






纳什均衡:任何玩家都不能通过独自改变策略而获益的策略组合,即所有玩家均处于最佳应对的策略组合。
混合策略纳什均衡:一个混合策略组合,任何玩家都不能通过独自改变混合策略而使自身期望收益提高。
协同问题
多个均衡,如何选取?
修改基本假设:通讯机制,社会规则,…
特殊的博弈:合作与竞争
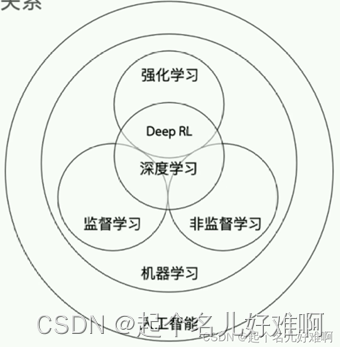
强化学习:通过从交互中学习来实现目标的计算方法。
交互过程:在每一步t,智能体:获得观察O_t,获得奖励R_t,执行行动A_t,环境:获得行动A_t,给出观察O_{t+1},给出奖励R_{t+1}
历史(History):是观察、奖励、行动的序列,即一直到时间t为止的所有可观测变量。
状态(State):是一种用于确定接下来会发生的事情(A,R,O),状态是关于历史的函数。状态通常是整个环境的, 观察可以理解为是状态的一部分,仅仅是agent可以观察到的那一部分。例:Q学习,DQN(深度q学习,用神经网络拟合Q函数)
策略(Policy):是学习智能体在特定时间的行为方式。是从状态到行为的映射。πθ=(s,a)策略函数,策略梯度更新Actor-Critic
确定性策略:函数表示,随机策略:条件概率表示
奖励(Reward):立即感知到什么是好的,一般情况下就是一个标量
价值函数(Value function):长期而言什么是好的。 价值函数是对于未来累计奖励的预测,用于评估给定策略下,状态的好坏
环境的模型(Model):用于模拟环境的行为,预测下一个状态,预测下一个立即奖励(reward)
智能体
智能体指任何能通过传感器感知环境和通过执行器作用于环境的实体。
性能度量:移动速度、反应速度、命令执行速度
环境:周围的人、路感、台阶和障碍
执行器:各个关节的电机
传感器:图像摄像头、红外传感器、陀螺仪
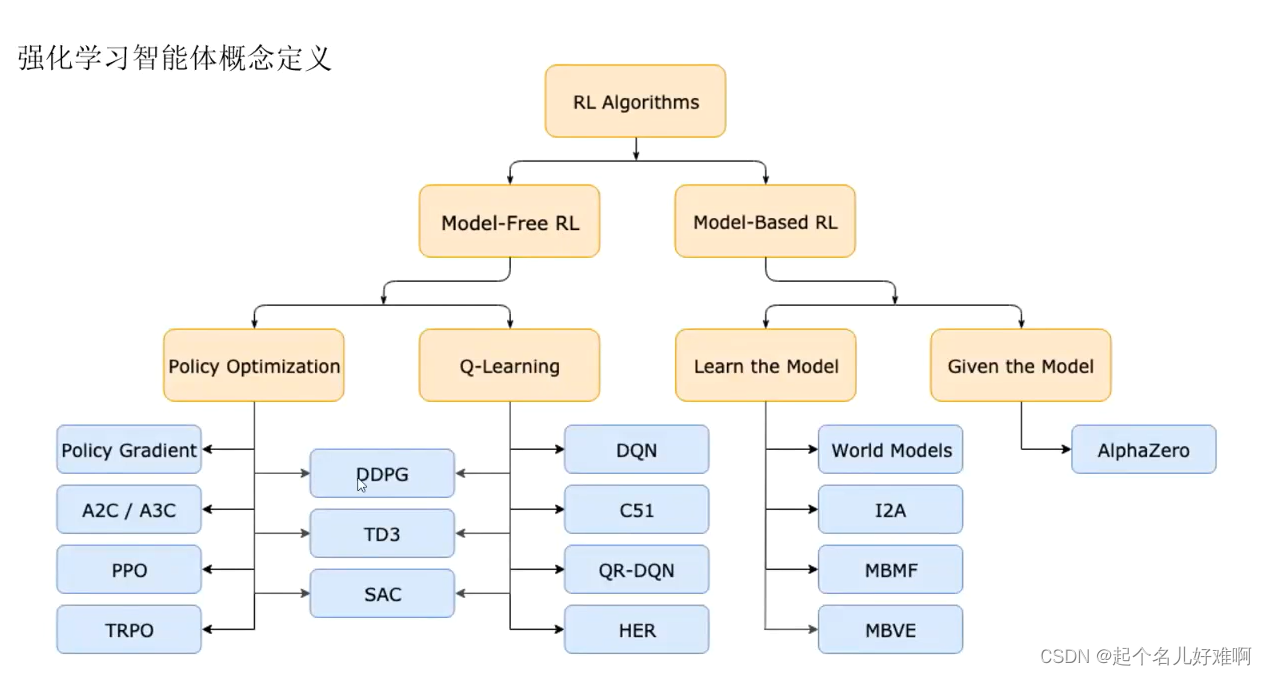
强化学习智能体的分类
model-based RL:模型可以被环境所知道,agent可以直接利用模型执行下一步的动作,而无需与实际环境进行交互学习。比如:围棋、迷宫
model_free RL:真正意义上的强化学习,环境是黑箱。 比如Atari游戏,需要大量的采样
基于价值:没有策略(隐含)、价值函数
基于策略:策略、没有价值函数
Actor-Critic:策略、价值函数
学习目标
stackelberg均衡学习 协同 合作
Depp Learning三个步骤:
1.定义函数(神经网络,actor)
2.决定funtion好坏
定义loss,找到一个参数使loss最小
用同一个action成千上百次,Rθ的期望最高的最好
3.选一个最好的funtion
梯度上升

基于价值value-based和基于策略policy-based

On-policy vs Off-policy
On-policy策略:使用策略π学习,使用策略π与环境交互产生经验(由于需要兼顾探索,策略π并不稳定)
Off-policy策略(两个策略): 目标策略:π 行为策略:μ
使用 Off-policy的好处:目标策略π用于学习最优策略,行为策略μ更具有探索性,与环境交互产生经验轨迹。
表格方法的缺点:表格可能占用极大内存;当表格极大时,查表效率低下。
使用值函数近似的优点:仅需存储有限的参数;状态泛化,相似的状态可以输出一样。
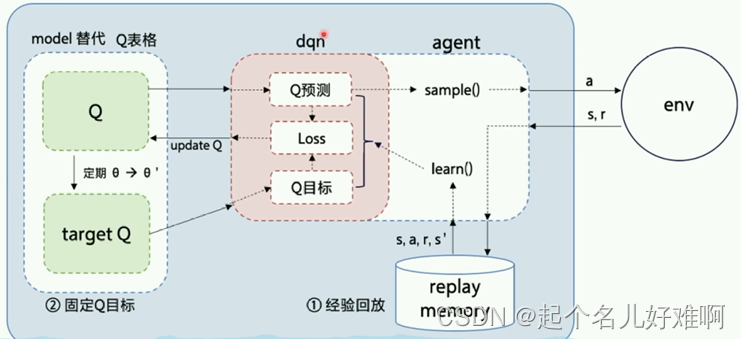
DQN引入非线性函数近似Q表格
DQN的两大创新点
1、经验回放 解决样本的关联性和利用效率的问题
2、固定Q目标 解决算法训练不稳定的问题
策略探索的一些原则
朴素方法:添加策略噪声 ε-greedy
积极初始化
基于不确定性地度量:尝试具有不确定收益的策略,可能带来更高的收益。
概率匹配:基于概率选择最佳策略
状态搜索:搜索后续状态可能带来更高收益的策略。

















 4845
4845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









