






食物分类实战
固定随机种子:使训练可复现
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
HW = 224读入文件:
def read_file(self, path):
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
print("读到了%d个数据" % len(xi))
return xi
else:
for i in tqdm(range(11)): #tqdm可以显示读取进度
file_dir = path + "/%02d" % i #读取每个类别的照片的路径
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #设置装数据和标签的空容器
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list): #从路径中读出每个文件和每个文件路径的名字
img_path = os.path.join(file_dir, img_name) #链接路径和文件名形成图片目录
img = Image.open(img_path) #打开图片
img = img.resize((HW, HW)) #重新制定图片大小
xi[j, ...] = img #将标签和图片装入容器
yi[j] = i
if i == 0: #合并数据
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) #将数据竖着合并
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y注释:以上的dtype作用为规定不能为小数,因为rgb三通道都是整数表示
数据增广:

如图所示:图片在经过各种变换后人还能认识,但计算机不认识了,因为图片在变换后,原先的特征核对不上变换后的图片,因此要将原图变换后的图片也放入训练集训练。
一下是一些常用的变换:

需要调用的包
from torchvision import transforms实现的代码:
train_transform = transforms.Compose( #数据增广
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.RandomResizedCrop(224),
transforms.RandomRotation(50),
transforms.ToTensor()
]
)
val_transform = transforms.Compose(
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.ToTensor()
]
)注释:验证的时候要用原图
模型部分:
class myModel(nn.Module):
def __init__(self, num_class):
super(myModel, self).__init__()
#3 *224 *224 -> 512*7*7 -> 拉直 -》全连接分类
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 64*224*224
self.bn1 = nn.BatchNorm2d(64) #归一化
self.relu = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # 128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) #128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) #256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) #512*14*14
)
self.pool2 = nn.MaxPool2d(2) #512*7*7
self.fc1 = nn.Linear(25088, 1000) #25088->1000
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000-11
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0], -1) #拉直特征图
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x使用:
lr = 0.001
loss = nn.CrossEntropyLoss() #交叉熵损积
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4) #新的优化器:AdamW
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99新优化器的解释:

原来的优化器是sgd,Adam和sgd的区别,Adam在计算梯度时会计算上一次的梯度,比如上一次的梯度是负数,这次是整数,两者乘上各自的系数再相加还是负的那么这次的梯度依然是负数。
Adam和AdamW是区别:AdamW会动态的控制学习率,在梯度较大时相应的学习率会减小,而梯度较小时学习率会增大。
权重衰减:代码中优化器有一个参数weight_decay就是权重衰减,在参数正则化中:中,
就是权重衰减,可以让曲线变得更加平滑
训练函数:可以直接复制上一章的函数然后稍作修改
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device)
semi_loader = None
plt_train_loss = []
plt_val_loss = []
plt_train_acc = [] #准确率
plt_val_acc = []
max_acc = 0.0 #记录最高的准确率
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time()
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()) #计算一轮下来预测成功的个数,argmax给出最大的下标
plt_train_loss.append(train_loss / train_loader.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #记录准确率,
if semi_loader!= None:
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
semi_loss += train_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
print("半监督数据集的训练准确率为", semi_acc/train_loader.dataset.__len__())
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
if epoch%3 == 0 and plt_val_acc[-1] > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_loss
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1])
) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()准确值计算的原理在下图中说明:

取左边最大值下标与右边标签对比,相等的个数就是正确值的个数。
训练:
本来所有数据已经完成训练,但由于电脑突然黑屏,数据丢失,只在这大致记录一下
batch_x = 8,训练轮数:20
训练结果:准确率接近30%
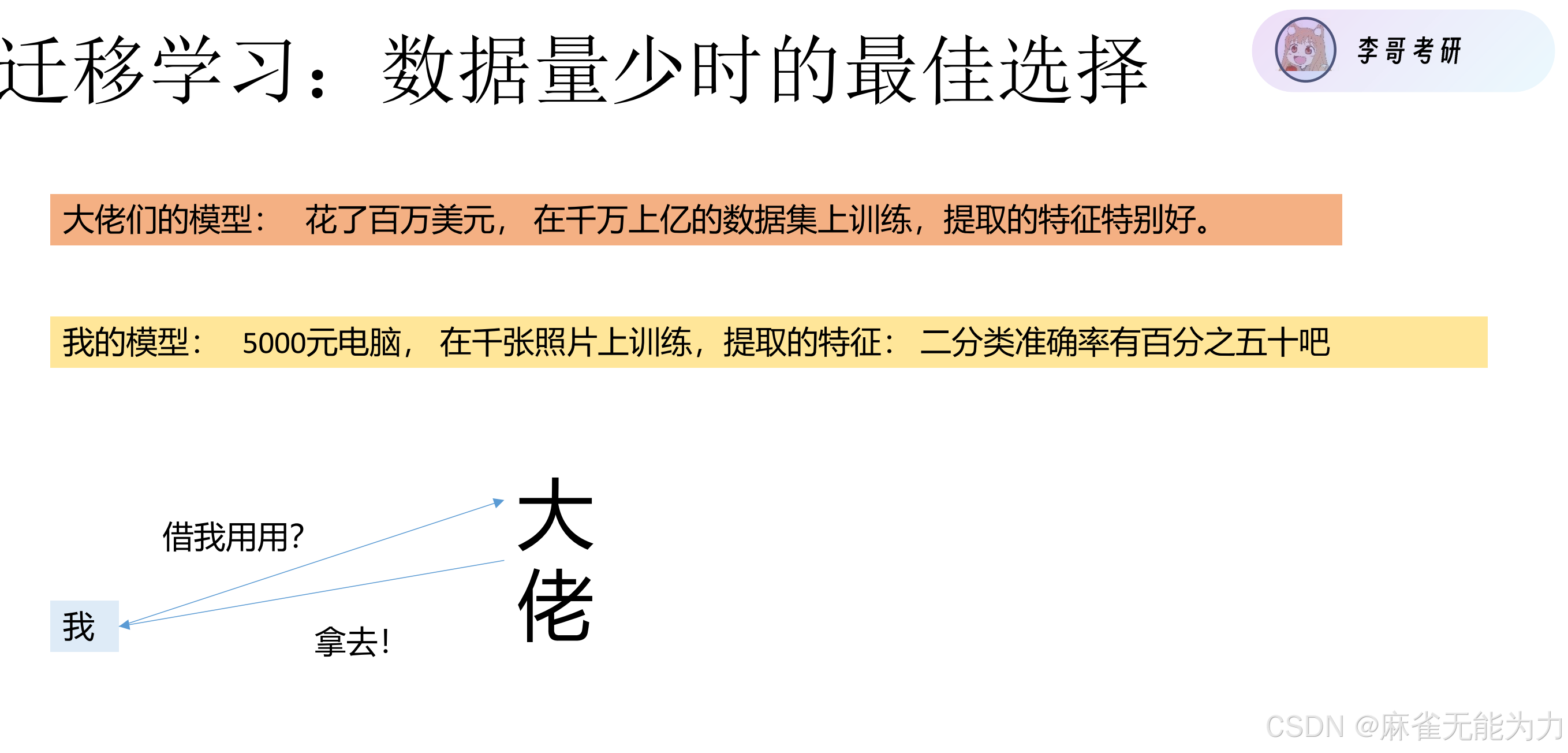
迁移训练:
不使用自己构建的模型而是直接将大佬的模型架构和参数拿过来用
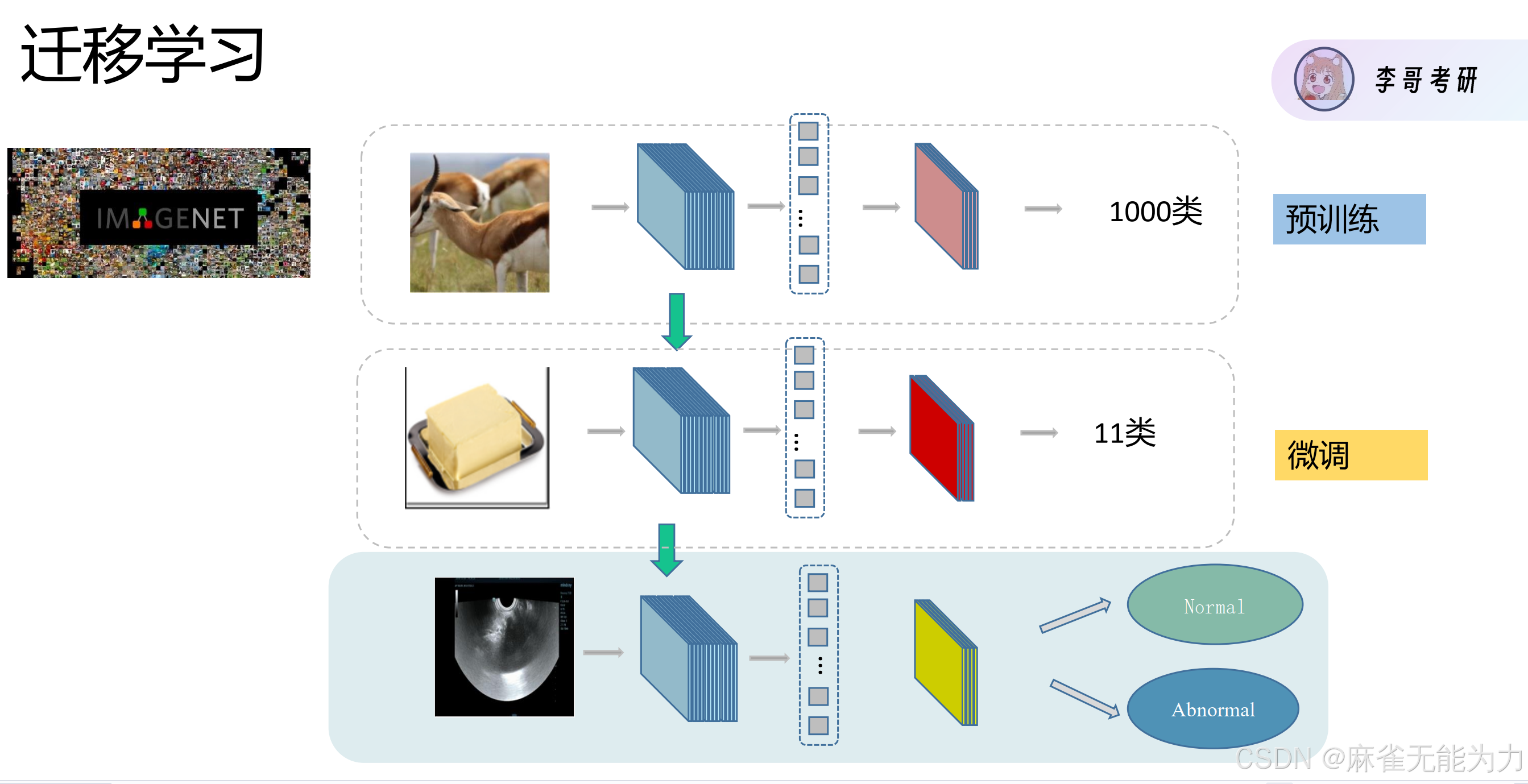
使用ResNet训练
代码:
from torchvision.models import resnet18
model = resnet18(pretrained=False) #用架构也用参数
in_features = model.fc.in_features #找出resnet分类头的输出维度
model.fc = nn.Linear(in_features, 11) #将模型的分类头改为输出维度11参数
batch_x = 8,训练轮数:40
训练结果:
训练结果丢失,准确率大致在70%左右
代码实现如下:
# model = myModel(11)
model, _ = initialize_model("vgg", 11, use_pretrained=True) #参数:调用的模型名,分类数量,时候迁移模型参数调用的包:
from model_utils.model import initialize_model线性探测:
将大佬的模型参数下载下来之后不计算梯度,完全保留原始参数就称为线性探测,否则是微调。
另:代码可以分模块使用
if __name__ == '__main__': #运行的模块, 如果你运行的模块是当前模块
print("你运行的是data.py文件")
filepath = '../food-11_sample'
train_loader = getDataLoader(filepath, 'train', 8)
for i in range(3):
samplePlot(train_loader,True,isbat=False,ori=True)
val_loader = getDataLoader(filepath, 'val', 8)
for i in range(100):
samplePlot(val_loader,True,isbat=False,ori=True)
##########################
这部分代码中:if __name__ == '__main__':表示只有运行当前文件才调用
半监督学习:
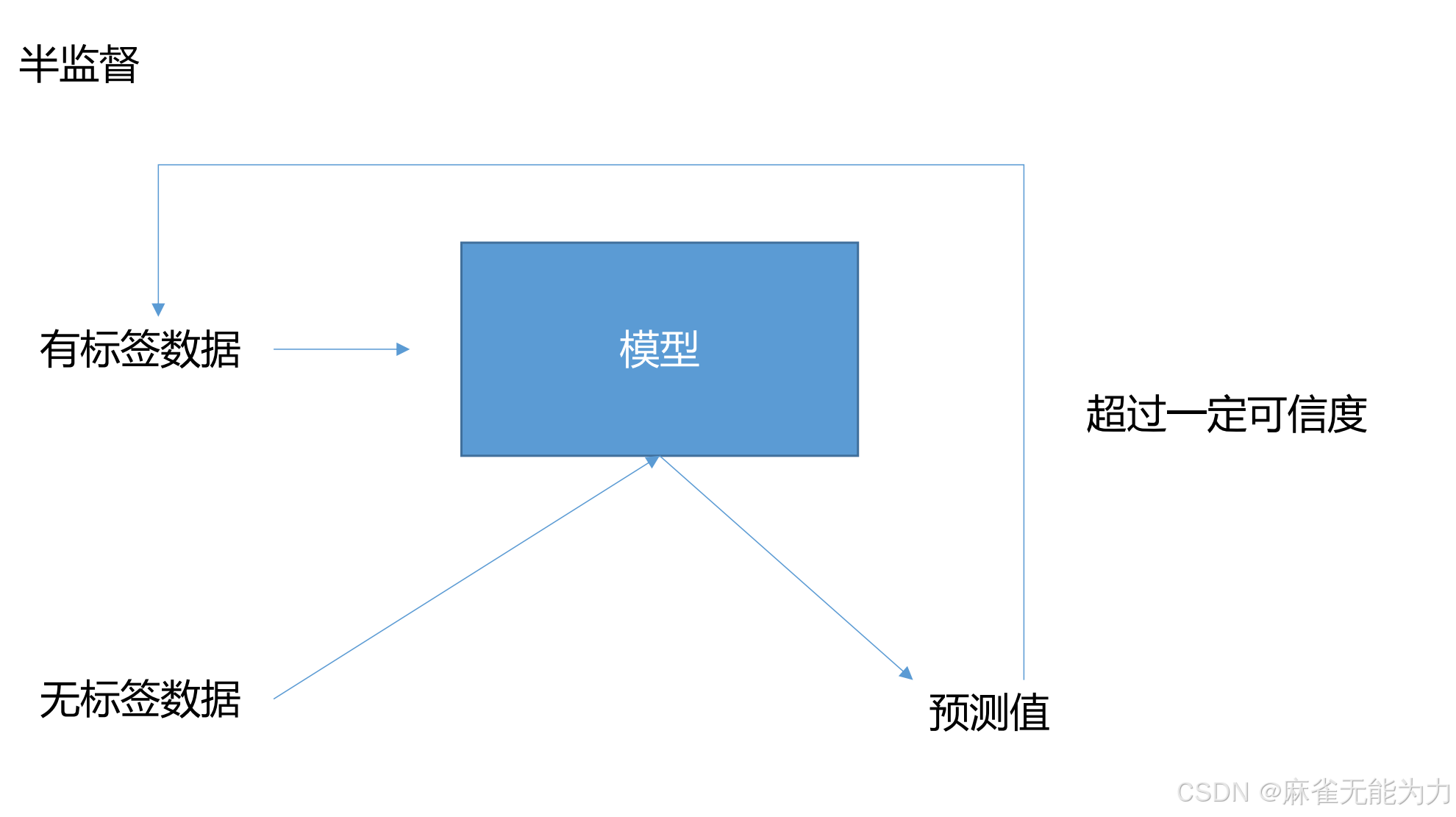
通过有标签的数据对模型进行训练,在模型准确度达到一定要求之后就用没有标签的数据过模型,为无标签数据打上标签,再当作有标签数据训练。
代码修改:
数据处理部分:
class food_Dataset(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi": #无标签数据处理
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) #标签转为长整形\(因为是整数不是小数)
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path): #将read_file函数放到类当中
if self.mode == "semi": #无标签数据读取,不读y
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
print("读到了%d个数据" % len(xi))
return xi
else:
for i in tqdm(range(11)): #tqdm可以显示读取进度
file_dir = path + "/%02d" % i #读取每个类别的照片的路径
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #设置装数据和标签的空容器
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list): #从路径中读出每个文件和每个文件路径的名字
img_path = os.path.join(file_dir, img_name) #链接路径和文件名形成图片目录
img = Image.open(img_path) #打开图片
img = img.resize((HW, HW)) #重新制定图片大小
xi[j, ...] = img #将标签和图片装入容器
yi[j] = i
if i == 0: #合并数据
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) #将数据竖着合并
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y
def __getitem__(self, item):
if self.mode == "semi": #无标签数据处理
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)其中:
def __getitem__(self, item)需要返回两组数据,一组数据用来经过变换训练标签,一组数据保持不变,贴上标签后作为训练数据。
class semiDataset(Dataset):这个类负责将无标签数据通过模型和预定的准确率变为有标签数据作为训练数据
class semiDataset(Dataset): #需要分别输入数据,模型,设备,准确率
def __init__(self, no_label_loder, model, device, thres=0.99):
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []: #如果没有合格无标签数据
self.flag = False #设置标志
else:
self.flag = True #有合格数据则进行变换
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loder, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax() #softmax
with torch.no_grad():
for bat_x, _ in no_label_loder:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred)
pred_max, pred_value = pred_soft.max(1) #得到每组数据最大值即其下标
pred_prob.extend(pred_max.cpu().numpy().tolist()) #放在cpu上变成列表
labels.extend(pred_value.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob): #遍历预测数据的下标和预测值
if prob > thres: #如果预测值大于给定的准确率
x.append(no_label_loder.dataset[index][1]) #调用到原始的getitem
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)将这部分数据加到训练数据的函数:
def get_semi_loader(no_label_loder, model, device, thres): #将填上标签的数据加到训练数据中
semiset = semiDataset(no_label_loder, model, device, thres)
if semiset.flag == False:
return None
else:
semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)
return semi_loader训练部分的修改:
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
if epoch%3 == 0 and plt_val_acc[-1] > 0.6: #验证集验证效果大于0.6就训练一轮无标签数据
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_loss
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1])
) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
在训练代码的验证集部分进行修改
if semi_loader!= None: # 新增数据集不为空则加入训练集训练参数
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
semi_loss += train_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
print("半监督数据集的训练准确率为", semi_acc/train_loader.dataset.__len__())
训练部分要考虑到新增训练集的训练
源码:
import random
import torch
import torch.nn as nn
import numpy as np
import os
from PIL import Image #读取图片数据
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from torchvision import transforms
import time
import matplotlib.pyplot as plt
from model_utils.model import initialize_model
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
HW = 224
train_transform = transforms.Compose( #数据增广
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.RandomResizedCrop(224),
transforms.RandomRotation(50),
transforms.ToTensor()
]
)
val_transform = transforms.Compose(
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.ToTensor()
]
)
class food_Dataset(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) #标签转为长整形\(因为是整数不是小数)
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
print("读到了%d个数据" % len(xi))
return xi
else:
for i in tqdm(range(11)): #tqdm可以显示读取进度
file_dir = path + "/%02d" % i #读取每个类别的照片的路径
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #设置装数据和标签的空容器
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list): #从路径中读出每个文件和每个文件路径的名字
img_path = os.path.join(file_dir, img_name) #链接路径和文件名形成图片目录
img = Image.open(img_path) #打开图片
img = img.resize((HW, HW)) #重新制定图片大小
xi[j, ...] = img #将标签和图片装入容器
yi[j] = i
if i == 0: #合并数据
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) #将数据竖着合并
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
class semiDataset(Dataset):
def __init__(self, no_label_loder, model, device, thres=0.99):
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []:
self.flag = False
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loder, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax()
with torch.no_grad():
for bat_x, _ in no_label_loder:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred)
pred_max, pred_value = pred_soft.max(1)
pred_prob.extend(pred_max.cpu().numpy().tolist())
labels.extend(pred_value.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob):
if prob > thres:
x.append(no_label_loder.dataset[index][1]) #调用到原始的getitem
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
def get_semi_loader(no_label_loder, model, device, thres):
semiset = semiDataset(no_label_loder, model, device, thres)
if semiset.flag == False:
return None
else:
semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)
return semi_loader
class myModel(nn.Module):
def __init__(self, num_class):
super(myModel, self).__init__()
#3 *224 *224 -> 512*7*7 -> 拉直 -》全连接分类
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 64*224*224
self.bn1 = nn.BatchNorm2d(64) #归一化
self.relu = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # 128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) #128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) #256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) #512*14*14
)
self.pool2 = nn.MaxPool2d(2) #512*7*7
self.fc1 = nn.Linear(25088, 1000) #25088->1000
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000-11
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0], -1) #拉直特征图
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device)
semi_loader = None
plt_train_loss = []
plt_val_loss = []
plt_train_acc = [] #准确率
plt_val_acc = []
max_acc = 0.0 #记录最高的准确率
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time()
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()) #计算一轮下来预测成功的个数,argmax给出最大的下标
plt_train_loss.append(train_loss / train_loader.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #记录准确率,
if semi_loader!= None:
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
semi_loss += train_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
print("半监督数据集的训练准确率为", semi_acc/train_loader.dataset.__len__())
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
if epoch%3 == 0 and plt_val_acc[-1] > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_loss
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1])
) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
# path = r"F:\pycharm\beike\classification\food_classification\food-11\training\labeled"
# train_path = r"F:\pycharm\beike\classification\food_classification\food-11\training\labeled"
# val_path = r"F:\pycharm\beike\classification\food_classification\food-11\validation"
train_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\labeled"
val_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\validation"
no_label_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\unlabeled\00"
train_set = food_Dataset(train_path, "train")
val_set = food_Dataset(val_path, "val")
no_label_set = food_Dataset(no_label_path, "semi")
train_loader = DataLoader(train_set, batch_size=16, shuffle=True) #将数据分成批次
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False)
# model = myModel(11)
model, _ = initialize_model("vgg", 11, use_pretrained=True) #参数:调用的模型名,分类数量,时候迁移模型参数
lr = 0.001
loss = nn.CrossEntropyLoss() #交叉熵损积
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4) #新的优化器:AdamW
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









