrderController
- 这些类必须放在组件扫描的包或其子孙包下,并添加@Controller注解,或添加@RestController注解,由于主流的开发模式是服务器端向客户端响应正文,通常使用的是@RestController
- 一般还会在这些类的声明之前添加@RequestMapping注解,以统一设计URL中的前缀路径
- 每个控制类中将有若干个处理请求的方法
4. ModelAndView
Controller组件处理完请求后得到的结果,由数据与视图名称组成
- 在实际开发中,由于springMVC提供了更加便捷的API,通常并不直接使用这个类型作为方法的返回值,当需要转发数据时,可以在方法的参数列表中添加ModelMap对象用于封装需要转发的数据,并使用string类型的返回值表示视图的名称,如果需要重定向,则返回以redirect:作为前缀的string即可。
- 主流的开发模式时服务器端向客户端响应正文,完全不需要使用该类型的对象。
5. ViewResolver
视图解析器,可根据视图名称(由ModelAndView返回)确定需要使用的视图组件
- Spring MVCM架内置了简单的实现类:InternalResourceViewResolver,当使
用JSP文件作为视图时将使用它,主要配置prefix和suffix这2个属性,Spring
MVC框架会将prefix的值、控制器返回的视图名称、suffix的值拼接起来,以确
定JSP文件的位置并使用 - 使用Thymeleaf的模版页面作为视图组件时,则配置ThymeleafViewResolver,
配置思想大致相当,但需要另外配置Thymeleaf的模版引擎和模版解析器 - 主流的开发模式是服务器端向客户端响应正文,完全不需要使用该组件
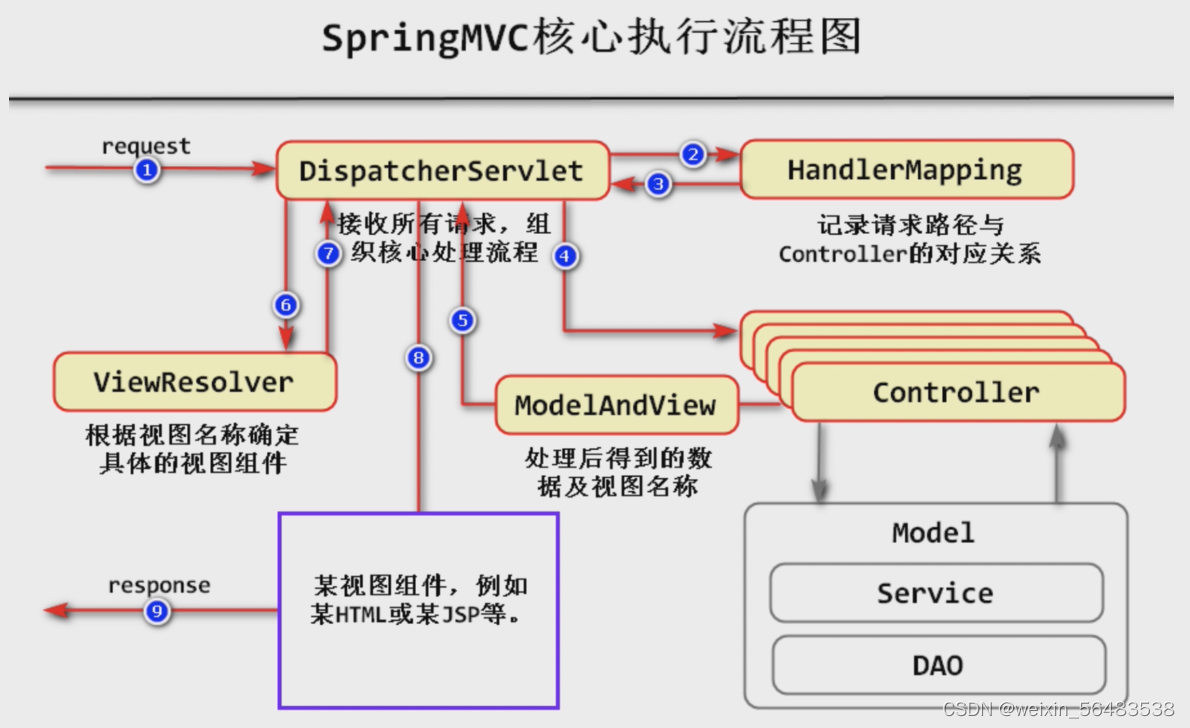
tips:要完全了解五个核心组件的使用还需学习《基于XML配置的springMVC》扩展视频教程,技术较老。
springbean的生命周期
简单生命周期
-
通常,需要讨论生命周期的类型,都是由开发人员编写,但不由开发人员自行管 理的,例如Java EE中的Servlet组件,它是由Web容器(例如Tomcat)进行管理 的,而Spring Bean是由Spring框架进行管理的。
-
无论是Servlet,还是Spring Bean,都不由开发人员管理,所以,开发人员需要知道它们的生命周期,即:什么时候会被创建出来,什么时候会被销毁,并且,在什么情景下会被调用什么方法,以Servlet为例,幵发人员必须知道Servlet中的init()方法会在什么时候被调用,还有service()方法、destroy()方法,只有了解了生命周期方法,才能明确在哪个方法里编写什么代码。
- 例如:当你在使用Servlet时,如果处理数据需要使用到某个流对象,那么,你
不应该在Servlet的init()方法中调用流对象的close()方法
- 例如:当你在使用Servlet时,如果处理数据需要使用到某个流对象,那么,你
-
Spring允许你在类中自定义初始化和销毁的2个生命周期方法
- 初始化方法:将在构造方法之后被调用
- 销毁方法:将在销毁之前被调用
-
这2个方法的声明:
- 公有权限
-被外部调用,应该使用公有权限 - 返回值类型使用void
- 方法名称自定义
- 参数列表为空
-可以添加boolean类型的参数
- 公有权限
-
仅符合单例特性的Spring Bean才需要讨论生命周期
-
即:scope偵为singleton (默认)
-不要称之为单例模式
-
如果scope值为prototype,对象按需创建(通过开发人员的代码,什么时候获 取Bean什么时候创建),用完即销毁(通常是局部变量,方法运行结束后即销 毁),开发人员可以完全控制创建后、销毁前的操作,无需Spring管理。
-
完整的生命周期
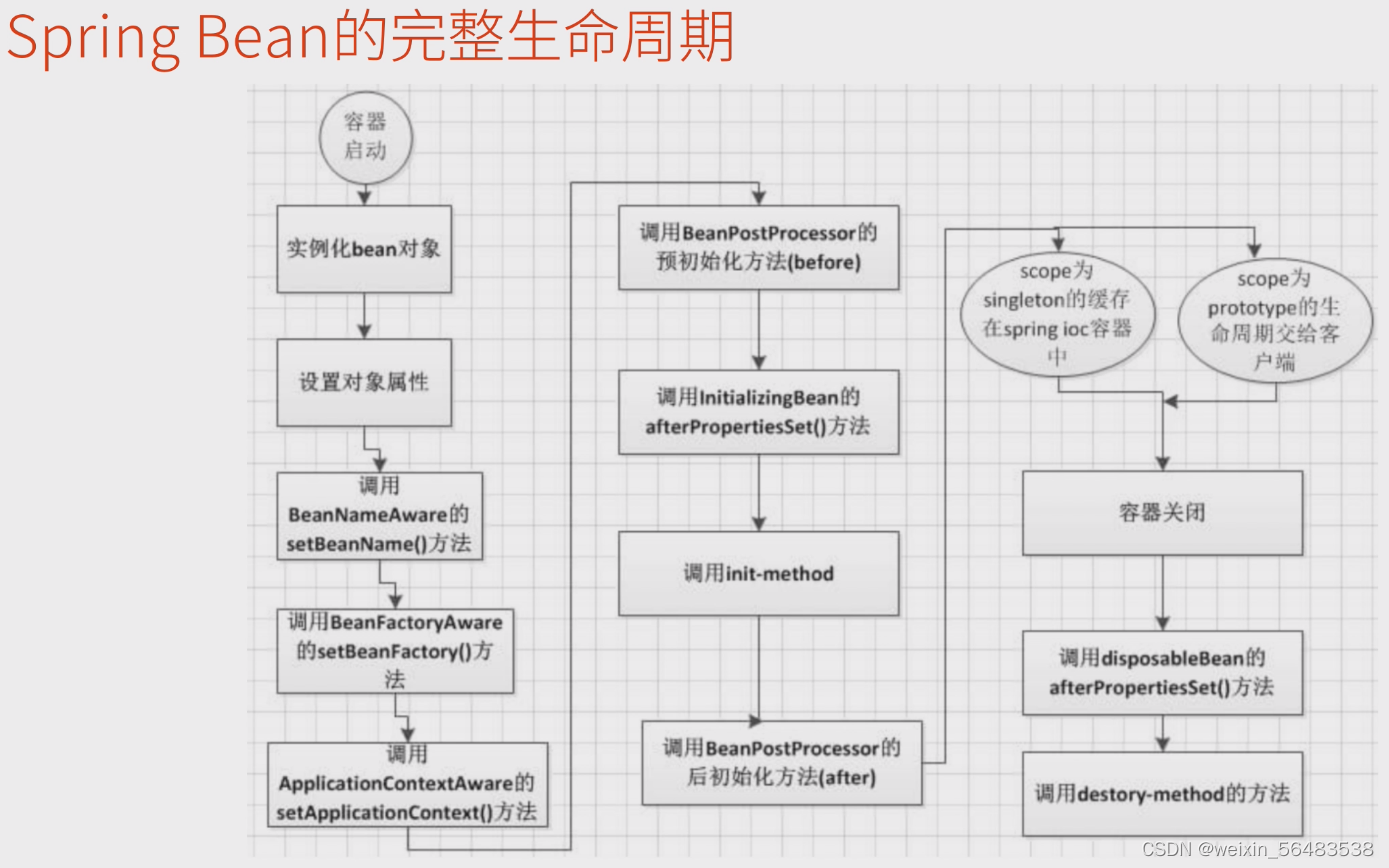
- 提示:Spring Bean的完整生命周期更加复杂,绝大部分环节是由spring框架自动完成,开发人员能够干预的部分非常有限,与自定义生命周期方法相差不大。
生命周期流程
-
实例化Bean:对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。对于Applicationcontext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
-
设置对象属性(依赖注入):实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息以及通过BeanWrapper提供的设置属性的接口完成依赖注入。
-
处理Aware接口: Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean
-
实现BeanNameAware接口
- 调用setBeanName(String beanld)方法,传递的是Bean的id
-
实现BeanFactoryAware接口
- 调用 setBeanFactory(BeanFactory bean Factory)方法,传递的是 Spring 工厂自身
-
实现ApplicationContextAware接口
- 调用setApplicationContext(ApplicationContext)方法,传入Spring上下文
-
小结:无论实现了哪种xxxAware接口,Spring都会自动调用其对应的方法,并且自动传递方法的参数
-
-
BeanPostProcessor:如果想对Bean进行一些自定义的处理,可以使Bean实现BeanPostProcessor接口,该接口中包含会在初始化之前、初始化之后的2个方法:
-
Object postProcessBeforelnitialization(Object bean, String beanName) throws BeansException
- 此时会调用
-
Object postProcessAfterlnitialization(Object bean, String beanName) throws BeansException
- 后续会调用
-
-
InitializingBean:如果实现了该接口,则调用afterPropertiesSet()方法
-
自定义初始化:如果Bean配置了初始化方法(自定义的),则会自动调用
- 如果需要干预,直接操作这一步就行,之前的交给spring框架
-
BeanPostprocessor:尝试调用postProcessAfterlnitialization()方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术。
注意:至此,Bean就已经被正确创建了,之后就可以使用这个Bean了。 -
DisposableBean:当Bean不再需要时(例如Spring Applicationcontext销毁之前),将准备销毁,如果Bean实现了DisposableBeanli口,会调用destroy()方法。
-
自定义销毁:如果Bean配置了销毁方法(自定义的),则自动调用。
面试总结
-
讨论Spring Bean的生命周期是因为Bean由Spring框架进行管理,以致于我们能够明确Bean会在什么时候创建、什么时候销毁,并且,当有必要的情况下,能够在创建之后、销毁之前进行干预,执行自定义的一些代码,只有作用域为“单例”(即scope值为singleton)时才讨论这个问题,否则,当作用域为prototype时,Bean会在获取对象时创建,局部的Bean会在方法执行结束后被销毁,其间的过程我们可以完全把控,则不需要讨论生命周期的问题。
-
Spring Bean的完整生命周期大致有9个阶段:
① 实例化Bean
② 设置对象属性(依赖注入)
③ 【如果实现了接口】
④ 【如果实现了接口】
⑤ 【如果实现了接口】
⑥ 自定义初始化
处理Aware接口
BeanPostProcessor.postProcessBeforelnitialization()
InitializingBean.afterPropertiesSetO
⑦ 【如果实现了接口】
⑧ 【如果实现了接口】
⑨ 自定义销毁 -
比较常用的是自定义初始化方法和销毁方法,它们将分别在构造方法之后和销毁之前被调用
- 如果使用XML文件配置<bean>,可以配置<bean>的init-method和destroy-method属性以应用这2个自定义方法。
- 如果使用配置类的@Bean方法创建对象,可以在@Bean注解中配置init-method和d est roy- m eth od属性以应用这2个自定义方法。
- 如果项目使用了javax包,还可以选择分别在这2个自定义方法之前添加@PostConstructffl@PreDestroy 注解。
事务
什么是事务
事务是数据库中保证一系列的写操作要么全部成功,么全部失败的机制
- 如果只有1次写操作,可以不是事务性的
- 如果只有读操作,可以不是事务性的
- 如果有2次或以上次数的写操作,必须是事务性的
事务的传播表现
事务的传播表现为:某个数据访问过程中调用了另一个事务,事务应该如何执行
- 当前数据访问过程可以不是事务性的
- 当前数据访问过程也可以是事务性的,即:X事务调用Y事务
- 例如某种传播方式为:暂停当前事务,执行另一个事务,完毕后继续执行当前
事务
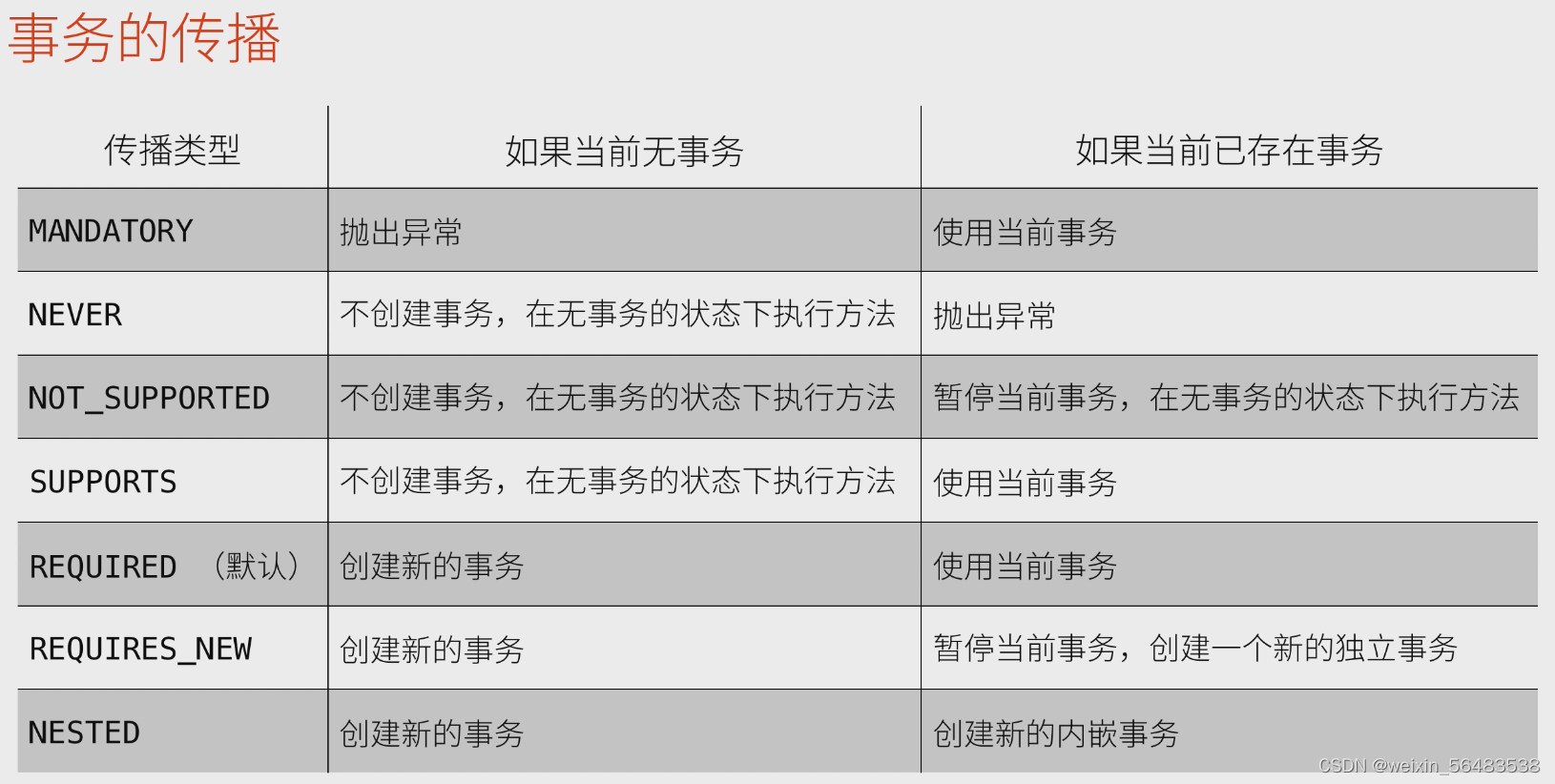
注:绝大多数使用默认的传播方式即可
关于@Transactional注解
-
在使用Spring管理事务的项目中,可以使用@Transactiona[注解,以表示某个方法是事务性的。
-
通过@Transactional的propagation属性可以配置事务的传播方式。
- 该注解是spring-tx.jar中的
- 该注解是spring-tx.jar中的
-
可以添加在接口的声明之前,或添加在接口的实现类的声明之前
- 推荐添加在接口的声明之前,因为实现类可能变化
- 将作用于接口中声明的所有方法
-
可以添加在接口中的抽象方法的声明之前,或添加在接口的实现类中实现的方法的声明之前
- 推荐添加在接口中的抽象方法的声明之前,因为实现类可能变化
- 仅作用于当前方法
- 如果接口/实现类和方法都添加了该注解,并配置不同,则方法级的配置会覆盖接口/类级的配置
-
通常应用于业务层,并且,业务层必须有接口和其实现类
- Spring管理事务是基于接口代理的
- 如果没有接口,却使用了(©Transactional,启动项目时会报错
- 当出现类内部的方法之间的调用,被调用的方法之前的@Transactional无效
- Spring管理事务是基于接口代理的
-
Spring框架管理事务,帮助幵发人员解决了不同数据库编程技术在处理事务时需
要编写的代码不同的问题- JDBC:需要使用Connection对象调用setAutoCommit(false)、commit。、
rollback。 - JPA:需要使用EntityManager对象调用getTransaction()得到Transaction对
象,然后使用Transaction对象调用begin()、commit()、rollback()。 - Hibernate:需要使用会话对象调用beginTransaction(),并使用Transaction
对象调用commit()、 rollback() - 还有其它数据库编程技术,需要编写的代码也不相同
- JDBC:需要使用Connection对象调用setAutoCommit(false)、commit。、
-
Spring提取了本地事务和分布式事务的区别,在编写业务代码时,只需要掌握@Transactional注解的正确使用即可,无需关注事务是本地的还是分布式的
- 如果需要使用分布式事务,配置分布式事务的事务管理器即可
spring管理事务的原理
-
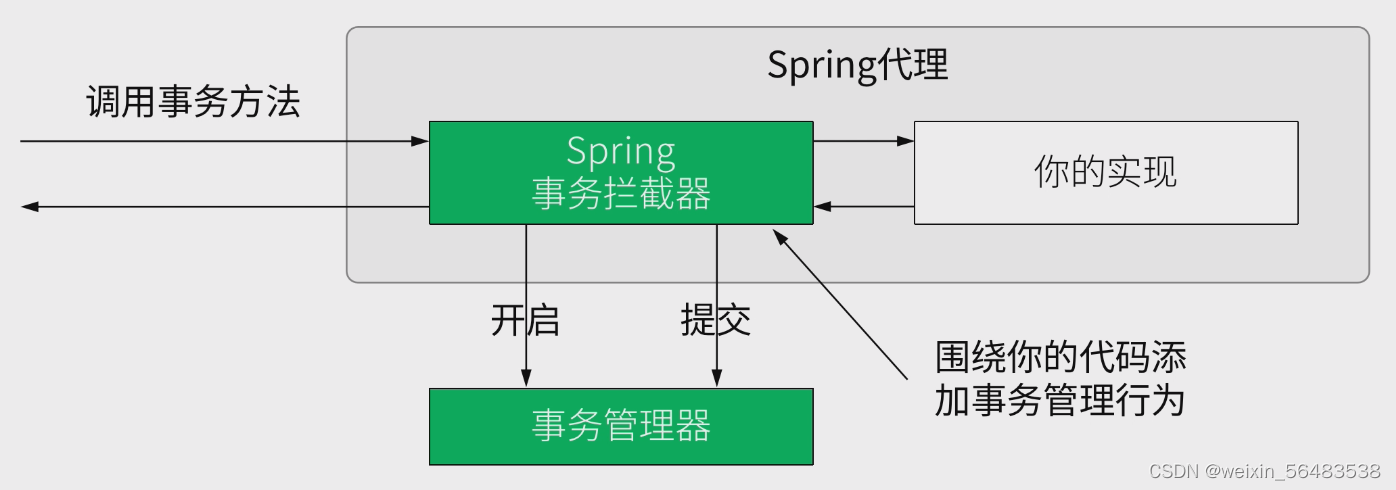
Spring会生成接口的代理对象,并通过AOP实现管理事务的
-
你的业务将被包裹在代理中
-
使用"around"类型的Advice
-
-
Spring管理事务的过程中添加的事务管理行为:
- 在执行你的业务方法之前,开启事务
- 如果业务方法顺利执行结束,则提交事务
- 如果业务方法抛出异常,则回滚事务
- 默认情况下,仅当抛出RuntimeException时回滚,可以通过@Transactional注解的rollbackFor和noRollbackFor属性进行配置
事务总结
-
事务的传播方式共有了种:
- MANDATORY
- NEVER
- NONSUPPORTED
- SUPPORTS
- REQUIRED
- REQUIRES_NEW
- NESTED
-
事务注解是@TranscationaL 这是Spring框架(spring-tx.jar,当添加spring-jdbc.jar时会依赖)定义的注解。
-
Spring框架会基于接口代理模式来管理事务,其实现原理上使用了AOP技术,使用Around类型的Advice包裹了业务方法,以添加事务管理行为。
-
Spring框架管理事务,帮助开发人员解决了不同数据库编程技术在处理事务时需
要编写的代码不同的问题,也提取了本地事务和分布式事务的区别,当需要使用
分布式事务时,只需要配置事务管理器即可,业务代码的编写方式不变。 -
Spring框架管理事务时,会在代理对象调用业务方法之前幵启事务,如果业务方
法顺利执行结束,则提交事务,如果业务方法抛出异常,则回滚事务,默认情况
下,仅当抛出RuntimeException时回滚,可以通过@Transactional注解的
rollbackFor 和 noRollbackFor 属性进行配置。 -
实际使用原则:
-
通常在业务层处理事务,当使用Spring管理事务时,由于它是基于接口代理模式的,所以必须先创建业务接口,再创建业务实现类,如果某个业务方法涉及多次(超过1次)写操作,那么,它需要是事务性的,则可以在方法的声明之前添加@Transactional注解,或者,也可以将注解添加在业务接口的声明之前,这会使得当前接口中的所有方法都是事务性的,当然,还可以将注解添加在业务实现类的声明之前,或业务实现类中实现的方法的声明之前,由于实现是可能调整的,所以更推荐在接口中使用这个注解。
-
当需要管理事务的传播方式时,配置@Transactional注解的propagation属性即可,在绝大部分情况下,没有必要刻意的设置事务的传播方式,使用默认的REQUIRED即可,它表现为:如果当前无事务,将创建新的事务,如果当前已存在事务,则使用当前事务。
-
Mybatis
Mybatis的分页实现
Mybatis本身没有对分页的专门处理,开发人员在编写SQL语句时使用LIMIT子句自行分页即可:
List<User> findList(@Param("offset")Integer offset,
@Param("count")Integer count);
<select id="findList" resutMap="BaseResultMap">
SELECT * FROM user LIMIT #{offset}, #{count}
</select>
产生的问题
- 查询的数据大多需要响应到客户端,当客户端显示数据列表时,仅仅响应一个数
据列表是不够的,通常还需要分页相关的多个数据,例如:- 当前第几页
- 查询的已知条件
- 共几页(总页数)
- 其它数据
- 当前第几页
- 为了满足客户端显示数据列表的需求,还需要自行查询总记录数,并计算总页数
及相关数据
PageHelper 插件
-
PageHelper是一款专门用于Mybatis的分页插件
- https://github.com/pagehelper/Mybatis-PageHelper
- 提示:之所以将PageHelper称之为“插件”,是因为它是基于Mybatis拦截器
实现的,而Mybatis将拦截器定位为Plugin (插件)
-
你只需要在执行查询之前设置页码与查询结果最大数量即可:
//查询结果最大数量,也是每页数量,应该是相对固定的值 //可能来自配置文件,或用于配置的数据表 private Integer count; public PageInfo<User> findList(Integer page) { PageHelper.startPage (page, count); List<User> list = userMapper.findList(); PageInfo<User> pagelnfo = new Pagelnfo<>(list); return pageInfo; } -
按以上方式执行查询,得到的结果(Pagelnfo对象)中将封装了许多实用的分页
数据,例如:- 查询得到的List集合
- 最大页数
- 它在执行你的查询之前,会先查询总记录数
- 当前页码
- 是否有上一页
- 是否有下一页
- 是否为第1页
- 是否为最后一页
- 其它
-
PageHelper对数据访问层代码是”非侵入性“的
- 你不需要调整你在使用Mybatis时编写的任何数据访问层的代码,只需要在业务逻辑层调用数据访问层之前添加代码即可实现分页。
面试题考察点
- 关于“Mybatis的分页实现”问题的考察点应该在于:Mybatis的拦截器。
拦截器:
- Mybatis提供了拦截器(Interceptor)接口,允许幵发者自定义执行拦截器:
@Intercepts({@Signature(method = "prepare", type = StatementHandler.class,
args = {Connection.classr Integer.class}),
@Signature(method = "query", type = Executor.class,
args = {MappedStatement.class, Object.class, RowBounds.class,
ResultHandler.class, CacheKey.class, BoundSql.class})})
public class CustomMybatisInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Th rowable {
//编写你的实现
return invocation.proceed(
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
@Override
public void setProperties(Properties properties) {
}
}
-
在配置SqlSessionFactoryBean时应用拦截器
@Bean public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource) throws Exception { SqlSessionFactoryBean SqlSessionFactoryBean = new SqlSessionFactoryBean(); SqlSessionFactoryBean.setDataSource(dataSource); SqlSessionFactoryBean.setMapperLocations(mapperLocations); SqlSessionFactoryBean,setPlugins(new CustomMybatisInterceptor()); return sqlSessionFactoryBean; } -
如果已经配置好了SqlSessionFactory,添加拦截器:
@Configuration @ConditionalOnBean(SqlSessionFactory.class) @AutoConfigureAfter(Mybatis的配置类.class) public class MybatisInterceptorConfiguration { @Autowired private List<SqlSessionFactory> sqlSessionFactoryList; @PostConstruct public void addlnterceptor() { for (SqlSessionFactory sqlSessionFactory : sqlSessionFactoryList) { sqlSessionFactory.getConfigurationf).addlnterceptorf new CustomMybatisInterceptor()); } } }
-
Mybatis的拦截器可以做到分页效果,但是,实现成本比较高:
- 需要创建拦截器
- 需要配置应用拦截器
- 拦截器内部设定相关规则
- 对哪些方法执行拦截并分页
- 分页参数(offset/count)如何获取
-
所以,一般不手动编写拦截器实现分页,而是使用PageHelper
-
PageHelper也是通过Mybatis拦截器实现的
-
如果在Springs Mybatis框架下使用PageHelper,必须自行配置它的Mybatis拦截器
-
如果在Spring Boot项目中添加的是pagehelper-spring-boot-starter依赖,则它已经自动注册了 Mybatis拦截器,你可以直接使用。
-
注意:PageHelper在处理分页参数时,使用了ThreadLocal,即分页参数与线程
是绑定的,所以是线程安全的,但PageHelper.startPage()与调用持久层查询必
须是连续的2条语句:
面试参考
- 如果在面试时,面试官出了这道题,其考察的知识点应该是:
- 是否了解过Mybatis的拦截器
- 是否知道PageHelper的实现原理
- 为避免被面试官的后续问题难倒,建议:
- 专门学习Mybatis的拦截器
- 需对Mybatis的执行原理有一定了解
- 查看PageHelper的拦截器相关源代码
- 难度不算大
- 专门学习Mybatis的拦截器
总结
- 在使用Mybatis编程时,可以在编写SQL语句时添加LIMIT子句,并在查询方法中添加LIMIT子句所需的参数,即可实现分页查询,但是,分页查询可能还需要总页数等其它数据,需要专门查询总记录数并计算,操作相对繁琐。
- 在实际幵发时,可以使用PageHelper分页插件,它是专门用于Mybatis框架的,本质上是使用Mybatis拦截器实现的,如果在Spring- Mybatis框架下使用PageHelper,必须自行配置它的Mybatis拦截器,如果在Spring Boot项目中添加的是pagehelper-spring-boot-starter依赖,则它已经自遂注册了Mybatis拦截器。
- 使用PageHelper插件时,持久层代码不需要关心分页相关的内容,仅需要调用持久层查询之前调用PageHelper.startPage()方法即可实现分页,并且,还可以将查询到的结果用于创建Pagelnfo对象,该对象中封装了许多实用的分页数据,例如当前页数、总页数等。
Mybatis缓存机制
缓存的概念
- 将数据临时存储在某个位置,并且,通常伴随特定的清除临时存储的数据的机制
- 通常,从临时存储位置获取数据的成本更低
- 使用Mybatis查询数据时,完整来说是查询数据库中的数据,则需要连接到数据库服务器,并且从数据库服务器的硬盘中查询所需的数据,无论是连接,还是查询硬盘数据,都是比较耗时的,则可以事先(第1次查询时,或者更早时……)将数据查出来并保存到应用服务器的内存中,则需要数据时直接使用即可。
- 通常,从临时存储位置获取数据的成本更低
缓存的作用
- 提高获取数据的效率
- 在绝大部分应用程序中,查询在所有数据访问(增、删、改、查)中的占比可
能超过80%,因此,查询效率非常重要
- 在绝大部分应用程序中,查询在所有数据访问(增、删、改、查)中的占比可
缓存机制
Mybatis有2种缓存机制,分别称之为一级缓存和二级缓存,当需要查询数据时,会优先从二级缓存中查询数据,如果没有命中,则从一级缓存中获取,如果仍未命中,则从数据库中查询数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
Mybatis的一级缓存
-
会话缓存:基于SqISession的缓存
- SqISession:类似JDBC的Connection,但它在Mybatis中负责许多操作,例如处理SQL语句中的参数、执行SQL语句、获取执行结果、处理事务……
- 仅同一会话、执行相同查询、参数相同时生效
-例如:在同一会话中多次执行select count(*) from user ,或多次执行
select * from user where id=? 且 ?的值相同
-
会话缓存的清理
- 会话结束
-自然结束,或显式的调用了SqlSession的close。方法 - 执行了任何写操作(增、删、改)之后
-一旦执行了写操作,此前缓存的结果可能不准确 - 执行了任何清理缓存的方法
-例如:执行了SqlSession的dearCache()方法
- 会话结束
-
会话缓存的特点:
- 由Mybatis自行管理
-通常,幵发人员不需要干预,绝大部分过程也无法干预 - 主要适用于同一会话短时间内连续的相同查询
-不同会话、不同查询,甚至查询参数不同时,均不适用,所以应用场景较少
- 由Mybatis自行管理
-
练习指导(基于Spring Boot的项目):
-
在application.properties中将日志级别设置为较低,例如trace
-
Mybatis默认会岀输出日志,包括执行的SQL语句、参数、执行结果等,只是日志级别较低,默认并不显示
-
logging.level.当前项目根包=trace
-
-
在测试类中进行测试
- 自动装配Sq(SessionFactory
- 在测试方法中:
-调用SqISessionFactory的openSession()方法,得到SqISession对象
-调用SqISession对象的getMapper。方法,得到Mapper接口的代理对象
-
反复执行相同的查询,可通过观察到:只执行了 1次SQL语句
-如果是较慢的查询,仅首次较慢,后续每一次几乎无耗时 -
更换查询参数(值必须不同),可以观察到:再次执行了SQL语句
-如果是较慢的查询,更换参数后的首次查询仍较慢 -
通过SqlSessionFactory得到新的SqlSession,并再次获取Mapper接口的对象,再查询,可以观察到:即使此前已经执行完全相同的查询,仍再次执行了SQL语句
-
Mybatis的二级缓存
-
namespace缓存:基于Mapper接口的缓存
- 默认未幵启
- 整合环境下,全局开启,各namespace未开启
- 无视是否同一会话
- 默认未幵启
-
开启namespace缓存
-
添加节点
<mapper namespace="xxxxxxx.OrderMapper"> <cache/> ...... </mapper> -
封装结果的类实现Serializable
-
-
关闭某些查询的缓存
在select语句配置加上useCache=“false”。
<select id="xxx" resultType="xxxx.xxentity" useCache="false"></select> -
namespace缓存的特点:
- 除非某些<select>节点配置了useCache=“false”,否则,当前namespace所有查询结果都会缓存
- 所有写操作(增、删、改)都会清理缓存
- 默认使用LRU (Least Recently Used:最近最少使用)算法清除
缓存总结
-
一级缓存:
- 由Mybatis自行管理,一定程度人为不可控
- 主要适用于同一会话短时间内连续的相同查询,适用场景少
-
二级缓存
- 不同会话均可共用
- 需要手动开启
- 不需要手动管理,默认使用LRU算法进行清理
- 同一个namespace中某些查询可配置为不缓存,但同一个namespace中幵启的多种查询的缓存的配置相同
-
无论是哪种缓存(包括Mybatis以外的其它缓存机制),都是“牺牲空间、换取时间”的做法
- 牺牲更多的存储空间(占用原本不会占用的空间),提高执行效率,以换取更多的可用时间
-
缓存的“效率”和“有效”难两全
- 即使缓存了数据,其它操作可能更新了数据
-如果不同步更新缓存,则缓存的数据不准确,甚至可能是无效数据
-如果同步更新缓存,则需要牺牲一定的效率
- 即使缓存了数据,其它操作可能更新了数据
-
使用缓存之前,你必须考虑:
- 你是否愿意牺牲缓存将占用的空间
-内存空间一般是比较宝贵的 - 希望缓存的数据的使用频率与更新频率
-如果更新频率非常低,而使用频率非常高,则是划算的 - 你是否需要保证缓存数据的有效性
-并不是所有数据都必须完全精准
-例如:某些榜单
- 你是否愿意牺牲缓存将占用的空间
-
Mybatis的一级缓存基本上“不用管”
-
Mybatis的二级缓存基本上“不好用”
- 同一个namespace下的所有查询的缓存配置均相同
- 自动使用算法清理,无法精准控制
- 每执行写操作后都会清理
- 应用服务器的内存可能本来就已经很紧张,再牺牲一定空间用于缓存,可能影响应用服务器处理数据的效率
-
由于Mybatis的二级缓存“不好用”,在实际幵发中,一般不使用Mybatis的二级缓存,而是使用专门的缓存技术,还可以使用专门的缓存服务器,甚至缓存服务器集群,以更全面、更细致的处理缓存
- 例如:使用 Memcached、Redis等
数据库
数据库视图
视图的作用
-
在绝大部分的关联查询中,都存在某些表中某些字段的数据是不需要被查询出来的,使用视图时,可以完全不关心这些的字段,甚至都不需要知道它们在真实的数据表中是否存在,所以可用于隐藏部分数据
- 即使只查某1张表,也经常不需要查询全部的字段
CREATE VIEW v_user_info AS select id, username, day_of_birth from user; select * from v_user_info; -
通过只查询部分字段,还可以使得MySQL中的某些用户被授权访问视图,却不授权访问原始数据表,使得这些用户无法访问某些数据,一定程度上提高了安全性
- 在MySQL中(或其它数据库系统中),可以创建多个用户,并分配不同权限
-
视图还可以跨表甚至跨域,可连接多张表甚至多台数据库
-
在小型应用的开发中可能并没有以上这些需求
-
由于视图并不是真实存在的数据表,物理上是不存在数据的,每次通过视图进行
查询时,本质上还是查询了真实的数据表,所以,它并不能提高查询效率,同时,
由于视图本身也不包含数据,所以,不可以对视图进行任何类型的写操作。
完整格式
CREATE
[OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPLABLE}]
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
总结
-
可以通过 CREATE VIEW view_name AS select_statement 格式的语句创建视图
-
可以将一些常用的、相对固定的复杂查询创建对应的视图,以减少反复编写长篇的、相同的SQL语句的开发量。
- 合理的使用视图,可以提高安全性。
-
视图还可以跨表甚至跨域,可连接多张表甚至多台数据库。
- 在小型应用的开发中可能并没有以上这些需求。
-
由于视图并不是真实存在的数据表,物理上是不存在数据的,每次通过视图进行查询时,本质上还是查询了真实的数据表,所以,它并不能提高查询效率,同时,由于视图本身也不包含数据,所以,不可以对视图进行任何类型的写操作。
数据库的索引
索引的概念
在关系数据库中,索引(Index)是一种单独的、物理的対数据库表中一列或多列的值进行排序的一种存储结构。
索引的作用
- 明显提高查询数据的效率
- 以3000万条数据的表为例,对“非索引”字段查询时,耗时可能超过5秒,对“索引”字段查询时,一般在毫秒级
-不同硬件可能略有不同
- 以3000万条数据的表为例,对“非索引”字段查询时,耗时可能超过5秒,对“索引”字段查询时,一般在毫秒级
创建索引
-
创建和删除索引的基本语法示例:
CREATE INDEX index_username ON user (username); DROP INDEX index_username ON user;index_username 自定义索引名称
user 数据表名称
username 需要创建索引的字段名称
- 注意:创建索引是比较耗时的操作
- 当前表中的数据越多,创建索引耗时越久
- 创建索引是一次性操作
- 注意:创建索引是比较耗时的操作
索引的原理
-
当没有索引时,MySQL只能从头到尾的尝试匹配要查询的数据,如果数据表中有3000万条数据,则会把这3000万条数据全部查一遍,且由于数据并不是集中存放在磁盘的某一个位置,而是散列存储的,所以在查询过程中会进行频繁的IO操作,导致查询效率低下!
-
•当创建索引时,MySQL会将对应字段的数据全部排序,并在索引中记录下每条数据的位置信息,索引就相当于“书的目录”,当需要查询数据时,会先翻这个“目录”,从而找到数据所在的“页码”(数据在磁盘中的位置),然后精准定位到数据在磁盘中的位置,所以查询效率非常高!
-
索引的本质是一种B+Tree结构(是一种树型结构)的数据,InnoDB存储引擎中页的大小为16KB,即使使用BIGINT类型的主键,也只占8字节,在B+Tree中使用的指针一般4~8字节,每个主键与指针形成B+Tree中的一个节点,则每个节点占用16字节,那么,每页至少可存储16KB/16B = 1000个节点,一个深度为3的B+Tree至少可以记录1000 x 1000 x 1000 = 1000 000 000个节点,并对应到实际的数据,即能够维护10亿条数据,所以,使用这种结构,只需要执行次10操作即可发现需要查询的数据,然后查询对应的数据即可。
-
在MySQL中,PRIMARY KEY (主键索引)、UNIQUE (唯一索引)、INDEX (索引)、FULLTEXT (全文索引)均使用B+Tree结构。
注意事项
-
基于索引的特性,在使用时必须注意:
- 索引不会包含有NULL值的列
- 数据量非常少的表没有必要创建索引,例如绝大部分字典表
- 数据会经常变动的表不要创建索引,因为会频繁更新索引,导致写入效率低下
- 查询时字段值需要运算会导致索引失效,例如where age + 1 > 18B寸age的索引将失效
- 左侧模糊查询无法使用索引,因为索引是基于对数据进行排序得到的
-
不同的企业对索引的使用可能有更高的要求,例如:
- 如果varchar的长度超过一定范围,不允许使用索引
- 类型为text的字段不允许使用索引
- 其它要求

















 7251
7251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









