







 本文详细介绍了MySQL中的查询操作,包括单表查询的排序、聚合函数、分组、LIMIT分页,以及约束的使用,如主键、非空、唯一和默认值约束。深入探讨了多表查询,包括外键约束、级联删除操作,以及内连接、外连接查询。此外,还讲解了合并查询(UNION和UNION ALL)和子查询的多种类型。最后,提到了MySQL中的日期时间函数和系统信息函数的应用,以及SQL执行顺序的重要性。
本文详细介绍了MySQL中的查询操作,包括单表查询的排序、聚合函数、分组、LIMIT分页,以及约束的使用,如主键、非空、唯一和默认值约束。深入探讨了多表查询,包括外键约束、级联删除操作,以及内连接、外连接查询。此外,还讲解了合并查询(UNION和UNION ALL)和子查询的多种类型。最后,提到了MySQL中的日期时间函数和系统信息函数的应用,以及SQL执行顺序的重要性。
第一节单表查询
1.1排序
1)单列排序
语法结构:
SELECET 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC/DESC]
- ASC表示升序排列(默认)
- DESC表示降序排序
- 不影响真实数据
代码示例:
select * from emp e where salary>6000 ORDER BY e.salary DESC;
select * from emp order by salary;
2)多列排序
- 同时对多个字段进行排序,如果第一个字段相同,就按照第二个字段进行排序,依次类推
select * from emp order by salary desc, eid asc;
-- 排序完之后按照,另外一个条件进行排序
1.2聚合函数
- 函数:方法,它封装了一些逻辑,比如给他一堆数据,特定函数可以返回最大值max(),avg()平均值
- 聚合,也称为聚合统计或聚合查询,就需要使用select关键字,有select就得有from xxx
语法结构:
select 聚合函数(字段名) from 表名;
5个聚合函数:
| 聚合函数 | 作用 |
| count(字段) | 统计指定列不为NULL的记录行为 |
| sum(字段) | 计算指定列的数值和 |
| max(字段) | 计算指定列的最大值 |
| min(字段) | 计算指定列的最小值 |
| avg(字段) | 计算指定列的平均值 |
代码示例:
-- 1 查询员工的总数
select COUNT(DISTINCT eid) from emp;
select count(*) from emp;
select count(1) from emp; -- count函数会忽略掉空值
-- 2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值
select sum(salary) as '总薪水', max(salary) '最大薪水', min(salary) '最小薪水', avg(salary) '平均薪水' from emp;
-- 3 查询薪水大于4000员工的个数
select count(*) from emp where salary>4000;
-- 4 查询部门为'教学部'的所有员工的个数
select count(*) from emp where dept_name='教学部';
-- 5 查询部门为'市场部'所有员工的平均薪水
select avg(salary) as '市场部平均薪资' from emp where dept_name='市场部';
1.3分组
group by 函数
- 分组往往和聚合函数一起使用,对数据进行分组,分完组之后在各个组内进行聚合统计分析
- 比如:求各个部门的员工数
- 分组查询指的是使用GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
语法格式:
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
- HAVING 是对聚合之后的结果进行进一步的过滤
代码示例:
需求1:
SELECT sex,avg(salary) from emp GROUP BY sex;- -- 注意:
1)GROUP BY 的字段必须出现在前面SELECT的位置;
2)前面SELECT的位置,除了GROUP BY 的字段、聚合函数,不能出现其他字段;但在MySQL中其实是可以的
- 原句&原理:

需求2:
-- 0.查询所有部门的信息
select dept_name as '部门名称' from emp group by dept_name;
-- 1.查询每个部门的平均薪资
select dept_name,avg(salary) from emp GROUP BY dept_name;
-- 2.查询每个部门的平均薪资, 部门名称不能为null
select dept_name,avg(salary) from emp GROUP BY dept_name HAVING dept_name is not null;
-- where是GROUP BY之前过滤的
select dept_name, avg(salary) from emp where dept_name is not null GROUP BY dept_name;需求3:
-- 查询平均薪资大于6000的部门
select dept_name, avg(salary) from emp WHERE dept_name is not NULL GROUP BY dept_name HAVING avg(salary)>6000;where和having的区别
| 过滤方式 | 特点 |
| where | where进行分组前的过滤 where后面不能写 聚合函数 |
| having | having 是分组后的过滤 having后面可以写 聚合函数 |
1.4 limit 关键字--分页
- limit是限制的意思,用于限制返回的查询结果的行数(可以通过limit指定查询多少行数据)和python当中的head(10)有些类似
- limit语法是MySQL的方言,用来完成分页
语法结构:
select 字段1,字段2··· from 表名 limit offet, length;
参数说明:
- limit offet, length;关键字可以接受一个 或者两个为0 或者正整数的参数
- offset 起始行数,从0开始记数,如果省略 则默认为0, 也就是要查询的数据从第一条开始;
- length 返回的行数,也就是终止显示的行数
代码示例:
select * from emp limit 0,3;
/*
通常用于分页
每一页显示多少条记录往往是固定,PageSize=3(每页显示3条记录)
当前页pageNum=2
根据以上参数从MySQL中获取到第二页应该显示的那3条记录
第一页 limit 0,3
第二页 limit 3,3
第三页 limit 6,3
第n页 limit ?,3
起始行的偏移量该怎么计算?
(当前页-1)*每页条数
(n-1)*3
在程序中计算出来,然后传入到MySQL语句中,
最终拼接出类似于这样的语句:
select * from emp limit x,y;
和外部工程师结合得是比较多的
*/
第二节 约束
- 约束是针对字段的
常见的约束
| 约束名 | 约束关键字 |
| 主键 | primary key |
| 唯一 | unique |
| 非空 | not null |
| 外键 | foreign key |
2.1 主键约束
| 特点 | 不可重复 唯一 非空 |
| 作用 | 用来表示数据库中的每一条记录(唯一标识锁数据表中的一条记录) |
1)添加主键约束
语法结构:
字段名 字段类型 primary key
代码示例:
①建表添加主键方式一,直接在创建字段的时候定义
create table emp2(
eid int primary key,
ename varchar(20),
sex char(1)
);② 建表添加主键方式二,也可以在设置好字段之后加上主键
create table emp3(
eid int,
ename VARCHAR(20),
sex char(1),
primary key(eid)
);③ 给已经存在的数据表添加主键约束
alter table emp add primary key(eid);那些数据可以作为主键?
- 通常根据业务去设计主键,在实际生产过程中每张表都会设计一个主键
- 是给数据库和程序使用的,跟最终的客户无关,所以主键没有意义没有关系,只要能够保证不重复就好,比如身份证号码etc
- 另外,如果没有和业务关联太大的可以设计为主键的列的话,我们在进行数据库设计的时候往往人为加一列作为主键列,习惯上起名为id,rid等:12345
2)删除主键
alter table emp drop primary key;
desc emp;
3)主键的自增
- 主键如果让我们自己添加有可能重复,我们通常希望在每次插入新记录的时候,数据库自动生成关键字段的值
- 关键字:
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
代码示例:
-- 创建主键自增的表
create table epm2(
-- 关键字 AUTO_INCREMENT,主键类型必须是整数类型
eid int primary key auto_increment,
ename VARCHAR(20),
sex char(1)
);- 在输入的时候可以不需要输入自增的eid这一列
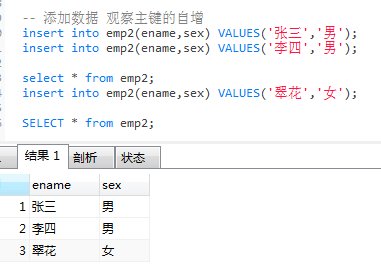
4)修改主键自增的起始值
- 设置自增的起始值,create后设置;不设置是默认从1开始
create table emp2(
eid int primary key auto_increment,
ename VARCHAR(20),
sex char(1)
)auto_increment=100;
5)DELETE和TRUNCATE对自增长的影响
| 清空数据表的方式 | 特点 |
| DELETE | 只是删除表中所有数据,对自增没有影响;就是即便删除了,自增的不会断和变 |
| TRUNCATE | truncate是将整个表删除,然后创建一个新的表;自增的主键,重新从1开始 |
6)查看最后生成的自增值
select last_insert_id;
2.2 非空约束
- 某一列不允许为空
语法格式:
字段名 字段值 not null
代码示例:
create table emp2(
eid int primary key auto_increment,
ename VARCHAR(20) not null,
sex char(1)
);
2.3 唯一约束
- 表中的某一列的值不能重复( 对null不做唯一的判断)
语法格式:
字段名 字段值 unique
代码示例:
create table emp2(
eid int primary key auto_increment,
ename VARCHAR(20) unique,
sex char(1)
);- 主键约束和唯一约束的区别:
1.主键约束 唯一且不能够为空
2.唯一约束,唯一但是可以为空
3.一个表中只能有一个主键,但是可以有多个唯一约束
2.4 默认值约束
- 默认自约束 用来指定某列的默认值
语法格式:
字段名 字段类型 DEFAULT 默认值
代码示例:
create table emp4(
eid int primary key auto_increment,
ename VARCHAR(20) not null unique default '奥利给',
sex char(1)
);
第三节 多表查询
3.1外键约束
- 主键:数据表A中有一列,这一列可以唯一的标识一条记录
- 外键:数据表A中有一列,这一列指向了另外一张数据表B的主键
- 主键和外键之间的关系:

1)创建外键约束
语法格式:
①新建表时添加外键:
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字
段名)
②已有表添加外键:
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名)
REFERENCES 主表(主键字段名);
代码示例:
-- 先创建一个主表
create table department(
id int primary key auto_increment,
dep_name varchar(50),
dep_location varchar(50)
);
-- 在创建从表的时候,直接建立外键
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT,
dept_id INT, -- 外键字段类型要和主表的主键字段类型保持一致
-- 添加外键约束
constraint emp_dep_fk foreign key(dept_id) REFERENCES department(id)
-- 这个名字是自己定义,方便后续书写代码
);
2)插入数据
-- 插入一条有问题的数据 (部门id不存在)
-- Cannot add or update a child row: a foreign key constraint fails
INSERT INTO employee (ename, age, dept_id) VALUES ('错误', 18, 3);- 添加外键约束,就会产生强制性的外键数据检查, 从而保证了数据的完整性和一致性
3)删除外键约束
- 添加/删除外键针对的都是从表
语法格式:
alter table 从表 drop foreign key 外键约束名称
4)添加外键约束
语法格式:
alter table从表 add [constraint] [外键约束名称] FOREIGN KEY (外键字段名)
REFERENCES 主表(主键字段名);
代码示例:
alter table employee add CONSTRAINT emp_dep_fk foreign key(dept_id) REFERENCES department(id);
5)外键约束的注意事项
1.有主外键关系的两个表插入数据的时候,首先插入主表,然后再插入从表
2.删除:首先应该删除从表的关联数据,然后再删除主表的关联数据(因为从表对主表有引用)
3.从表外键类型必须与主表主键类型一致, 否则创建失败
6)级联删除操作
- 如果想实现删除主表数据的同时,也删除掉从表数据,可以使用级联删除操作
- 级联删除
ON DELETE CASCADE
代码示例:
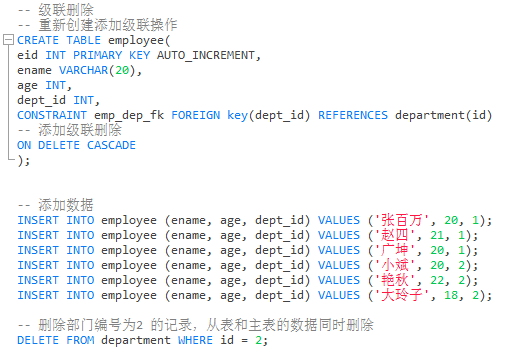
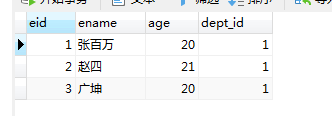
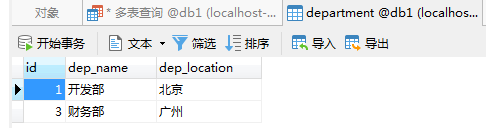
- 结果展示:
3.2 什么是多表查询
- DQL: 查询多张表(至少涉及2张表),获取到需要的数据
- 比如 我们要查询家电分类下 都有哪些商品,如分类表+商品表
3.3 数据准备
3.4 笛卡尔积

- -- 多表关联查询最早的方式(笛卡尔积)
select * from category, products;- 得出的数据会重叠无法使用
3.5 多表查询的分类
1)内连接查询
- 内连接的特点:
- 通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
- 比如通过: 从表的外键 = 主表的主键 方式去匹配
① 隐式内链接 where
- form子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接.
- 使用where条件过滤无用的数据
语法格式:
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
代码示例:
-- 笛卡尔积+WHERE条件
select * from category as c, products p where c.cid=p.category_id;
select * from category as c, products p where c.cid=p.category_id and cname='家电';
②显式内连接 join on
- 使用 inner join ...on 这种方式, 就是显式内连接
语法格式:
select 字段名 from 左表 [inner] join 右表 ON 条件;
-- inner 可以省略
代码示例:
-- 显式内连接改造 上面的笛卡尔积+where (隐式内连接)
select * from category c inner join products p on c.cid=p.category_id;
-- 查询鞋服分类下,价格大于500的商品名称和价格
select p.pname,p.price from category c inner join products p on c.cid=p.category_id where price>500 and cname='鞋服';
2)外连接查询
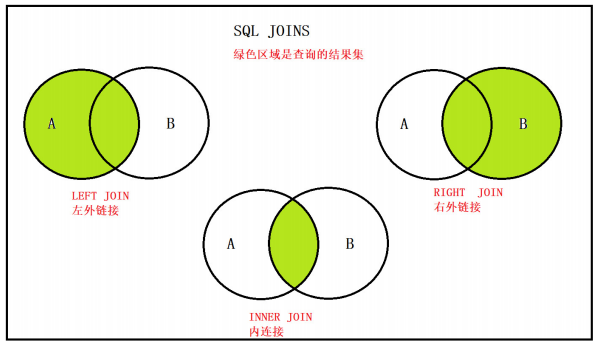
①左外连接 left join on
- 左外连接 , 使用 LEFT OUTER JOIN , OUTER 可以省略
- 左外连接的特点:
- 以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
- 如果匹配不到, 左表中的数据正常展示, 右边的展示为null.
语法格式:
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件;
代码示例:
-- 左关联连接查询
SELECT * from category c left join products p on c.cid=p.category_id;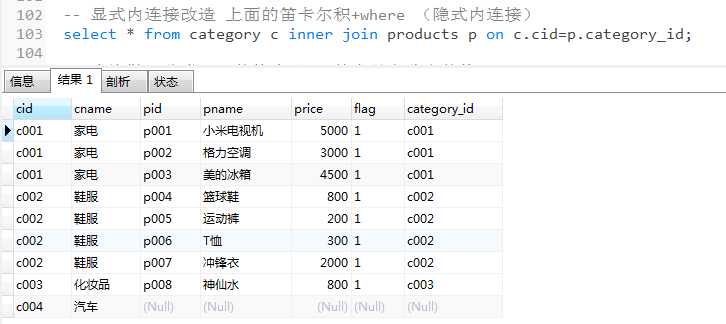
-- 左外连接, 查询每个分类下的商品个数
SELECT c.cname '分类',COUNT(p.pname) as '分类下的商品个数' from category c left join products p on c.cid=p.category_id GROUP BY c.cname; 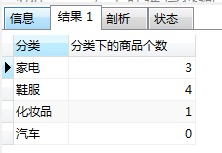
- 用于自连
代码示例:
select *
from t
left join t1 on t1=t
left join t2 on t2=t;
②右外连接 right join on
- 右外连接 , 使用 RIGHT OUTER JOIN , OUTER 可以省略
- 右外连接的特点:
- 以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
- 如果匹配不到,右表中的数据正常展示, 左边展示为null
语法格式:
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件;
- 多于两个表的查询:
表1 表2 表3 表4 表5
(表1+表2)a
(a+表3)b
(b+表4)c
······
第四节 合并查询
4.1 UNION
- UNION 操作符用于合并两个或多个 SELECT 语句的结果集,并消除重复行。
- UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
语法结构:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
代码示例:
SELECT Id,NAME,Amount,Date
FROM customers
LEFT JOIN orders
on customers.Id = orders.Customers_Id
UNION
SELECT Id,NAME,Amount,Date
from customers
RIGHT JOIN orders
on customers.Id = orders.Customers_Id;- 也就是说,把左右两张表的数据内容都合并在一起了,并且去除重复项
小结:
1. 选择的列数必须相同;
2. 所选列的数据类型必须在相同的数据类型组中(如数字或字符)
3. 列的名称不必相同
4. 在重复检查期间,NULL值不会被忽略
4.2 UNION ALL
- UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
- UNION ALL 运算符所遵从的规则与 UNION 一致。
总结:
UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而Union All不会去除重复记录。
2、UNION ALL只是简单的将两个结果合并后就返回。
3、在执行效率上,UNION ALL 要比UNION快很多,因此,若可以确认合并的两个结果集中不包含重复数据,那么就使用UNION ALL。
4.3 全连接full out join
- 一般被译作外连接、全连接,实际查询语句中可以写作 FULL OUTER JOIN 或 FULL JOIN。外连接查询能返回左右表里的所有记录,其中左右表里能关联起来的记录被连接后返回。
第五节 子查询
5.1 什么是子查询
子查询概念:
一条select 查询语句的结果, 作为另一条 select 语句的一部分
子查询的特点:
子查询必须放在小括号中
子查询的场景中还会有另外一个特点,整个sql至少会有两个select关键字
子查询常见分类:
where型 子查询: 将子查询的结果, 作为父查询的比较条件;
子查询的结果是单列单行,使用 =
from型 子查询 : 将子查询的结果, 作为 一张表,提供给父层查询使用
exists型 子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包
含子查询的结果
5.2 where型子查询——结果作为查询条件
语法格式:
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
代码示例:
-- 将最高价格作为条件,获取商品信息
SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
-- 查询小于平均价格的商品
SELECT * FROM products WHERE price < (SELECT AVG(price) FROM products);
5.3 from型子查询——结果作为一张表
语法格式:
SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
代码示例:
select * from
(
select c.cname,count(p.pname)
from category c
left join products p on c.cid = p.category_id
group by c.cname
)a;
5.4 exists型 子查询——结果是单列多行
- 子查询的结果类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
语法格式:
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
代码示例:
-- 子查询获取的是单列多行数据
SELECT * FROM category
WHERE cid IN (SELECT DISTINCT category_id FROM products WHERE price <2000);
5.5 子查询总结
1. 子查询如果查出的是一个字段(单列), 那就在where后面作为条件使用.
单列单行 where后面接 =
单列多行 where后面接 in
2. 子查询如果查询出的是多个字段(多列), 就当做一张表使用(要起别名).
第六节 小试牛刀
6.1 导入csv文件
- 步骤:
①在Navicat中创建好对应的数据库和table后,Navicat中在对应的表右击,选择“导入向导”,选择“CSV文件”下一步
②导入对应的文件,编码默认为utf8,不需要更改;在需要导入的位置键入文件所在位置,包含文件名,类似python读取文件的方式
③下一步,下一步,日期的位置可以选择YMD方式 ,下一步→表名和表名的确认,下一步→确认源字段和目标字段,下一步→导入模式,直到点击“开始”;进度条完成后,点击“关闭”结束
④如果是通过复制文件路径的方式导入,在点击“下一步”之后会出现错误提示,这时点击“上一步”,再点击“下一步”,文件则会显现
6.2 实操案例(4个)
/*
需求1: 查询线索(二级渠道jdsc)后续转化成交车型详情
大白话:看一下二级渠道jdsc,它下面的线索成交时,人家客户购买的都是什么车型
结合数据表分析
线索和渠道 ———> clue表
成交购买的车型 ——> order表
需要进行clue表和order表的关联查询(使用内连接进行关联查询)
条件:二级渠道jdsc
返回结果:线索id 线索所属渠道名称 购买的车型
*/
SELECT
c.clue_id,
ca_n,
chexing_id
FROM
clue_day c,
order_day o
WHERE
c.clue_id = o.clue_id
AND c.ca_n = 'jdsc';
SELECT
c.clue_id,
ca_n,
chexing_id
FROM
clue_day c
JOIN order_day o ON c.clue_id = o.clue_id
WHERE
c.ca_n = 'jdsc';
-- 需求2:统计所有渠道(按照二级渠道)的转化率
-- 转化率:成单数(order_day表获取)/线索数(clue_day表获取)
-- 渠道下有多个线索(clue表)
SELECT
ca_n,
count( o.city_id )/ count( c.clue_id ) sale_rate
FROM
clue_day c
LEFT JOIN order_day o ON c.clue_id = o.clue_id
GROUP BY
ca_n
ORDER BY
sale_rate DESC
LIMIT 6;
-- 需求3:查询各城市线索数并计算所有城市线索总数
-- 关键词:城市 线索
SELECT city_id,count(clue_id) FROM clue_day GROUP BY city_id
UNION ALL
SELECT '总计'as 'city_id', count(clue_id) FROM c- datediff函数是SQL中求日期相差日的函数
SELECT DATEDIFF('2020-08-08','2020-08-19') as diffdate;- ceil函数是向上取整的函数
- with as 的用法(扩展):如果一整句查询中多个子查询都需要使用同一个子查询的结果,那么建议用with,将共用的子查询用简写表示出来。
-- 需求4:找出优质渠道,做重点投入
-- 我们对于优质渠道(以二级渠道来说)的定义:
--
-- 该二级渠道内平均转化周期< 整体平均转化周期
-- 该二级渠道的线索量 > 各二级渠道平均线索量
/*
--针对《二级渠道内平均转化周期》和《二级渠道的线索量》的分析
转化周期:成单日期 — 线索创建日期
平均:avg
渠道线索量:分组 count统计
*/-- 分组聚合(count/avg)
-- with as 在一个sql中提取公共的子查询出来(相当于一个表)
WITH ca_value AS (
SELECT
ca_n,
avg(
DATEDIFF( o.created_at, c.clue_created_at )) avg_time,
count( c.clue_id ) clue_num
FROM
clue_day c
LEFT JOIN order_day o ON c.clue_id = o.clue_id
WHERE
o.created_at IS NOT NULL
AND c.clue_created_at IS NOT NULL
GROUP BY
ca_n
) SELECT
ca_n,
avg_time,
clue_num
FROM
ca_value
WHERE
clue_num >(-- 各二级渠道平均线索量
SELECT
ceil(
avg( clue_num ))
FROM
ca_value
)
AND avg_time <(-- 整体平均转化周期
SELECT
avg(
DATEDIFF( o.created_at, c.clue_created_at )) avg_time
FROM
clue_day c
LEFT JOIN order_day o ON c.clue_id = o.clue_id
WHERE
o.created_at IS NOT NULL
AND c.clue_created_at IS NOT NULL 小结:
需要把不同的需求拆分成小块,最后串联起来
第七节 扩展—MySQL函数
7.1 数学函数
| 函数 | 作用 | 代码示例 |
| ABS(x) | 返回x的绝对值
| select abs(-10) as '绝对值' select abs(price) from products |
| FLOOR(x)向下取整 CEIL(x)向上取整 | 返回不大于x的最大整数值 | select floor(5.9) as '向下取整'; select ceil(5.01) as '向上取整' |
| ROUND() | 保留小数点位数 | select round(5.419,2) as '四舍五入' -- 第二个数值是保留几位小数的意思 |
| RAND() | 返回0~1的随机数 | select rand(); |
| PI() | 返回圆周率的值 | select pi(); |
| MOD(x,y) | 返回x除以y以后的余数 | select mod(5,2); -- 求余数 |
7.2 字符串函数
| 函数 | 作用 | 示例 |
| CONCAT(S1,S2···) | 将字符串拼接,连接为一个字符串 | SELECT CONCAT('la','gou') AS 字符串链接; concat(table.a,table.b) from table |
| LEFT(s,n) | 返回从字符串s开始的n最左字符 | SELECT LEFT('lagou',2) AS le_sub #la |
| RIGHT(s,n) | 返回从字符串s开始的n最右字符 | select right('lagou',2) as ri_sub #ou |
| mid(s,n1,n2) | 返回从字符串s开始的左边第n1个字符开始的n2个字符 | select mid('lagou',2,3) as mid_sub #ago |
| TRIM(s) | 移除掉字串中s的字头或字尾处空格 | SELECT TRIM(' lagou ') AS 去掉首尾空格; |
| REPLACE(s,s1,s2) | 用字符串s2替代字符串s重的字符串s1 | SELECT REPLACE('lagou_jiaoyu','_','.') AS 字符串替换; #lagou.jiaoyu |
| SUBSTRING(s,n,len) | 截取字符串s中第n个位置开始,长度为len的字符串 | SELECT SUBSTRING('lagou_jiaoyu',7,6) AS SUBSTRING提取子串 (同mid) |
| length() | 返回字符串的长度 | select length('lagou'); #5 |
| REVERSE(s) | 将字符串s的顺序翻转过来 | SELECT REVERSE('lagou') AS 字符串翻转; |
7.3 日期和时间函数
| 函数 | 作用 | 示例 |
| CURDATE() | 返回当前日期 | SELECT CURDATE() AS 当前日期; |
| CURTIME() | 返回当前时间 |
|
| NOW() | 返回当前日期和时间 |
|
| MONTH(d) | 返回月份 |
|
| YEAR(d) | 返回年份 |
|
7.4 条件判断函数
| 函数 | 作用 |
| IF(expo,v1,v2) | 如果表达式成立,则执行v1,否则执行v2 |
| CASE WHEN | 用于计算条件列表并返回多个可能结果表达式之一 |
| ··· | ··· |
代码示例:
1.IF(expo,v1,v2)
SELECT IF(10>5,10,5) as 最大值;
select if(10>2,10,2);
select pname,
if(price>2000,'奢侈品','普通商品') '商品性质'
from products;
select pname,if(price>2000,price-1000,price) '优惠后的价格' from products;
2.CASE WHEN
SELECT CASE WHEN 10>5 THEN 10 ELSE 5 END AS 最大值;
case
when 条件1 then 结果1
when 条件2 then 结果2
when ... then 结果n
(else 结果n+1)
end
7.5 系统信息函数
| 函数 | 作用 | 代码示例: |
| version() | 返回数据库的版本 | select version() as 数据库版本; |
| databases() | 返回当前数据库名 | select databases() as 当前数据库名; |
| user() | 返回当前用户名 | select user() as 用户名; |
| ··· | ··· |
|
函数拓展:
1、DATE_SUB和DATE_ADD函数
- DATE_SUB(curdate(),INTERVAL 1 DAY) 该函数意为:求出昨天的日期;
- 实现过程:1.使用curdate()求出当天日期;
- 2.使用DATE_SUB(当天日期,INTERVAL 1 DAY)实现当天日期减一天的日期,即昨日日期;
语法格式:
DATE_ADD(date, INTERVAL expr type) 增加时间
DATE_SUB(date, INTERVAL expr type) 退减时间
代码示例:
select
date_add('2010-12-31 23:59:59', interval 1 second) as co11,
adddate('2010-12-31 23:59:59', interval 1 second) as co12,
date_add('2010-12-31 23:59:59', interval '1:1' minute_second) as co13;
+---------------------+----------------------+-----------------------+
|c011 |co12 |co13 |
+---------------------+----------------------+-----------------------+
|2011-01-01 00:00:00 |2011-01-01 00:00:00 |2011-01-01 00:01:00 |
+---------------------+----------------------+-----------------------+
-- 同理date_sub 和 subdate 函数
-- date_add 和 date_sub 在指定修改的时间段时,也可以指定负值,负值代表相减,即返回以前的日期和时间
2、SUBTIME 函数
subtime(date,expr)
- 将date减去expr值,并返回修改后的值;
- 其中date是一个日期或日期表达式,而expr是一个时间表达式
代码示例:
select subtime('2000-12-31 23:59:59', '1:1:1') as co11 , subtime('02:02:02','02:00:00') as co12;
-- '1:1:1'这里默认对应时间表达式的最小值
+---------------------------------+----------------------------------+
|co11 |co12 |
+---------------------------------+----------------------------------+
|2000-12-31 22:58:58 |00:02:02 |
+---------------------------------+----------------------------------+
3、DATE_FORMAT(date,format) 时间格式化函数
代码示例:
select
date_format('1997-10-04 22:23:00','%W %M %Y') as co11,
date_format('1997-10-04 22:23:00','%D %y %a %d %m %b %j') as co12;
+---------------------------------+----------------------------------+
|co11 |co12 |
+---------------------------------+----------------------------------+
|Saturday October 1997 |4th 97 Sat 04 10 Oct 277 |
+---------------------------------+----------------------------------+
select
date_format('1997-10-04 22:23:00','%H:%i:%s') as co13,
date_format('1999-01-01','%X %V') as co14;
+---------------------------------+----------------------------------+
|co13 |co14 |
+---------------------------------+----------------------------------+
|22:23:00 |1998 52 |
+---------------------------------+----------------------------------+
- date_format 时间日期格式
| 说明符 | 说明 |
| %a | 工作日的缩写名称(Sun...Sat) |
| %b | 月份的缩写名称(Jan...Dec) |
| %c | 月份,数字形式(0···12) |
| %D | 以英文后缀表示月中的几号(1st,2nd···) |
| %d | 该月日期,数字形式(00···31) |
| %e | 该月日期,数字形式(0···31) |
| %f | 微妙(000000···999999) |
| %H | 以2位数表示24小时(00···23) |
| %h,%I(字母i) | 以2位数表示12小时(01···12) |
| %i | 分钟,数字形式(00···59) |
| %j | 一年中的天数(001···366) |
| %k | 以24(0···23)小时表示时间 |
| %l(字母L) | 以12(1···12)小时表示时间 |
| %M | 月份名称(January···December) |
| %m | 月份,数字形式(0···12) |
| %p | 上午(AM)或者下午(PM) |
| %r | 时间,12小时制(小时hh:分钟mm:秒数ss后加AM或PM |
| %S,%s | 以2位数形式表示秒(00···59) |
| %T | 时间,24小时制(小时hh:分钟mm:秒数ss) |
| %U | 周(00···53),其中周日为每周一天 |
| %u | 周(00···53),其中周一为每周一天 |
| %V | 周(01···53),其中周日为每周一天;和%X同时使用 |
| %v | 周(01···53),其中周一为每周一天;和%x同时使用 |
| %W | 工作日名称(周日···周六) |
| %w | 一周中的每日(0=周日···6=周六) |
| %X | 该周的年份,其中周日为每周一天;数字形式,4位数;和%V同时使用 |
| %x | 该周的年份,其中周一为每周一天;数字形式,4位数;和%v同时使用 |
| %Y | 4位数形式表示年份 |
| %y | 2位数形式表示年份 |
| %% | 标识符% |
- TIME_FORMAT() 只处理时间
4、 GET_FORMAT(val_type,format_type) 格式函数
- val_type 表示日期数据类型,包括DATE、DATETIME 和TIME;
- format_type 表示格式化显示类型,包括EUR、INTERVAL、ISO、JIS、USA等
代码示例:
-- 示例1:
select get_format(date,'ERU'), get_format(date,'USA');
+---------------------------------+----------------------------------+
|get_format(date,'ERU') |get_format(date,'USA') |
+---------------------------------+----------------------------------+
|%d.%m.%Y |%m.%d.%Y |
+---------------------------------+----------------------------------+
-- 示例2:
select date_format('2000-10-05 22:23:22', GET_FORMAT(DATE,'USA'));
+--------------------------------------------------------------------+
|date_format('2000-10-05 22:23:22', GET_FORMAT(DATE,'USA')) |
+--------------------------------------------------------------------+
|10.05.2000 |
+--------------------------------------------------------------------+
拓展代码顺序:
- 掌握SQL的执行顺序,才能正确地读懂SQL语句。
- 执行顺序:
- With as --> FROM(JOIN 部分一般先左后右) --> WHERE --> GROUP BY --> HAVING --> SELECT --> ORDER BY
- 每个部分中,先执行子查询内部,再将子查询看做一个整体,按普通顺序执行。
- 多个子查询嵌套,最先执行最内部的子查询
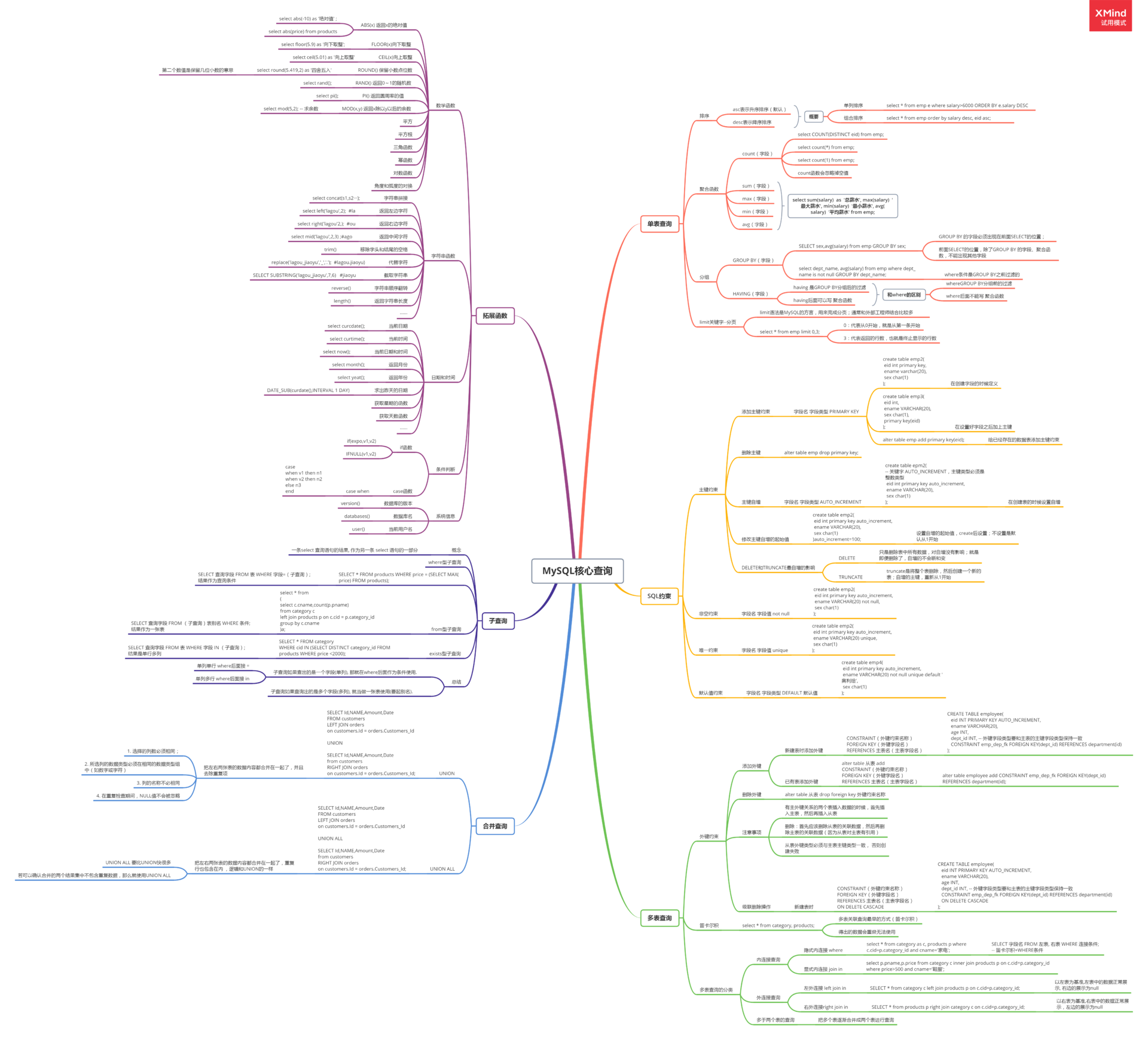
语句汇总图

















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









