






如何将文字转会为数值:
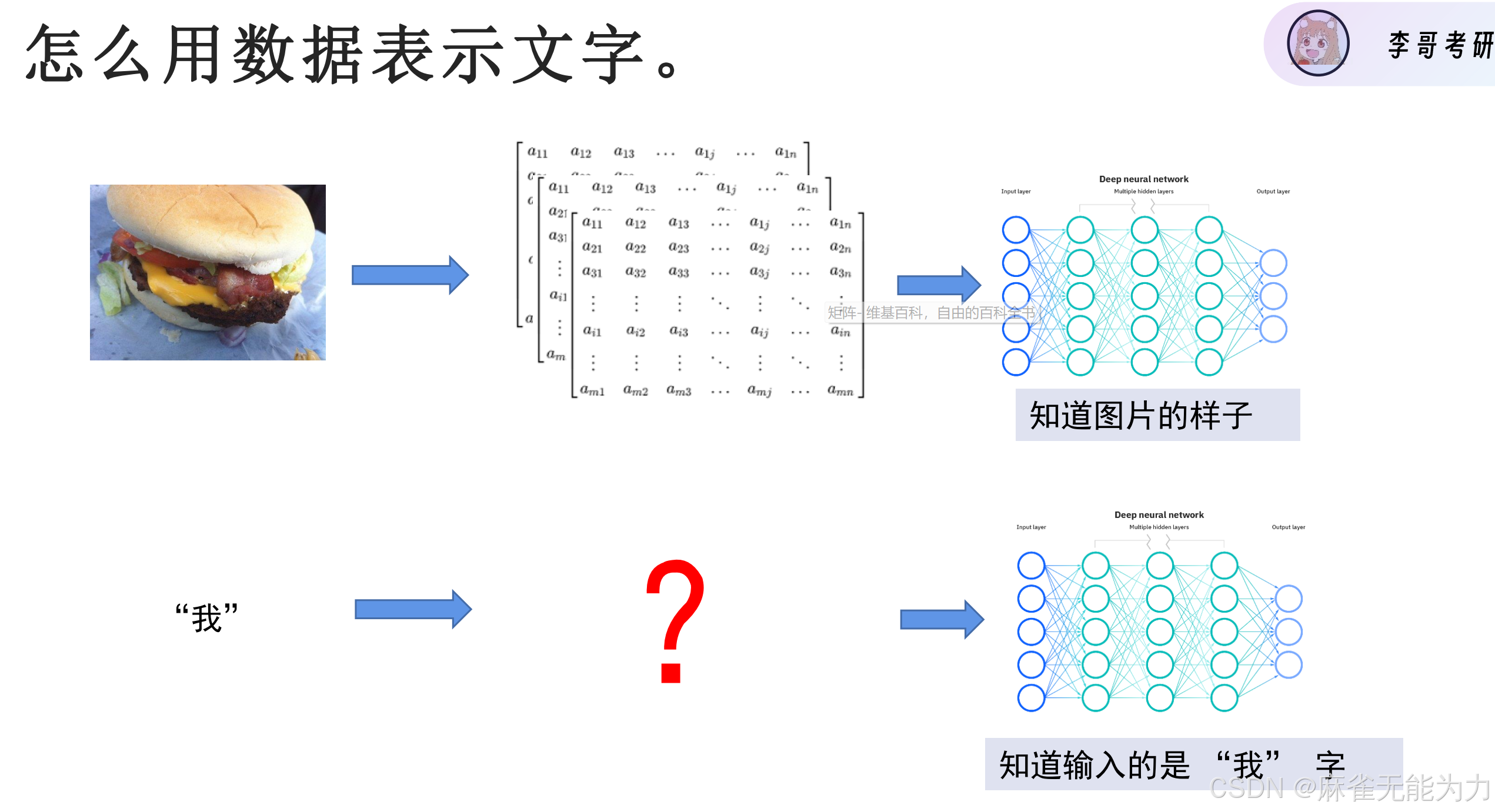 通过one-hot进行encoding
通过one-hot进行encoding
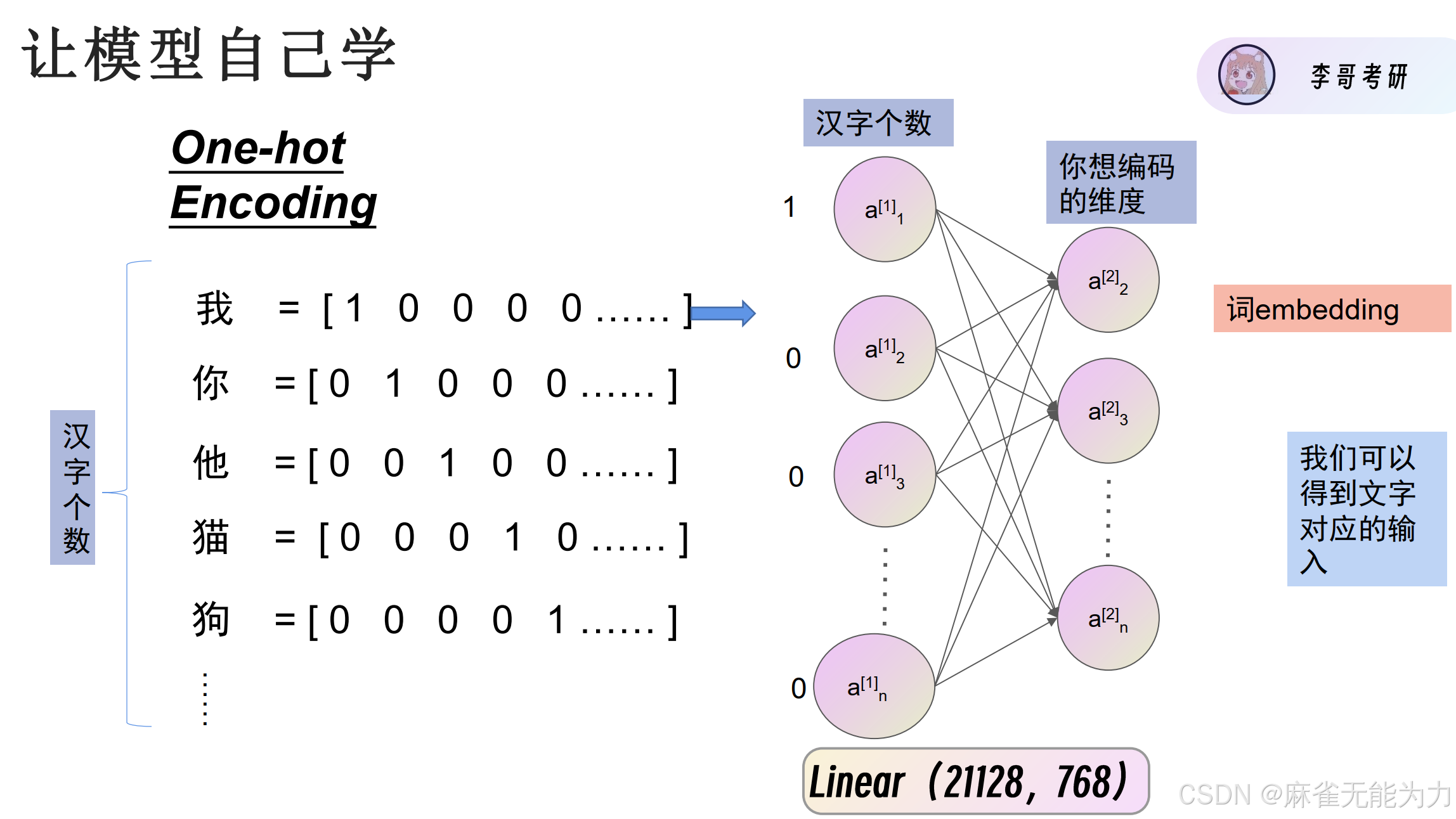
这样可以用模型提取特征值,完成各种输出任务:
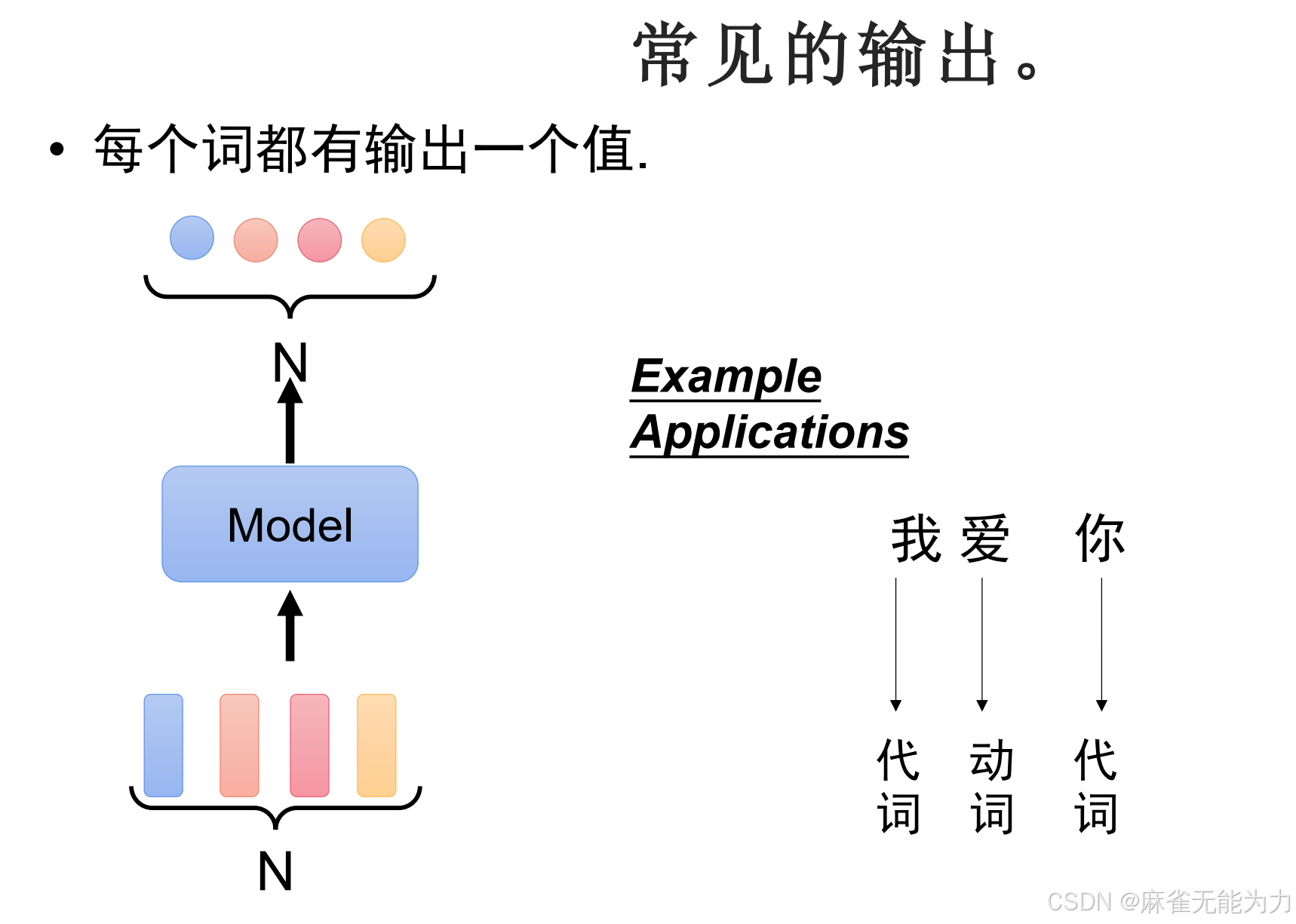
输出是多分类
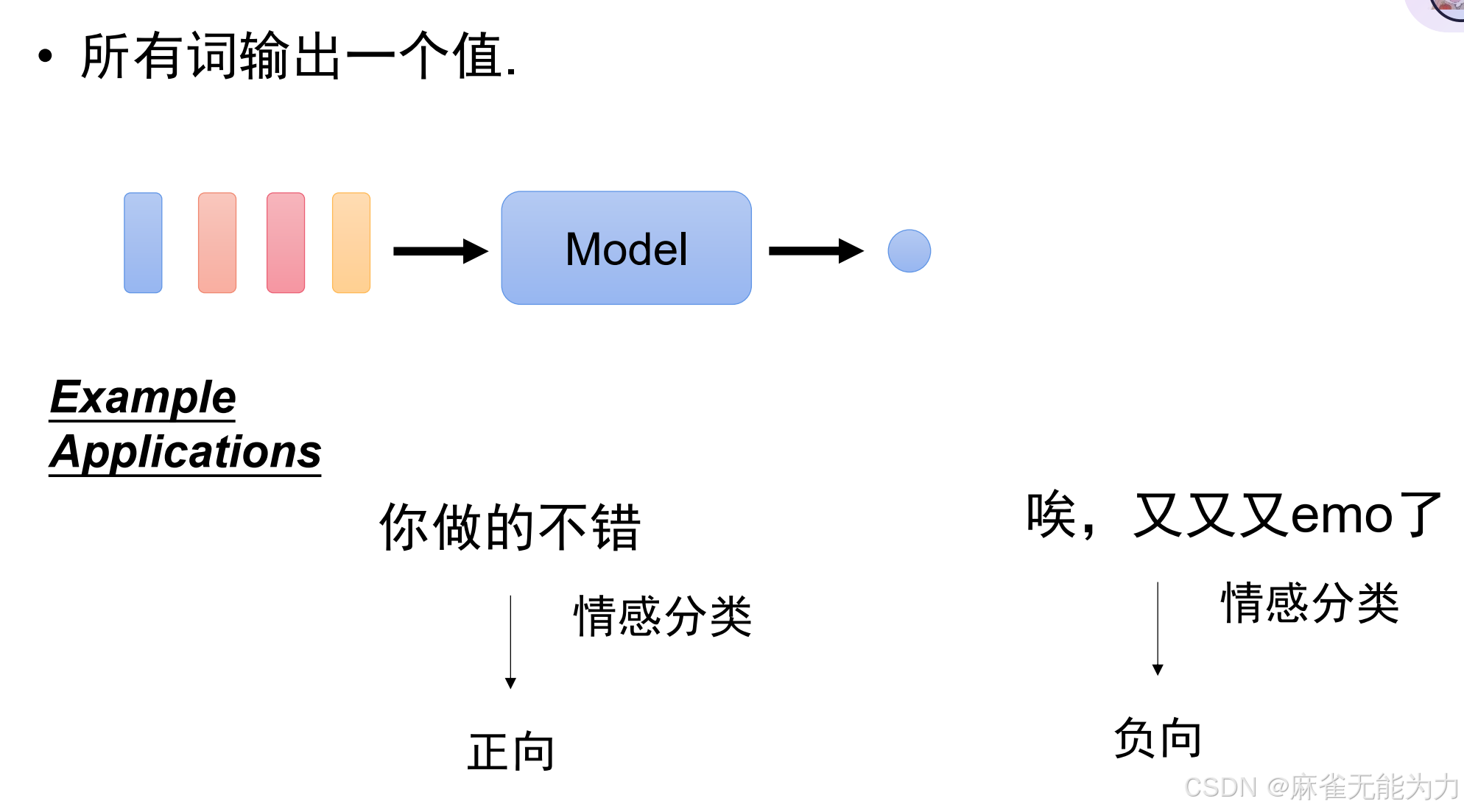
输出是二分类
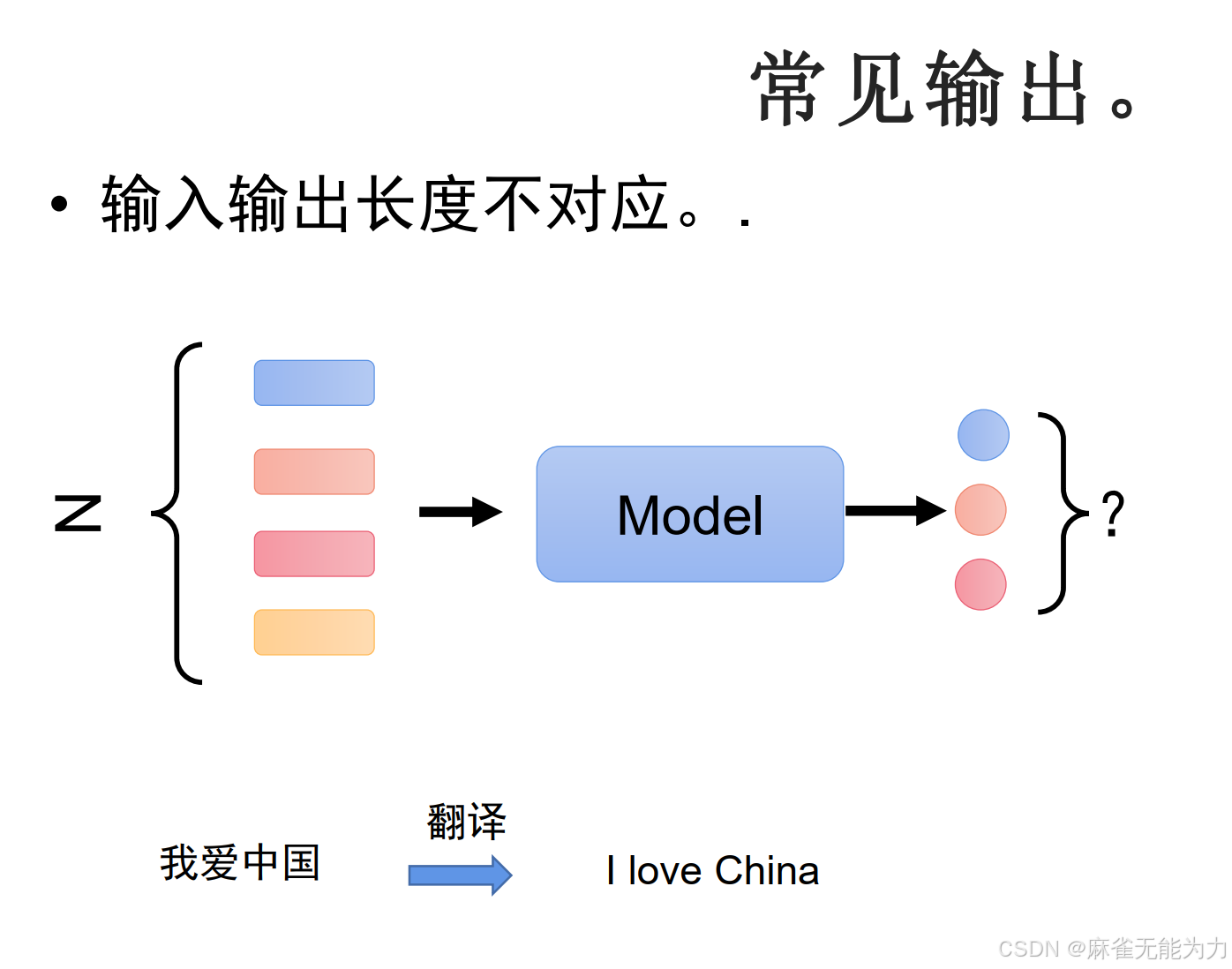
输出是序列
如何提取每个字词在整体语境中的特征:
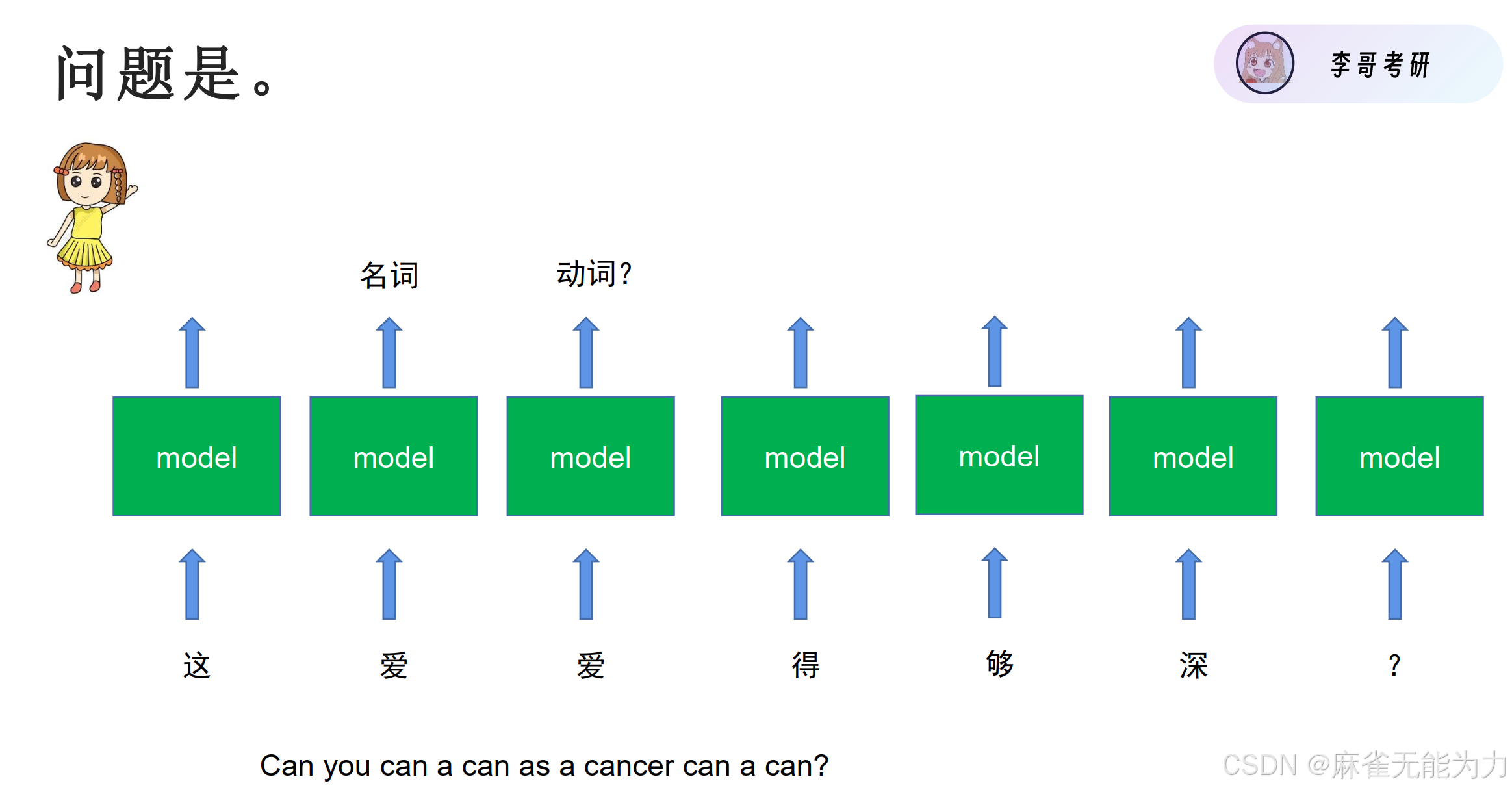
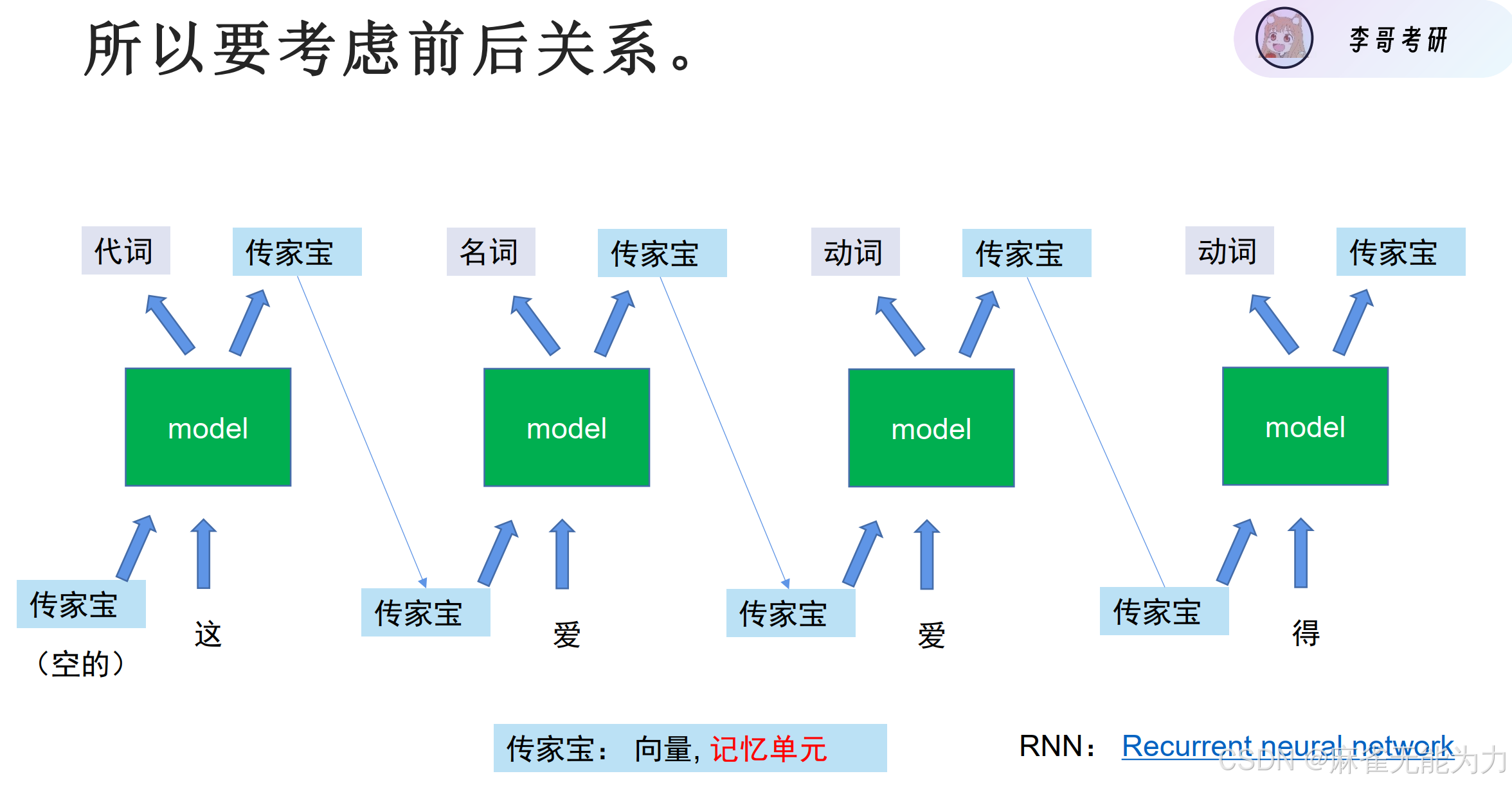
有一种方法是运用记忆单元(传家宝),串行的记录整个句子的特征。如:CNN
但这会带来一些问题:句子相关词相隔太远怎么办?
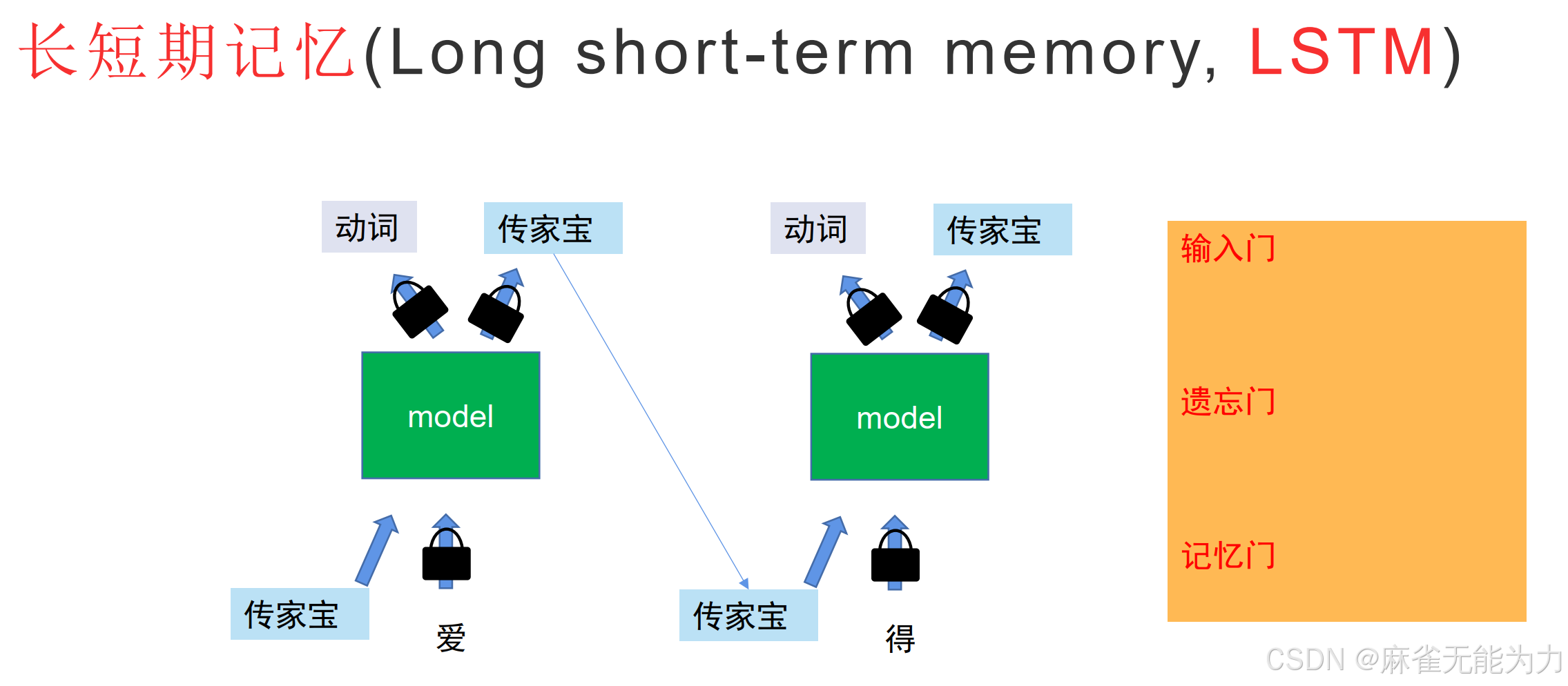
LSTM可以禁止某些字词修改记忆单元,从而提升效果。
但还有一个更重要的问题:文章太长,串行结构太慢
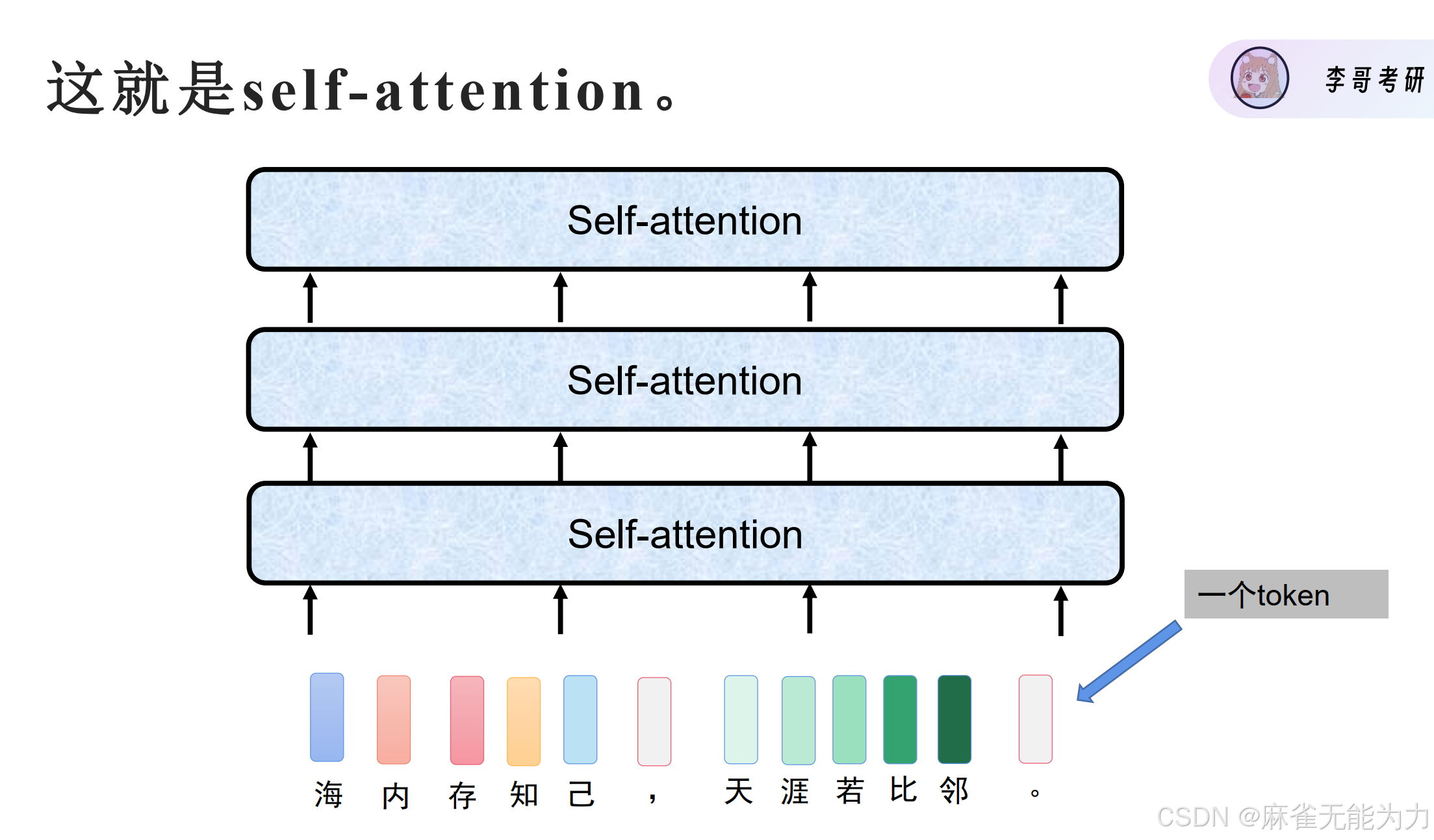
引入自注意力机制
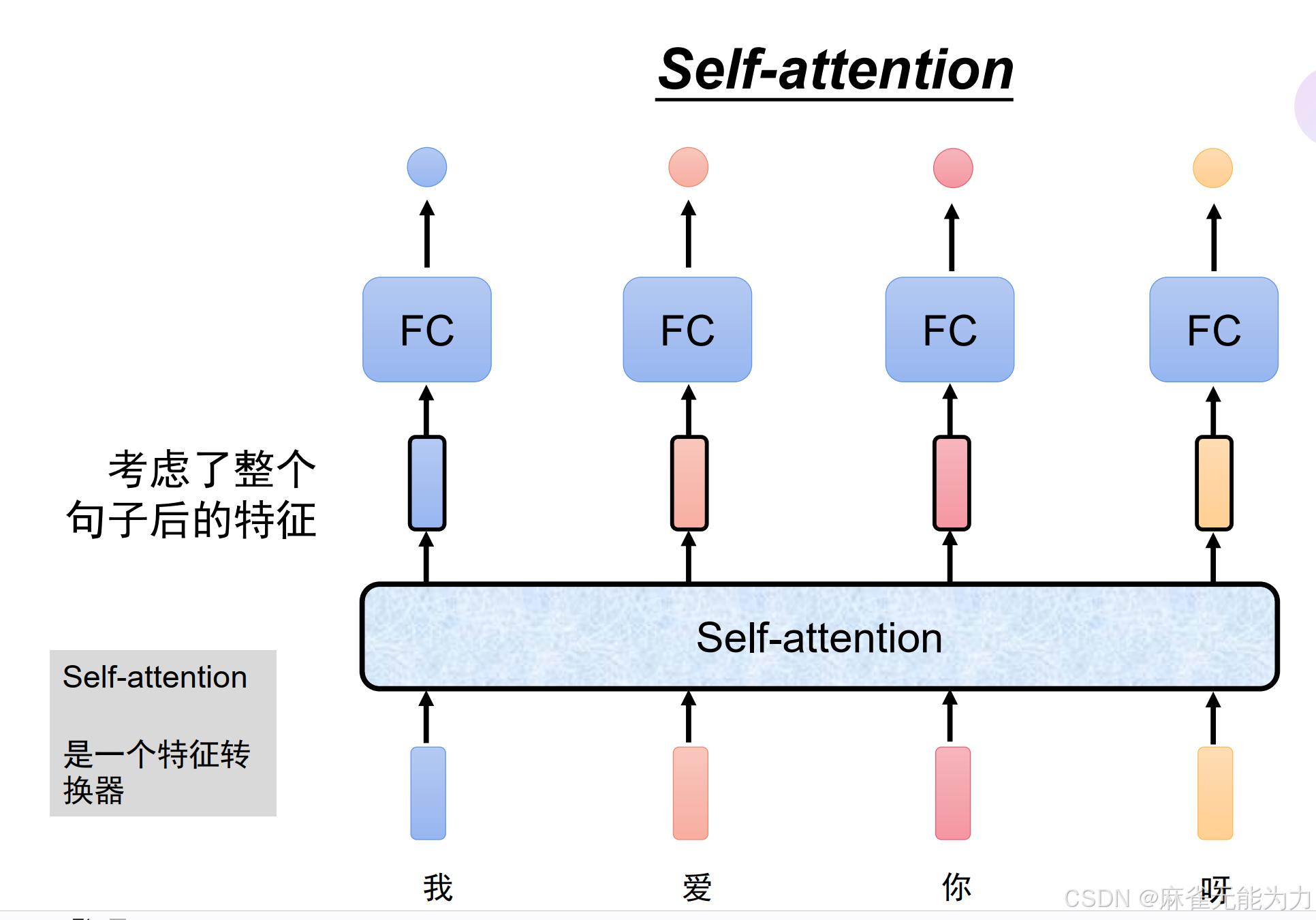
下图是自注意力机制的总体模型:
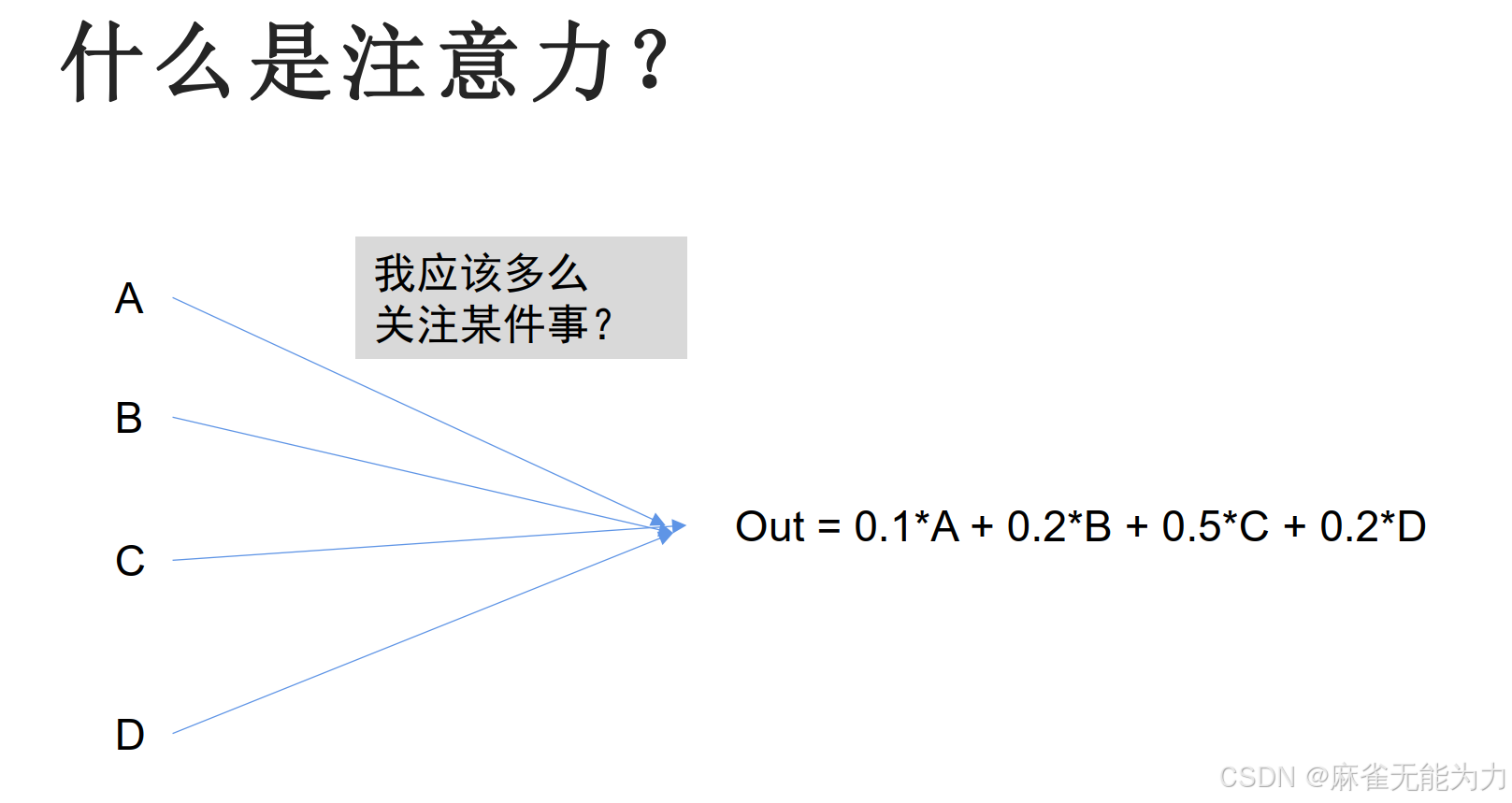
什么是注意力:
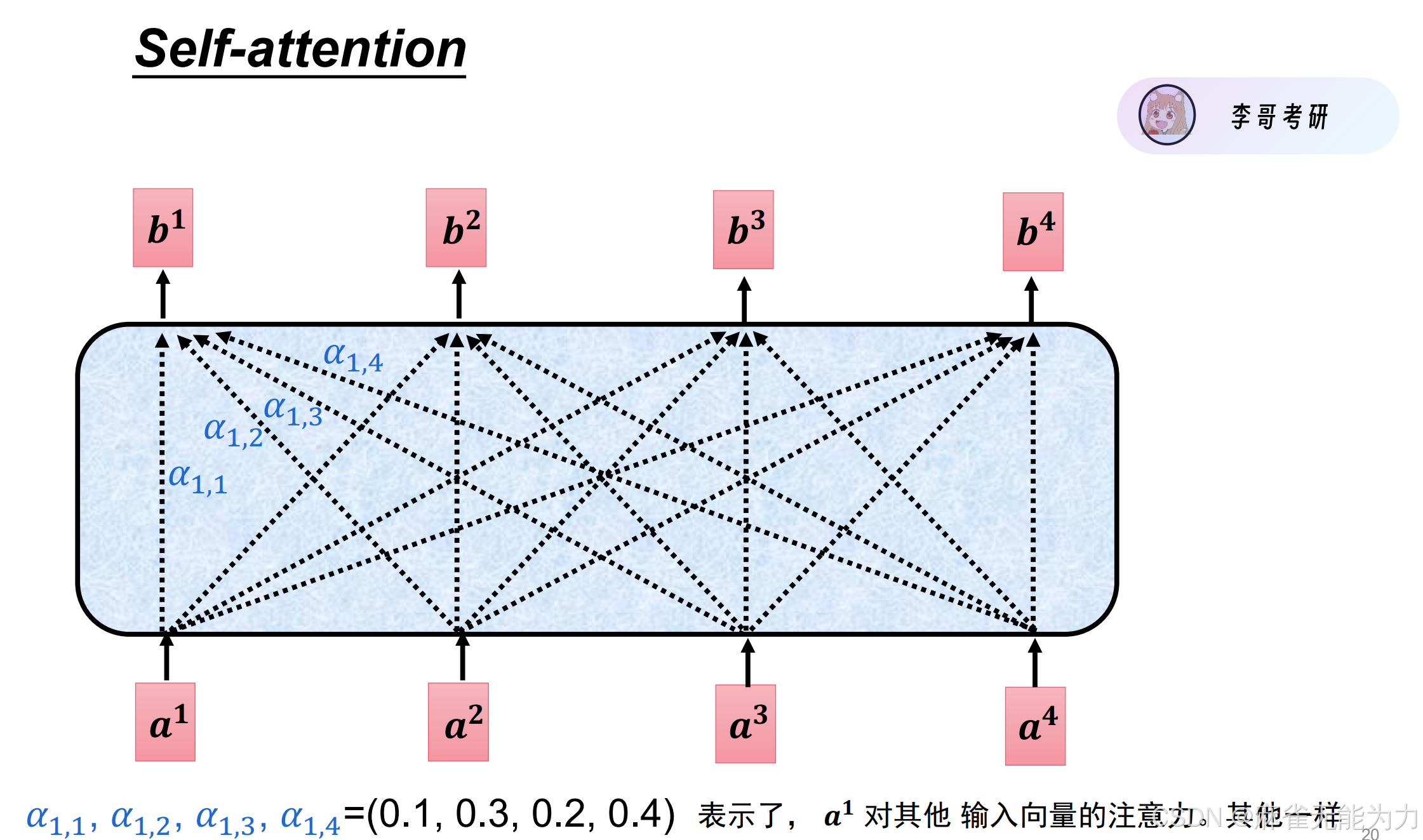
对于一句话中的一个字,提取其特征值不仅要注意自身,也要将一部分注意力分配给同一句话的其他字。
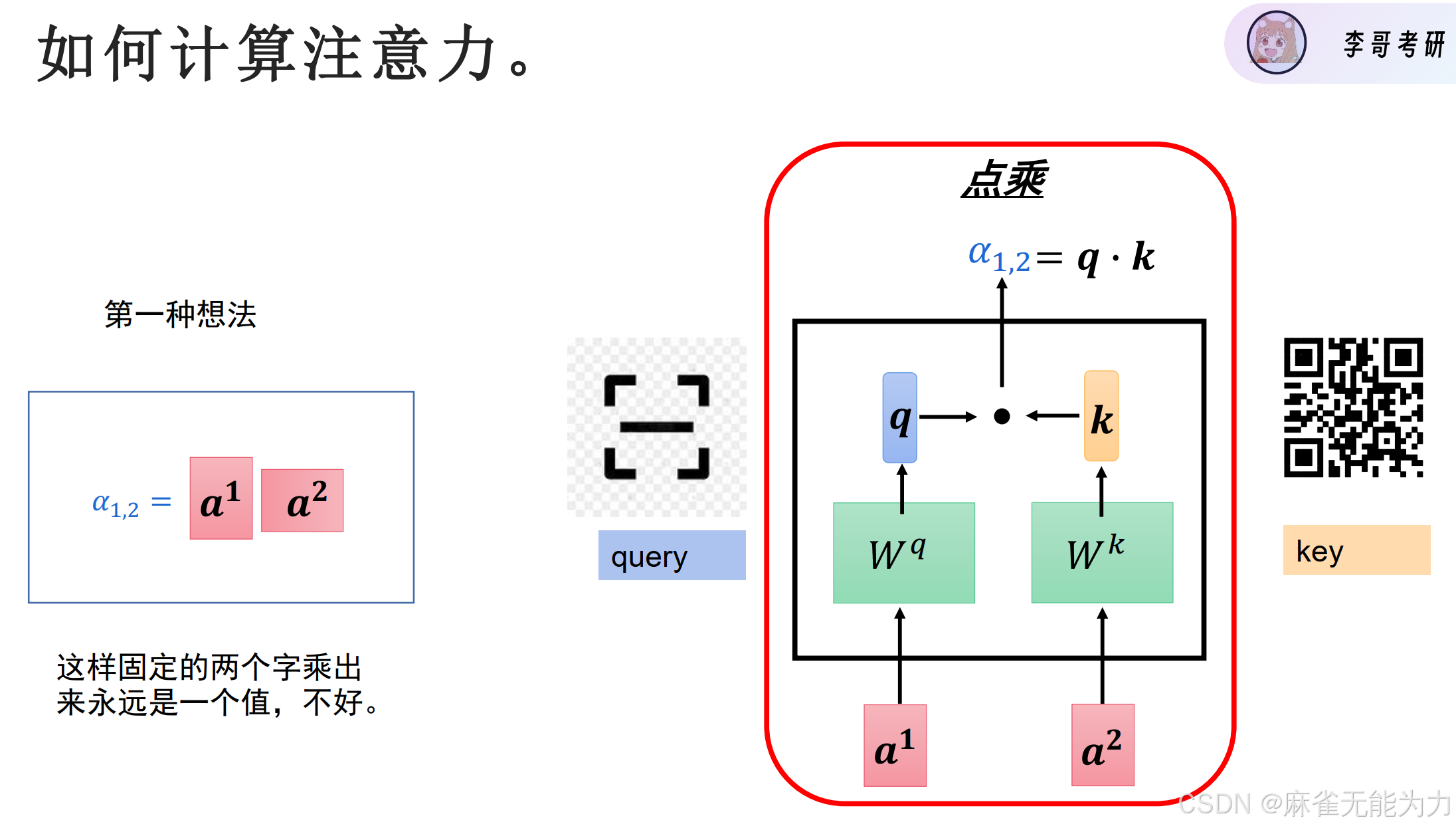
注意力靠两个部分完成:我怎么注意别人,我怎么让别人注意
在该模型中是分别通过和
两个矩阵乘以自身完成。
上图中的就是
包含全局注意力的特征值。
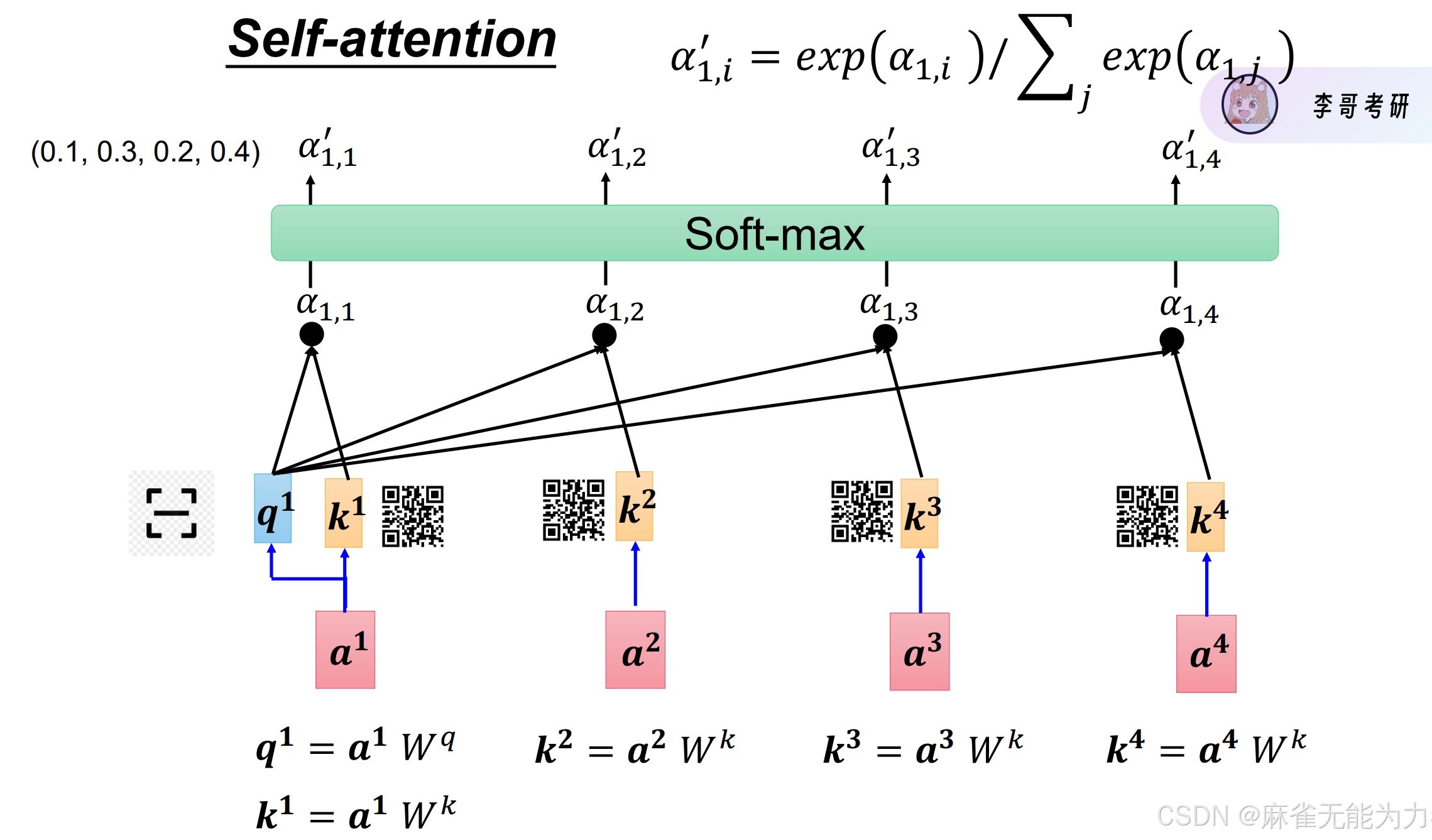
如上图所示,就提取出了每个输入值归一化后的特征值。
为了确保输入数据和输出数据形状等个方面相匹配还要加上一个
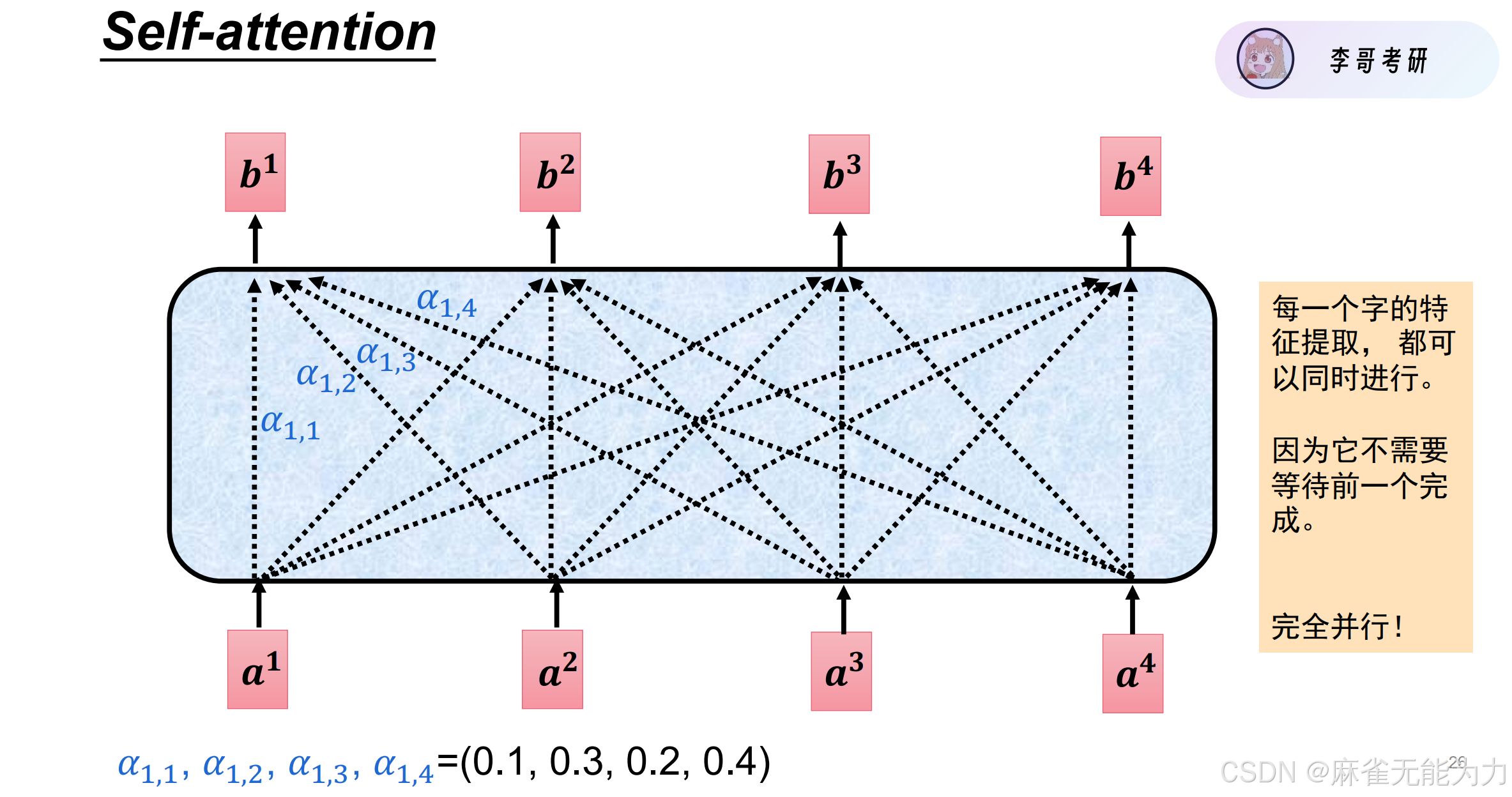
这样就构建了一个完全并行运算的有全局信息的特征值提取方法:
接下来用矩阵方程性质进行描述(注意下图中的矩阵描述方法与线性代数中的矩阵有所不同)
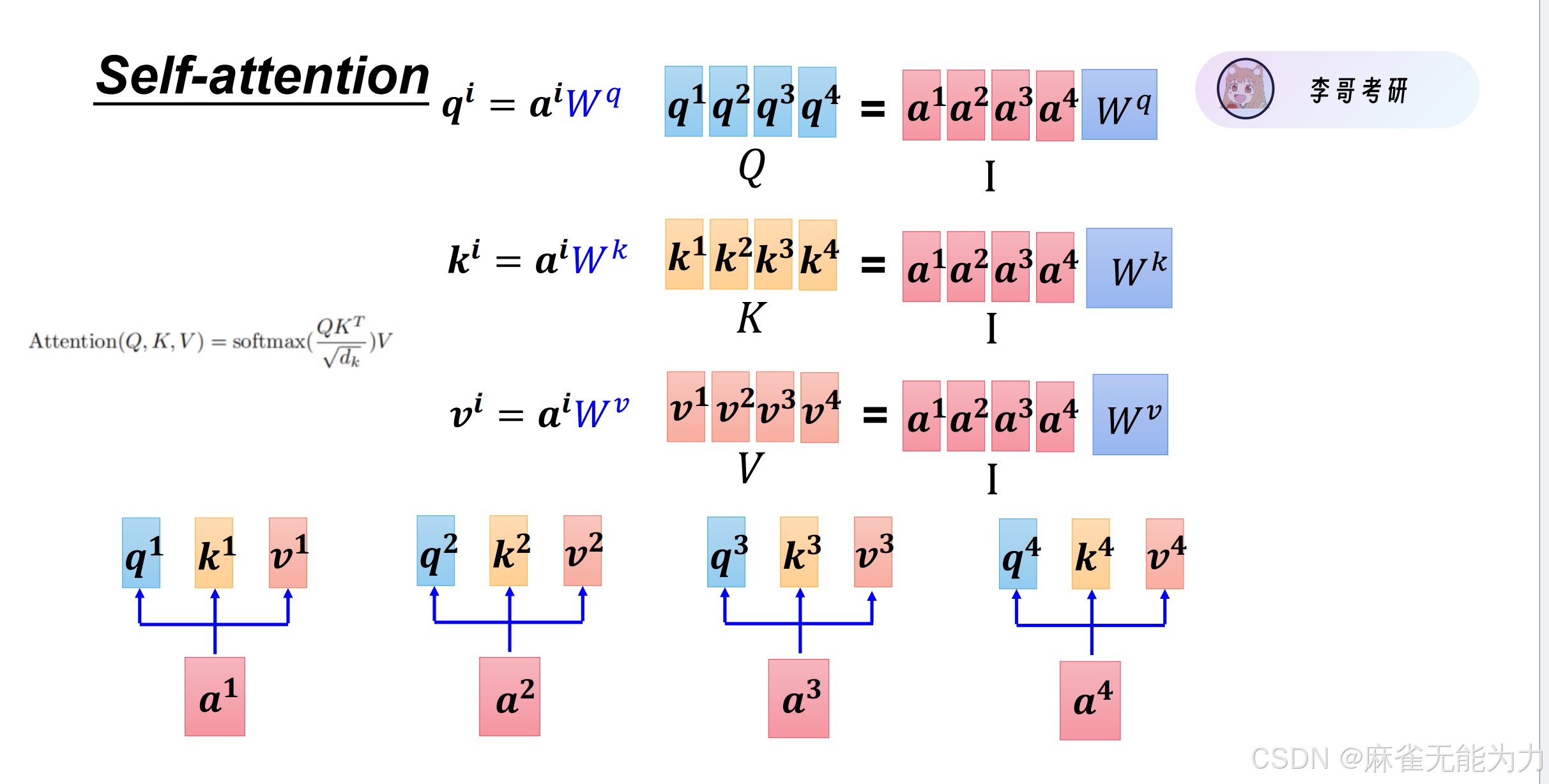
得到每个字的query,key和value向量
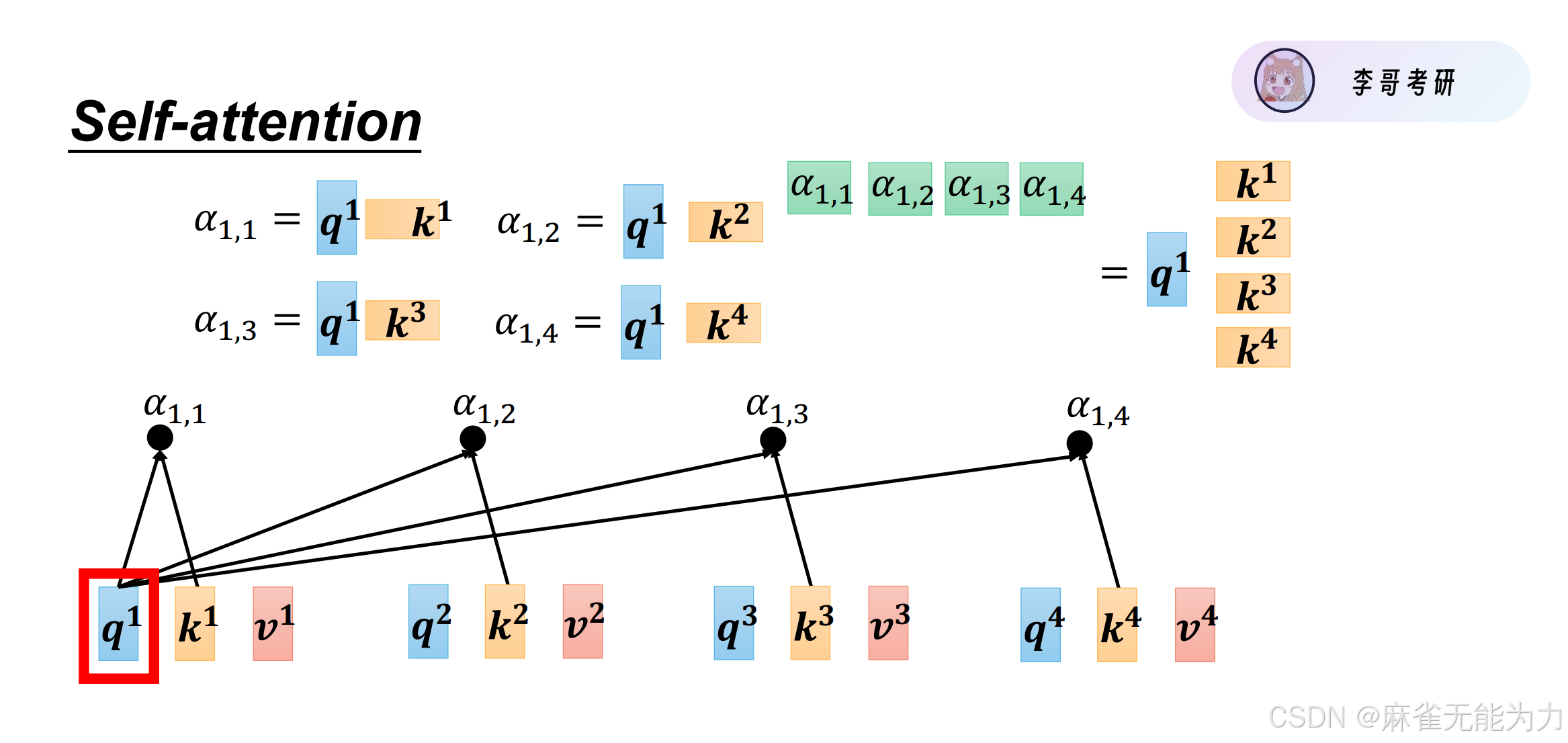
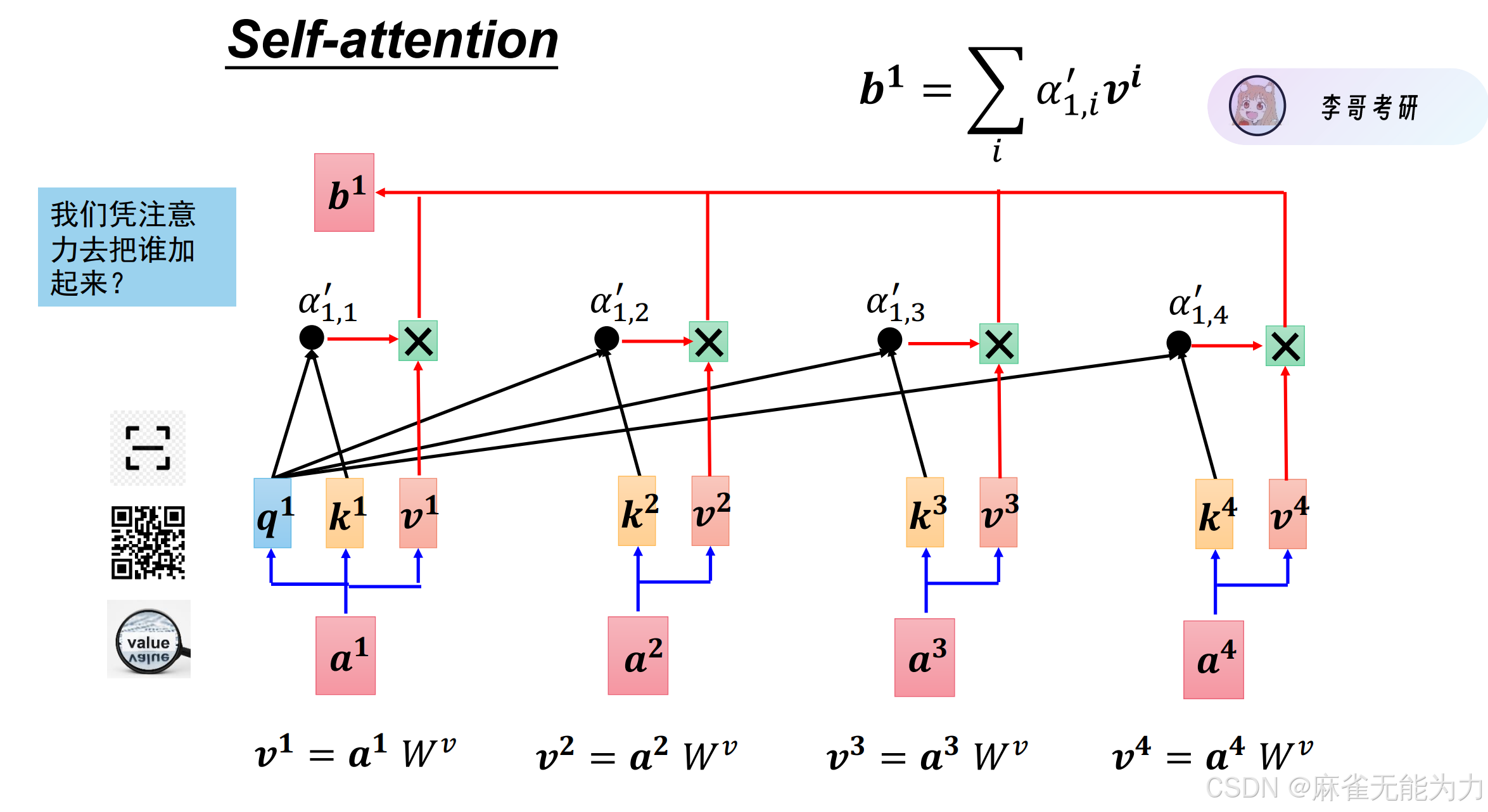
query和key相乘得到每个字对于其他字的注意力。
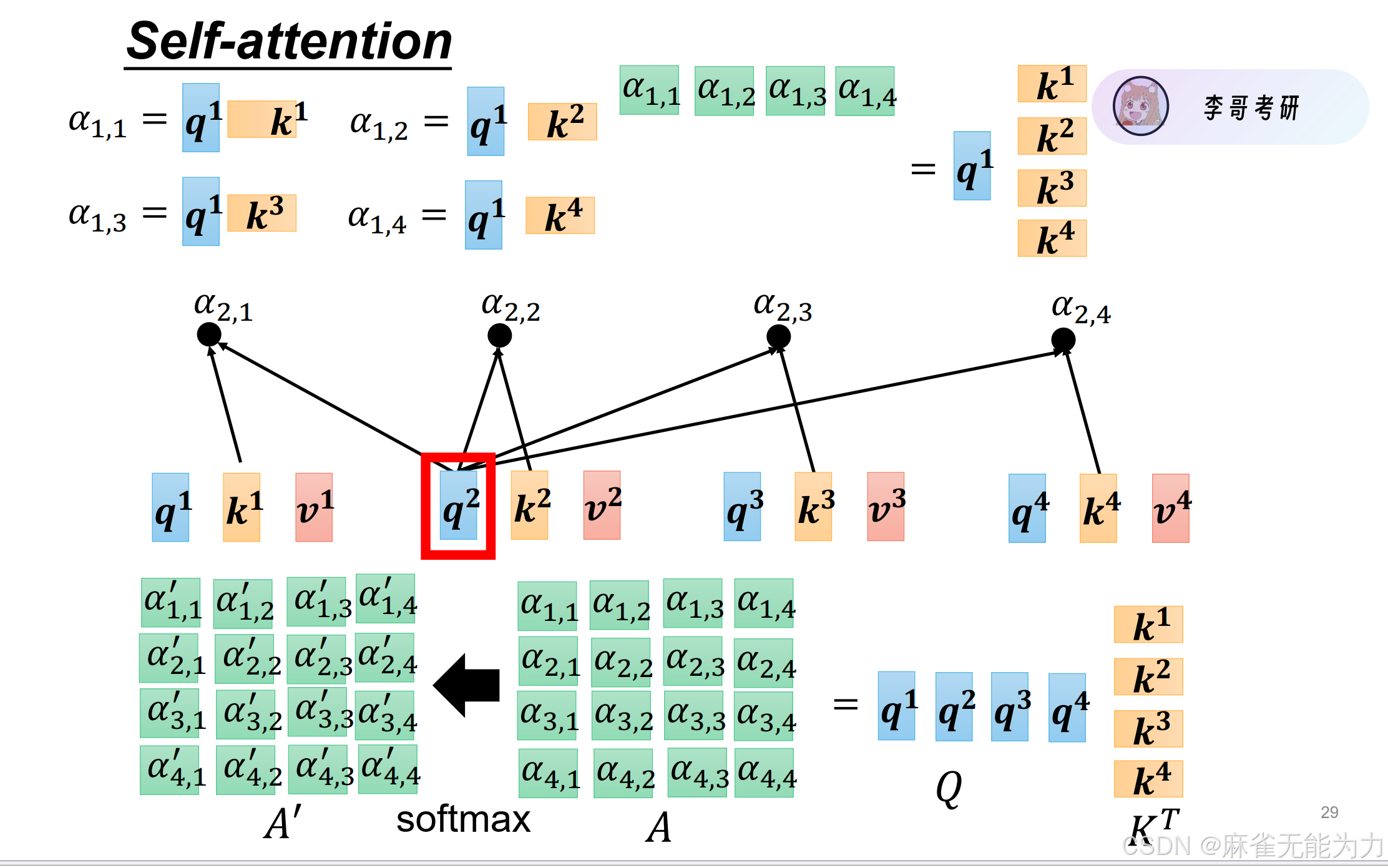
最终会形成一个n*n的矩阵(表示第i个字对第j个字的注意力
然后做一个softmax的处理
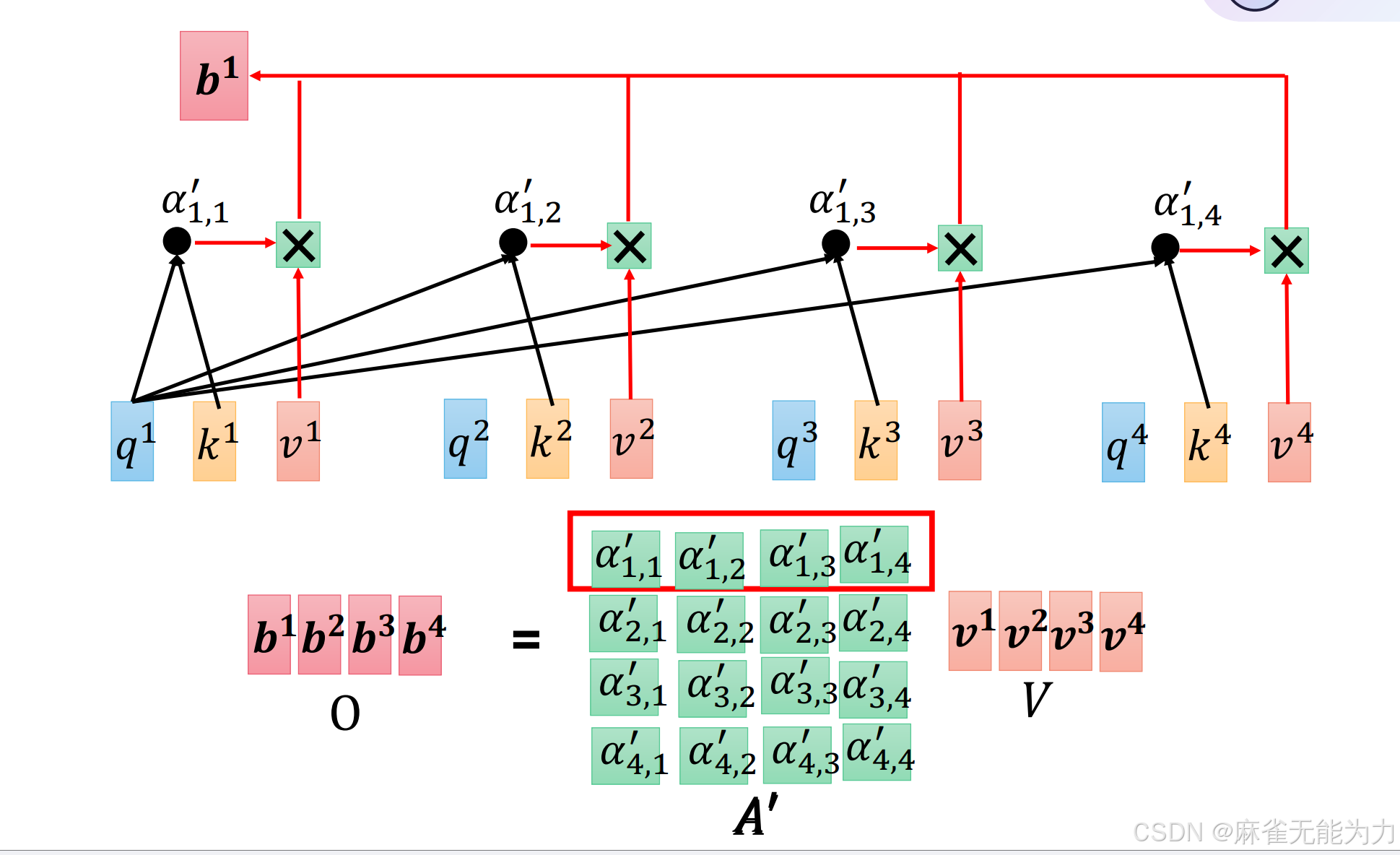
最后与value相乘再相加得到全局特征值
有哪些需要训练的参数:
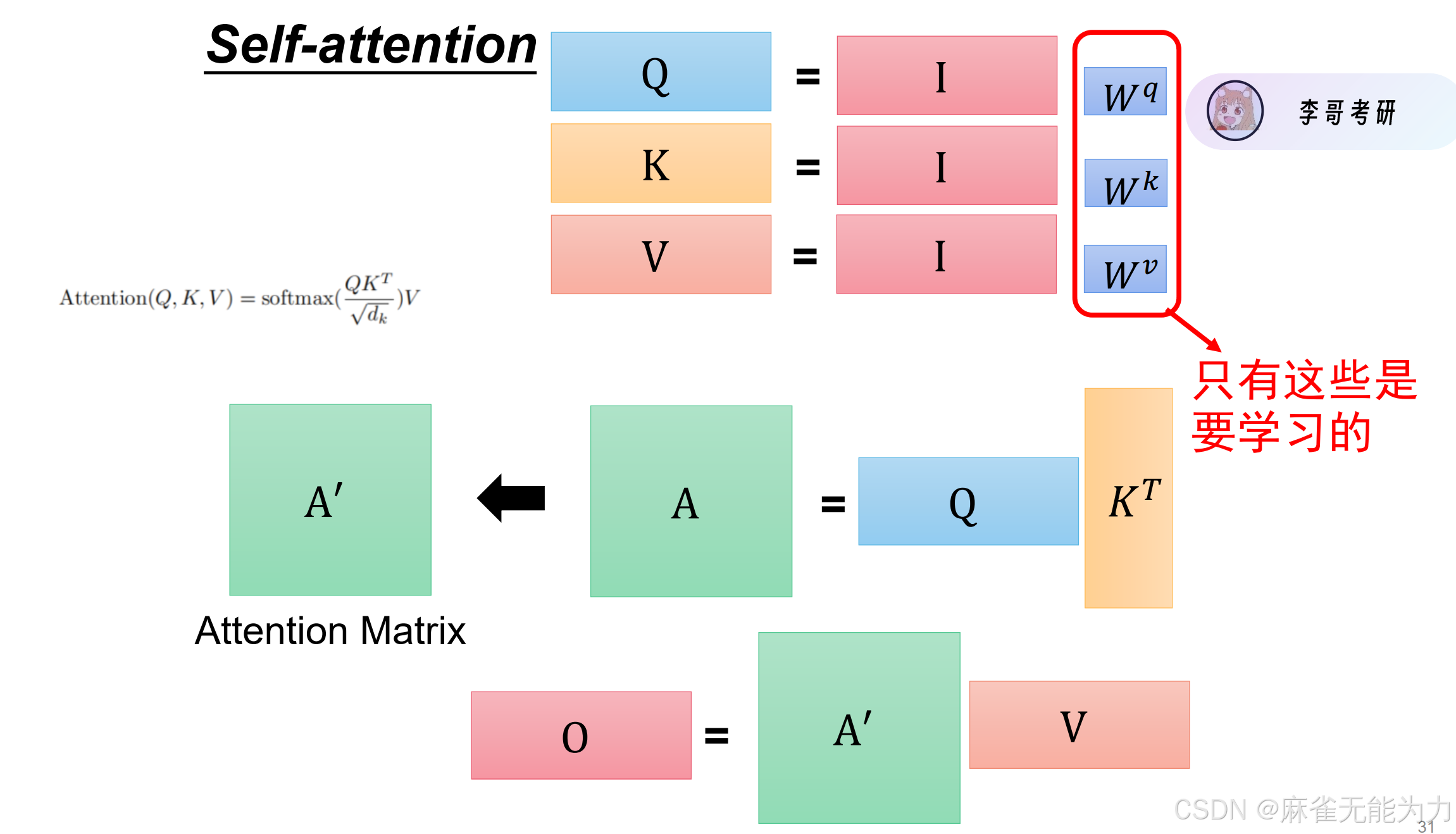
了解内容:
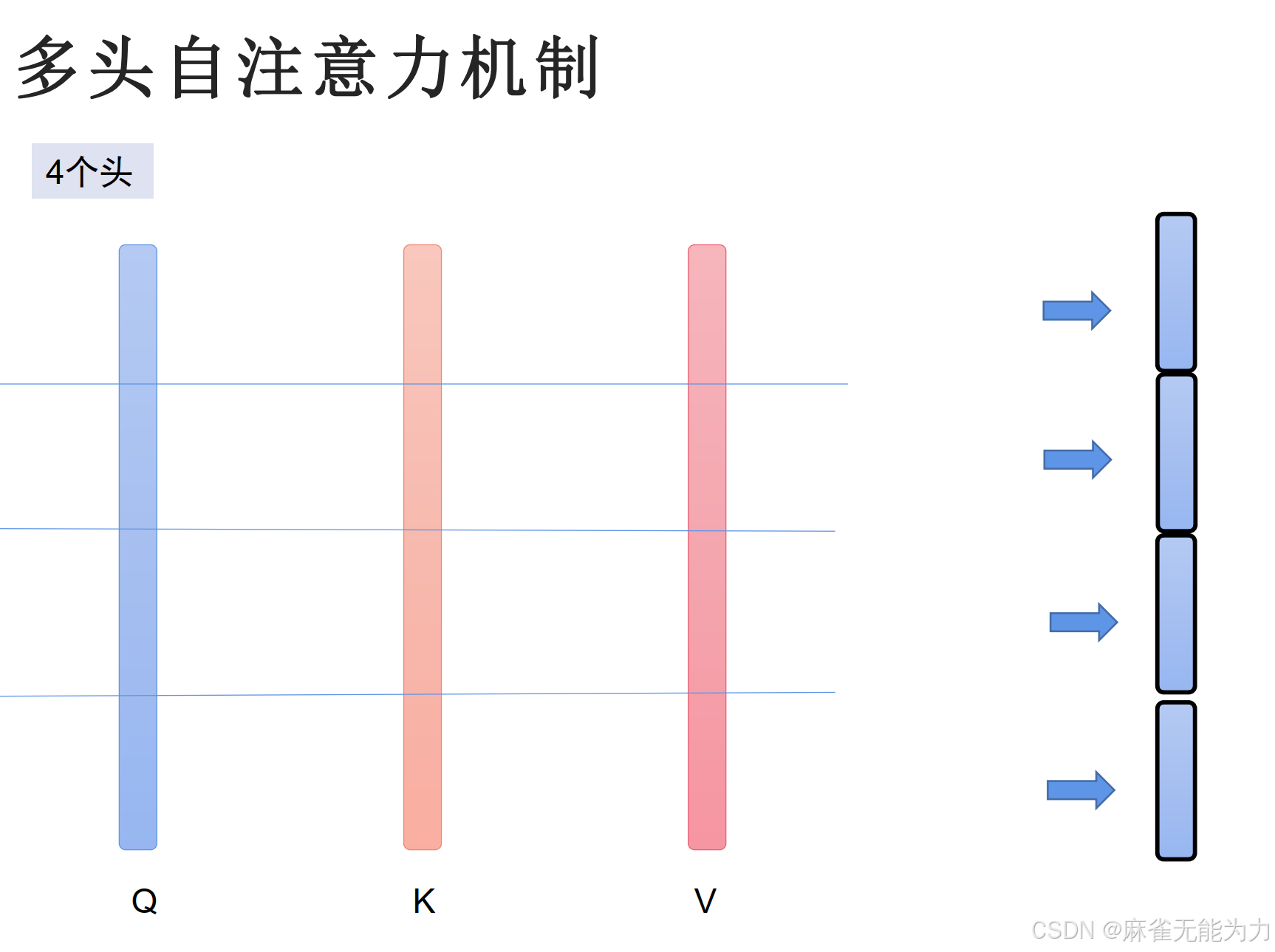
加层数:
位置信息
文字是一段序列,文字相同,顺序不同,内容完全不同
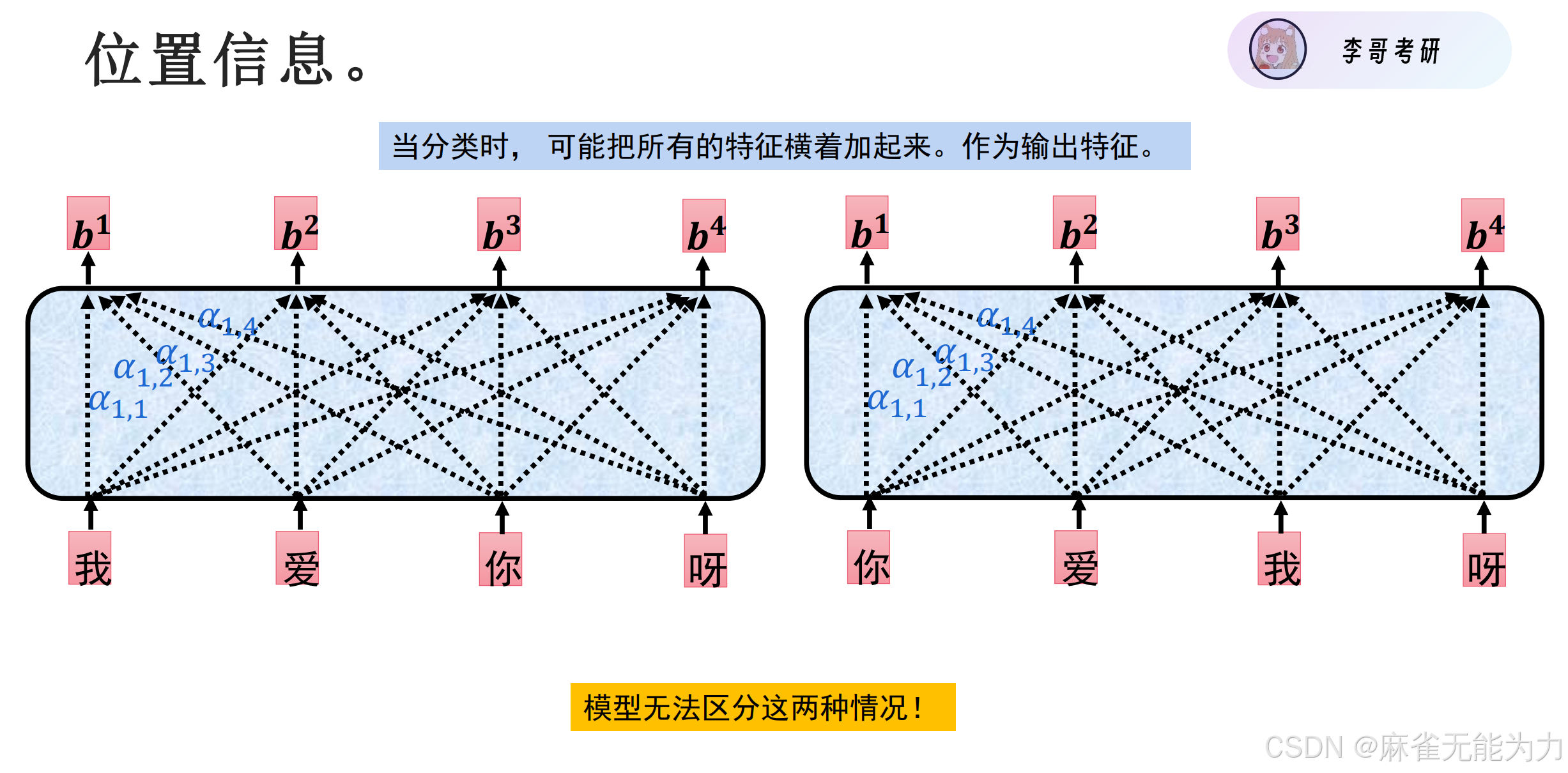
将位置信息也加入到输入数据中:
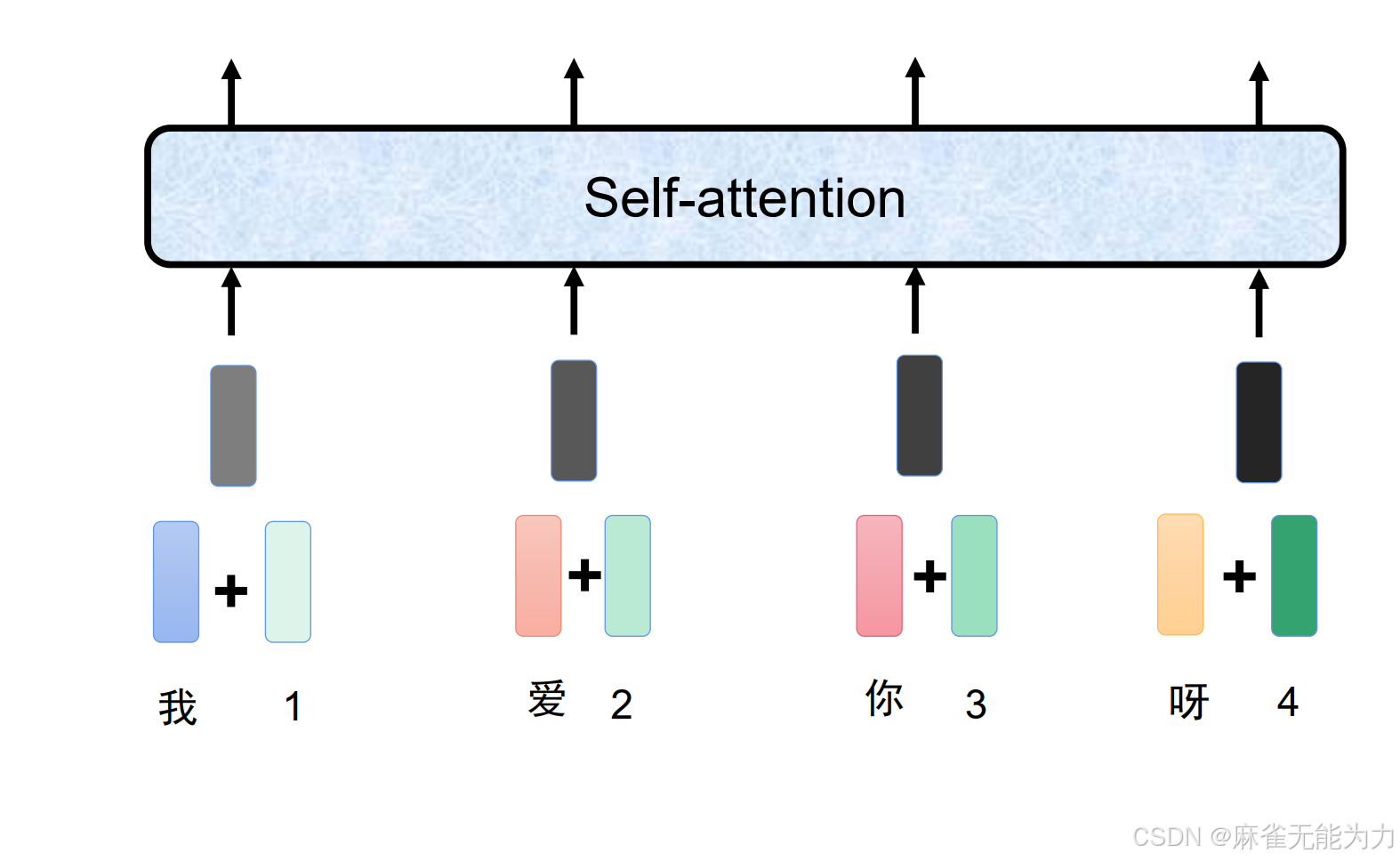
要经过一个线性变换变成输入数据的长度
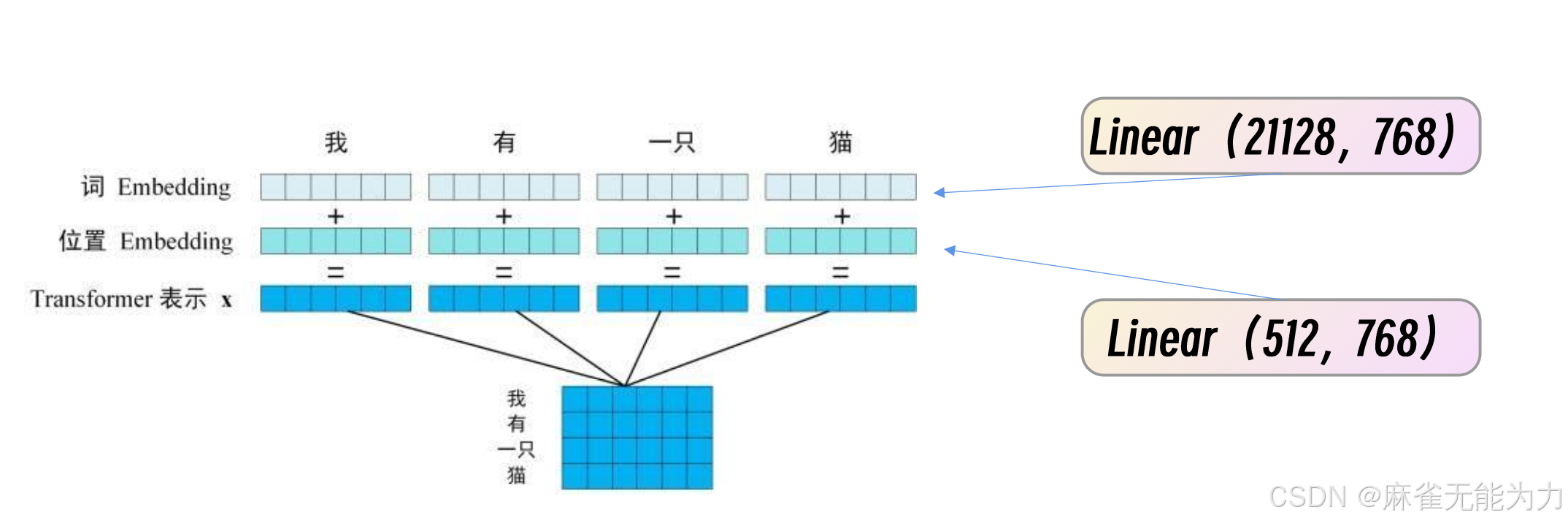
这是的输入数据称为一个token
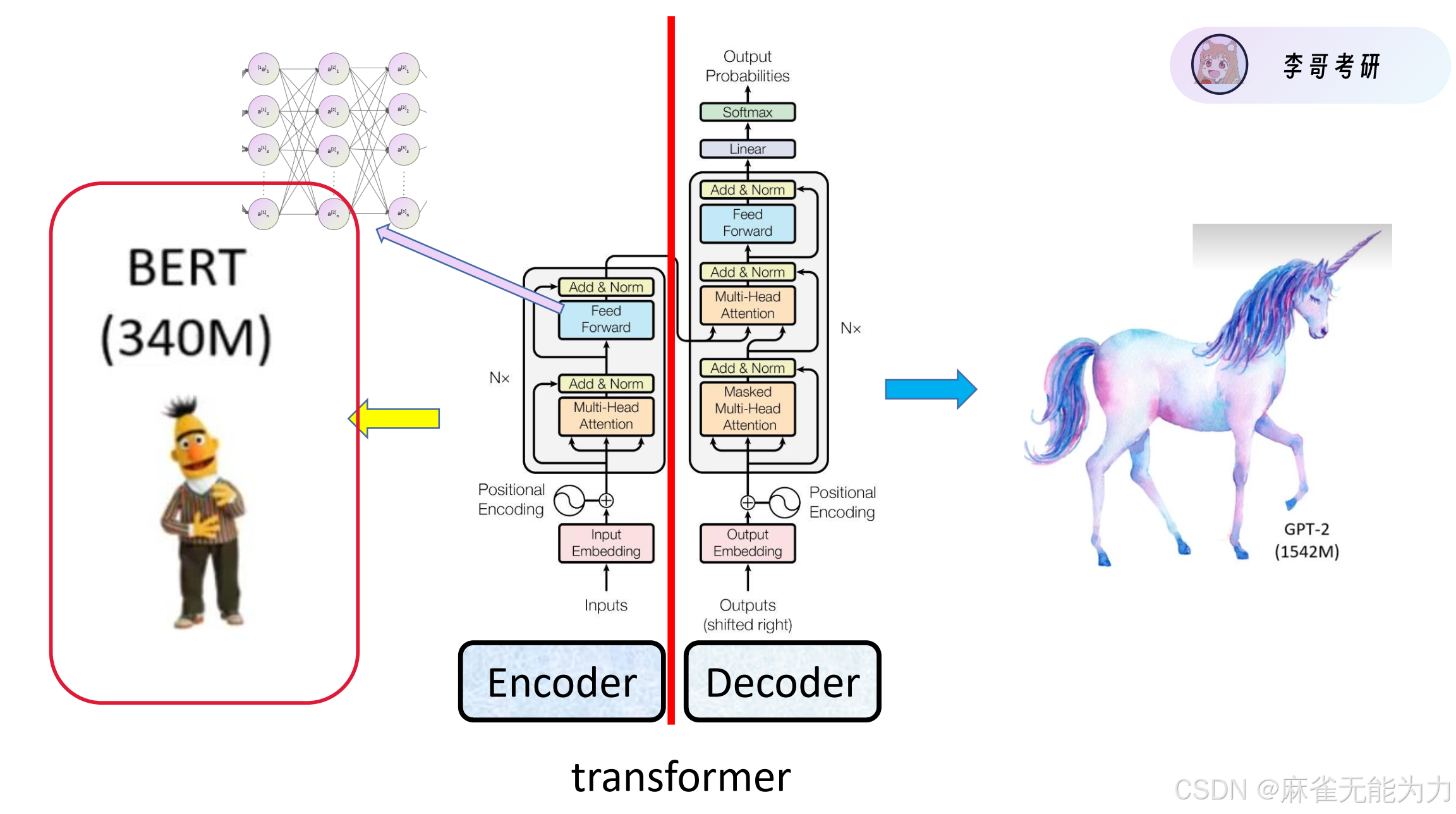
transformer模型的结构:
通过结合迁移训练的方法
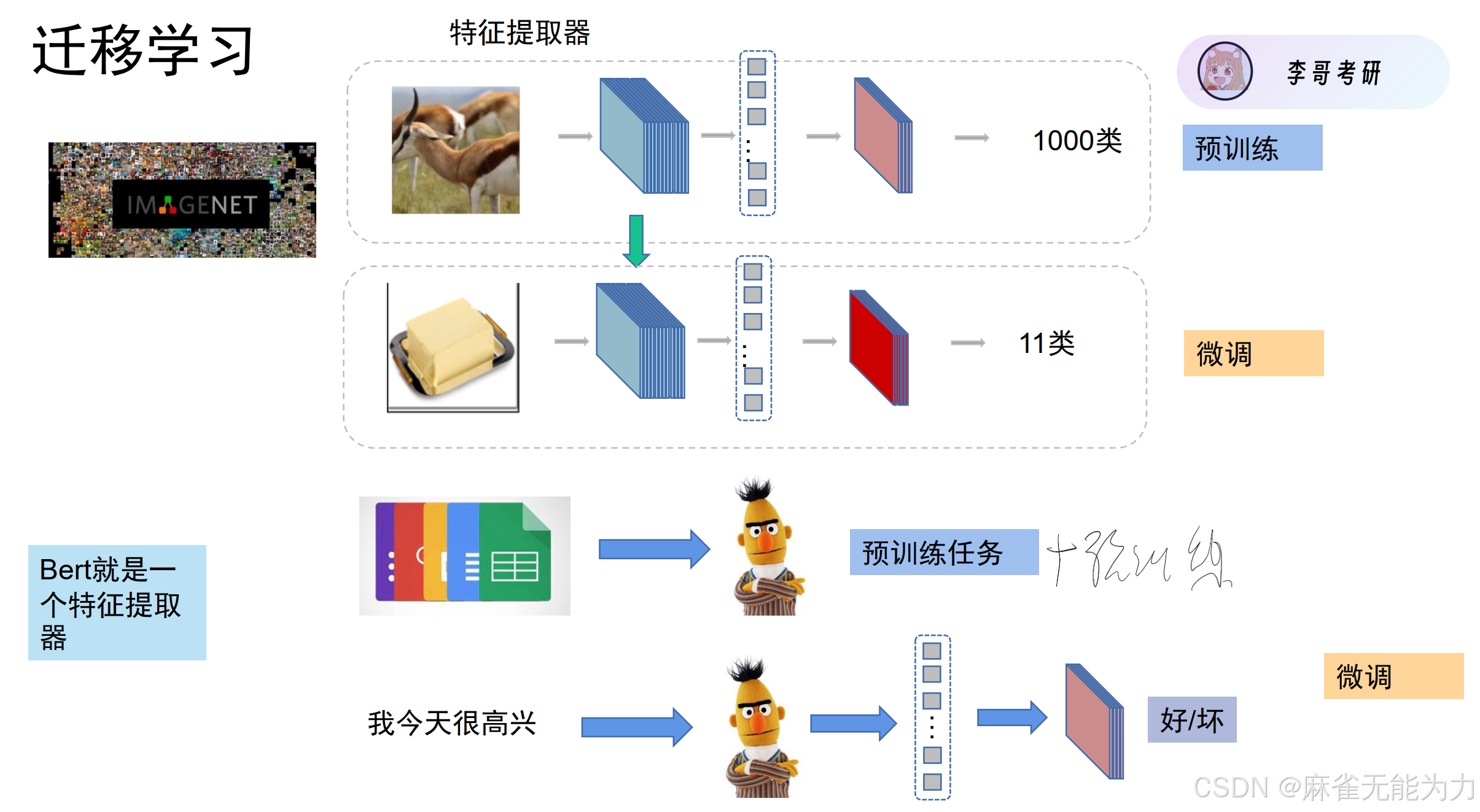
如何进行预训练:
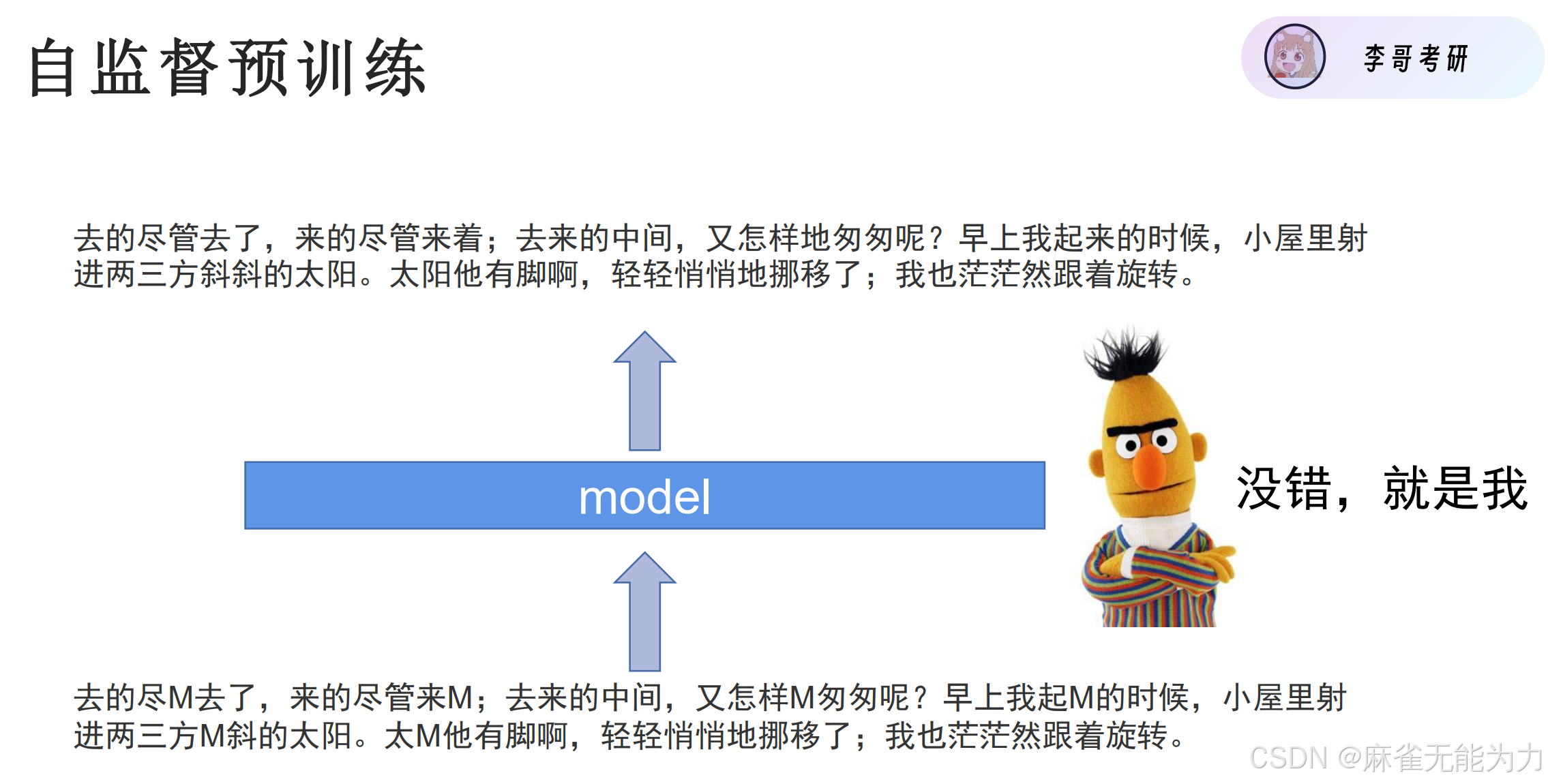
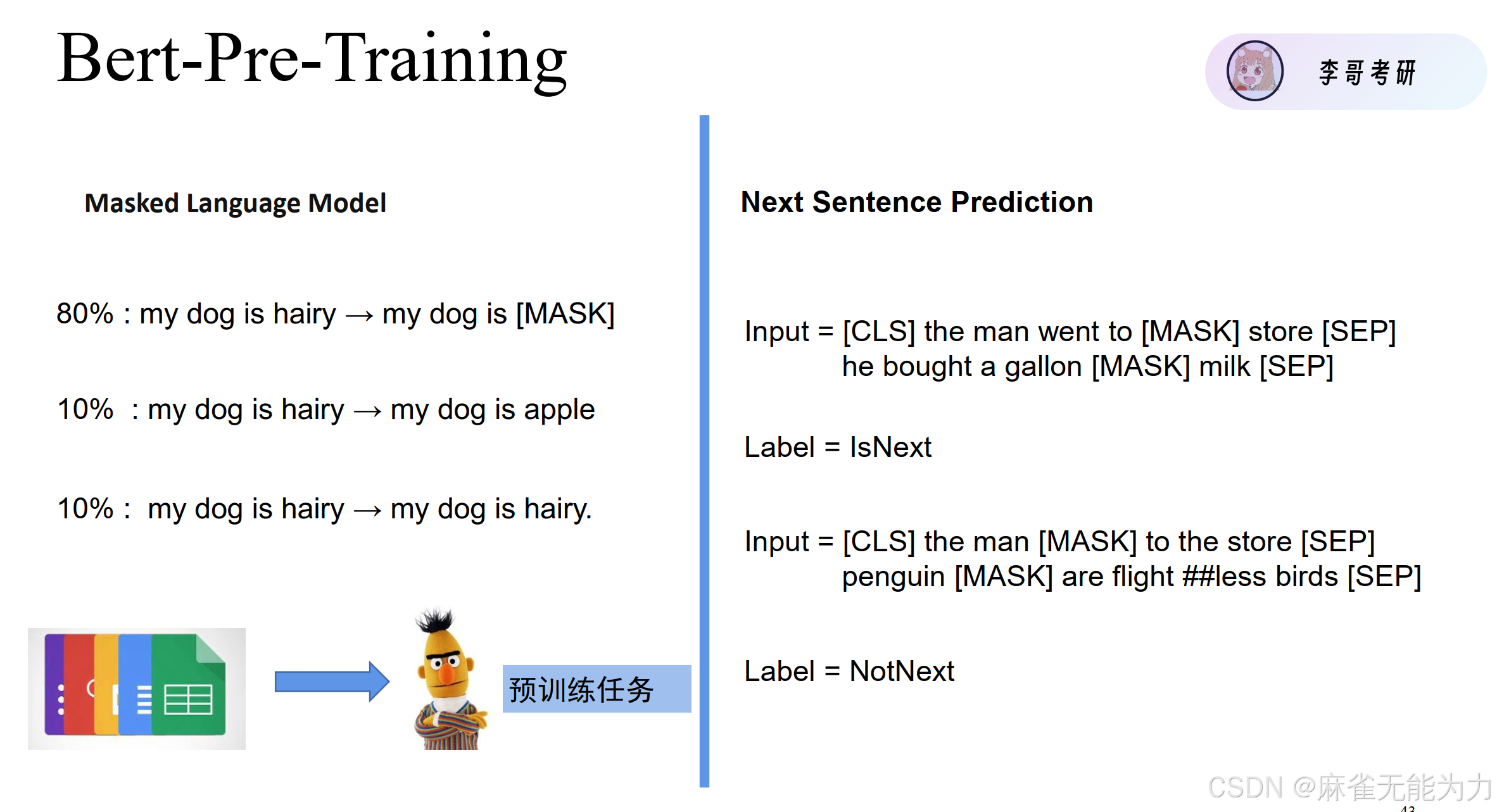
字遮罩训练和句子连续标签训练:
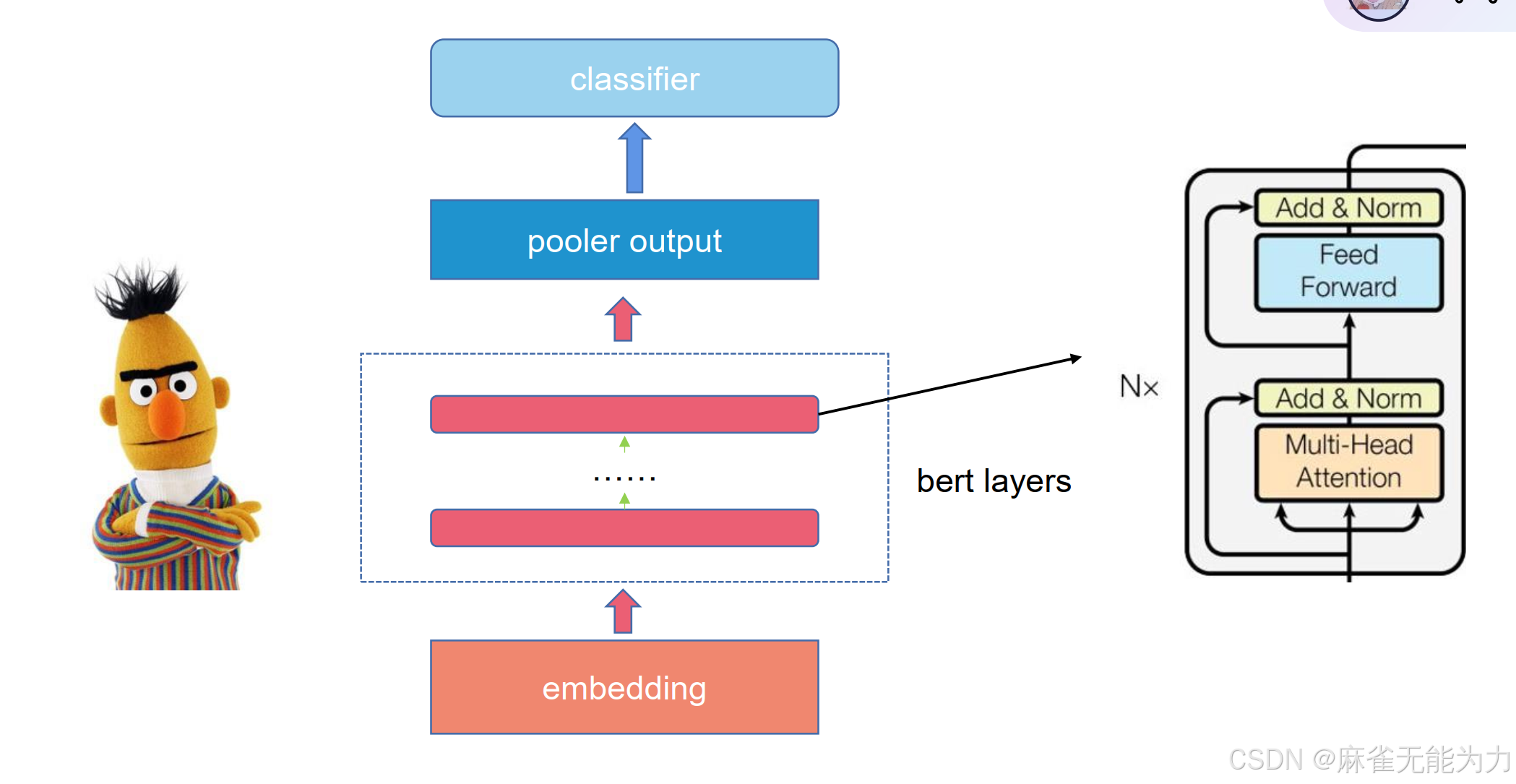
bert的结构:
bert来自一个芝麻屋中的角色:
embedding:使用one-hot
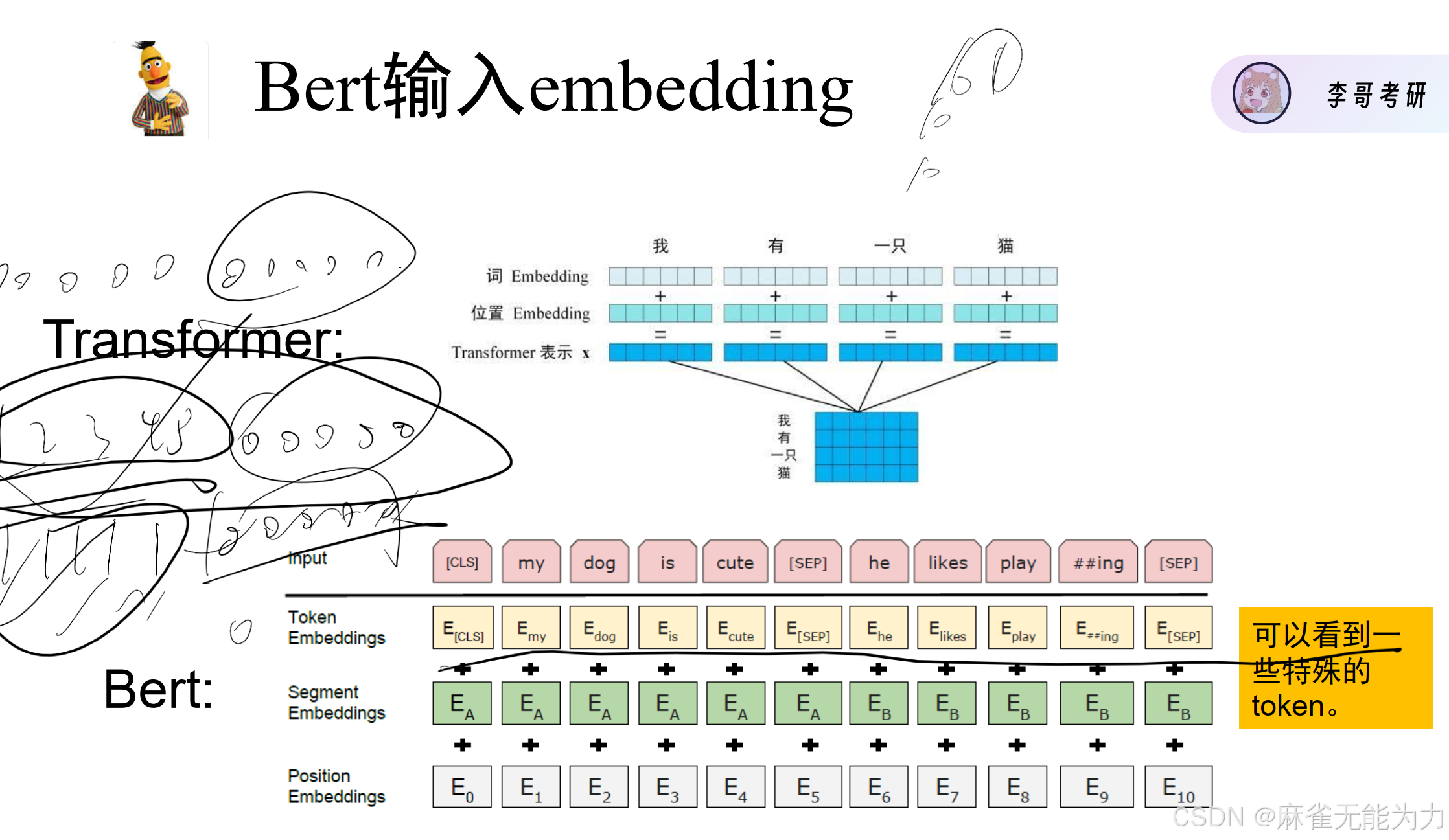
注解:Segment Embedding是表明文字属于那一句话;在input中有一些特殊的token,CLS是专门用来做分类的,它会记录全局的信息,从而拥有全局的特征,而SEP表示一个句子的结束
pooling
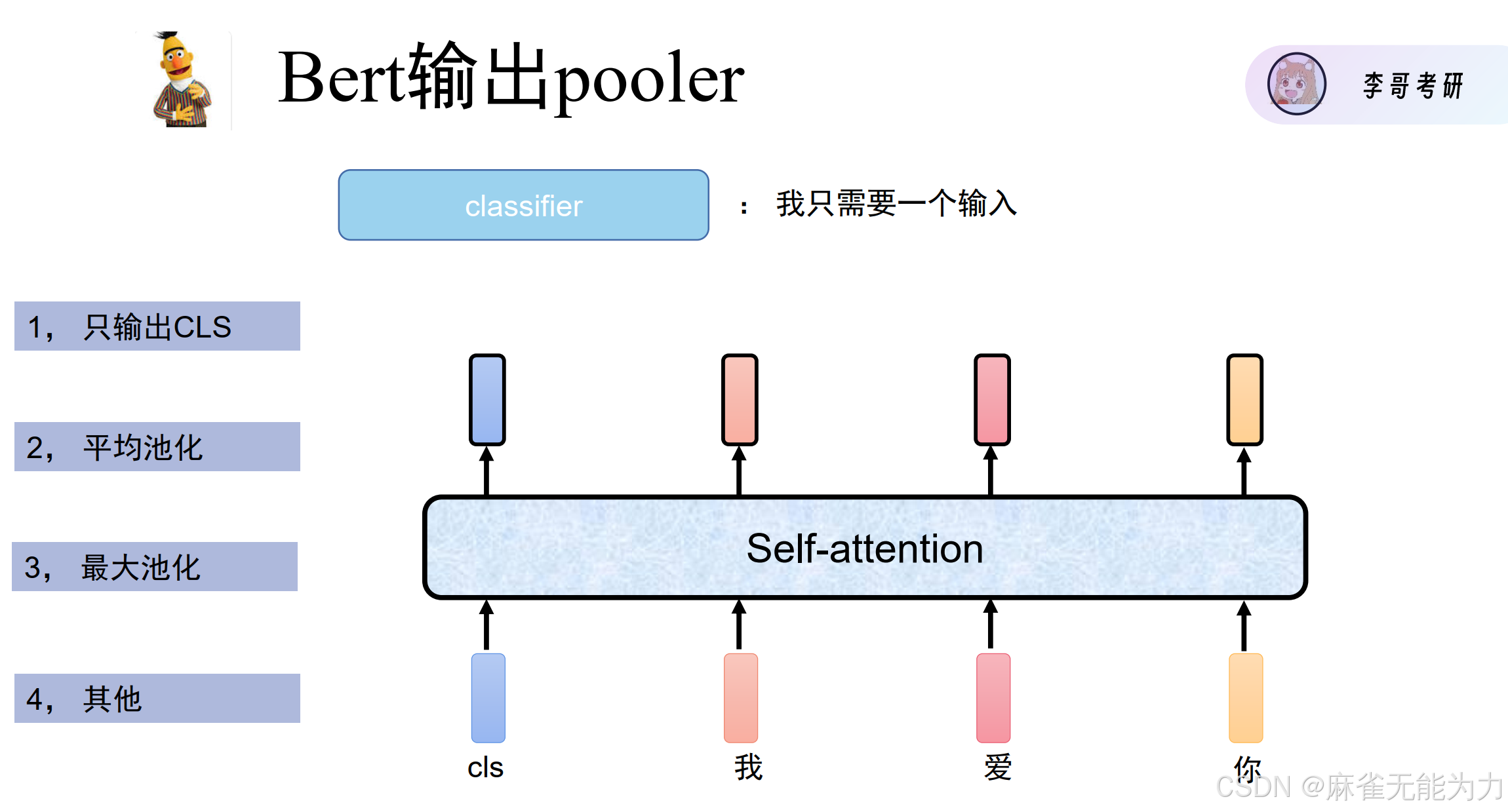
上图是一些常用的pooling方法,其他方法比如再用一层注意力机制,找到那个注意力最高的做输出



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









