







不为失败找理由,只为成功找方法。所有的不甘,因为还心存梦想,所以在你放弃之前,好好拼一把,只怕心老,不怕路长。
python系列之函数进阶
python系列前期章节
- python系列之注释与变量
- python系列之输入输出语句与数据类型
- python系列之运算符
- python系列之控制流程语句
- python系列之字符串
- python系列之列表
- python系列之元组
- python系列之字典
- python系列之集合
- python系列之函数基础
一、lambda函数:简单操作的速写
lambda函数是高阶函数的其中一部分,如果一个函数有一个返回值,并且只有一句代码,就可以使用lambda简化。
# 传统写法
def square(x):
return x ** 2
# lambda语法
lambda 参数列表 : 表达式
# lambda写法
square = lambda x: x ** 2
# 实际应用:列表排序
students = [("Bob", 88), ("Alice", 95), ("Eve", 78)]
students.sort(key=lambda s: s[1], reverse=True)
print(students) # [('Alice', 95), ('Bob', 88), ('Eve', 78)]
直接打印lambda表达式,输出的是此lambda的内存地址。
# 创建 可以使用一个变量接收返回的值
fn1 = lambda a, b: a + b
# 调用传参和普通函数一样
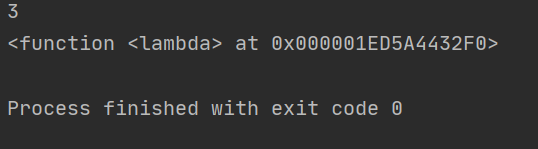
print(fn1(1,2))
# 直接打印,是打印其内存地址
print(fn1)
运行结果:
【注意事项】:
1、lambda表达式的参数可有可无;
2、函数的参数在lambda表达式中完全适用;
3、lambda表达式能接收任何数量的参数但只能返回一个表达式的值。
4、直接打印lambda表达式,输出的是此lambda的内存地址。
二、闭包:记住状态的函数
场景:生成计数器
def create_counter(start=0):
count = start
# 闭包
def counter():
nonlocal count
count += 1
return count
return counter
# 创建独立计数器
c1 = create_counter()
c2 = create_counter(100)
print(c1(), c1()) # 1 2
print(c2(), c2()) # 101 102
三、函数式编程
把函数作为参数传入,或者返回值是另一个函数,这样的函数称为高阶函数,高阶函数是函数式编程的体现。函数式编程就是指这种高度抽象的编程范式。
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
1、函数的参数是函数
需求:对任意两个数字,整理后再求和
首先看传统的方式
def sum_num(a, b):
"""
这种方式虽然实现了该需求,但是不够灵活
"""
return abs(a) + abs(b)
再看函数式编程
# 使用高阶函数实现该需求,参数作为函数
def sum_num2(a, b, f):
"""
:param a: 数值1
:param b: 数值2
:param f: 传入一个函数,lambda也是函数
:return:
"""
# f()是函数,传入的函数,这里做求和
return f(a) + f(b)
# 调用,直接函数名,不用加括号()
print(sum_num2(20, -3, abs))
# 使用lambda来做乘方
print(sum_num2(2, 3, lambda x: x ** 2))
【说明】由此可见,使用高阶函数比传统的方式在某些情况下会灵活很多。
2、函数的返回值是函数
高阶函数除了可以接受函数作为参数外,还可以把函数作为返回值返回。一个函数返回值(return)为另一个函数。
案例需求:求一堆数据的和
# 参数使用的是不定参数形式
def sum_num3(*args):
# 定义函数,这里使用了闭包概念
def my_sum():
sums = 0
# 循环求和
for x in args:
sums += x
return sums
# 返回函数,也是直接名字,不用加括号()
return my_sum
# 调用 ,直接打印是打印其函数地址,如:<function sum_num3.<locals>.my_sum at 0x000001B534033510>
print(sum_num3(20, 10, 5))
# 调用要和平时一样后面加括号(),因为返回的是函数,即调用函数名()
print(sum_num3(20, 10, 5)())
四、必须掌握的5大内置高阶函数
1. map函数:数据转换流水线
map函数说明: map函数接收的是两个参数,一个是函数名,另一个是序列,其功能是讲序列中的数值作为函数的参数依次传入到函数值中执行,转化再返回列表中,返回的是一个迭代器对象。
图解:

场景:电商价格批量转换
prices = [100, 200, 300]
# 传统循环写法
discounted = []
for price in prices:
discounted.append(price * 0.8)
# 函数式写法
discounted = list(map(lambda x: x*0.8, prices))
print(discounted) # [80.0, 160.0, 240.0]
# 配合自定义函数
def apply_discount(price, rate=0.8):
return price * rate
discounted = list(map(apply_discount, prices))
2. filter函数:智能数据筛选
filter函数说明: python内建的filter()函数用于过滤序列,和map()类似,filter()也接收一个函数和一个序列;但不同的是filter()把传入的函数依次作用于每一个元素,然后根据返回值是True还是False决定元素的保留与丢弃。
场景:筛选合格考试成绩
scores = [85, 92, 58, 76, 43]
# 传统写法
passed = []
for score in scores:
if score >= 60:
passed.append(score)
# 函数式写法
passed = list(filter(lambda x: x >= 60, scores))
print(passed) # [85, 92, 76]
3. reduce函数:数据聚合计算
reduce函数说明: reduce函数也是一个参数作为函数,另一个参数为序列对象(比如list列表)。其返回值为一个值而不是迭代器对象,故其常用于叠加、叠乘等。
场景:计算购物车总金额
# 该函数不在默认包中,所以要导入
from functools import reduce
cart = [{"name": "牛奶", "price": 25},
{"name": "面包", "price": 15},
{"name": "鸡蛋", "price": 12}]
# 传统写法
total = 0
for item in cart:
total += item["price"]
# 函数式写法
total = reduce(lambda acc, item: acc + item["price"], cart, 0)
print(total) # 52
4. sorted函数:灵活排序
sorted函数说明: python内置的sorted()函数就可以对list进行排序;和序列中本身的sort函数类似。
场景:学生成绩排名
students = [
{"name": "Alice", "score": 88},
{"name": "Bob", "score": 95},
{"name": "Eve", "score": 78}
]
# 按分数降序排列
sorted_students = sorted(students,
key=lambda x: x["score"],
reverse=True)
print([s["name"] for s in sorted_students]) # ['Bob', 'Alice', 'Eve']
5. zip函数:数据配对
zip函数说明: zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
场景:合并用户信息
names = ["Alice", "Bob", "Charlie"]
ages = [25, 30, 28]
emails = ["a@test.com", "b@test.com", "c@test.com"]
# 生成用户字典列表
users = [{"name": n, "age": a, "email": e}
for n, a, e in zip(names, ages, emails)]
print(users)
# [{'name': 'Alice', 'age': 25, 'email': 'a@test.com'}, ...]
五、函数式编程实战:电商数据分析
# 原始订单数据
orders = [
{"id": 1, "amount": 150, "category": "electronics"},
{"id": 2, "amount": 80, "category": "clothing"},
{"id": 3, "amount": 200, "category": "electronics"},
]
# 1. 过滤电子类订单
electronics = filter(lambda x: x["category"] == "electronics", orders)
# 2. 提取金额列
amounts = map(lambda x: x["amount"], electronics)
# 3. 计算平均金额
from functools import reduce
average = reduce(lambda a, b: a + b, amounts) / len(list(amounts))
# 链式写法
average = (
reduce(lambda a, b: a + b,
map(lambda x: x["amount"],
filter(lambda x: x["category"] == "electronics", orders)))
/ len(list(filter(lambda x: x["category"] == "electronics", orders)))
)
print(f"电子类订单平均金额: {average}") # 175.0
六、常见误区与最佳实践
❌ 错误示范:滥用嵌套lambda
# 难以阅读的写法
result = list(map(lambda x: (lambda y: y**2)(x) + 10, range(5)))
# 推荐写法
def process_num(x):
squared = x ** 2
return squared + 10
result = list(map(process_num, range(5)))
✅ 最佳实践:适当结合传统写法
# 混合使用更清晰
high_scores = [s for s in scores if s > 90] # 列表推导式
total_score = reduce(lambda a,b: a+b, high_scores)
⚠️ 闭包变量陷阱
# 错误写法
funcs = []
for i in range(3):
funcs.append(lambda: i**2)
print([f() for f in funcs]) # [4, 4, 4] 而不是预期的[0,1,4]
# 正确写法
funcs = []
for i in range(3):
funcs.append(lambda i=i: i**2) # 捕获当前值
七、综合项目:搭建智能数据处理管道
# 定义处理函数
def read_data(file): return [1, -2, 3, -4, 5]
def clean_negative(data): return filter(lambda x: x > 0, data)
def double_values(data): return map(lambda x: x*2, data)
def sum_values(data): return reduce(lambda a,b: a+b, data)
# 组合处理流程
processing_pipeline = [
clean_negative,
double_values,
sum_values
]
# 执行管道
data = read_data("data.txt")
result = data
for process in processing_pipeline:
result = process(result)
print(f"最终结果: {result}") # (1+3+5)*2 = 18
八、结语
前一章讲解了函数基础,本章讲解了函数进阶,到此的话,函数的知识点就告一段落咯,但是函数的使用后续会很频繁,所以对于函数这一块要高度重视,使用好函数,会让代码看起来很优雅、简洁。

















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









