








论文标题:自动文本检索中的术语加权方法
论文链接:https://www.cs.colostate.edu/~howe/cs640/papers/salton_termWeighting.pdf
在自动文本检索中,术语加权(Term Weighting)是一种非常重要的技术。它通过对文档中每个词的权重进行计算,以确定其在检索过程中的重要性。这种方法可以帮助搜索引擎更准确地找到用户所需的文档。
常用的术语加权方法有以下几种:
- TF-IDF(Term Frequency-Inverse Document Frequency):这是一种经典的术语加权方法,它结合了词频(TF)和逆文档频率(IDF)两个因素。TF-IDF 的基本思想是:如果一个词在一个文档集中的出现频率较高,而在特定文档中的出现频率较低,那么这个词对于这个文档的重要性就越高。
- BM25(Best Match 25):这是一种基于概率的术语加权方法。BM25 认为一个词对文档的重要程度取决于它在文档中的出现频率和在整个文档集中的出现频率。与 TF-IDF 不同的是,BM25 还考虑到了文档的长度因素。
- Language Modeling:语言建模是一种通过建立文档的语言模型来计算术语权重的方法。它的基本思想是:一个好的术语应该能够帮助我们更好地预测文档中的其他词。常见的语言建模方法包括 N-gram、Hidden Markov Model(HMM)和 Latent Dirichlet Allocation(LDA)等。
- Deep Learning:深度学习是一种通过神经网络模型来计算术语权重的方法。它可以自动地从大量文本数据中学习到有用的特征,并用于提高文本检索的准确性。常见的深度学习模型包括 Convolutional Neural Network(CNN)、Recurrent Neural Network(RNN)和 Transformer 等。
这些术语加权方法各有优缺点,在实际应用中可以根据具体需求选择合适的方法。
摘要
过去20年的实验数据表明,基于分配适当加权的单个词的文本索引系统可以产生比其他更复杂的文本表示方法更好的检索结果。这些结果在很大程度上取决于有效术语权重系统的选取。本文总结了自动术语加权的见解,并提供了基本的单术语索引模型,以便与其他更复杂的文本分析方法进行比较。
1. 自动文本分析
在20世纪50年代末,Luhn [1]首次提出,可以通过比较存储的文本和用户信息查询的内容标识符来设计自动文本检索系统。通常,从文档和查询的文本中提取某些词汇用于内容识别;或者,内容表示可以通过熟悉所考虑的主题领域和文档集合内容的专业索引员手动选择。在两种情况下,文档都将通过如下形式的词向量来表示:
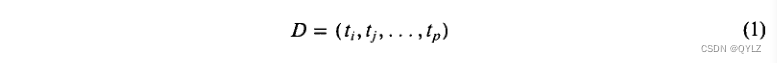
其中每个tk标识分配给某个样本文档D的内容项。类似地,信息请求或查询可以表示为向量形式或布尔语句形式。因此,一个典型查询Q可能被制定为:
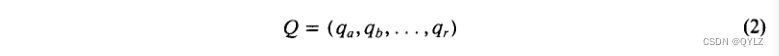
或者
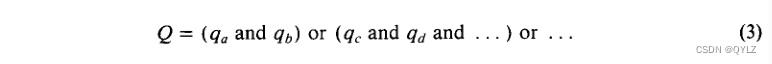
在这里,qk再次表示分配给查询Q的项。
通过在每个向量中包含系统中允许的所有可能的内容项,并添加项权重分配以提供项之间的区别,可以更正式地表示方程式(1)和(2)中的术语向量。因此,如果W&(或Wqk)表示在文档D(或查询Q)中术语tk的权重,并且有t个术语可用于内容表示,那么文档D和查询Q的词向量可以写成:
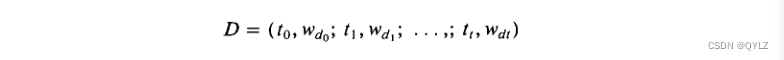
和
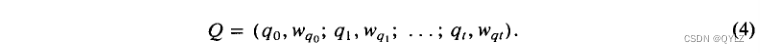
在上述公式中,假定当术语k未分配给文档D(或查询Q)时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









