



 本文介绍了文本处理中词项权重(Term weighting)的概念及其计算方法,重点讲解了TF-IDF模型,并探讨了如何通过词项权重提取短文本的核心词汇。
本文介绍了文本处理中词项权重(Term weighting)的概念及其计算方法,重点讲解了TF-IDF模型,并探讨了如何通过词项权重提取短文本的核心词汇。
对文本分词后,接下来需要对分词后的每个term计算一个权重,重要的term应该给与更高的权重。举例来说,“什么产品对减肥帮助最大?”的term weighting结果可能是: “什么 0.1,产品 0.5,对 0.1,减肥 0.8,帮助 0.3,最大 0.2”。Term weighting在文本检索,文本相关性,核心词提取等任务中都有重要作用。我们可以把这个拿来进行对我们构建的词向量进行加权。
Term weighting的打分公式一般由三部分组成:local,global和normalization。即
TermWeight=L_{i,j}、 G_i、 N_j。L_{i,j}是term i在document j中的local weight,G_i是term i的global weight,N_j是document j的归一化因子。
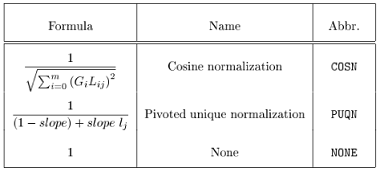
常见的local,global,normalization weight公式有:
Local weight formulas:

Global weight formulas:

Normalization factors:
TF-IDF:
Tf-Idf是一种最常见的term weighting方法。在上面的公式体系里,Tf-Idf的local weight是FREQ,glocal weight是IDFB,normalization是None。tf是词频,表示这个词出现的次数。df是文档频率,表示这个词在多少个文档中出现。idf则是逆文档频率,idf=log(TD/df),TD表示总文档数。Tf-Idf在很多场合都很有效,但缺点也比较明显,以“词频”度量重要性,不够全面,譬如在搜索广告的关键词匹配时就不够用。
核心词、关键词提取
- 短文本串的核心词提取。对短文本串分词后,利用上面介绍的term weighting方法,获取term weight后,取一定的阈值,就可以提取出短文本串的核心词。

















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









