







基于前三天的学习,我们知道了浏览器与服务器基于HTTP协议下的工作流程与报文格式(返回值为html文档),并不是我们想要的直观图片,txt等内容。那我们接下来的目标就很简单了,把得到的报文转化成我们想要的内容。
(原理:html文档组成中body标签对是指HTML页面中的<body>标签和</body>标签,这些标签用于包含页面的主要内容,例如文本、图片、视频等。body标签对中的内容会在页面上显示,是网页的核心部分。有时文件内容太大,会指向一个固定存储地址,也需要我们辨别)
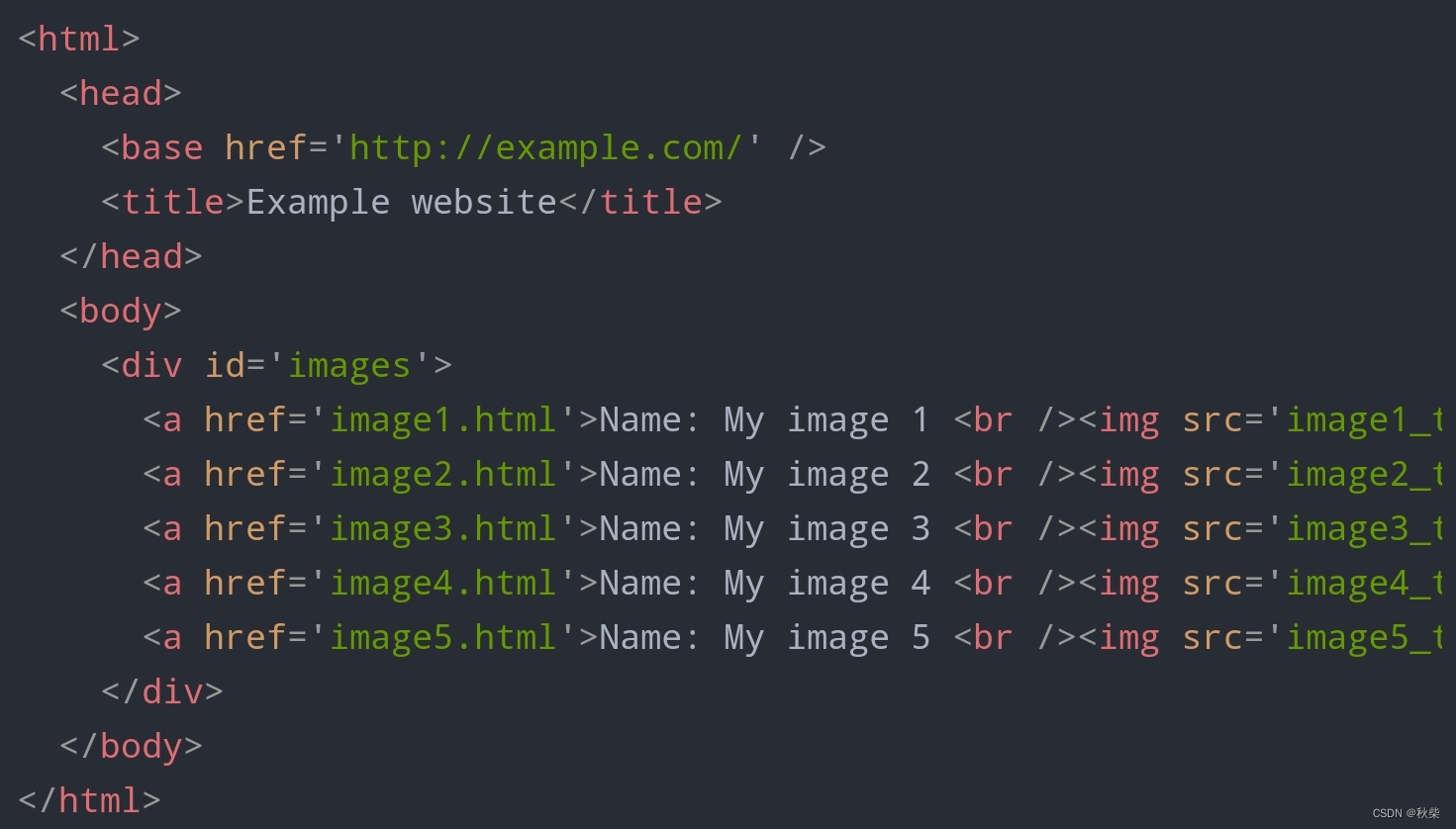
即通过我们规定好的提取规则,将HTML文档中的一些特殊资源片段(类似有css,xpath,下载资源地址等)提取出来,这些资源再经过后续处理美化(比如下载,保存,求和,统计等),就可以得到我们最终需要的资源。
这个过程,我们称为创建selector选择器
(注释:这也是整个简单爬虫过程中最难的部分,这里的简单包括两层意思:
1:selector常用的创建方法规则是统一的,无论是re正则,还是XPATH,亦或是Beautiful soup和parse,他们的匹配方法大同小异,一法通万法通
2.我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











