






实战案例为新冠感染人数预测项目:
依赖的包
import numpy as np
import csv
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import torch.nn as nn
from torch import optim
import time
from sklearn.feature_selection import SelectKBest, chi2
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"代码结构:
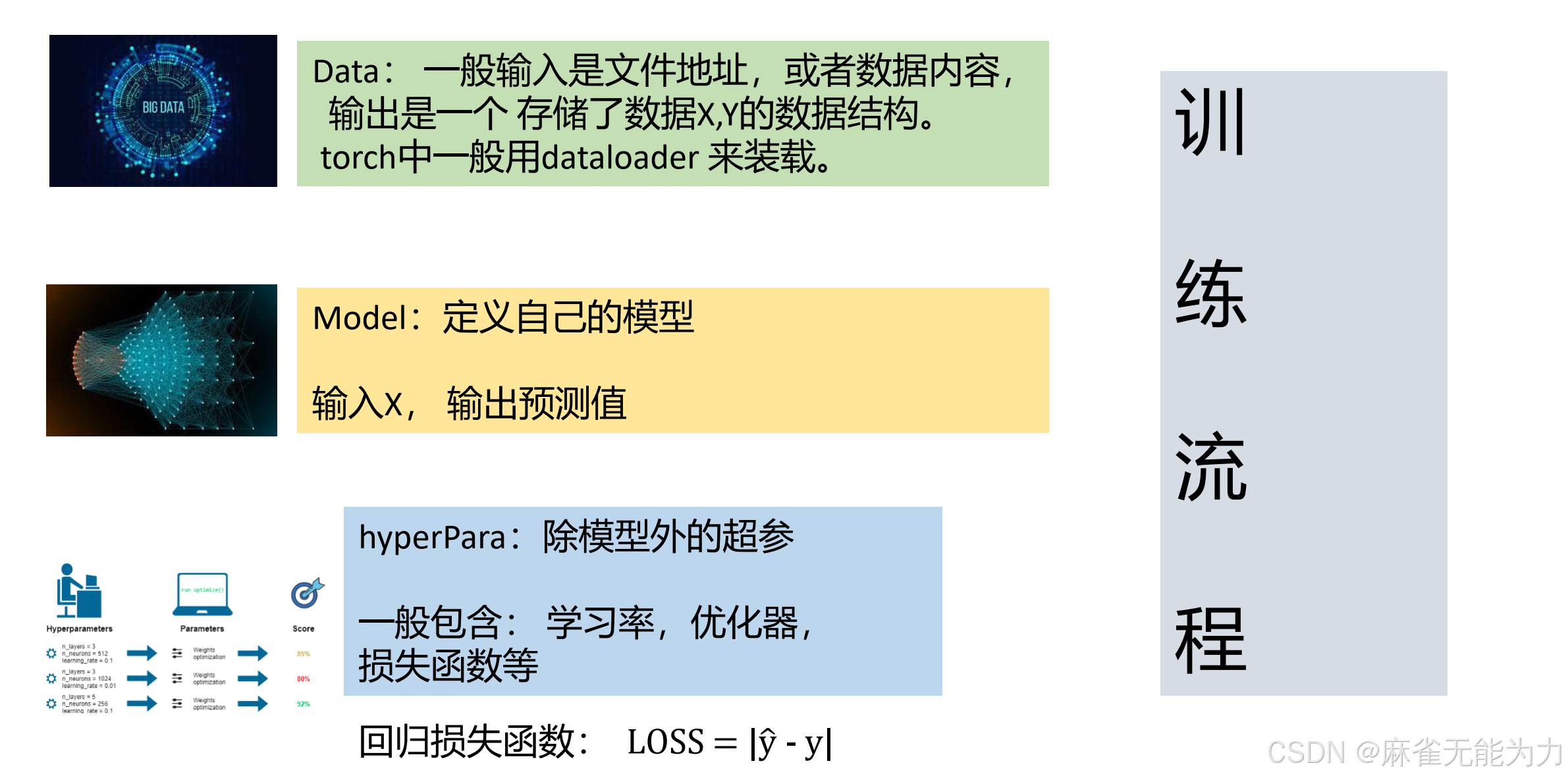
Data部分:
何为Dataset类?

Dataset类的作用为处理文件数据,将文件地址输入后输出整理好的数据x和y
Dataset类用三个函数完成上述过程:init函数负责初始化,输入的文件地址,输出x,y两个数据
getitem函数负责取对应下标的数据
len函数取数据的长度
具体代码如下:
class CovidDataset(Dataset):
def __init__(self, file_path, mode="train", all_feature=False, feature_dim=6):
with open(file_path, "r") as f: #打开文件
ori_data = list(csv.reader(f)) #取出数据
column = ori_data[0] #取数据第一行
csv_data = np.array(ori_data[1:])[:, 1:].astype(float) #去除数据第一行第一列并转化为矩阵,将数据类型修改为浮点数
feature = np.array(ori_data[1:])[:, 1:-1]
label_data = np.array(ori_data[1:])[:, -1]
if all_feature:
col = np.array([i for i in range(0, 93)])
else:
_, col = get_feature_importance(feature, label_data, feature_dim, column)
col = col.tolist()
if mode == "train": #逢5取1. #根据模式对数据进行处理
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
data = torch.tensor(csv_data[indices, :-1]) #转为张量
self.y = torch.tensor(csv_data[indices, -1])
elif mode == "val": #验证数据
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
data = torch.tensor(csv_data[indices, :-1])
self.y = torch.tensor(csv_data[indices, -1])
else: #检验数据
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices])
data = data[:, col]
self.data = (data- data.mean(dim=0, keepdim=True))/data.std(dim=0, keepdim=True) #归一化(mean是对数据特定维度进行处理)
self.mode = mode
def __getitem__(self, idx):
if self.mode != "test": #根据模式取数据
return self.data[idx].float(), self.y[idx].float() #根据下标取数据
else:
return self.data[idx].float()
def __len__(self): #返回数据长度
return len(self.data)
代码解析均在注释当中,没有注释的代码作用将在下文中提到
随机梯度下降
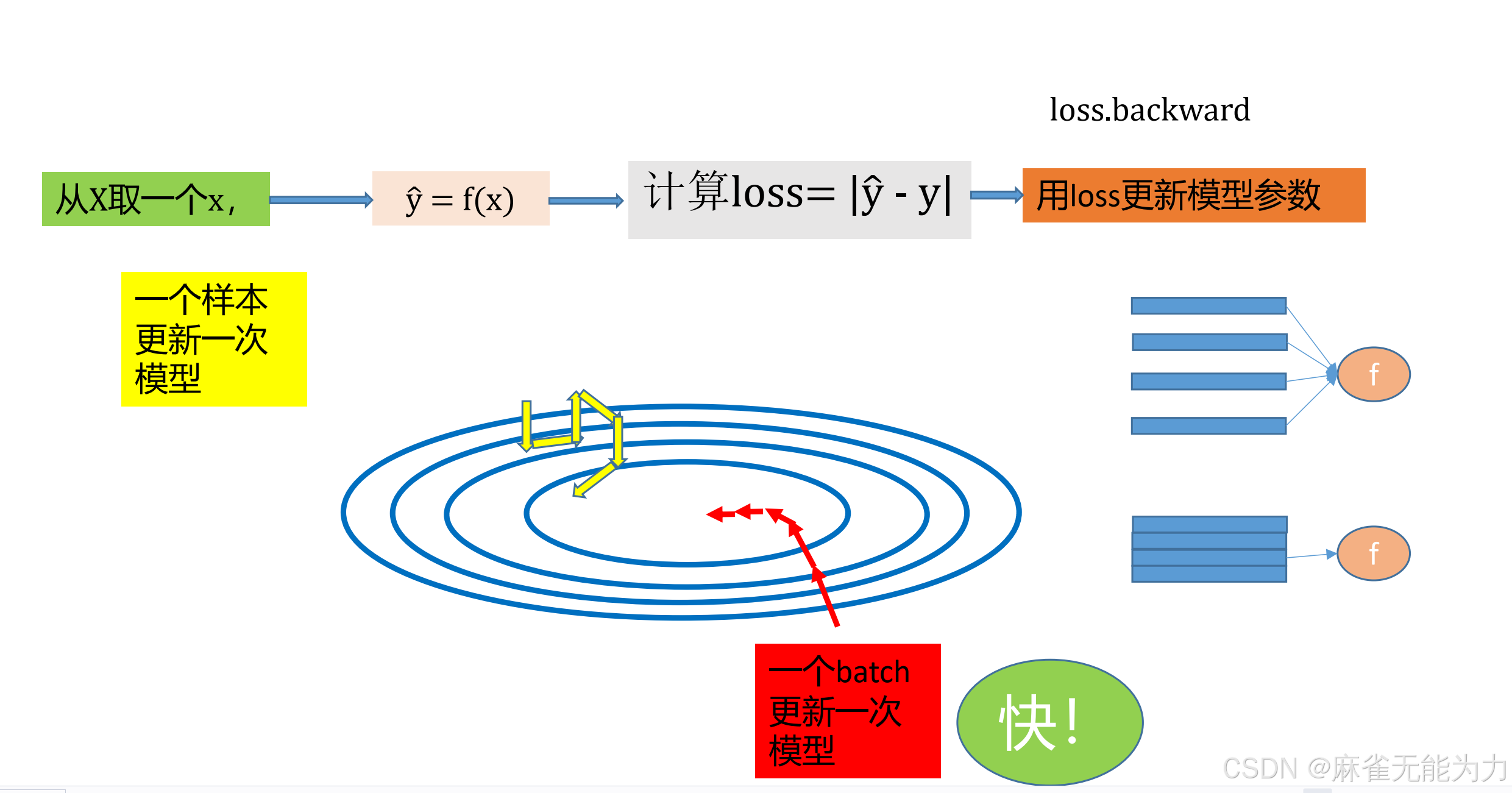
如图采用批次训练的方法处理梯度,一个batch为一批
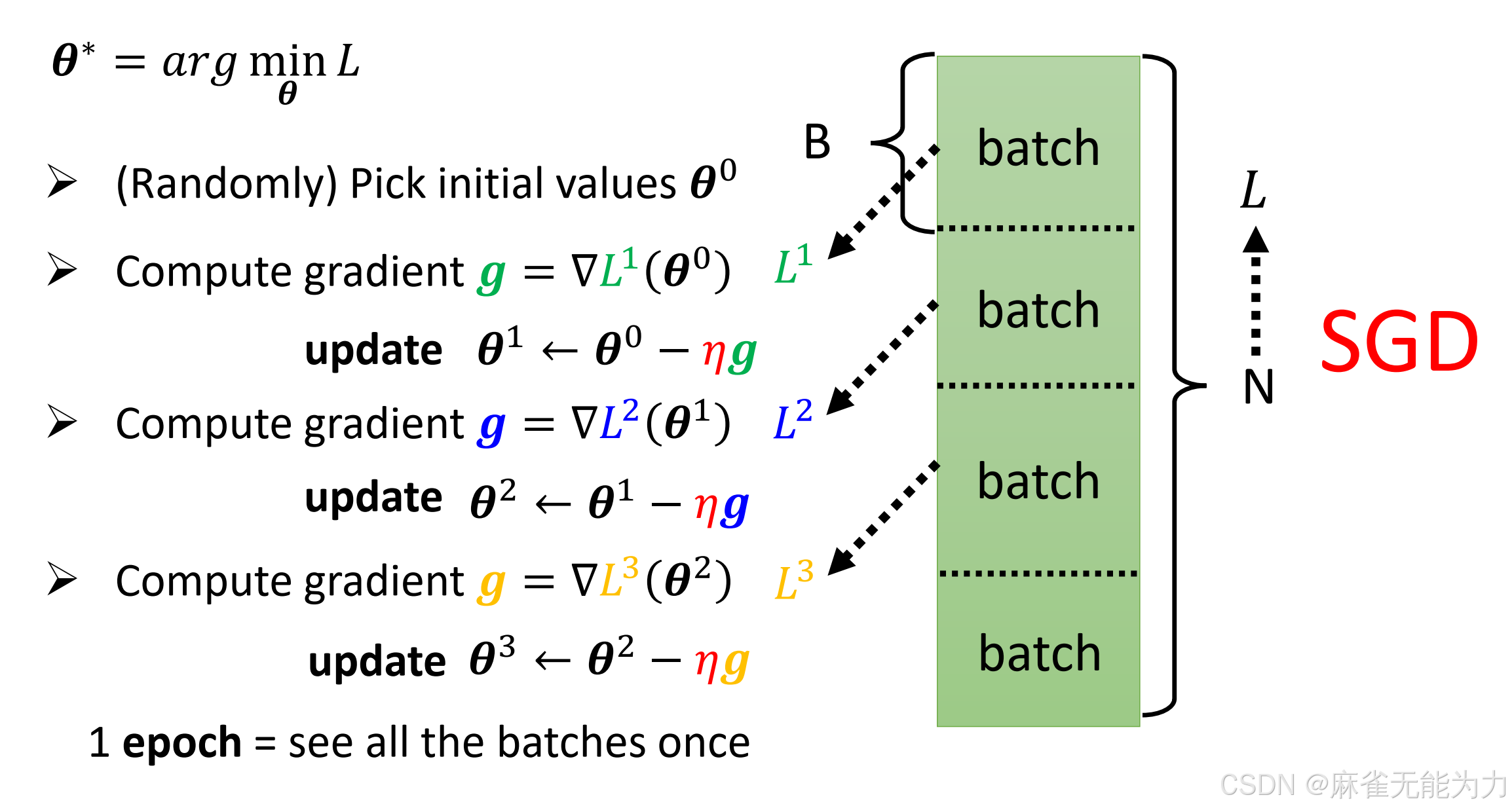
代码如下:
train_dataset = CovidDataset(train_file, "train",all_feature=all_feature, feature_dim=feature_dim) #根据模式取数据
val_dataset = CovidDataset(train_file, "val",all_feature=all_feature, feature_dim=feature_dim)
test_dataset = CovidDataset(test_file, "test",all_feature=all_feature, feature_dim=feature_dim)
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) #随机梯度下降,batch_size为一批数据大小,shuffle为是否随机打乱
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)model部分

model的类
代码如下:
class MyModel(nn.Module): #继承
def __init__(self, inDim): #inDim为输入维度
super(MyModel, self).__init__() #重新定义模型
self.fc1 = nn.Linear(inDim, 64)
self.relu1 = nn.ReLU() #定义激活函数
self.fc2 = nn.Linear(64, 1)
def forward(self, x): #模型前向过程
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size()) > 1: #将x的数据降为1维
return x.squeeze(1) #squeeze(1)表示1维(0,1,2,~)
return xhaperara
代码如下:
device = "cuda" if torch.cuda.is_available() else "cpu" #设置设备
print(device)
config = { #设置参数
"lr": 0.001, #学习率
"epochs": 20, #训练轮数
"momentum": 0.9, #动量
"save_path": "model_save/best_model.pth", #最佳模型保存路径
"rel_path": "pred.csv"
}
train_val(model, train_loader, val_loader, device, config["epochs"], optimizer, loss, config["save_path"]) #训练函数关于动量的解释:

梯度下降优化当中,极值不一定是最值,因此保留一个动量增加优化到最值的几率
训练函数的实现
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
model = model.to(device)
plt_train_loss = [] #记录所有轮次的loss
plt_val_loss = []
min_val_loss = 9999999999999
for epoch in range(epochs): #冲锋的号角
train_loss = 0.0 #每轮次的loss
val_loss = 0.0
start_time = time.time() #起始时间
model.train() #模型调为训练模式
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device) #数据上设备
pred = model(x) #数据过模型
train_bat_loss = loss(pred, target,model) #算loss
train_bat_loss.backward() #算loss回传
optimizer.step() #更新模型的作用
optimizer.zero_grad() #梯度清零
train_loss += train_bat_loss.cpu().item() #本轮loss累加
plt_train_loss.append(train_loss / train_loader.__len__()) #计算本轮平均loss,train_loader.__len__()为该轮批次次数
model.eval() #模型调整为验证模式
with torch.no_grad(): #验证模式不用更新梯度
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target,model)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss/ val_loader.__len__())
if val_loss < min_val_loss: #验证训练效果
torch.save(model, save_path) #保存最好的训练参数
min_val_loss = val_loss
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f"% \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1])) #打印信息
plt.plot(plt_train_loss) #画图
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()测试函数部分:
def evaluate(sava_path, test_loader,device,rel_path ): #得出测试结果文件
model = torch.load(sava_path).to(device)
rel = [] #输出数据
with torch.no_grad():
for x in test_loader:
pred = model(x.to(device)) #过模型输出预测值
rel.append(pred.cpu().item())
print(rel)
with open(rel_path, "w",newline='') as f: #打开保存到csv文件 newline表示设定行尾添加内容,这里为什么都不做目的是不要换行
csvWriter = csv.writer(f)
csvWriter.writerow(["id","tested_positive"]) #writerow会自动换行,因此要去除上面的换行
for i, value in enumerate(rel):
csvWriter.writerow([str(i), str(value)])
print("文件已经保存到"+rel_path)
evaluate(config["save_path"], test_loader, device, config["rel_path"]) #调用函数其他优化
loss的正则化
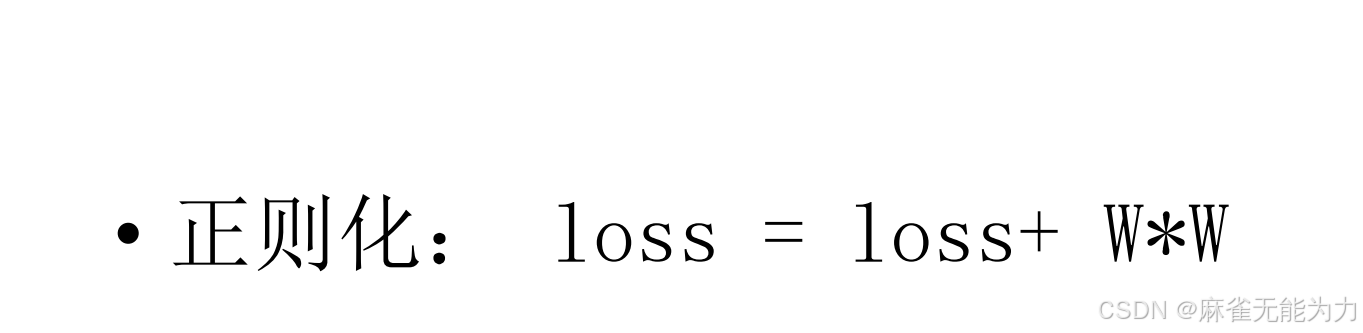
目的是将参数w尽量减小,因为在loss计算时会乘以w,较小的w可以避免偏移较大的点的影响,避免过拟合。(能减小loss的原因:优化过程loss会降低,将w加入loss,w也会下降),一般w*w前会加一个很小的系数,因为w一般较大。
代码:
def mseLoss_with_reg(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失。相关系数线性相关:
取出所有列数据中最重要的几列进行计算,避免其他无关项的干扰:(通过计算相关系数的方法)
代码:
#构造函数
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
#在类中添加选项
def __init__(self, file_path, mode="train", all_feature=False, feature_dim=6):
all_feature = False #设定模式
if all_feature:
feature_dim = 93
else:
feature_dim = 6包括所有调用类和模型的地方都要修改,此处不再赘述,可在源码中查看
源码:
import matplotlib.pyplot as plt
import torch
import numpy as np
import csv
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import torch.nn as nn
from torch import optim
import time
from sklearn.feature_selection import SelectKBest, chi2
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
class CovidDataset(Dataset):
def __init__(self, file_path, mode="train", all_feature=False, feature_dim=6):
with open(file_path, "r") as f: #打开文件
ori_data = list(csv.reader(f)) #取出数据
column = ori_data[0] #取数据第一行
csv_data = np.array(ori_data[1:])[:, 1:].astype(float) #去除数据第一行第一列并转化为矩阵,将数据类型修改为浮点数
feature = np.array(ori_data[1:])[:, 1:-1]
label_data = np.array(ori_data[1:])[:, -1]
if all_feature:
col = np.array([i for i in range(0, 93)])
else:
_, col = get_feature_importance(feature, label_data, feature_dim, column)
col = col.tolist()
if mode == "train": #逢5取1. #根据模式对数据进行处理
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
data = torch.tensor(csv_data[indices, :-1]) #转为张量
self.y = torch.tensor(csv_data[indices, -1])
elif mode == "val": #验证数据
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
data = torch.tensor(csv_data[indices, :-1])
self.y = torch.tensor(csv_data[indices, -1])
else: #检验数据
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices])
data = data[:, col]
self.data = (data- data.mean(dim=0, keepdim=True))/data.std(dim=0, keepdim=True) #归一化(mean是对数据特定维度进行处理)
self.mode = mode
def __getitem__(self, idx):
if self.mode != "test": #根据模式取数据
return self.data[idx].float(), self.y[idx].float() #根据下标取数据
else:
return self.data[idx].float()
def __len__(self): #返回数据长度
return len(self.data)
class MyModel(nn.Module): #继承
def __init__(self, inDim): #inDim为输入维度
super(MyModel, self).__init__() #重新定义模型
self.fc1 = nn.Linear(inDim, 64)
self.relu1 = nn.ReLU() #定义激活函数
self.fc2 = nn.Linear(64, 1)
def forward(self, x): #模型前向过程
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size()) > 1: #将x的数据降为1维
return x.squeeze(1) #squeeze(1)表示1维(0,1,2,~)
return x
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
model = model.to(device)
plt_train_loss = [] #记录所有轮次的loss
plt_val_loss = []
min_val_loss = 9999999999999
for epoch in range(epochs): #冲锋的号角
train_loss = 0.0 #每轮次的loss
val_loss = 0.0
start_time = time.time() #起始时间
model.train() #模型调为训练模式
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device) #数据上设备
pred = model(x) #数据过模型
train_bat_loss = loss(pred, target,model) #算loss
train_bat_loss.backward() #算loss回传
optimizer.step() #更新模型的作用
optimizer.zero_grad() #梯度清零
train_loss += train_bat_loss.cpu().item() #本轮loss累加
plt_train_loss.append(train_loss / train_loader.__len__()) #计算本轮平均loss,train_loader.__len__()为该轮批次次数
model.eval() #模型调整为验证模式
with torch.no_grad(): #验证模式不用更新梯度
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target,model)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss/ val_loader.__len__())
if val_loss < min_val_loss: #验证训练效果
torch.save(model, save_path) #保存最好的训练参数
min_val_loss = val_loss
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f"% \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1])) #打印信息
plt.plot(plt_train_loss) #画图
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
def evaluate(sava_path, test_loader,device,rel_path ): #得出测试结果文件
model = torch.load(sava_path).to(device)
rel = [] #输出数据
with torch.no_grad():
for x in test_loader:
pred = model(x.to(device)) #过模型输出预测值
rel.append(pred.cpu().item())
print(rel)
with open(rel_path, "w",newline='') as f: #打开保存到csv文件 newline表示设定行尾添加内容,这里为什么都不做目的是不要换行
csvWriter = csv.writer(f)
csvWriter.writerow(["id","tested_positive"]) #writerow会自动换行,因此要去除上面的换行
for i, value in enumerate(rel):
csvWriter.writerow([str(i), str(value)])
print("文件已经保存到"+rel_path)
all_feature = False
if all_feature:
feature_dim = 93
else:
feature_dim = 6
train_file = "covid.train.csv"
test_file = "covid.test.csv"
train_dataset = CovidDataset(train_file, "train",all_feature=all_feature, feature_dim=feature_dim) #根据模式取数据
val_dataset = CovidDataset(train_file, "val",all_feature=all_feature, feature_dim=feature_dim)
test_dataset = CovidDataset(test_file, "test",all_feature=all_feature, feature_dim=feature_dim)
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) #随机梯度下降,batch_size为一批数据大小,shuffle为是否随机打乱
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
# for batch_x, batch_y in train_loader:
# print(batch_x, batch_y)
#
# predy = model(batch_x)
#
# file = pd.read_csv(train_file)
# print(file.head())
device = "cuda" if torch.cuda.is_available() else "cpu" #设置设备
print(device)
config = { #设置参数
"lr": 0.001, #学习率
"epochs": 20, #训练轮数
"momentum": 0.9, #动量
"save_path": "model_save/best_model.pth", #最佳模型保存路径
"rel_path": "pred.csv"
}
model = MyModel(inDim=feature_dim).to(device)
loss = mseLoss_with_reg
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])
train_val(model, train_loader, val_loader, device, config["epochs"], optimizer, loss, config["save_path"]) #训练函数
evaluate(config["save_path"], test_loader, device, config["rel_path"])

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









