






【摘要】
原生的K8S集群系统架构优化——可观测性优化,针对集群无法监控和度量问题,进行梳理优化。
【案例正文】
【背景】
 https://blog.youkuaiyun.com/weixin_53439529/article/details/132565188
https://blog.youkuaiyun.com/weixin_53439529/article/details/132565188【问题】
【过程与结果】
【初步解决思路】
1.kuboard是K8S的一个图形化界面,K8S中对象的全生命周期管理都可用界面操作,相对降低了使用难度,之前同事就是这么部署的,但是部署完成之后还是提示metrics-server未安装,可能是kuboard有问题,删掉metrics-server重装。
实际上用yaml更快更准确(个人感受),换成用yaml部署。
2.安装后kubectl get pods 发现metrics-server -n kube-system已经在运行了,但是不能用,可能是镜像有问题,换一个确定正常的镜像。
3.metrics-server已经在运行,进入容器分析日志。
4.网络通信原因
【成因分析】
其实这个问题产生的原因和解决方案非常简单,但是整个排查过程走了很多弯路,也受到了很多误导,所以想从最底层的原理一次性把metrics-server搞明白,也把走过的弯路和错误思路总结一下。
【原理】
K8S分层架构如下:
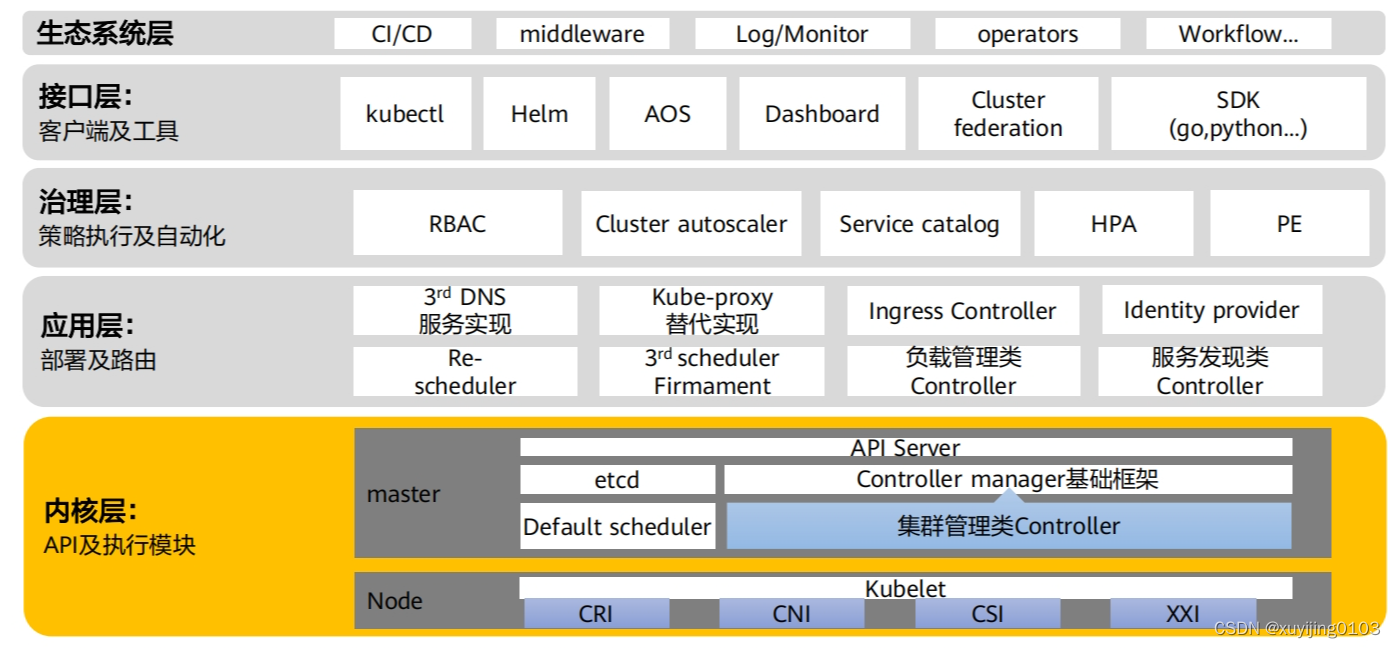
可以看到K8S本来的架构里是没有度量metrics的,这个探针相当于是一个安装进去的软件,部署在kube-system命名空间下的一个无状态负载。
目前各家云厂商封装好的云容器平台都能提供metrics-server,甚至在此基础上也做了自己的监控软件,比如华为云CCE是把metrics-server作为插件一键安装的,同时也提供了自研的cce-hpa-controller用来采集自定义指标,也有prometheus+grafana这种监控形式,AOM干脆就把这些监控运维等能力集成为一个运维平台了。从使用体验看的确是云厂商的这种封装好的产品更方便,不易出错,自己装容易踩坑,我们这个环境就是踩了很多坑。
回到正题,安装metrics-server后,它的运行流程也符合下图:
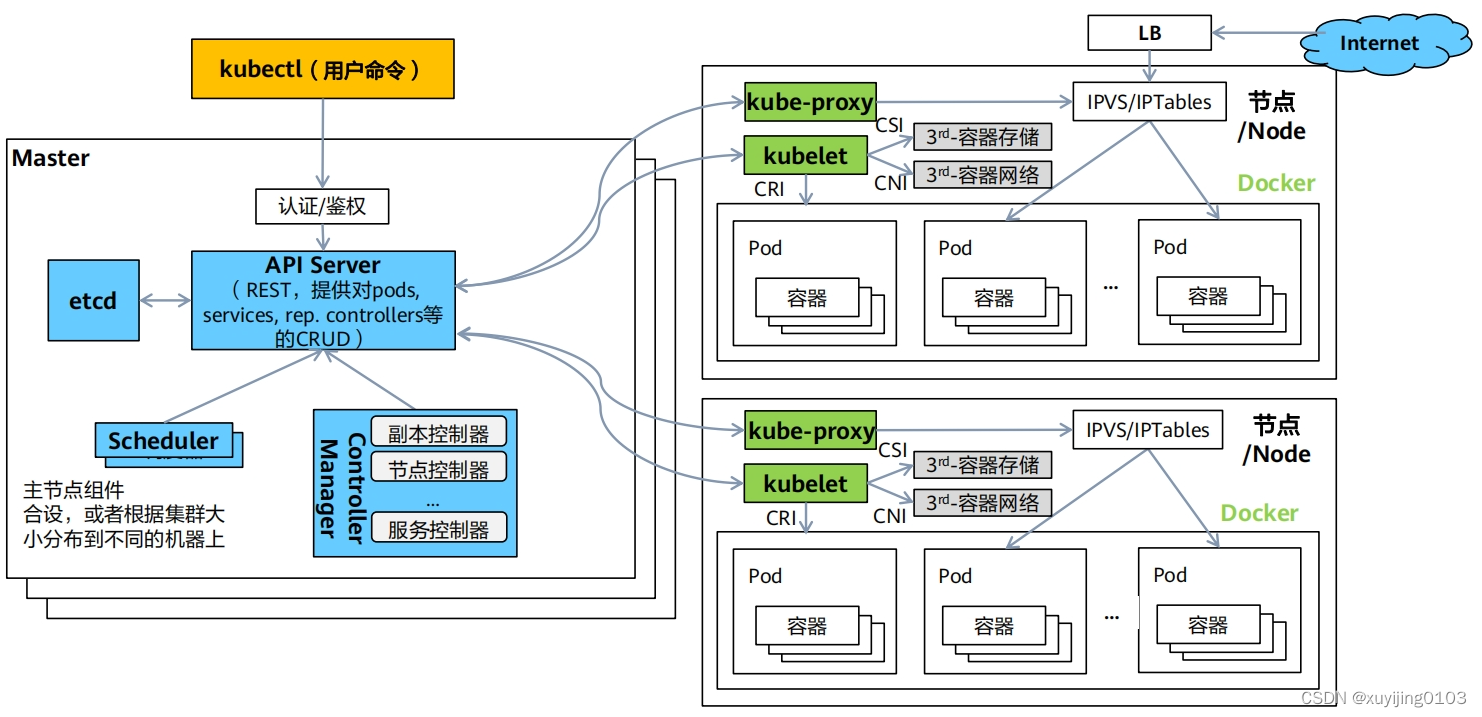
个人理解它的网络通信机制是这样:metrics-server作为一个应用被安装进去,在master上通过API Server为控制平台提供一个前端,metrics-server负载通过clusterIP类型的service做集群内服务发现。在node上又通过kube-proxy与容器进行网络通信,kube-proxy可以使用IPVS/IPTables两种域名解析协议,把服务的域名解析为容器的ip给其他容器使用。一般高版本K8S使用IPVS,自带一个负载均衡的机制。这样就形成了一个API Serverkube-proxy
IPVS/IPTables
容器的一个通信链路,这也是K8S中负载基本的通信链路。
那么metrics-server凭什么获取到node/pod/pvc等各个对象的CPU使用率/内存使用率等各项指标呢?这需要metrics-server非常高的权限,所以在安装之初就需要给metrics-server授权。K8S提供了两种用户:普通用户和Service Account。Service Account 是通过 Kubernetes API 管理的用户,Service Account 都绑定了一组 Secret,Secret 可以被挂载到 Pod 中,以便 Pod 中的进程可以获得调用 Kubernetes API 的权限,创建后kubectl describe serviceaccount metrics-server -n kube-system可以发现serviceaccount有很多个token。用户创建完成需要授权,对应集群角色ClusterRole和角色绑定RoleBinding以及集群角色绑定 ClusterRoleBinding。这些都是在创建metrics-server应用时指定,可以用一个yaml解决。
按照开始的思路排查错误原因:
1.进入metrics-server容器分析日志
本以为这是最快的能确定问题原因的方式,但是kubectl logs metrics-server -n kube-system打出来的日志没啥问题,换句话说metrics-server运行都很正常,没有报错。
2.删掉了原来kuboard安装的metrics-server重装,换成其他镜像。
重新安装用的是metrics-server:v0.6.2版本的镜像,为了排除镜像的影响,从华为云SWR镜像中心下载了该版本镜像。在华为云CCE中已经安装过这个版本的metrics-server插件,确定能够正常使用,并且安装后下载了yaml文件对比kuboard上的yaml文件,没有什么差异。然而用该yaml重新部署了metrics之后发现还是老样子。
3.根据kuboard上的提示排查。
到这一步有点找不到思路了,kuboard上面又一直显示metrics-server未安装,下面跟了一个链接Metrics server 常见问题 | Kuboard,所以抱着试一试的心态根据提示排错。没想到就跳进了一个坑,太坑了我去......顶多三个小时解决的问题耗了三天都没解决。在此提醒大家,不要轻信这种常见问题之类的答案,他们在写的时候匹配的都是特别常见的情况,原因也都非常基础。我们在网上搜的时候一般都是排查了常见原因之后,所以很多时候跟我们实际遇到的问题对不上,即便是同样的报错也不一定是同一种原因。
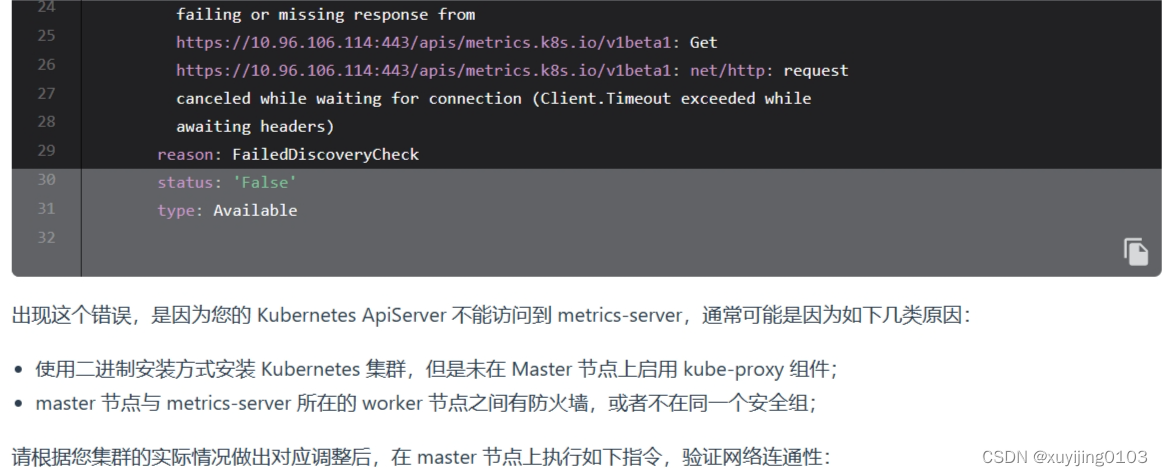
如上图,metrics-server安装后status和reason与图中一模一样,但是这个原因非常局限,而且就是跟着这个排错思路走才掉进坑的。首先检查网络:已确认master与node之间网络互通,且关闭了防火墙;根据提示 curl -ik https://10.96.106.114:443/apis/metrics.k8s.io/v1beta1测试网络连通性,发现不通,于是怀疑是kube-proxy通信问题,开始了漫长的kube-proxy排查过程。
在开头的原理中解释过kube-proxy通信链路,节点上检查metrics-server是否正确运行并有数据返回:
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes报错[root@node1 /]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes Error from server (ServiceUnavailable): the server is currently unable to handle the request 很明显无法连接到metrics-server服务。
本打算进入容器curl测试,结果发现metrics-server容器中没有安装curl命令,而且wget/nslookup啥的都没有。
[root@node1 /]# kubectl exec -it metrics-server-5d5897ddc6-7hcjq -n kube-system -- curl -k https://apiserver.cluster.local:6443 OCI runtime exec failed: exec failed: container_linux.go:345: starting container process caused "exec: \"curl\": executable file not found in $PATH": unknown
没办法,容器外测试:
curl --insecure https://apiserver.cluster.local:6443返回403错误:
[root@node1 /]# curl --insecure https://apiserver.cluster.local:6443 { "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403
其实到这里应该能找到成因的,就是403错误,也就是权限问题,但是判断报错失误又走入了一个误区,以为kube-proxy组件没有权限。
pods "metrics-server-ffcc5dcd-" is forbidden: error looking up service account kube-system/metrics-server: serviceaccount "metrics-server" not found
分析kube-proxy组件的日志,发现一直在跑错误:
E0731 03:32:38.846960 1 graceful_termination.go:88] Try delete rs "10.110.178.214:443/TCP/10.210.56.14:443" err: Failed to delete rs "10.110.178.214:443/TCP/10.210.56.14:443", can't find the real server I0731 03:32:38.847068 1 graceful_termination.go:92] lw: remote out of the list: 10.110.178.214:443/TCP/10.210.56.14:443
意思是删除 "10.110.178.214:443/TCP/10.210.56.14:443" 时出现了问题,因为无法找到真实的服务器,前面10.110.178.214:443是metrics-server的服务地址,怀疑后面的地址是由kube-proxy解析出来的容器地址,但是解析这个真实的地址失败了。
同时kube-proxy的消息有一个异常,MountVolume.SetUp failed for volume "kube-proxy" : stat /var/lib/kubelet/pods/e2e636c8-28a2-40b9-bff9-a78af8c7507f/volumes/kubernetes.io~configmap/kube-proxy: no such file or directory
意思是指定的文件或目录不存在,而这个配置是通过ConfigMap挂载的,里面放的是kube-proxy的配置文件kubeconfig.conf。
用configmap挂载配置文件挺常见的,而且是一种非常好的习惯。这样可以把负载的功能和配置解耦。比如kube-proxy需要用到某个配置文件,直接放到容器里面可能会产生容器删除配置丢失的情况,而把配置文件用configmap托管给k8s,在负载的yaml中设置好挂载路径,在每一个副本重启时都可以自动把配置挂上。
进入Kube-proxy容器发现挂载路径下真的没有kubeconfig.conf,于是重新创建了configmap定义kubeconfig.conf,yaml参考:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
data:
kubeconfig.conf: |
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://apiserver.cluster.local:6443
name: default
contexts:
- context:
cluster: default
namespace: default
user: default
name: default
current-context: default
users:
- name: default
user:
tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token然后kubectl apply -f your-configmap.yaml 创建,结果还是不行。
到这里已经过去三天了,在过程中也求助过其他同事,不幸的是同事也踩进了这个坑,我俩每天同步分析kube-proxy的结果,然而没有任何用......
【解决方案】按官方文档重装metrics-server
因为卡点实在太久了,而且也求助不到合适的人,所以求助了我们比较熟悉的云厂商——华为。我们其他项目也用了华为云CCE,跟他们联系还比较方便;而且测试了很多遍安装metrics-server都没问题,对比了很多次也都没发现什么不同,想着大厂能封装那对原生的也许很懂(实话说真没想到他们会帮忙看,毕竟这用的是原生的K8S不是他们的产品)。
HW的效率还是很高的,立马就拉会讨论,应该是产品部的一位研发大佬,按之前的思路查了一遍确实没找到原因,但是大佬提出要不用github上k8s v1.19.0匹配的yaml文档部署试试,也许是之前的yaml少了或者多了什么东西。
事实证明确实是少了一点配置,是一个clusterrole:metrics-server:system:auth-delegator。yaml参考:
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: '10.210.56.201/library/metrics-server:v0.6.2'
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
但这个yaml部署完了之后启动报错,是因为kuboard配置启动参数只能显示5个,--kubelet-insecure-tls这个参数要重新配置一遍,然后就启动成功啦,可以正常监控系统指标了。
【总结】
总结一下这个可观测性的优化过程:总的来说有些过程过于耗时,可以省略提高效率的,尤其是卡点之后一定要及时提出和求助(主要是一直找不到该求助谁);然后思路跑偏的话真的很麻烦,能避免就避免吧。
给大家安利一下华为云的实验室,整个优化过程一直是用的免费实验点,而且开一个实验室没必要非得按实验手册来,可以在一定范围内玩自己想玩的,只是有可能会因为不符合实验要求被清掉,这个可以自己摸索。比如开一个CCE有关的实验室,在里面做CCE相关的实验,这个是不会被清除的,而且实验时间可以延长,每次延长2小时,愿意的话可以玩一天。我们是贫穷的打工人,要尽量白嫖大厂资源......要知道高级云服务可是蛮贵的。
冲着这免费的实验室和服务(业界好像对此吐槽很多,但是仅从自身体验来说HW在大厂里算够意思的),我还能再吹HW好几年,希望华为能继续提高格局,给我更多白嫖的机会。
吐槽一下kuboard这个鬼东西(仅指我们用的这个版本)
1.部署metrics-server参考的是kuboard给出的yaml,这个yaml中缺少clusterrole,但是其实我后来手动在kuboard中配置了所有的clusterrole,理论上也是可以的,不知道为啥没有生效。怀疑是我们的K8S版本和kuboard版本不匹配,但是安装的时候明明找的是适配版本。
2.kuboard上面部署应用参数默认只能5个,不管yaml里写了多少只显示5个,其他的就得手动加进去,很麻烦......
3.kuboard给的常见问题排错真的太辣鸡,除了挖坑还有什么......


















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









