






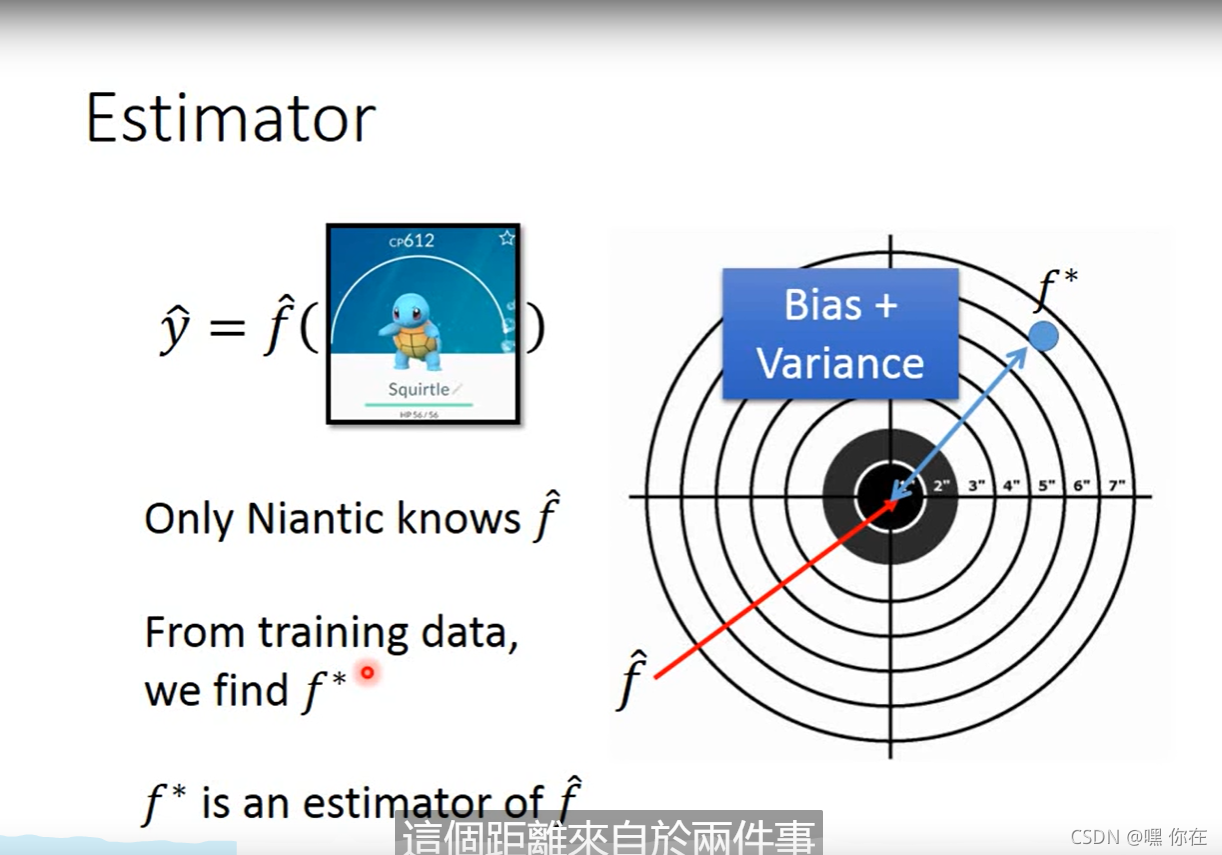
继续上一篇文章,我们可以看到,构造的最好的函数还是会产生误差,那么这些误差受什么影响呢?【bias和variance】


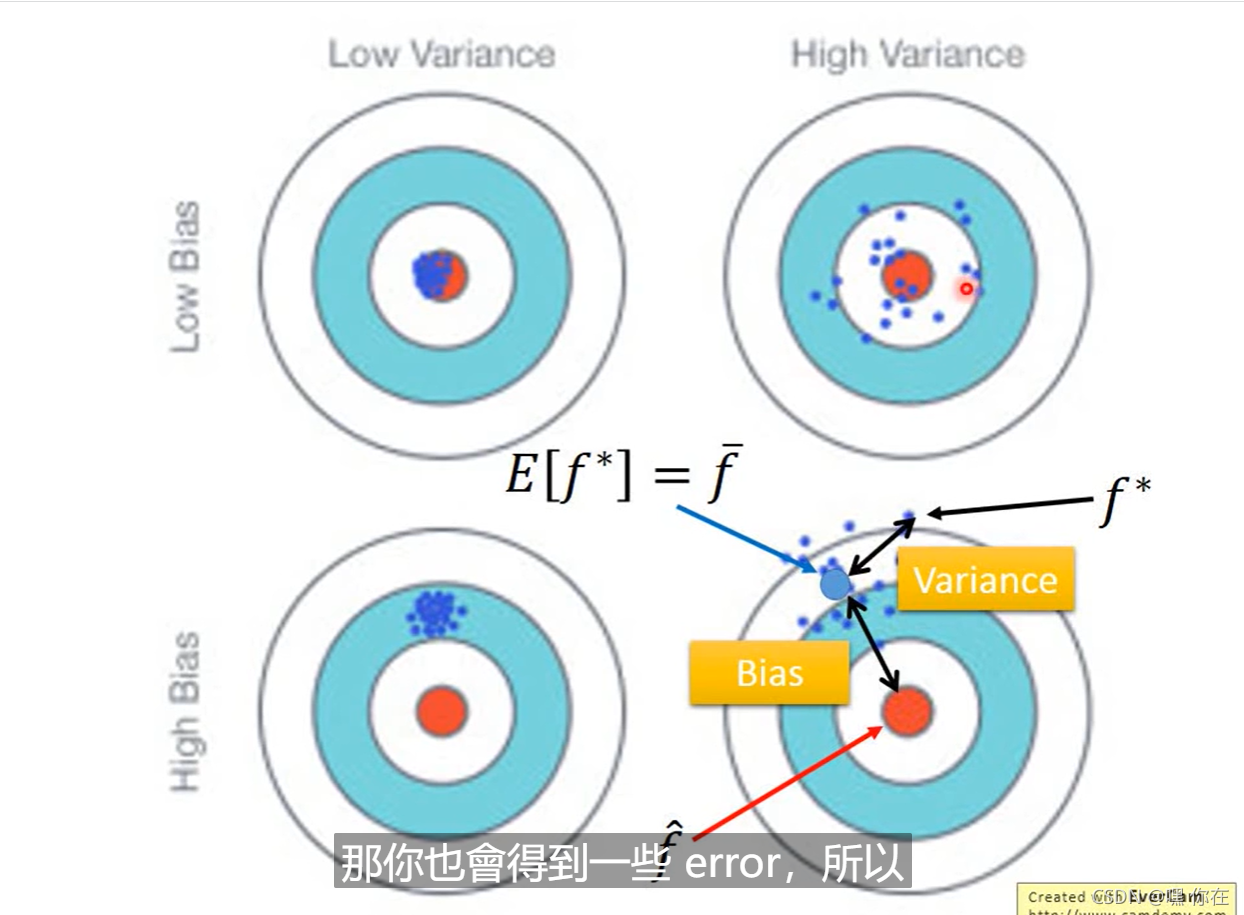
方差越小越集中,所以当n越大时,方差越小,则数据越集中
均值时无偏估计,方差是有偏估计
下图是对方差的估计

假如使用 y=b+w*Xcp 这个模型 。给的数据不一样找到的最好的函数也不一样(w,b的值不同)
下图是100次实验,选择不同的模型会有不同的图像结果
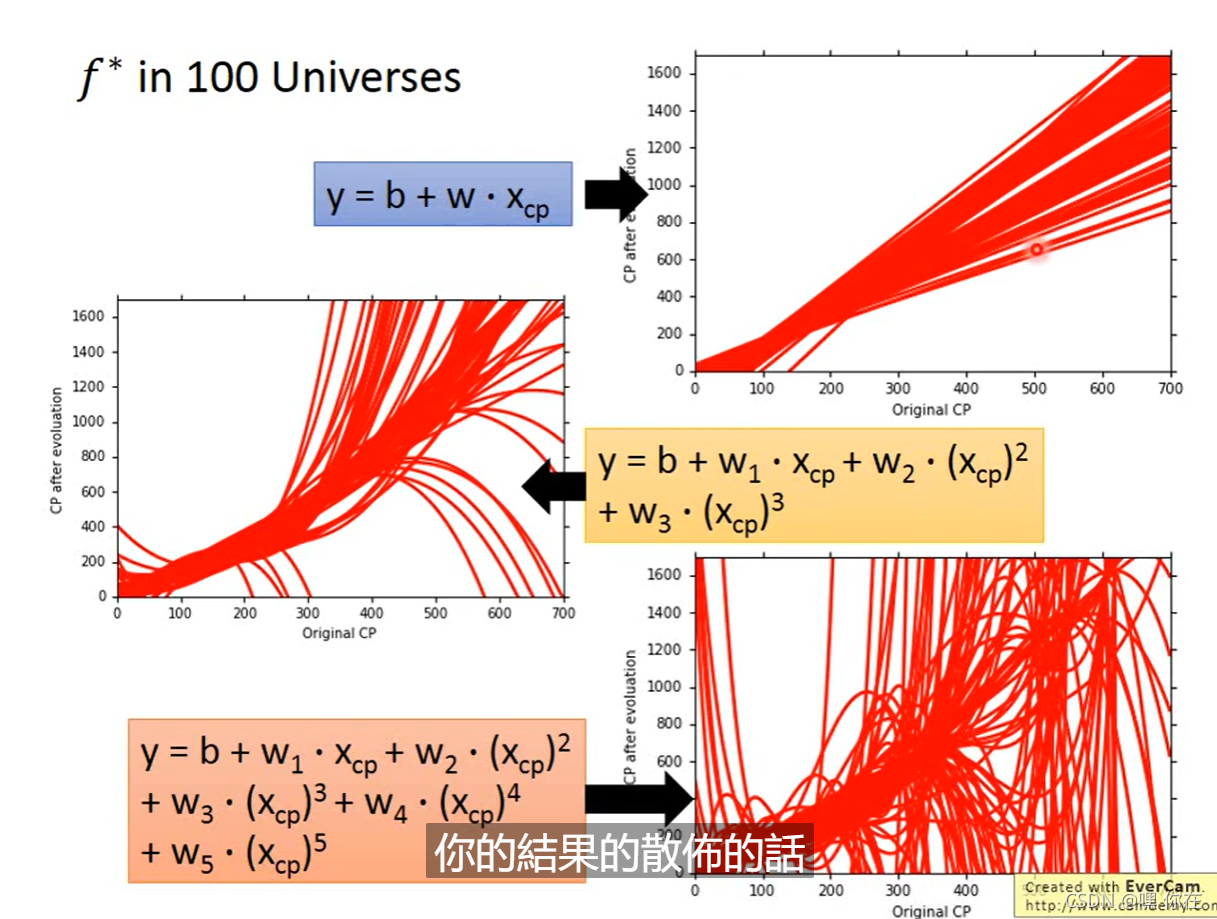
Variance
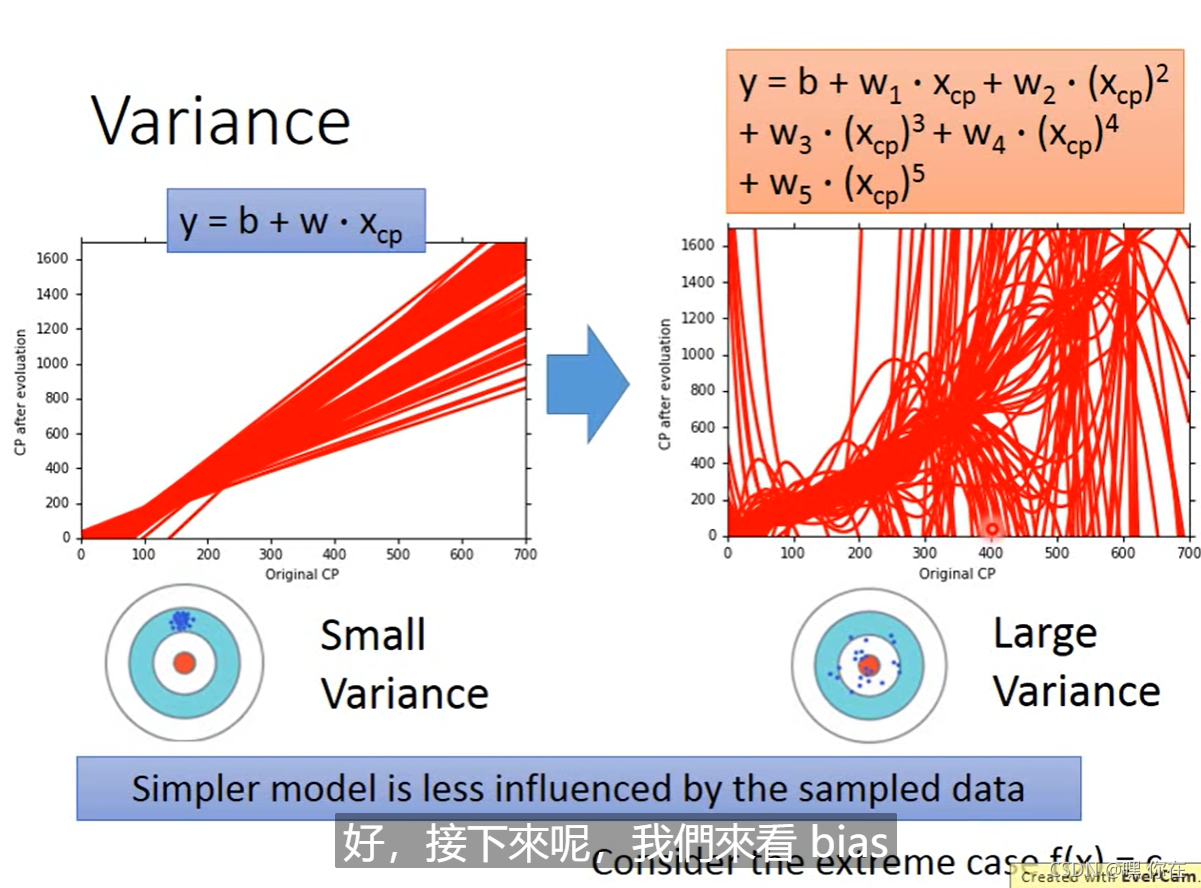
模型越简单,方差就会越小。模型越复杂,方差就会越大。简单的模型受到数据的影响较小。
Bias
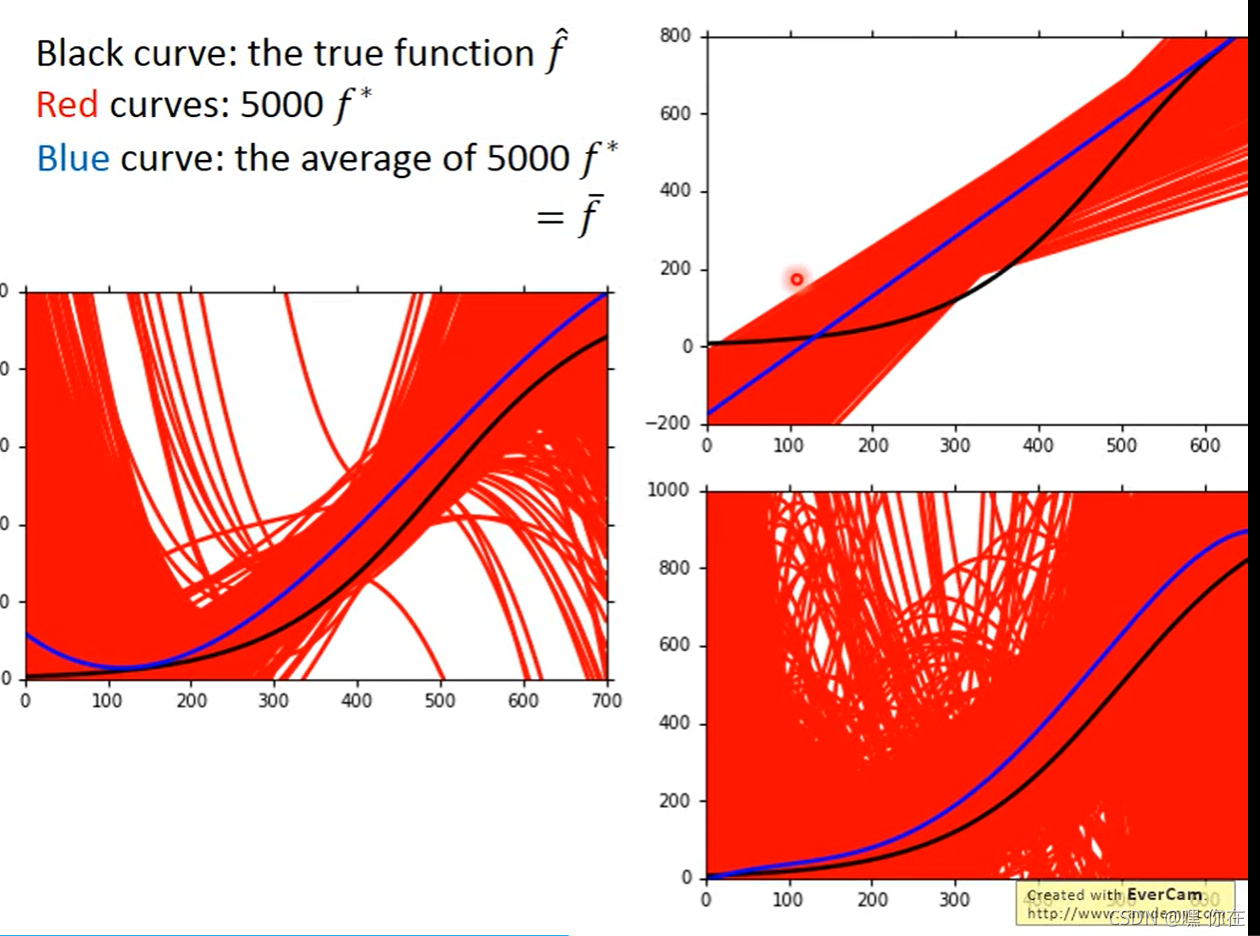
1.黑色的是原有的值
2.红色的是100次实验得到的不同的函数图像
3. 蓝色的是100条红线的平均值
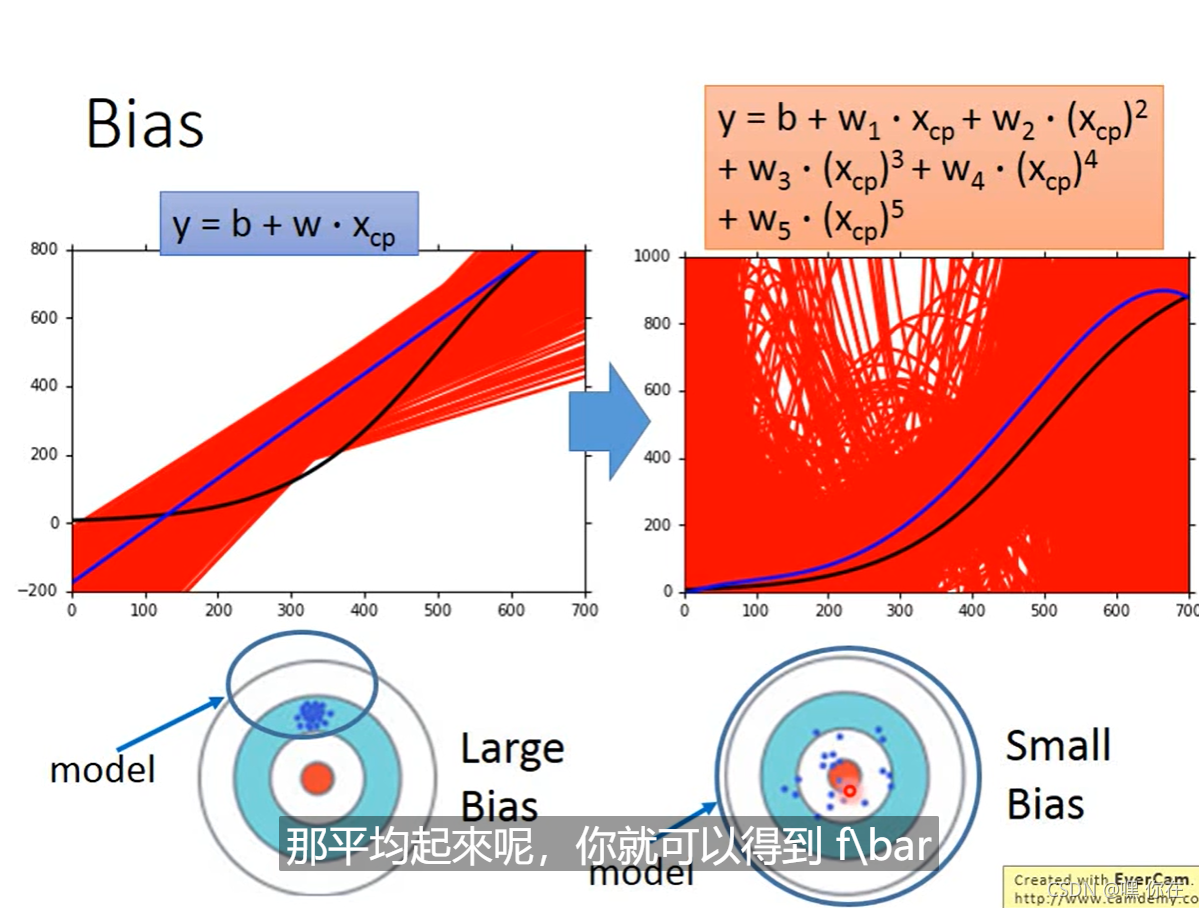
函数越简单,函数space越小,那么我们选取的函数只能在那个函数集中选择,那么离中心点就会比较远。函数越复杂 函数space越大,点就会很分散,那么我们取得平均值就会离中心点较近。
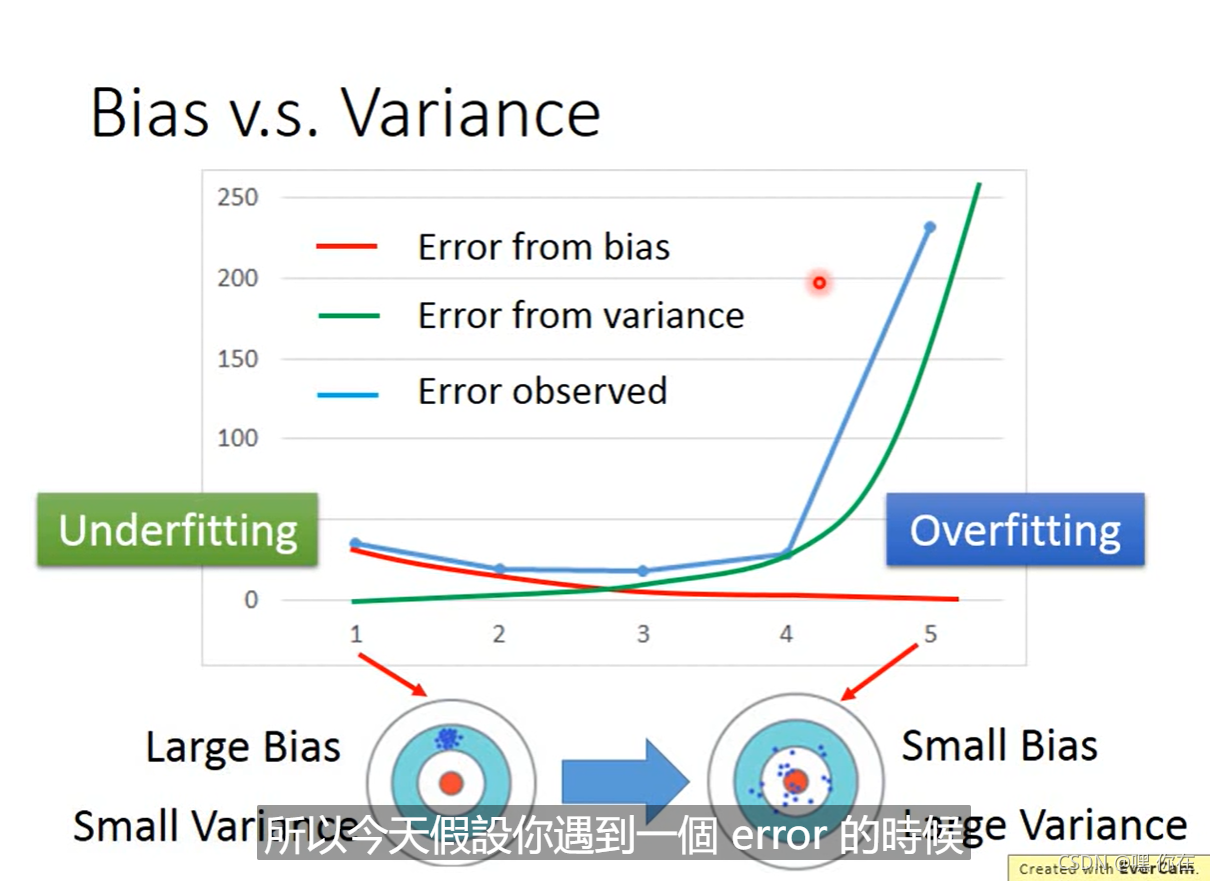
怎么解决bias大和variance大
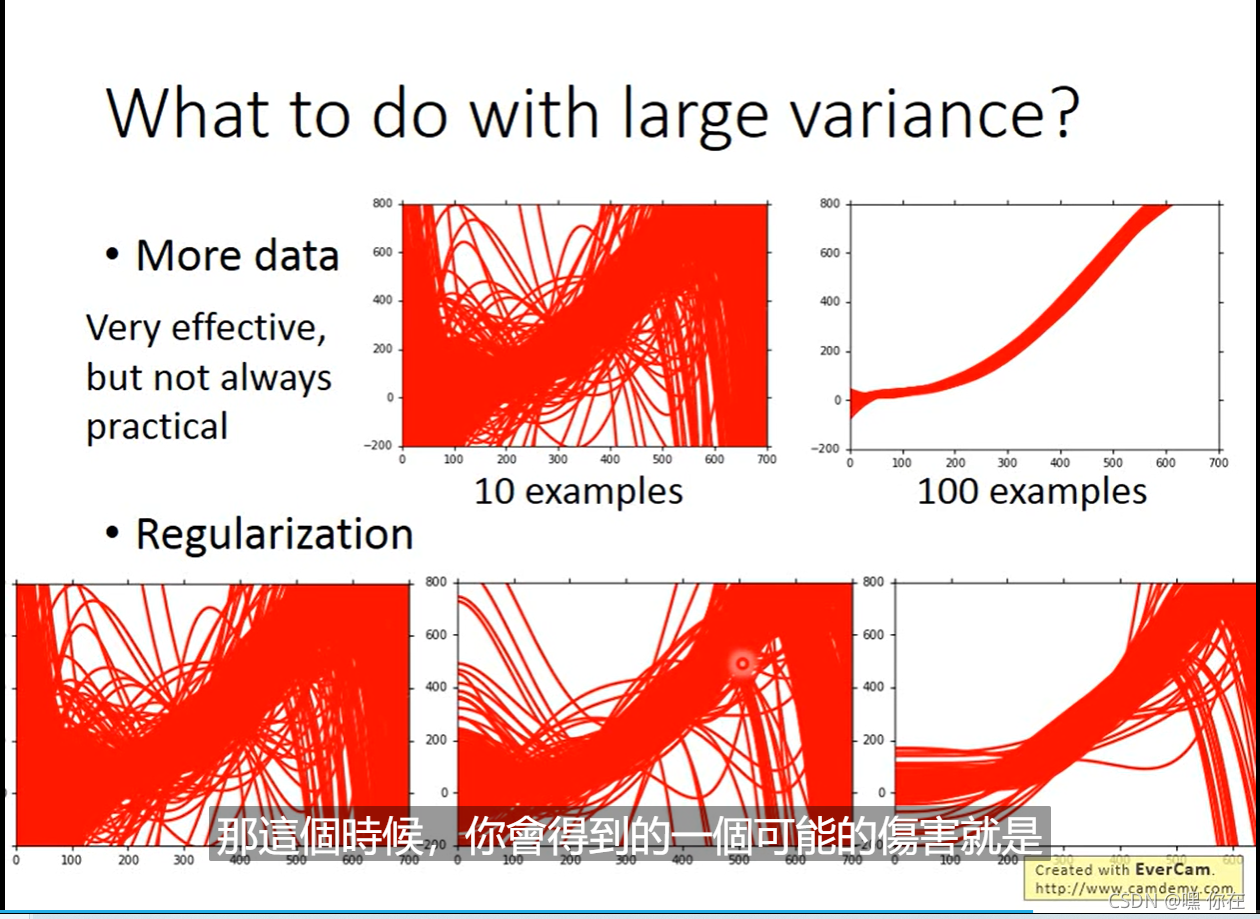
解决variance大应该减少训练数据的种类或者使用正则化减少模型的复杂度
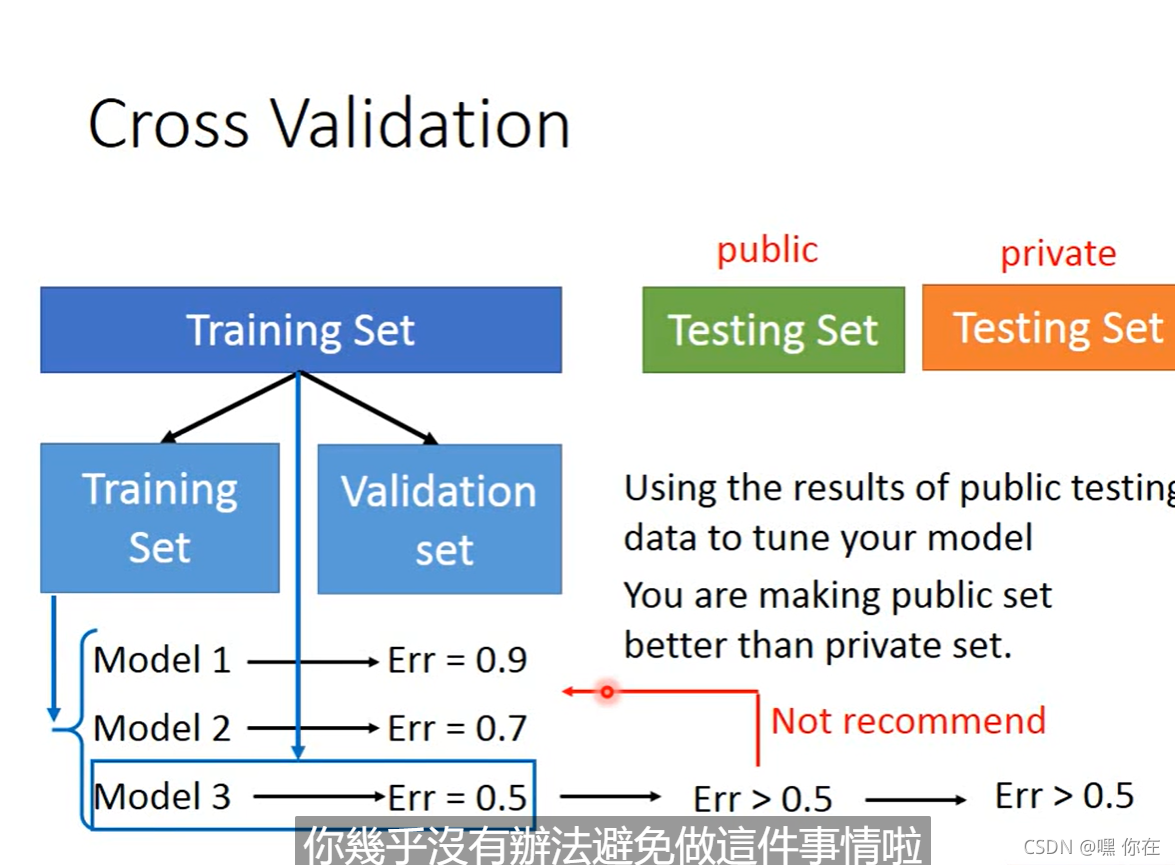
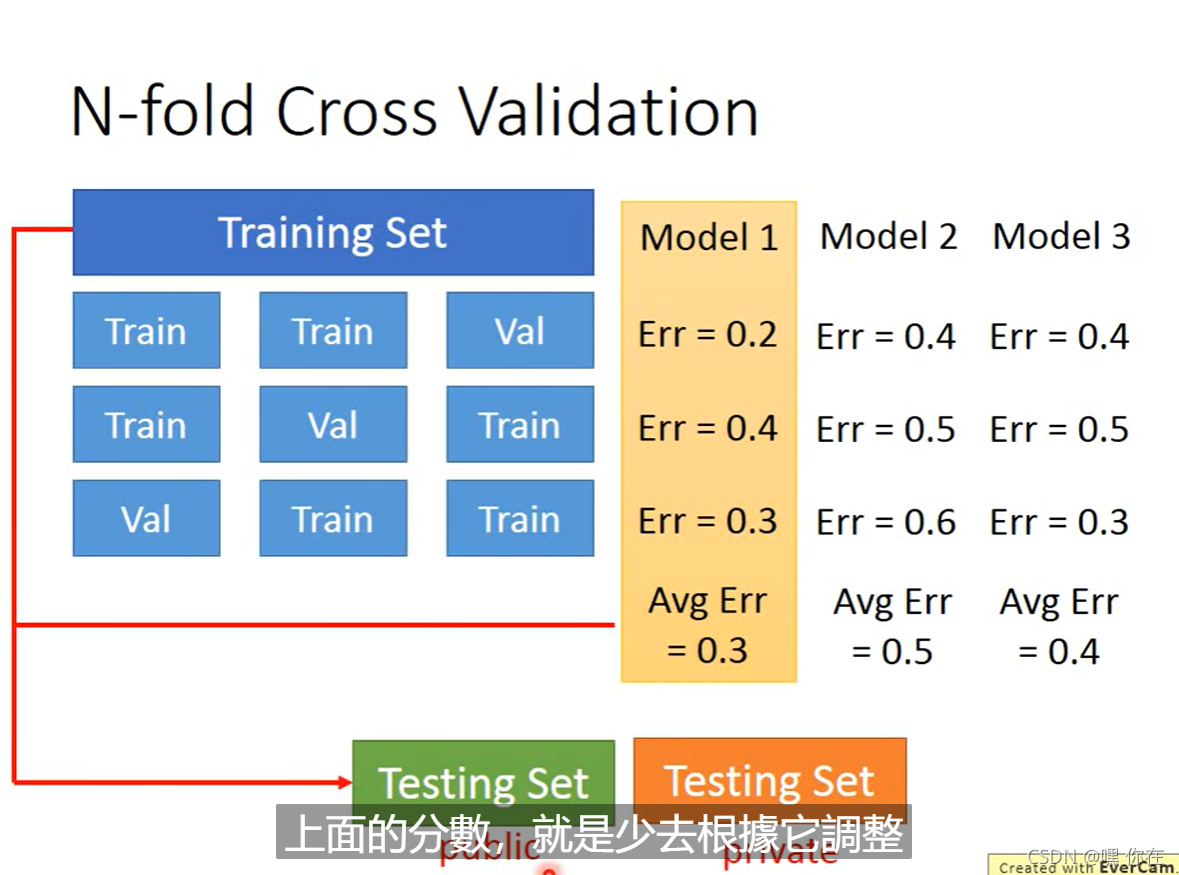
模型选择


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









