







文章目录
一、Docker基本架构
docker架构采用标准的c/s架构,服务端用于管理数据,客户端用于用户交互,服务端和客户端可以在同一台机器上面运行,也可以在不同的机器上运行。
1.1 服务端
一般运行于后台,接受客户端的请求,只允许本地的root和docker用户组成员访问,可以通过-H来修改参数监听方式。同时支持HTTPS的方式来验证。
1.2 客户端
用户不可以和服务器直连,需要通过Docker客户端执行命令,与Docker服务器进行交互。与docker服务端不同的是,等待服务器放回的消息,收到消息后会马上结束。再执行的时候,需要再次调用客户端程序。同时可以执行命令指定服务器地址。
可以通过
docker version
去查看链接情况
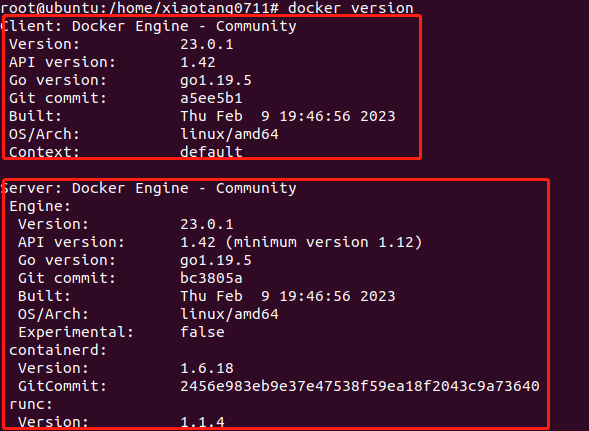
如果没有则需要指定其到正确通信位置,实例代码如下
docker -H tcp://127.0.0.1:1234 version
二、Namespace
Namespace其实就相当于修改了看待计算机的视图,对于用户看到的线程进行了限制,比如说,我在外面运行了一个进程号为100的centos,但是在centos的内部,其进程号是重新开始计算的

我们通过一个小例子来操作一下
docker run -it centos /bin/bash
ps
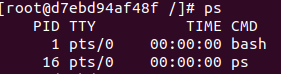
在镜像容器内部,我们的进程从1重新开始
ctrl+q+p(退出但不终止容器)
docker ps
ps aux | grep d7ebd94af48f
ps a 显示现行终端机下的所有程序,包括其他用户的程序
ps u 以用户为主的格式来显示程序状况
ps x 显示所有程序,不以终端机来区分

找到刚刚这个镜像的id后,再去去打印其所有进程,很清楚的可以看到,centos的进程号为2799,但是其内部的进程号为1
2.1 Namespace的类别
Linux使用了6种namespace,分别对应6种资源: Mount、 UTS、IPC、PID、Network和User。
1.Mount namespace
其可以将文件系统的目录和另外一个目录关联起来,让容器看上去拥有了一整个文件系统,我们操作只会在当前容器生效不会影响其他容器。
2.UTS namespace
简单的来说可以让容器拥有自己的名字
docker run -h xiaotang -it centos

3.IPC namespace
让容器有共享的内存和信号量,使其在同一Namespace下可以互相通信
4.PID namespace
主要用来隔离我们的进程ID,使其可以重复且相互之间不受影响,也就是我们之前上面的例子啦,如果比喻成父子关系的话也就是,所有的父亲可以看到自己的子进程,子看不到父,楚门的世界啊哈哈哈哈。
5.Network namespace
让我们的容器拥有独立的网卡、ip和路由
6.Usernamespace
主要用来隔离和User权限相关的Linux资源,包括User ID和Group ID,用来管理用户和划分权限。
2.2 Namespace的劣势
1.隔离不彻底
多个容器使用的依旧是宿主机的内核,在windows宿主机上用低版本的Linux运行较高版本的Linux,行不通
2.部分资源不可以被Namespace化
时间,宿主机和容器时间保持一致
3.安全问题
因为共享内核,容器中应用暴露,攻击面大。可以通过一些技术来调整,但通常情况下不知道应该禁用哪些系统调用。
三、Cgroups
虽然我们使用namespace所限制,但是在外部看来,容器里面的进程会是一个整体,和宿主机上其他的资源依旧是竞争关系,因此依据有可能会把所有资源耗尽。Cgroups的设置,可以限制单个进程或者多个进程使用资源分配管理的机制,如上一小节中,我们设置cpu时间以及I/O读取限制,都属于其中的一种。
举个例子吧
docker run -it --cpu-shares 521 progrium/stress -c 1
然后我们
ls /sys/fs/cgroup/cpu/docker
可以看到会有一个容器进程ip的目录
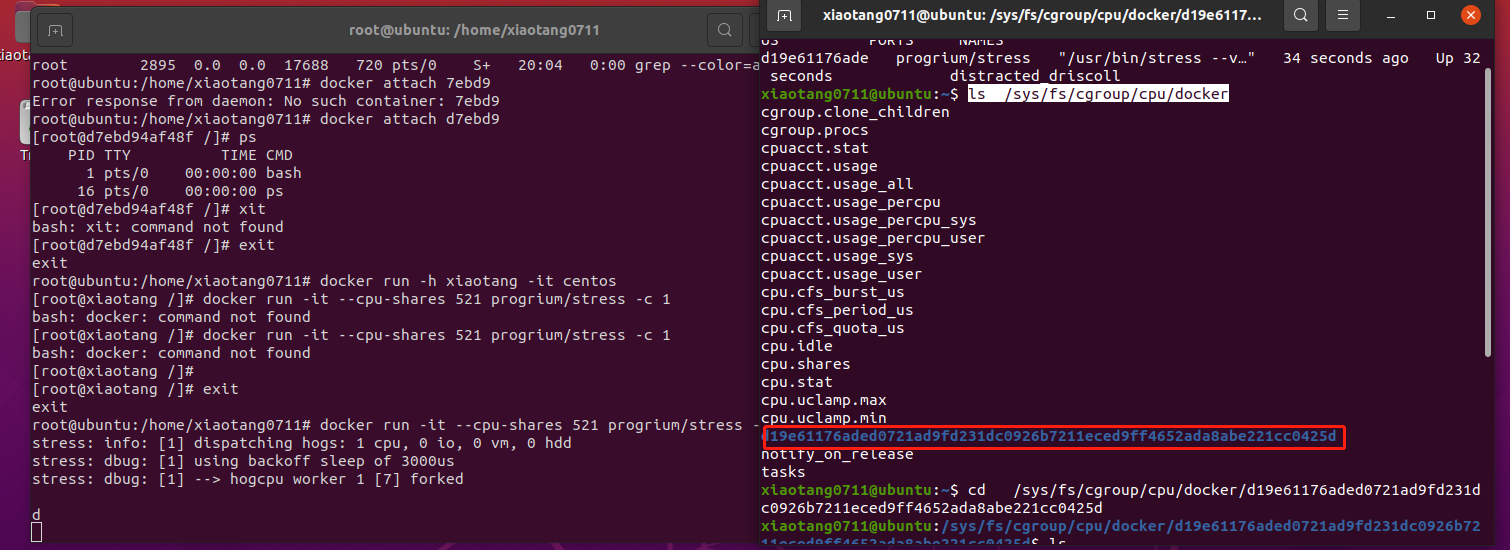
进入,然后打开里面的
cat cpu.shares
然后就可以看到我们刚刚分配的内存资源

3.1 Cgroups的限制能力
| 子系统 | 功能 |
|---|---|
| blkio | 该子系统为块设备设定输入/输出限制,如物理设备(磁盘、固态硬盘、USB 等 )。 |
| cpu | 该子系统使用调度程序提供对 CPU的 Cgroups 任务访问 |
| cpuacct | 该子系统自动生成Cgroups 中任务所使用的 CPU 报告 |
| cpuset | 该子系统为 Cgroups 中的任务分配独立CPU(在多核系统)和内存节点。 |
| devuces | 该子系统可允许或者拒绝 Cgroups 中的任务访问设备 |
| freezer | 该子系统挂起或者恢复 Cgroups 中的任务 |
| memory | 该子系统设定 Cgroups 中任务的内存限制,并自动生成由那些任务使用的内存资源报告 |
| net_cls | 该子系统使用等级识别符标记网络数据包,可允许 Linux 流量控制程序识别从具体 Cgroups中生成数据包 |
| ns | 该子系统提供了一个将进程分组到不同命名空间的方法 |
Cgroups对用户暴露出来的操作接口是文件系统,会在/sys/fs/cgroups的路径下,可以进行查看
mount -t cgroupscd
cd /sys/fs/cgroup/cpu
ls

3.2 实例验证
cd /sys/fs/cgroup/cpu
mkdir container
ls container/
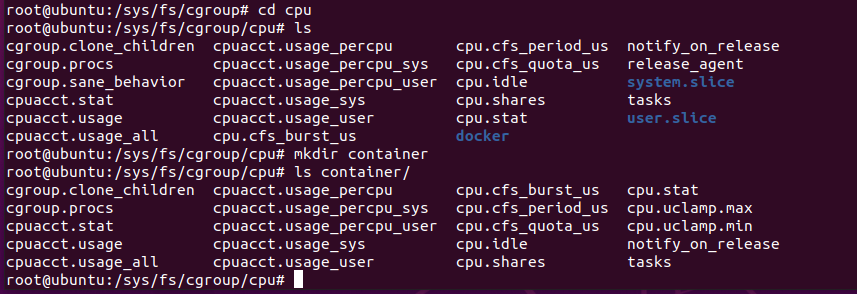
然后去跑满cpu
while :; do :; done &
top
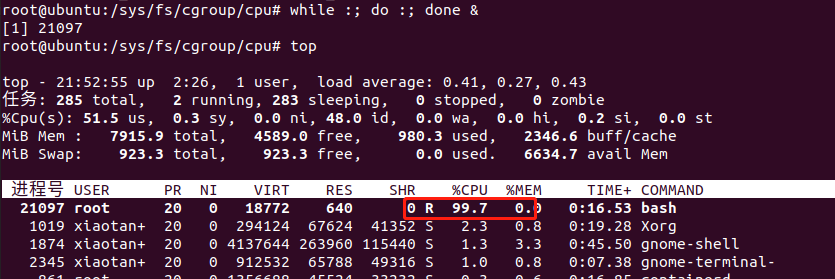
cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
现在我们打开限制,使其只能使用20%的cpu带宽,然后注意把我们刚刚top里面的进程号写入tasks
echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
echo 21097 > /sys/fs/cgroup/cpu/container/tasks
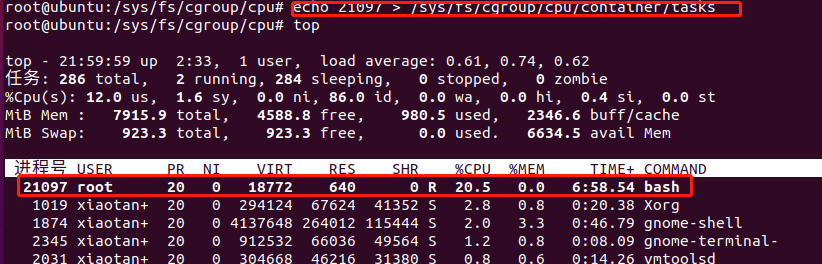
即我们可以通过为每一个容器创建控制组,加入到task文件中,来进行限制
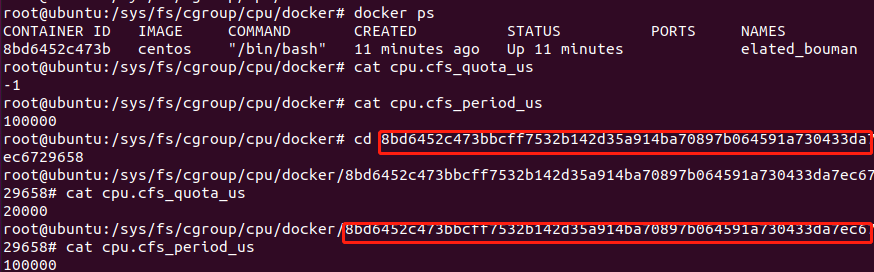
docker run -it -d --cpu-period=100000 --cpu-quota=20000 centos /bin/bash
启动后也可以在在我们的控制组里面看到对应文件啦
cd /sys/fs/cgroup/cpu/docker
ls
cd 你的进程号
cat cpu.cfs_quota_us
cat cpu.cfs_period_us
3.3 Cgroups的劣势
在proc文件中,用户可以直接访问这些文件,但是用户在容器中中,使用top查看的会是宿主机的数据
四、Docker文件系统
4.1可读可写层的工作原理
docker镜像采用的是层级结构,通过docker命令一层一层通过docker commit来形成只读层,我们容器所有的操作都是在可读可写层上进行操作,直接删除容器后,可读可写层也会随着删除,可以用docker commit,来形成只读层。
1.写时复制
cow技术相当于直接共用容器中的只读层来节约空间,我们要进行操作时只需要把要写的文件复制到自己的文件系统进行修改
2.分时复制
用时分配是先前没有分配空间,只有在写入一个新文件的时候才进行分配
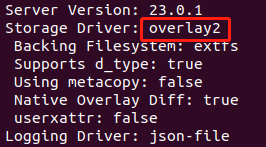
4.2docker存储驱动
Docker 提供了多种存储驱动(Storage Driver)来存储镜像,常用的几种 Storage Driver 是 AUFS、OverlayFS、Device Mapper、Btrfs、ZFS。
| Docker存储驱动 | 宿主机文件系统 |
|---|---|
| Overlay, Overlay2 | XFS(ftype=1), EXT4 |
| AUFS | XFS,EXT4 |
| Device Mapper | direct-lvm |
| Btrfs | Btrfs |
| ZFS | ZFS |
docker info
| 存储驱动 | 特点 | 优点 | 缺点 | 适用场合 |
|---|---|---|---|---|
| AUFS | 联合文件系统,未并入内核主线,文件级存储 | 作为 Docker 的第一个存储系统,有较长历史,比较文档,且在大量的生产中实践过,有较强的社区支持 | 有多层,在做写时复制操作时,如果文件比较大且存在于比较低的层,可能会慢一些 | 大并发但少IO的场景 |
| OverlayFS | 联合文件系统,并入内核主线,文件级存储 | 只有两层 | 不管修改的内容多少都会复制整个文件,对大文件进行修改显示要比小文件消耗更多的时间 | 大并发但少 IO的场景 |
| Device Mapper | 并入内核主线,块级存储 | 无论是大文件还是小文件都只复制需要修改的块,并不复制整个文件 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本,在很多容器启停的情况下可能会导致磁盘溢出 | IO 密集的场景 |



















 2392
2392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











