






1. 安装 Anaconda
如果你还没有安装 Anaconda,请按照以下步骤安装:
-
访问 Anaconda 官网 下载适合你操作系统的安装包。
-
安装 Anaconda,安装过程中勾选 “Add Anaconda to PATH”(将 Anaconda 添加到系统环境变量)。
-
安装完成后,打开终端(Windows 上是 Anaconda Prompt,macOS/Linux 上是 Terminal),输入以下命令检查是否安装成功:
conda --version如果显示版本号(如
conda 23.9.0),说明安装成功。
2. 创建并配置 Conda 环境
-
打开终端,创建一个新的 Conda 环境(例如命名为
yolov8_env):conda create --name yolov8_env python=3.9这里使用 Python 3.9,因为它是 TensorFlow 和 YOLOv8 都支持的版本。
-
激活环境:
conda activate yolov8_env -
安装必要的依赖:
conda install numpy pandas matplotlib jupyter
4. 安装 YOLOv8
-
在激活的 Conda 环境中安装 YOLOv8:
pip install ultralytics -
验证 YOLOv8 是否安装成功:
python -c "from ultralytics import YOLO; print(YOLO)"如果没有报错,说明安装成功。
-
如果无法用pip下载可以到git上面下载源代码,放到项目中
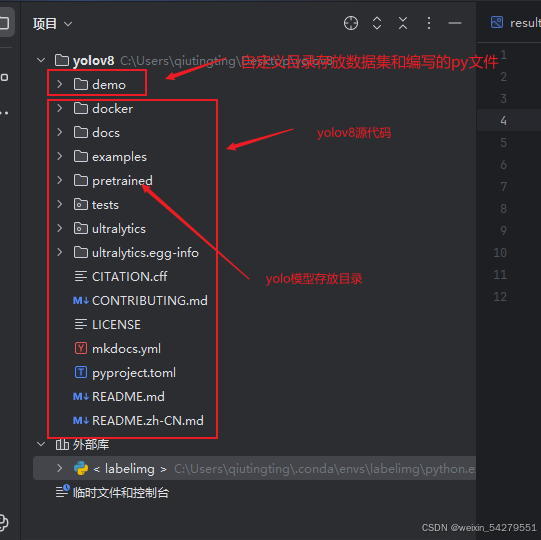
5. 配置 PyCharm
-
安装 PyCharm:
-
如果还没有 PyCharm,可以从 JetBrains 官网 下载并安装。
-
-
配置 Conda 环境:
-
打开 PyCharm,创建一个新项目。
-
在项目设置中,选择
File->Settings->Project: <项目名>->Python Interpreter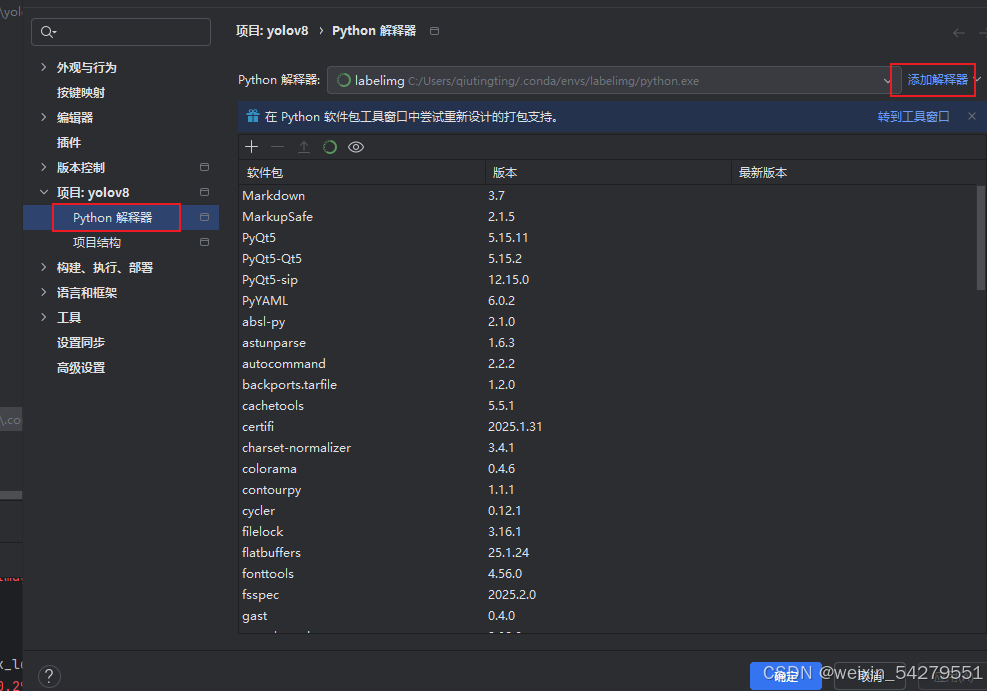
-
选择
Add Interpreter->Conda Environment->Existing environment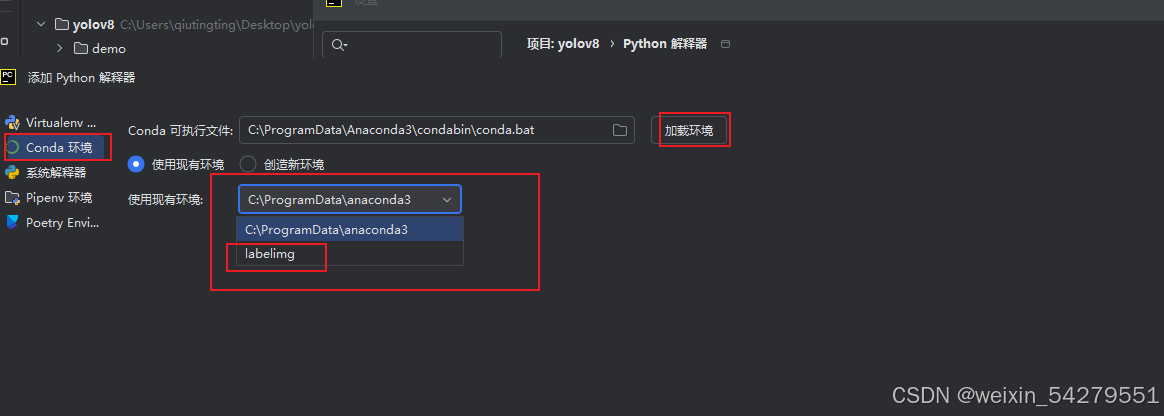
-
-
验证 PyCharm 配置:
-
在 PyCharm 中创建一个 Python 文件(如
test.py),输入以下代码:import tensorflow as tf from ultralytics import YOLO print("TensorFlow version:", tf.__version__) print("YOLO version:", YOLO) -
运行代码,如果输出 TensorFlow 和 YOLO 的版本号,说明配置成功。
-
6. 准备数据集
-
下载数据集:
-
你可以使用公开的数据集(如 COCO 或 VOC),或者准备自己的数据集。
-
数据集需要包含图像和对应的标注文件(如 YOLO 格式的
.txt文件)。
-
-
组织数据集:
-
数据集目录结构示例:
dataset/ ├── images/ │ ├── train/ # 存放训练集的图像文件(如 .jpg、.png) │ └── val/ # 存放验证集的图像文件 └── labels/ ├── train/ # 存放训练集的标签文件(.txt,YOLO 格式) └── val/ # 存放验证集的标签文件 -
确保每个图像文件(如
image1.jpg)对应一个标注文件(如image1.txt)。
-
-
创建数据集配置文件:
-
在项目目录下创建一个 YAML 文件(如
dataset.yaml),内容如下:# dataset.yaml train: dataset/images/train # 训练集图像路径 val: dataset/images/val # 验证集图像路径 nc: 3 # 类别数量(例如3类) names: ['cat', 'dog', 'car'] # 类别名称列表(按索引顺序)
-
7. 训练 YOLOv8 模型
-
在 PyCharm 中创建一个 Python 文件(如
train.py),输入以下代码:from ultralytics import YOLO # 加载预训练模型 model = YOLO('yolov8n.pt') # 训练模型 results = model.train(data='dataset.yaml', epochs=50, imgsz=640, device='cpu') -
运行
train.py,开始训练模型。-
由于使用的是 CPU,训练速度会较慢。建议使用小型数据集进行测试。
-
7. 划分数据集
-
通常按比例划分(如 80% 训练集,20% 验证集)
- 可使用代码自动划分(例如
splitfolders库):pip install splitfoldersimport splitfolders splitfolders.ratio("原始数据集路径", output="dataset", ratio=(0.8, 0.2))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









