






 文章介绍了爬虫学习的关键点,强调理解网络协议和Scrapy框架的重要性,而非单纯记忆函数。讨论了请求与响应的交互,数据解析和存储,以及如何处理登录、验证码和加密数据的挑战。文中还提到将通过实例项目深化对爬虫的理解。
文章介绍了爬虫学习的关键点,强调理解网络协议和Scrapy框架的重要性,而非单纯记忆函数。讨论了请求与响应的交互,数据解析和存储,以及如何处理登录、验证码和加密数据的挑战。文中还提到将通过实例项目深化对爬虫的理解。
更新一点爬虫的基本知识(scrapy框架,计算机协议以及一个入门案例)
p1.网络协议
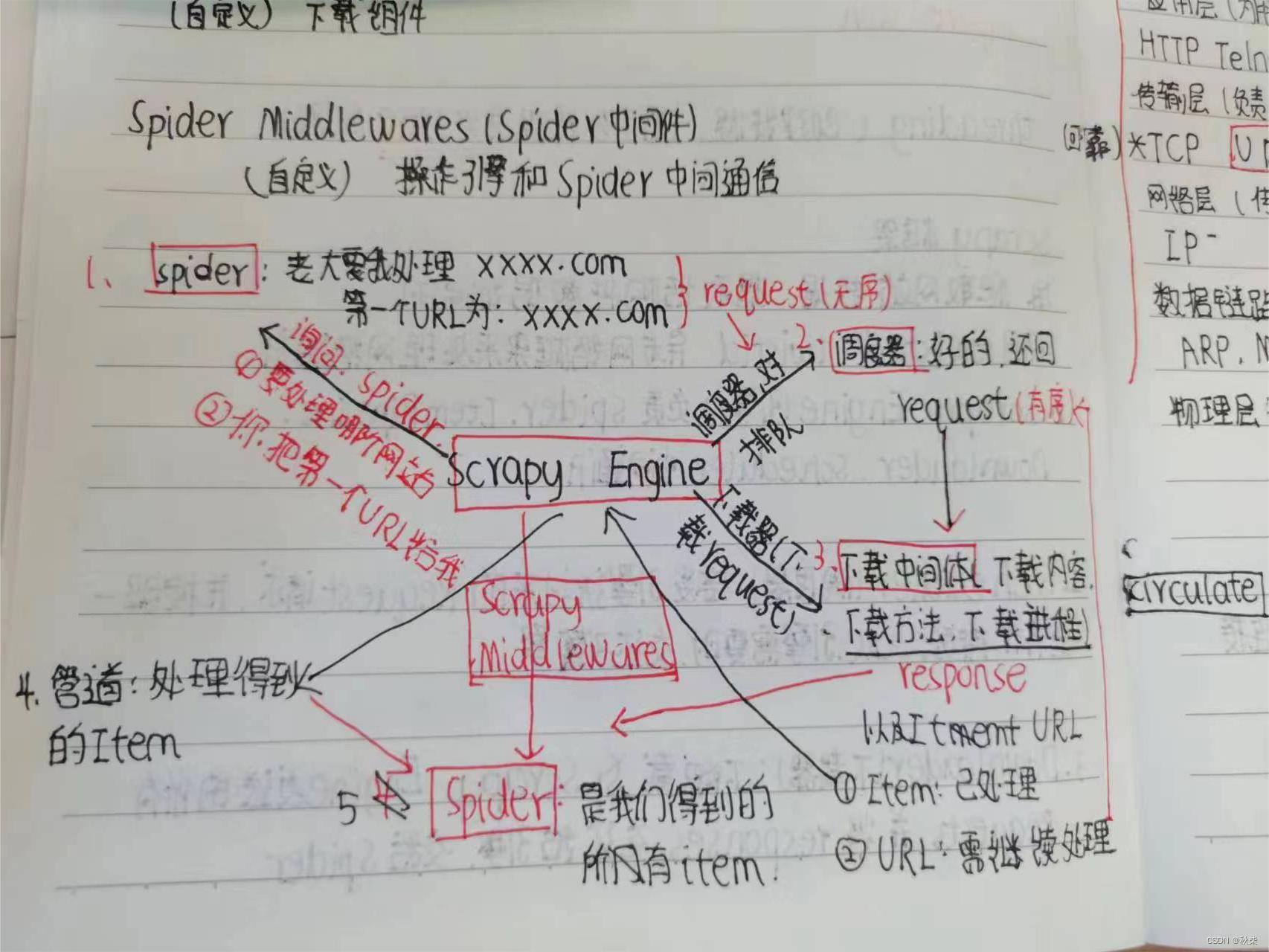
p3.scrapy框架
p5.程序案例及解析
个人观点:学习爬虫,不要像学习pandas,matplotlib这些库一样,事无巨细的记忆每一个函数。爬虫需要我们像浏览器一样思考,也就是需要回答以下的问题:
基本问题:
1.对于浏览器来说,我们的request是什么(url还是?)
2.浏览器对于我们的request怎样从服务器中获得response(xml,二进制数,json)
3.怎么样把response转换成我们可以读懂的文字(lxml,beautiful Soup),又以什么样的方式呈现(数据库,txt,excel等)
4.怎么样按照我们的心意爬取合适的数据(设计合适的下载中间体)
5.为什么爬虫程序要这样设计?(基于网络协议)
更高一级的问题:
1.怎么样给我们的爬虫做装饰,防止被网站察觉我们不是“正常人”?(虚拟身份的合理性)
2.如果必须要登录才可以爬取,怎么样给自己设置一个虚拟身份?(测试法)
3.如果需要目标网站需要图片/计算/短信验证码才能看到数据,我们应该怎么办?(简单算法)
4.网站的数据被以某种可解的方式进行加密,我们怎么样进行破解?(数据加密技术与反破解)
5.如果数据仅VIP可见,我们怎么样绕过它获得数据?(逆向工程)
等等......不一而足,但是仍然有途径可以解决。


 这里回答了我们的问题之一,为什么在爬取https/http协议下的网页时,需要进行请求头设计,在该协议下,响应端的报文决定了必须这样做 ,,
这里回答了我们的问题之一,为什么在爬取https/http协议下的网页时,需要进行请求头设计,在该协议下,响应端的报文决定了必须这样做 ,,

# 这是第一天,接下来的几天会逐步由浅入深,结合实例去做一些有趣的爬虫项目,让大家真正了解爬虫(没准会拿学校的官网开刀)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











