







提示:以下是本篇文章正文内容,下面案例可供参考
一、浅谈赫夫曼编码
赫夫曼编码(Huffman Coding),又称霍夫曼编码(哈夫曼编码),是一种编码方式,赫夫曼编码是可变字长编码(VLC)的一种。
赫夫曼编码满足前缀编码,即某个字符的编码都不能是其他字符编码的前缀编码,因此不会造成匹配的多义性。
二、获取赫夫曼编码
赫夫曼编码一般用于通信领域中当作信息的一种处理方式 ,处理的规则如下
我们将不同的字符当成不同的节点,每个字符出现的次数作为该节点的权值,将所有节点构造成一个赫夫曼树 我的上一篇博客有提到赫夫曼树的创建(还请各位大佬斧正)link
形成赫夫曼树后,我们将二叉树的左路指定为0,右路指定为1,沿赫夫曼树根节点到每个节点的路径保存相应的编码。
下面我们以字符串“hungryandhumble”为例
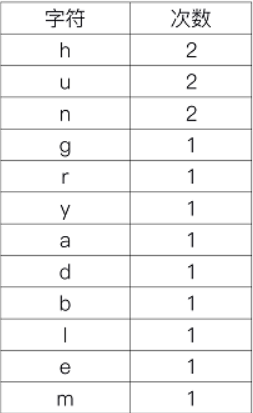
1.获取字符出现的次数
通过分析 各个字符出现的次数统计如下表1
表1 各个字符出现的次数
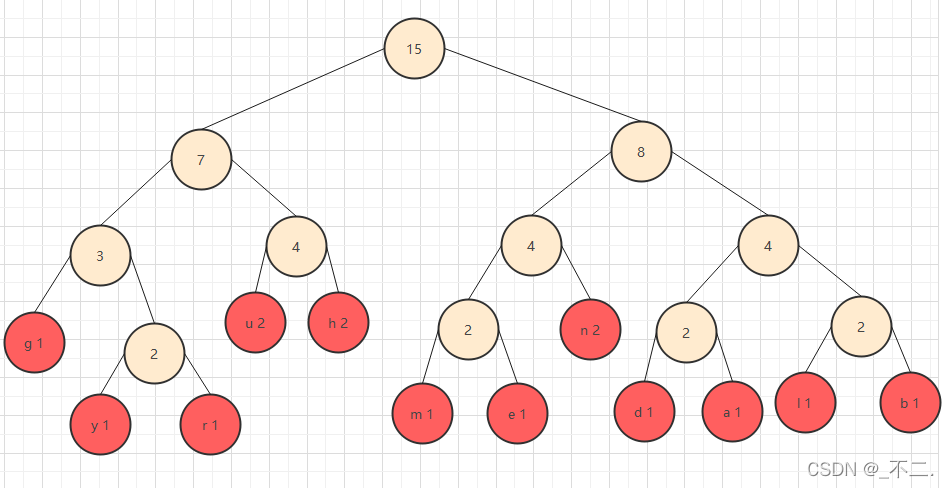
2.创建赫夫曼树
注意: 赫夫曼树根据排列的方法不同,也可能不太一样,这样对应的赫夫曼编码也不完全一样,但是赫夫曼树的带权路径长度WPL都是一样的,均为最小值。
例如 在上面的例子中,有多个字符出现的次数一样,当我们在森林中取出两棵树形成新树的过程中,由于有多个字符权值相同, 比如我们既可能取出字符r和字符y,也有可能取出字符a和字符b。同时,我们每次在森林中取出的两棵树摆放的位置也会影响赫夫曼树的生成,比如我们既可以将取出的字符r放在左边,将字符y放在右边,也可以反过来。
赫夫曼树(哈夫曼树)的创建(java实现)
视频演示赫夫曼树的生成过程
按照上述规则,创建的赫夫曼树如下
3.指定编码
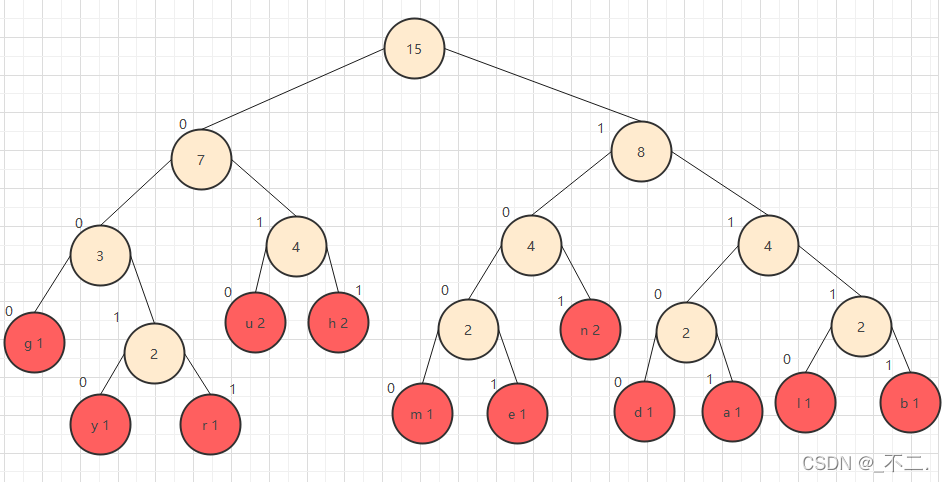
我们将二叉树的左路指定为0,右路指定为1
效果图如下
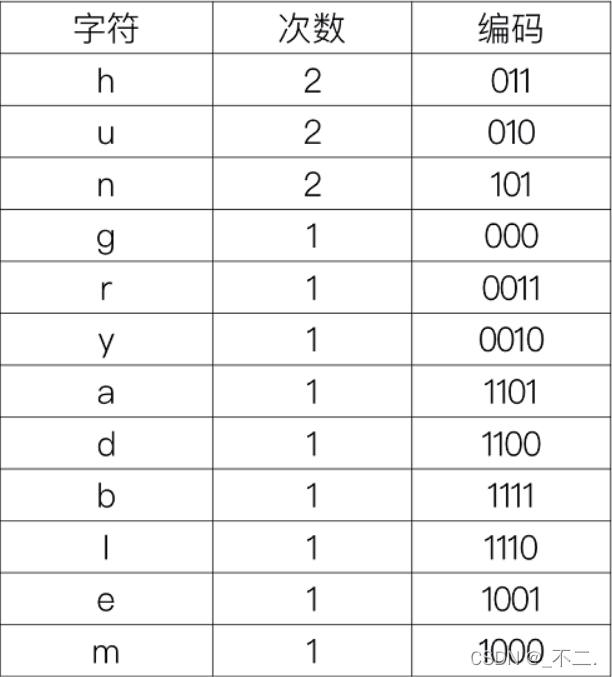
沿赫夫曼树根节点到每个节点的路径保存相应的编码。
效果图如下
三、代码实现
1.指定编码代码
//获取赫夫曼编码 向左边路径为0 右边为1
//思路
//1.每个节点的赫夫曼编码保存到huffmanCodes中
//2.生成赫夫曼编码的时候用到StringBuilder拼接路径
static Map<Byte, String> huffmanCodes = new HashMap<>();
static StringBuilder stringBuilder = new StringBuilder();
/**
* @param node 节点
* @param code 代码编码的值 0 / 1
* @param stringBuilder 用于拼接编码
*/
public static void getCodes(Node02 node, String code, StringBuilder stringBuilder) {
StringBuilder temp = new StringBuilder(stringBuilder); //保存上次拼接的值
temp.append(code); //拼接
if (node != null) {
if (node.getData() == null) {
//node为非叶子节点
getCodes(node.getLeft(), "0", temp); //向左递归遍历
getCodes(node.getRight(), "1", temp); //向右递归遍历
} else {
//说明bide是叶子节点
huffmanCodes.put(node.getData(), temp.toString()); //将相应的赫夫 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









