







农作物病虫害识别【机器学习】
一、数据集
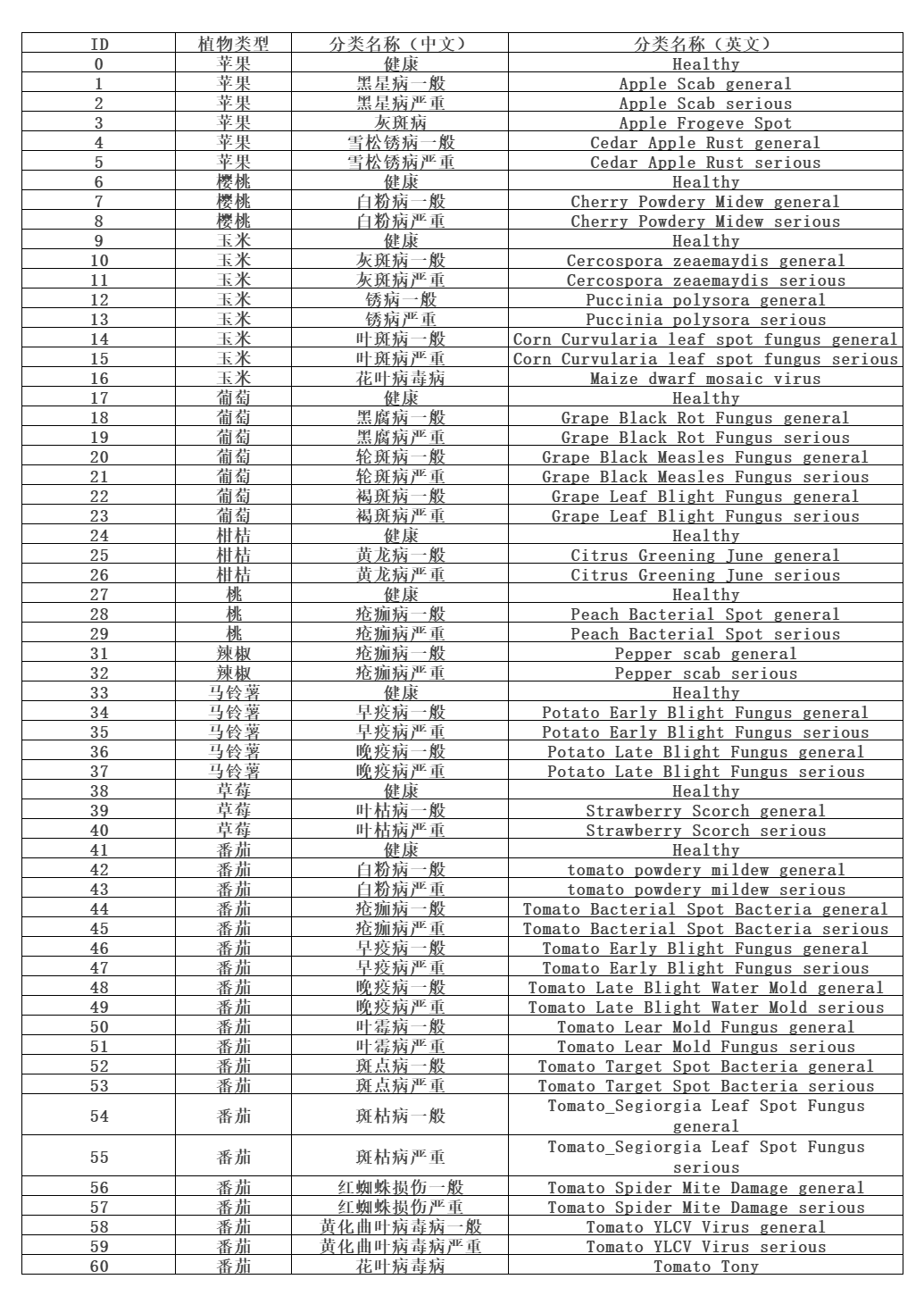
本研究基于AI Challenger农作物叶子图像数据集包含10种植物(苹果、樱桃、葡萄、柑桔、桃、草莓、番茄、辣椒、玉米、马铃薯)的27种病害(其中24个病害有分一般和严重两种程度),合计61个分类(按“物种-病害-程度”分)的特性,训练图像总数为31718张,测试图像总数为4540张。
https://aistudio.baidu.com/datasetdetail/101323
二、运行启动
下载好数据集之后,放置同一目录,只需要修改的路劲即可

本项目采用了ResNet50作为基础模型,该模型已在ImageNet数据集上进行了预训练,能够有效提取图像特征。为了适应具体的作物病害分类任务,模型的输出层被调整为61个类别,对应不同的病害类型。输入图像尺寸统一调整为224×224像素,以确保模型的一致性处理。在数据处理方面,通过数据增强技术(如随机水平翻转、旋转等)提升了模型的泛化能力,并使用标准化处理使数据分布更加稳定。训练过程中,采用Adam优化器,并结合ReduceLROnPlateau调度器和早停机制,以动态调整学习率并防止过拟合。训练过程通过TensorBoard进行实时监控,记录损失、准确率等关键指标。
train.py
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
import json
import os
from PIL import Image
import shutil
import time
from datetime import datetime
# 自定义数据集类
class AgriculturalDataset(Dataset):
def __init__(self, root_dir, json_file, transform=None):
self.root_dir = root_dir
self.transform = transform
# 读取json文件
with open(json_file, 'r') as f:
self.annotations = json.load(f)
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, 'images', self.annotations[idx]['image_id'])
image = Image.open(img_name).convert('RGB')
label = self.annotations[idx]['disease_class']
if self.transform:
image = self.transform(image)
return image, label
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # ImageNet标准化参数
])
# 在时间记录之前添加当前目录的定义
current_dir = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在目录
# 在训练循环前添加时间记录
start_time = time.time()
start_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
# 修改保存路径,使其更有组织
log_dir = os.path.join(current_dir, "logs", start_datetime)
model_dir = os.path.join(current_dir, "saved_models", start_datetime)
# 创建新的目录
os.makedirs(log_dir, exist_ok=True)
os.makedirs(model_dir, exist_ok=True)
print(f"Log directory: {log_dir}")
print(f"Model directory: {model_dir}")
# 添加GPU检查和信息打印
print("Checking CUDA availability...")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
# 检查数据路径是否存在(修改)并加载数据
base_dir = r"C:\Users\93368\Desktop\test"
train_dir = os.path.join(base_dir, "AgriculturalDisease_trainingset")
test_dir = os.path.join(base_dir, "AgriculturalDisease_validationset")
if not os.path.exists(train_dir):
raise FileNotFoundError(f"Training directory not found: {train_dir}")
if not os.path.exists(test_dir):
raise FileNotFoundError(f"Testing directory not found: {test_dir}")
# 检查json文件是否存在
train_json = os.path.join(train_dir, "AgriculturalDisease_train_annotations.json")
test_json = os.path.join(test_dir, "AgriculturalDisease_validation_annotations.json")
if not os.path.exists(train_json):
raise FileNotFoundError(f"Training annotation file not found: {train_json}")
if not os.path.exists(test_json):
raise FileNotFoundError(f"Testing annotation file not found: {test_json}")
# 创建数据集并打印数据集大小
train_dataset = AgriculturalDataset(
root_dir=train_dir,
json_file=train_json,
transform=transform
)
test_dataset = AgriculturalDataset(
root_dir=test_dir,
json_file=test_json,
transform=transform
)
print(f"Training dataset size: {len(train_dataset)}")
print(f"Testing dataset size: {len(test_dataset)}")
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0) # Windows上设置num_workers=0
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=0) # Windows上设置num_workers=0
# 更新模型创建代码
print("Creating model...")
model = torchvision.models.resnet50(weights=torchvision.models.ResNet50_Weights.IMAGENET1K_V1)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 61)
model = model.to(device)
print("Model created and moved to", device)
# 打印模型参数数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total parameters: {total_params:,}")
print(f"Trainable parameters: {trainable_params:,}")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 添加早停相关参数
early_stopping_patience = 10 # 连续10个epoch没有改善就停止
early_stopping_counter = 0
min_val_loss = float('inf')
# 训练参数
num_epochs = 100
# 初始化 tensorboard writer
try:
writer = SummaryWriter(log_dir=log_dir)
print("Successfully created SummaryWriter")
except Exception as e:
print(f"Error creating SummaryWriter: {e}")
raise
# 在训练开始前添加路径信息显示
print("\n" + "="*50)
print("训练配置信息:")
print("="*50)
print(f"当前工作目录: {os.getcwd()}")
print(f"数据目录: {base_dir}")
print("\n保存位置:")
print(f"└── 日志文件: {log_dir}")
print(f" └── TensorBoard 事件文件: events.out.tfevents.*")
print(f"└── 模型文件: {model_dir}")
print(f" ├── best_model_loss_X.XXXX_acc_X.XXXX.pth (最佳模型)")
print(f" └── final_model.pth (最终模型)")
print("\n查看训练进度:")
print(f"tensorboard --logdir={log_dir}")
print("然后在浏览器打开: http://localhost:6006")
print("="*50 + "\n")
# 训练循环
for epoch in range(num_epochs):
epoch_start_time = time.time()
print(f"\nEpoch {epoch+1}/{num_epochs}")
print('-' * 50)
# 训练阶段
model.train()
running_loss = 0.0
running_corrects = 0
all_train_preds = []
all_train_labels = []
# 添加进度显示
total_batches = len(train_loader)
for batch_idx, (inputs, labels) in enumerate(train_loader):
if batch_idx % 10 == 0:
print(f"Training batch {batch_idx}/{total_batches}", end='\r')
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 收集预测结果
all_train_preds.extend(preds.cpu().numpy())
all_train_labels.extend(labels.cpu().numpy())
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
print(f'Train Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 记录训练指标
writer.add_scalar("train/loss", epoch_loss, epoch)
writer.add_scalar("train/accuracy", epoch_acc, epoch)
writer.add_scalar("train/learning_rate", optimizer.param_groups[0]['lr'], epoch)
# 验证阶段
model.eval()
running_loss = 0.0
running_corrects = 0
all_val_preds = []
all_val_labels = []
with torch.no_grad():
for inputs, labels in test_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 收集验证集预测结果
all_val_preds.extend(preds.cpu().numpy())
all_val_labels.extend(labels.cpu().numpy())
val_loss = running_loss / len(test_dataset)
val_acc = running_corrects.double() / len(test_dataset)
print(f'Val Loss: {val_loss:.4f} Acc: {val_acc:.4f}')
# 记录验证指标
writer.add_scalar("val/loss", val_loss, epoch)
writer.add_scalar("val/accuracy", val_acc, epoch)
# 添加训练和验证的对比图
writer.add_scalars('Loss', {
'train': epoch_loss,
'val': val_loss
}, epoch)
writer.add_scalars('Accuracy', {
'train': epoch_acc,
'val': val_acc
}, epoch)
# 早停检查
if val_loss < min_val_loss:
min_val_loss = val_loss
early_stopping_counter = 0
# 保存最佳模型
model_path = os.path.join(model_dir, f'best_model_loss_{val_loss:.4f}_acc_{val_acc:.4f}.pth')
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_loss': val_loss,
'val_acc': val_acc,
'training_time': time.time() - start_time,
'timestamp': datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
}, model_path)
print(f'\n保存最佳模型:')
print(f'└── 位置: {model_path}')
print(f' ├── 验证损失: {val_loss:.4f}')
print(f' ├── 验证准确率: {val_acc:.4f}')
print(f' └── 当前轮次: {epoch+1}/{num_epochs}')
else:
early_stopping_counter += 1
print(f'EarlyStopping counter: {early_stopping_counter} out of {early_stopping_patience}')
if early_stopping_counter >= early_stopping_patience:
print('Early stopping triggered')
break
scheduler.step()
# 在每个epoch结束时显示时间
epoch_time = time.time() - epoch_start_time
total_time = time.time() - start_time
print(f'Epoch Time: {epoch_time:.2f}s | Total Time: {total_time/60:.2f}min')
# 训练结束后关闭writer
writer.close()
# 在训练结束时显示总时间
total_training_time = time.time() - start_time
print(f"\nTraining completed!")
print(f"Total training time: {total_training_time/60:.2f} minutes ({total_training_time/3600:.2f} hours)")
# 在训练结束时添加总结信息
print("\n" + "="*50)
print("训练完成总结:")
print("="*50)
print(f"开始时间: {start_datetime}")
print(f"结束时间: {datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}")
print(f"总训练时间: {total_training_time/60:.2f} 分钟 ({total_training_time/3600:.2f} 小时)")
print(f"\n最佳模型:")
print(f"└── 验证损失: {min_val_loss:.4f}")
print(f"└── 保存位置: {model_dir}")
print("\n可以通过以下方式查看训练过程:")
print(f"tensorboard --logdir={log_dir}")
print("="*50)
# 保存训练配置和结果摘要
summary_file = os.path.join(model_dir, 'training_summary.txt')
with open(summary_file, 'w') as f:
f.write("训练配置和结果摘要\n")
f.write("="*50 + "\n")
f.write(f"训练开始时间: {start_datetime}\n")
f.write(f"训练结束时间: {datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}\n")
f.write(f"总训练时间: {total_training_time/60:.2f} 分钟\n")
f.write(f"最佳验证损失: {min_val_loss:.4f}\n")
f.write(f"数据集大小:\n")
f.write(f" 训练集: {len(train_dataset)}\n")
f.write(f" 测试集: {len(test_dataset)}\n")
f.write(f"模型参数:\n")
f.write(f" 总参数量: {total_params:,}\n")
f.write(f" 可训练参数量: {trainable_params:,}\n")
f.write("="*50 + "\n")
print(f"\n训练摘要已保存到: {summary_file}")
test.py
import torch
import torchvision
from torch import nn
from torchvision.transforms import transforms
from PIL import Image
import os
# 定义完整的61个类别映射
disease_classes = {
0: "苹果-健康 (Apple-Healthy)",
1: "苹果-黑星病一般 (Apple_Scab general)",
2: "苹果-黑星病严重 (Apple_Scab serious)",
3: "苹果-灰斑病 (Apple Frogeve Spot)",
4: "苹果-雪松锈病一般 (Cedar Apple Rust general)",
5: "苹果-雪松锈病严重 (Cedar Apple Rust serious)",
6: "樱桃-健康 (Cherry-Healthy)",
7: "樱桃-白粉病一般 (Cherry_Powdery Midew general)",
8: "樱桃-白粉病严重 (Cherry_Powdery Midew serious)",
9: "玉米-健康 (Corn-Healthy)",
10: "玉米-灰斑病一般 (Cercospora zeaemaydis general)",
11: "玉米-灰斑病严重 (Cercospora zeaemaydis serious)",
12: "玉米-锈病一般 (Puccinia polysora general)",
13: "玉米-锈病严重 (Puccinia polysora serious)",
14: "玉米-叶斑病一般 (Corn Curvularia leaf spot fungus general)",
15: "玉米-叶斑病严重 (Corn Curvularia leaf spot fungus serious)",
16: "玉米-花叶病毒病 (Maize dwarf mosaic virus)",
17: "葡萄-健康 (Grape-Healthy)",
18: "葡萄-黑腐病一般 (Grape Black Rot Fungus general)",
19: "葡萄-黑腐病严重 (Grape Black Rot Fungus serious)",
20: "葡萄-轮斑病一般 (Grape Black Measles Fungus general)",
21: "葡萄-轮斑病严重 (Grape Black Measles Fungus serious)",
22: "葡萄-褐斑病一般 (Grape Leaf Blight Fungus general)",
23: "葡萄-褐斑病严重 (Grape Leaf Blight Fungus serious)",
24: "柑桔-健康 (Citrus-Healthy)",
25: "柑桔-黄龙病一般 (Citrus Greening June general)",
26: "柑桔-黄龙病严重 (Citrus Greening June serious)",
27: "桃-健康 (Peach-Healthy)",
28: "桃-疮痂病一般 (Peach_Bacterial Spot general)",
29: "桃-疮痂病严重 (Peach_Bacterial Spot serious)",
30: "辣椒-健康 (Pepper-Healthy)",
31: "辣椒-疮痂病一般 (Pepper scab general)",
32: "辣椒-疮痂病严重 (Pepper scab serious)",
33: "马铃薯-健康 (Potato-Healthy)",
34: "马铃薯-早疫病一般 (Potato_Early Blight Fungus general)",
35: "马铃薯-早疫病严重 (Potato_Early Blight Fungus serious)",
36: "马铃薯-晚疫病一般 (Potato_Late Blight Fungus general)",
37: "马铃薯-晚疫病严重 (Potato_Late Blight Fungus serious)",
38: "草莓-健康 (Strawberry-Healthy)",
39: "草莓-叶枯病一般 (Strawberry_Scorch general)",
40: "草莓-叶枯病严重 (Strawberry_Scorch serious)",
41: "番茄-健康 (Tomato-Healthy)",
42: "番茄-白粉病一般 (Tomato powdery mildew general)",
43: "番茄-白粉病严重 (Tomato powdery mildew serious)",
44: "番茄-疮痂病一般 (Tomato Bacterial Spot Bacteria general)",
45: "番茄-疮痂病严重 (Tomato Bacterial Spot Bacteria serious)",
46: "番茄-早疫病一般 (Tomato_Early Blight Fungus general)",
47: "番茄-早疫病严重 (Tomato_Early Blight Fungus serious)",
48: "番茄-晚疫病一般 (Tomato_Late Blight Water Mold general)",
49: "番茄-晚疫病严重 (Tomato_Late Blight Water Mold serious)",
50: "番茄-叶霉病一般 (Tomato_Leaf Mold Fungus general)",
51: "番茄-叶霉病严重 (Tomato_Leaf Mold Fungus serious)",
52: "番茄-斑点病一般 (Tomato Target Spot Bacteria general)",
53: "番茄-斑点病严重 (Tomato Target Spot Bacteria serious)",
54: "番茄-斑枯病一般 (Tomato_Septoria Leaf Spot Fungus general)",
55: "番茄-斑枯病严重 (Tomato_Septoria Leaf Spot Fungus serious)",
56: "番茄-红蜘蛛损伤一般 (Tomato Spider Mite Damage general)",
57: "番茄-红蜘蛛损伤严重 (Tomato Spider Mite Damage serious)",
58: "番茄-黄化曲叶病毒病一般 (Tomato YLCV Virus general)",
59: "番茄-黄化曲叶病毒病严重 (Tomato YLCV Virus serious)",
60: "番茄-花叶病毒病 (Tomato Tomv)"
}
def load_model(model_path, device):
"""加载训练好的模型"""
# 创建模型
model = torchvision.models.resnet50(weights=None)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 61) # 修改为61个类别
# 加载模型权重(添加 map_location 参数)
checkpoint = torch.load(model_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
return model
def predict_image(model, image_path, device):
"""预测单张图片的疾病类别"""
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 加载并处理图片
image = Image.open(image_path).convert('RGB')
image_tensor = transform(image).unsqueeze(0).to(device)
# 预测
with torch.no_grad():
outputs = model(image_tensor)
_, predicted = torch.max(outputs, 1)
# 获取预测概率
probabilities = torch.nn.functional.softmax(outputs, dim=1)
confidence = probabilities[0][predicted[0]].item()
return predicted.item(), confidence
def main():
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 加载模型
model_path = r"C:\Users\93368\Desktop\test\wheal-condition-identify-master\models\best_model_loss_0.4179_acc_0.8518.pth"
try:
print(f"Loading model from: {model_path}")
model = load_model(model_path, device).to(device) # 传入 device 参数
print("Model loaded successfully!")
except Exception as e:
print(f"Error loading model: {e}")
return
# 修改为新的测试图片目录
test_image_dir = r"C:\Users\93368\Desktop\test\images"
if not os.path.exists(test_image_dir):
print(f"Error: Test directory not found: {test_image_dir}")
return
# 获取前10张图片
image_files = [f for f in os.listdir(test_image_dir) if f.endswith(('.jpg', '.jpeg', '.png'))][:10]
print(f"\n预测目录中的前10张图片:")
print("="*50)
# 记录结果
results = []
# 预测前10张图片
for i, image_name in enumerate(image_files, 1):
image_path = os.path.join(test_image_dir, image_name)
print(f"\n图片 {i}/10: {image_name}")
try:
# 预测
predicted_class, confidence = predict_image(model, image_path, device)
# 输出结果(添加序号)
print(f"预测序号: {predicted_class}")
print(f"预测类别: {disease_classes[predicted_class]}")
print(f"置信度: {confidence*100:.2f}%")
results.append({
'image': image_name,
'class_id': predicted_class, # 添加序号
'prediction': disease_classes[predicted_class],
'confidence': confidence
})
except Exception as e:
print(f"处理图片出错 {image_name}: {e}")
continue
# 保存结果到文件
output_dir = os.path.dirname(model_path)
result_file = os.path.join(output_dir, 'prediction_results_10.txt')
print(f"\n保存结果到: {result_file}")
with open(result_file, 'w', encoding='utf-8') as f:
f.write("前10张图片预测结果\n")
f.write("="*50 + "\n")
f.write(f"模型路径: {model_path}\n")
f.write(f"测试图片目录: {test_image_dir}\n\n")
for result in results:
f.write(f"图片: {result['image']}\n")
f.write(f"预测序号: {result['class_id']}\n") # 添加序号
f.write(f"预测类别: {result['prediction']}\n")
f.write(f"置信度: {result['confidence']*100:.2f}%\n")
f.write("-"*30 + "\n")
print("\n预测完成!")
print(f"结果已保存到: {result_file}")
if __name__ == "__main__":
main()
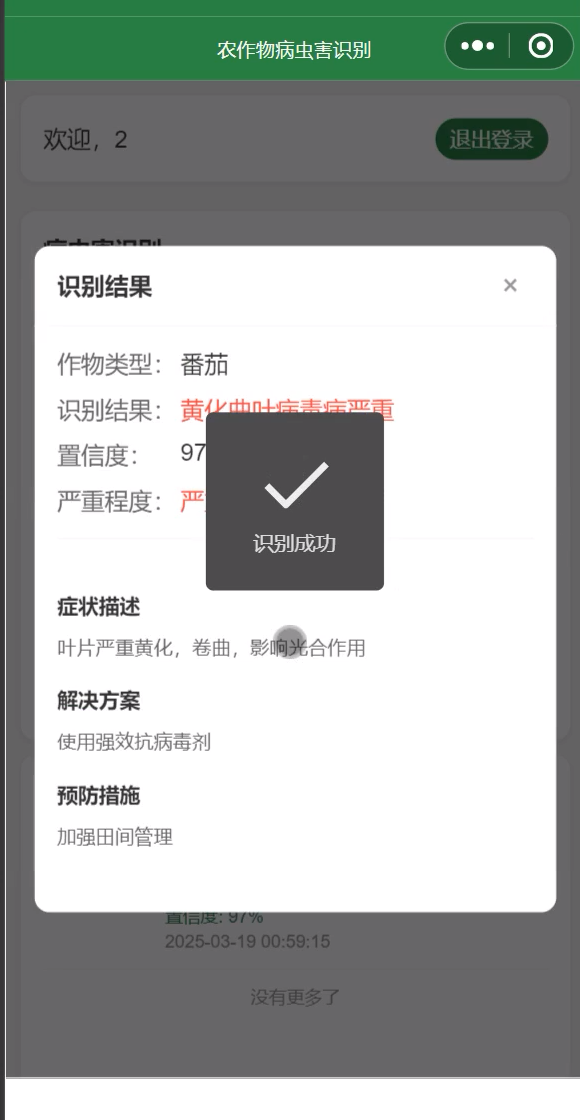
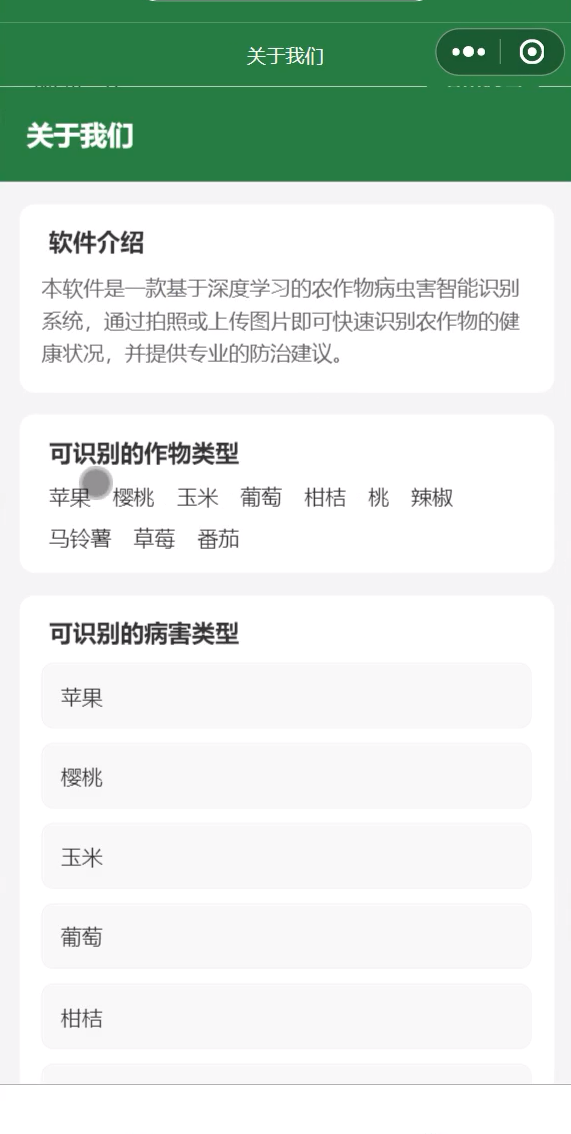
三、可视化





















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











