







牛客网在线编程_SQL篇_SQL大厂笔试真题
多复习:1,2,3,6,10,50(求连续登录大于3天 lead
SQL40:每个月Top3的周杰伦歌曲_牛客题霸_牛客网
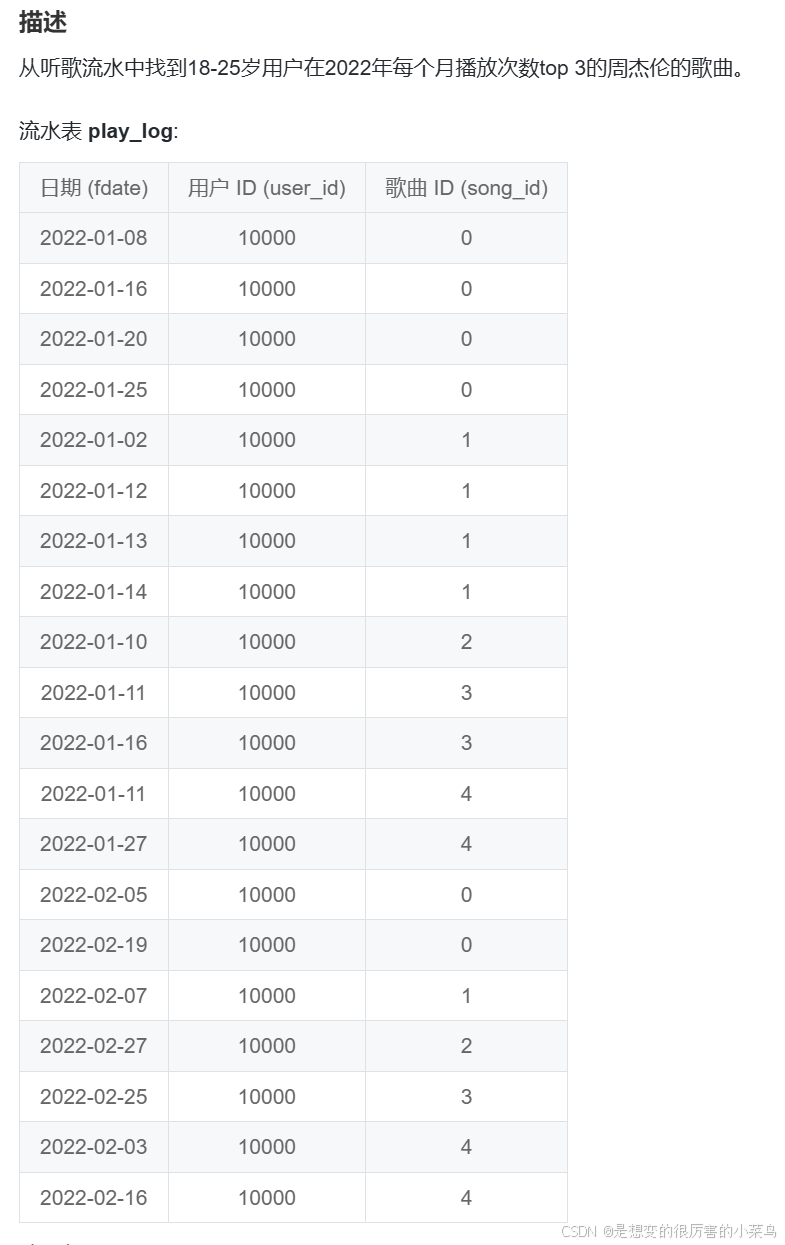
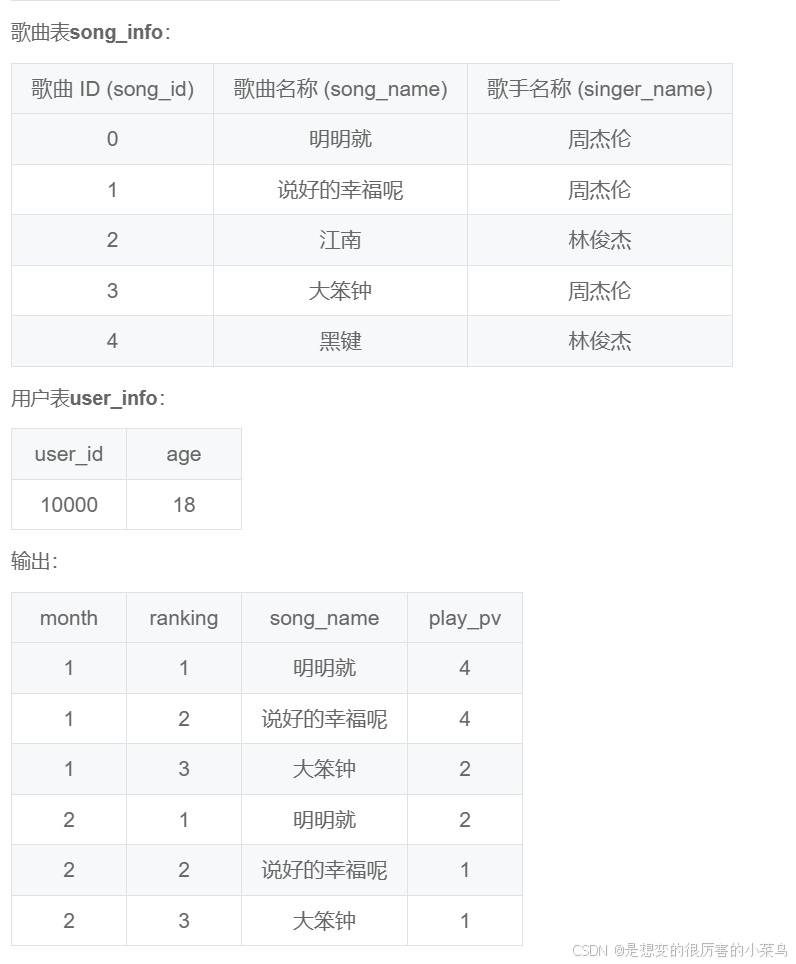
-- 从听歌流水中找到18-25岁用户在2022年每个月播放次数top 3的周杰伦的歌曲。
-- 分析
# 1、需要表连接 inner join 即可,连接字段
# 2、限制条件,18-25岁 & 2022年 周杰伦
# 3、看输出,找到应该有的字段:month(fdate)->month,且需要按照month分组 排序 ;
# ranking 是在每个month分组内再内部排序,窗口函数rank() order by play_pv
# song_name;
# play_pv:按照month,song_name 分组 求每首歌的播放次数
-- STEP 3:
SELECT *
FROM
(
-- STEP2 :对照输出表 写出筛选条件,使用函数完成需求
SELECT
MONTH(fdate) AS month,-- 对照输出表 写出字段
rank() over(partition by MONTH(fdate) order by COUNT(song_name) desc,song_info.song_id asc) as ranking,
song_name,
COUNT(song_name) AS play_pv
-- STEP1:3张表进行连接
FROM user_info
INNER JOIN play_log
ON user_info.user_id=play_log.user_id
INNER JOIN song_info
ON play_log.song_id=song_info.song_id
WHERE -- 限制条件
age BETWEEN 18 AND 25
AND singer_name='周杰伦'
AND YEAR(fdate)=2022
GROUP BY MONTH(fdate),song_name,song_info.song_id
-- 因为是先执行完group by 再执行select里面的 窗口函数,窗口函数里面又有song_id,需要再group by song_info.song_id
) t
WHERE ranking<=3
SQL41 :最长连续登录天数_牛客题霸_牛客网
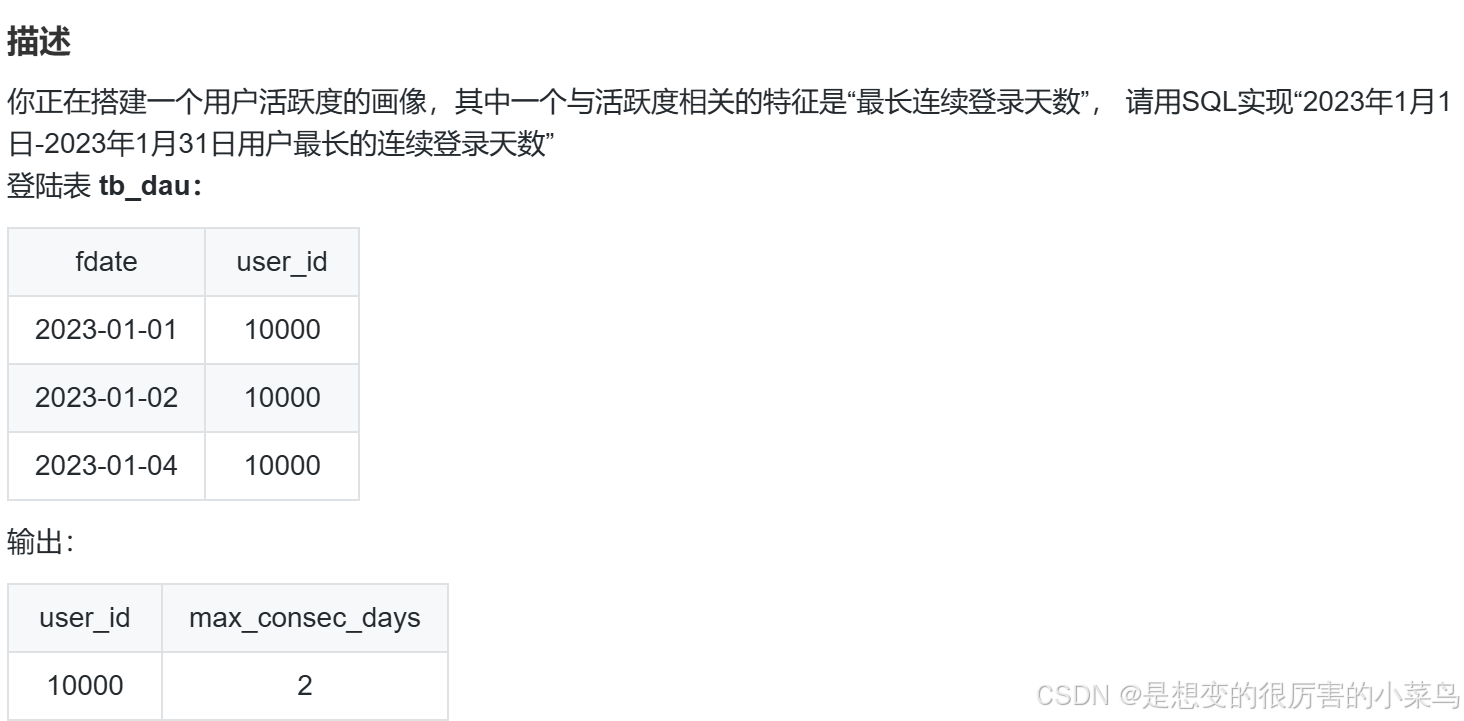
-- STEP 4:选出 最长的最长的连续登录天数 max 且 连续的意义是 count>=2
SELECT user_id,
MAX(consec_days) AS max_consec_days -- MAX 也是需要聚合函数,需要GROUP BY ,不要忘记
FROM
(
-- STEP3: 分组,求出新日期newfdate的天数
SELECT
user_id,
COUNT(newfdate) AS consec_days -- 分组求出连续天数 按user_id和日期来分组 ,保证可以汇总每个不同日期对应的天数
FROM
(
-- STEP2:利用日期函数 再得到一列-rank 的新日期
SELECT * ,
DATE_SUB(fdate,INTERVAL rn day) AS newfdate -- DATE_SUB(date, INTERVAL value unit)
FROM
(
-- STEP1: 多加一列 rank
SELECT
DISTINCT *,-- 以防相同的user_id 在同一天有2条相同记录
-- 窗口函数 dense_rank 按照fdate 排序
-- dense_rank()排序相同时会重复,总数会减少,即会出现1、1、2这样的排序结果;
# DENSE_RANK() OVER(PARTITION BY user_id ORDER BY fdate ASC) AS rank --rank rank 是一个保留字 尽量不用
DENSE_RANK() OVER(PARTITION BY user_id ORDER BY fdate ASC) AS rn
FROM tb_dau
WHERE
fdate BETWEEN '2023-01-01' AND '2023-01-31'
) as t1
) as t2
GROUP BY user_id,newfdate -- STEP3: 分组
) as t3
WHERE consec_days>=2
GROUP BY user_id -- STEP4:的分组
-- 注意 t1 t2 t3 如果不加的话,NEWCODE不能通过用例 会报错# 请用SQL实现“2023年1月1日-2023年1月31日用户最长的连续登录天数”
WITH T0 AS(
SELECT DISTINCT fdate,user_id,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY FDATE) as rn1
FROM tb_dau
WHERE fdate BETWEEN '2023-01-01' AND '2023-01-31'
),
T1 AS(
SELECT *,
DATE_SUB(fdate,INTERVAL RN1 DAY) AS NEXT_DATE
FROM T0
),
T2 as(
SELECT user_id,NEXT_DATE,
COUNT(NEXT_DATE) AS CONSEC_DAYS
FROM T1
GROUP BY user_id,NEXT_DATE
HAVING COUNT(NEXT_DATE)>=2
)
SELECT user_id,MAX(CONSEC_DAYS) as max_consec_days
FROM T2
GROUP BY USER_ID;SQL42:分析客户逾期情况_牛客题霸_牛客网
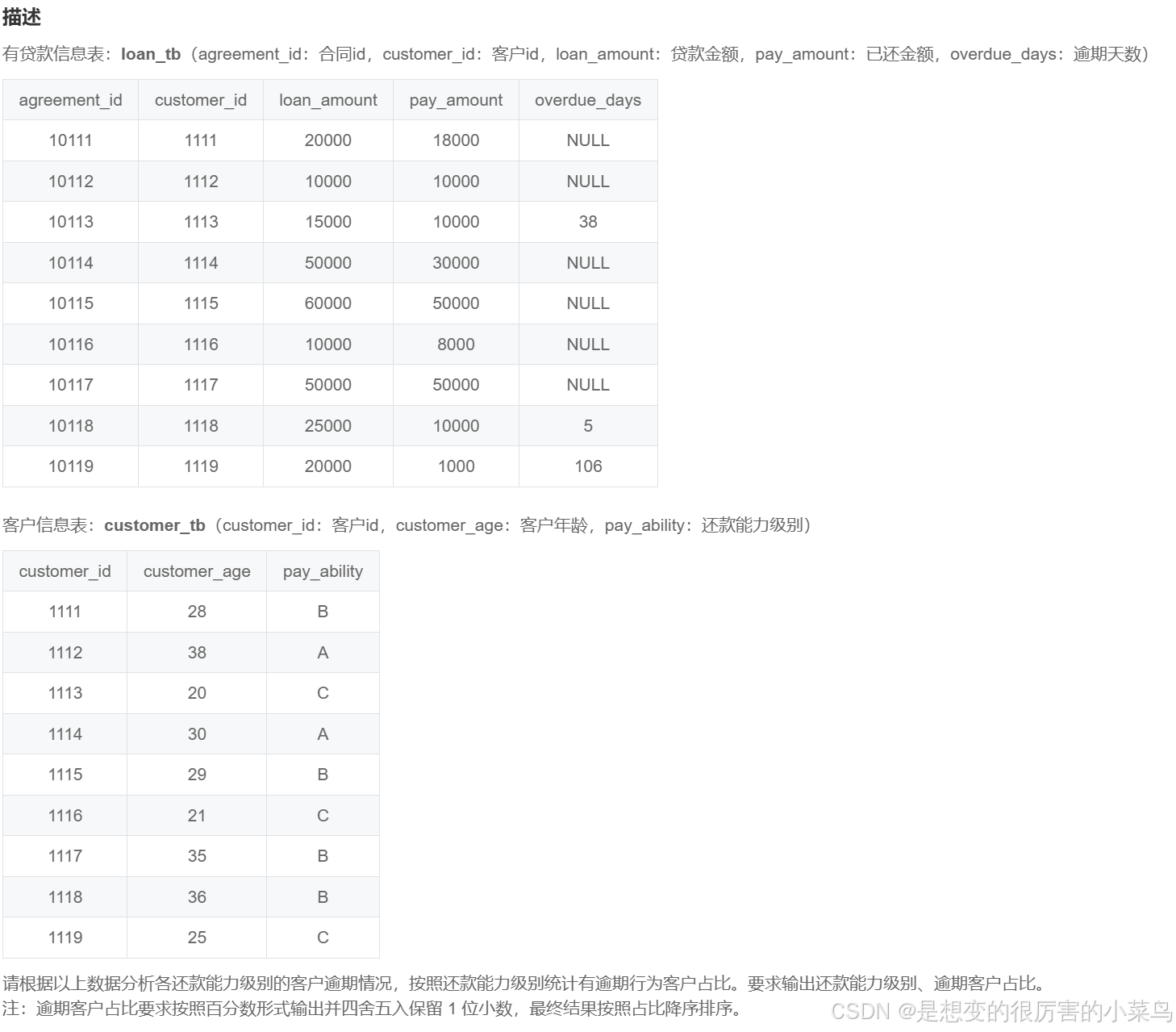

-- STEP 2:按照输出格式输出 按照百分数形式输出并四舍五入保留 1 位小数 且需要CONCAT %
SELECT
pay_ability,
-- ROUND( Not_overdue_cnt/total_cnt,1) -- 这个是计算的ratio
-- CONCAT 连接 ratio与%
CONCAT(ROUND( Not_overdue_cnt / total_cnt * 100 ,1),'%') AS overdue_ratio
-- STEP 1: 两张表连接,计算overdue的人数和总人数,方便后期算overdue_ratio
FROM
(
SELECT
pay_ability,
SUM(CASE WHEN overdue_days IS NOT NULL THEN 1 ELSE 0 END) AS Not_overdue_cnt,
COUNT(*) AS total_cnt
FROM loan_tb
INNER JOIN customer_tb
ON loan_tb.customer_id=customer_tb.customer_id
GROUP BY pay_ability
) AS T
-- 如果不加 AS T 报错 程序异常退出, 请检查代码"是否有数组越界等异常"或者"是否有语法错误" SQL_ERROR_INFO: 'Every derived table must have its own alias'
GROUP BY pay_ability
-- 最终结果按照占比降序排序。
ORDER BY overdue_ratio DESC
-- 第二遍 不熟
WITH T0 AS(
SELECT pay_ability,
SUM(CASE WHEN overdue_days IS NOT NULL THEN 1 ELSE 0 END) AS OVERDUE_CNT,
COUNT(*) AS TOTAL_PEOPLE
FROM loan_tb LEFT JOIN customer_tb
ON loan_tb.customer_id = customer_tb.customer_id
GROUP BY pay_ability
)
SELECT pay_ability,
CONCAT(ROUND(OVERDUE_CNT/TOTAL_PEOPLE*100,1),'%') AS overdue_ratio
FROM T0
ORDER BY overdue_ratio DESC;
SQL43: 获取指定客户每月的消费额_牛客题霸_牛客网
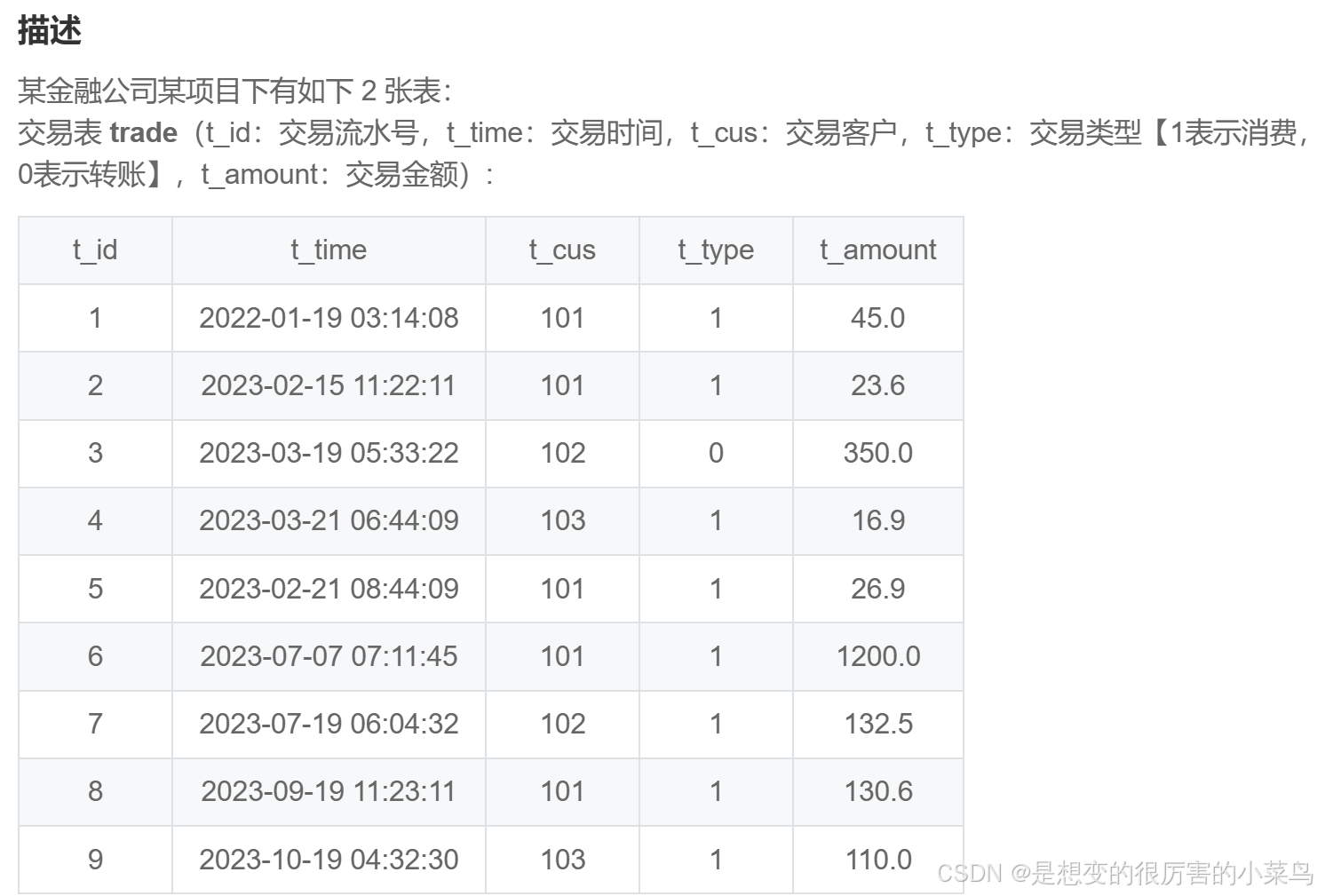

# 现需要查询 Tom 这个客户在 2023 年每月的消费金额(按月份正序显示)
SELECT
-- STEP 2 :按照输出格式 修改time
DATE_FORMAT(t_time,'%Y-%m') AS time,
SUM(t_amount) AS total
-- STEP 1:表连接
FROM trade
INNER JOIN customer
ON trade.t_cus=customer.c_id
AND customer.c_name='Tom'
AND t_type = 1 -- 题中很隐晦,求消费金额,1代表消费,0代表转账
WHERE YEAR(t_time)=2023
GROUP BY time
ORDER BY time ASC SQL44:查询连续入住多晚的客户信息?_牛客题霸_牛客网
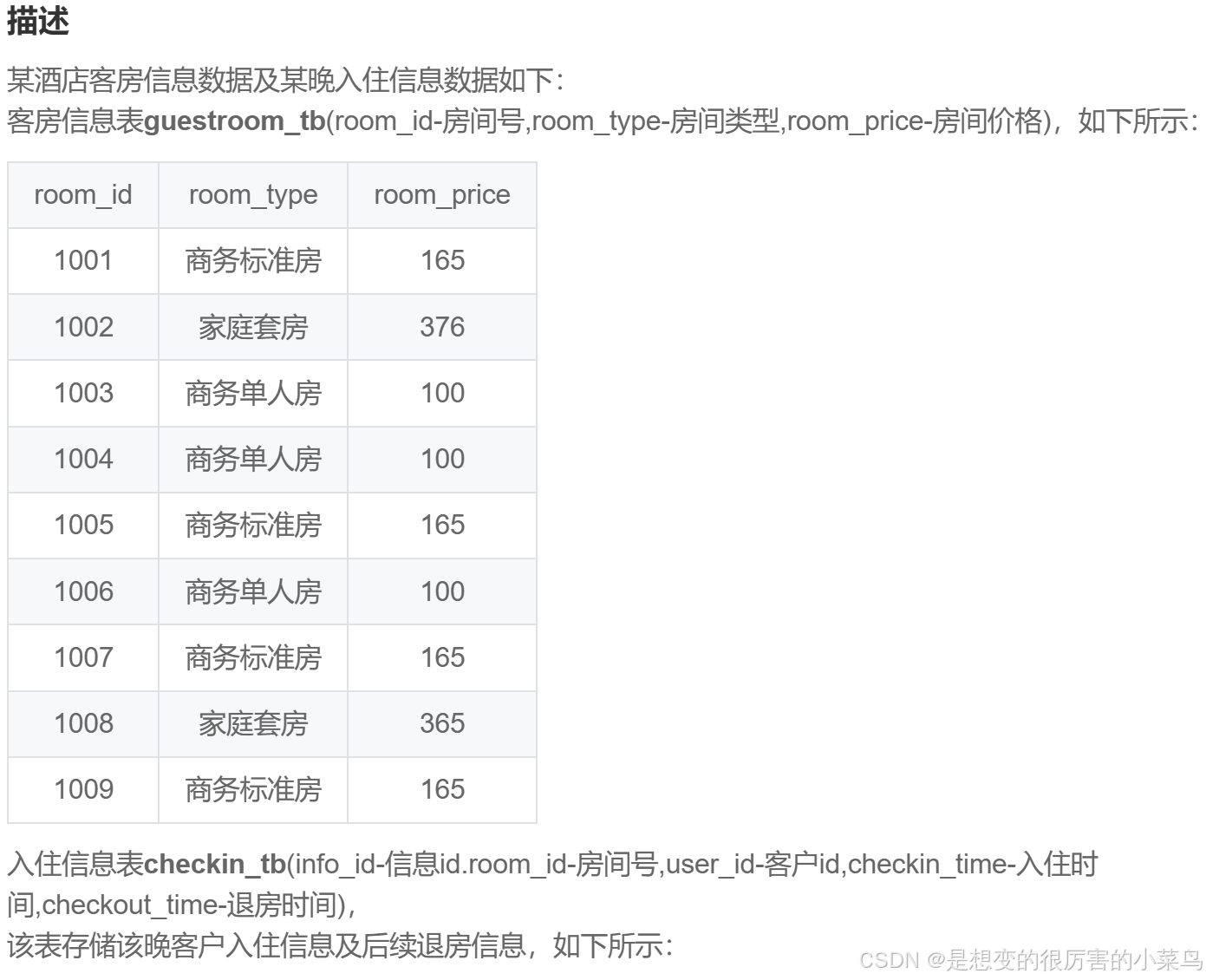
SELECT
user_id,
room_id,
room_type,
staydays as days
FROM
(
SELECT
checkin_tb.user_id,
checkin_tb.room_id,
guestroom_tb.room_type,
-- STEP 2:每个用户入住的天数
DATEDIFF(checkout_time,checkin_time) AS staydays -- 多加一列,求 每个用户入住的天数
-- STEP 1:连接表
FROM guestroom_tb
INNER JOIN checkin_tb
ON guestroom_tb.room_id=checkin_tb.room_id
WHERE checkin_time >= '2022-06-12' -- 限制条件,6月12日起
) as t
WHERE staydays>=2 -- 连续入住多晚的客户 要筛选出days>=2
ORDER BY days ASC, room_id ASC, user_id DESC
SQL45:统计所有课程参加培训人次_牛客题霸_牛客网
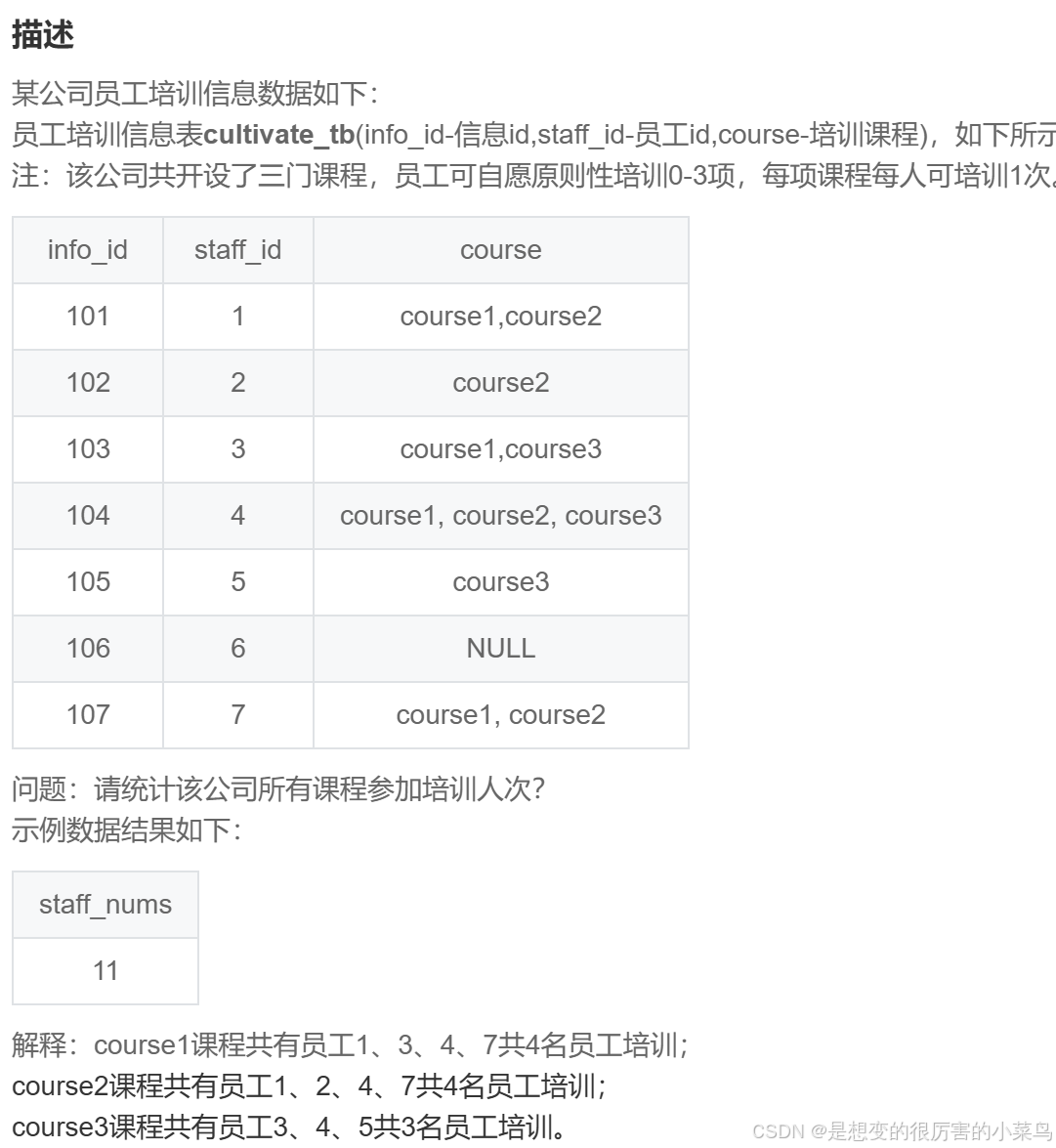
-- 请统计该公司所有课程参加培训人次?
-- 本题考查 如何提取对比 确定字段 like '%' 提取
-- 题中信息:共开设了三门课程
-- 一条条记录开始查找,只要对比到一个 就记作1,开始向下查找下一条数据
SELECT
CNT1+CNT2+CNT3 AS staff_nums
FROM
(
SELECT
SUM( CASE WHEN course LIKE '%course1%' THEN 1 ELSE 0 END ) AS CNT1 ,
SUM( CASE WHEN course LIKE '%course2%' THEN 1 ELSE 0 END ) AS CNT2 ,
SUM( CASE WHEN course LIKE '%course3%' THEN 1 ELSE 0 END ) AS CNT3
FROM
cultivate_tb
) as t --不写as t 会报错
SQL46:查询培训指定课程的员工信息_牛客题霸_牛客网
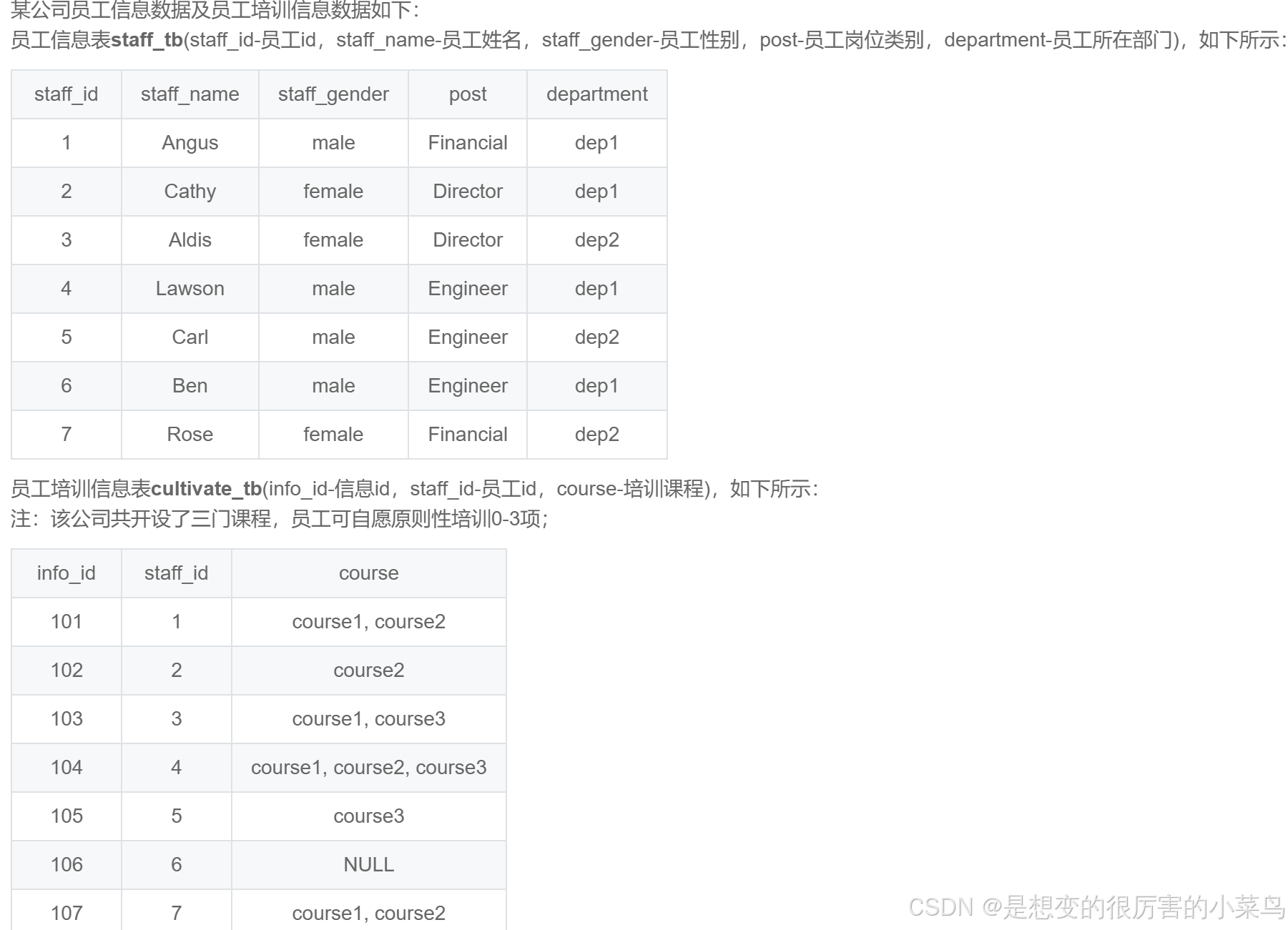

-- 输出要求 只要培训的课程中包含course3课程就计入结果
-- LIKE '%course3%' 直接在where语句中筛选
SELECT
staff_tb.staff_id,
staff_name
FROM staff_tb
INNER JOIN cultivate_tb
ON staff_tb.staff_id=cultivate_tb.staff_id
AND cultivate_tb.course like '%course3%'
ORDER BY staff_id -- 按照员工id升序排序
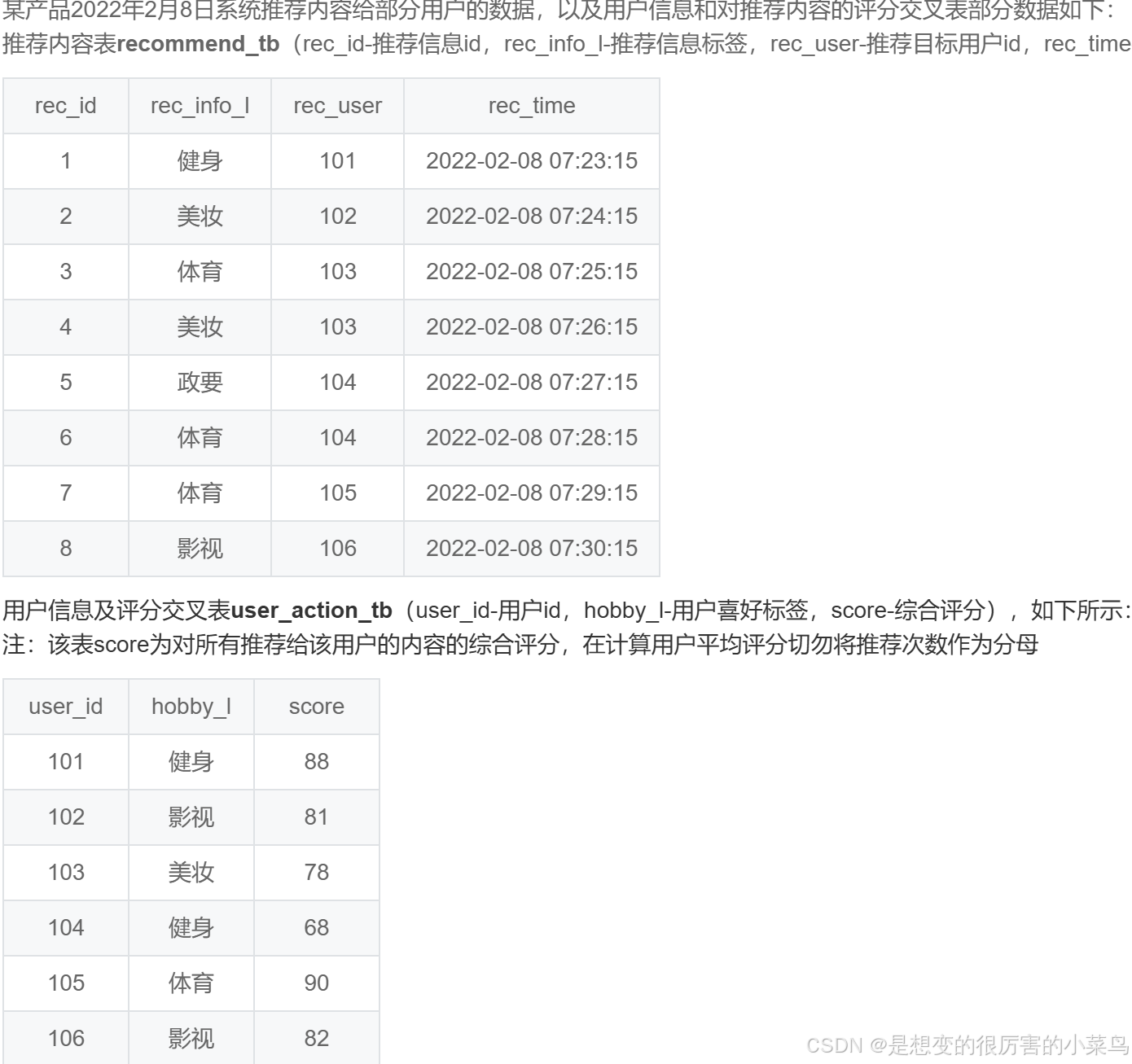
SQL47:推荐内容准确的用户平均评分_牛客题霸_牛客网
SELECT
ROUND(SUM(score)/COUNT(user_id),3) AS avg_score
FROM
(
SELECT
DISTINCT
user_action_tb.user_id,
user_action_tb.hobby_l,
user_action_tb.score
FROM recommend_tb
-- 如推荐多次给同一用户,有一次及以上准确就归为准确。
INNER JOIN user_action_tb
ON recommend_tb.rec_user=user_action_tb.user_id
AND recommend_tb.rec_info_l=user_action_tb.hobby_l -- 两个字段
) as t SQL48:每个商品的销售总额_牛客题霸_牛客网
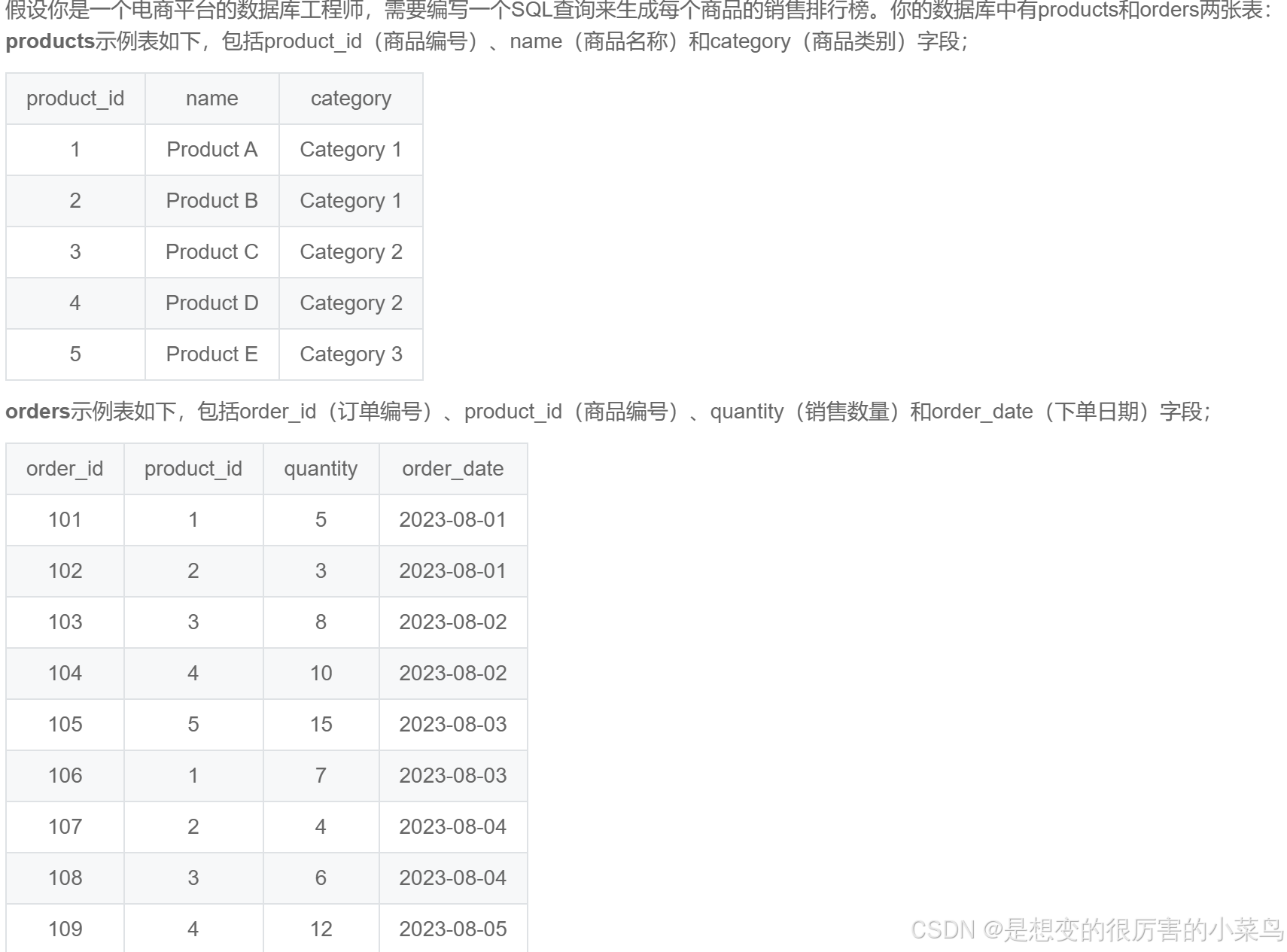
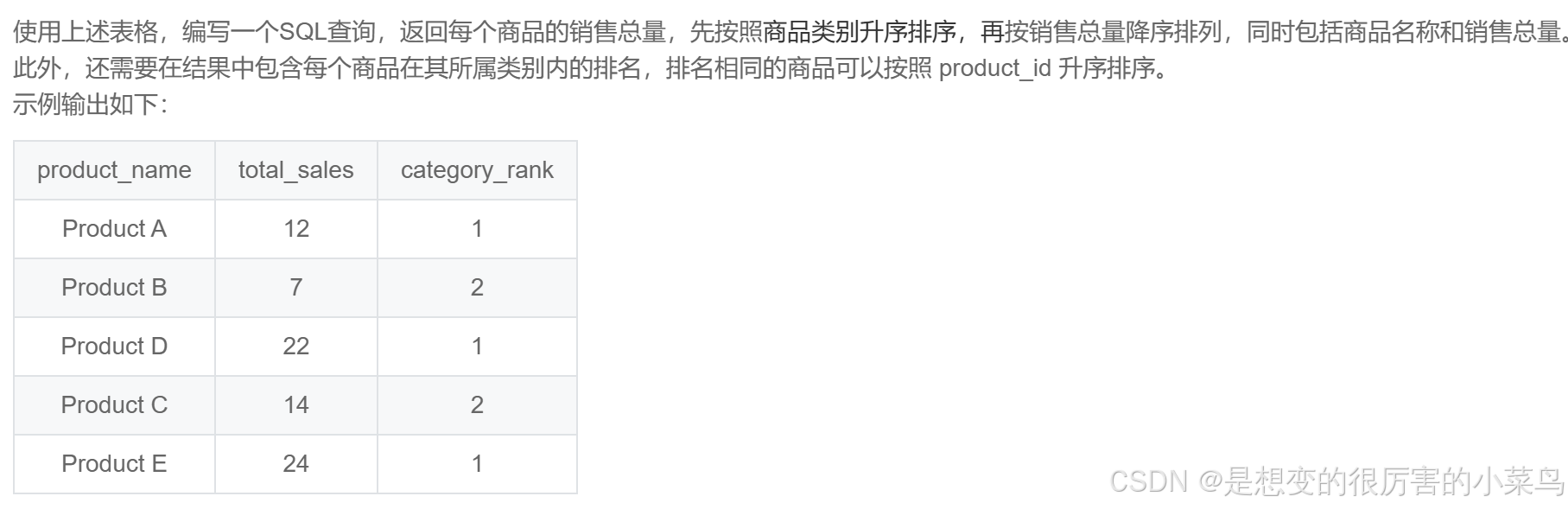
-- 根据 输出的实例以及要求:包含每个商品在其所属类别内的排名 ——>需要窗口函数
-- 法1: 不需要SELECT 嵌套,直接写窗口函数,但是窗口函数内部比较复杂
-- 以及 需要注意 窗口函数中涉及到的ORDER BY SUM(quantity) ,需要把聚合函数写入
-- 以及 需要注意,最后一行 GROUP BY 不止写没有聚合函数的 name,还需要些 窗口函数partition的字段 category
SELECT
name as product_name,
-- STEP2: 按照name 分组,求出每个商品name卖出的个数
SUM(quantity) AS total_sales,
-- 窗口函数
RANK() OVER(PARTITION BY category ORDER BY SUM(quantity) DESC,orders.product_id asc) as category_rank
-- STEP1:连接表
FROM products
INNER JOIN orders
ON products.product_id=orders.product_id
GROUP BY name,category,orders.product_id
-- 法2 虚拟表 2次select
WITH T0 as (
SELECT
name as product_name,
SUM(quantity) as total_sales,
category
FROM
products INNER JOIN orders
ON products.product_id = orders.product_id
GROUP BY product_name, category
)
SELECT
product_name,
total_sales,
RANK() OVER(PARTITION BY category ORDER BY total_sales DESC) as category_rank
FROM T0
SQL49:统计各岗位员工平均工作时长_牛客题霸_牛客网
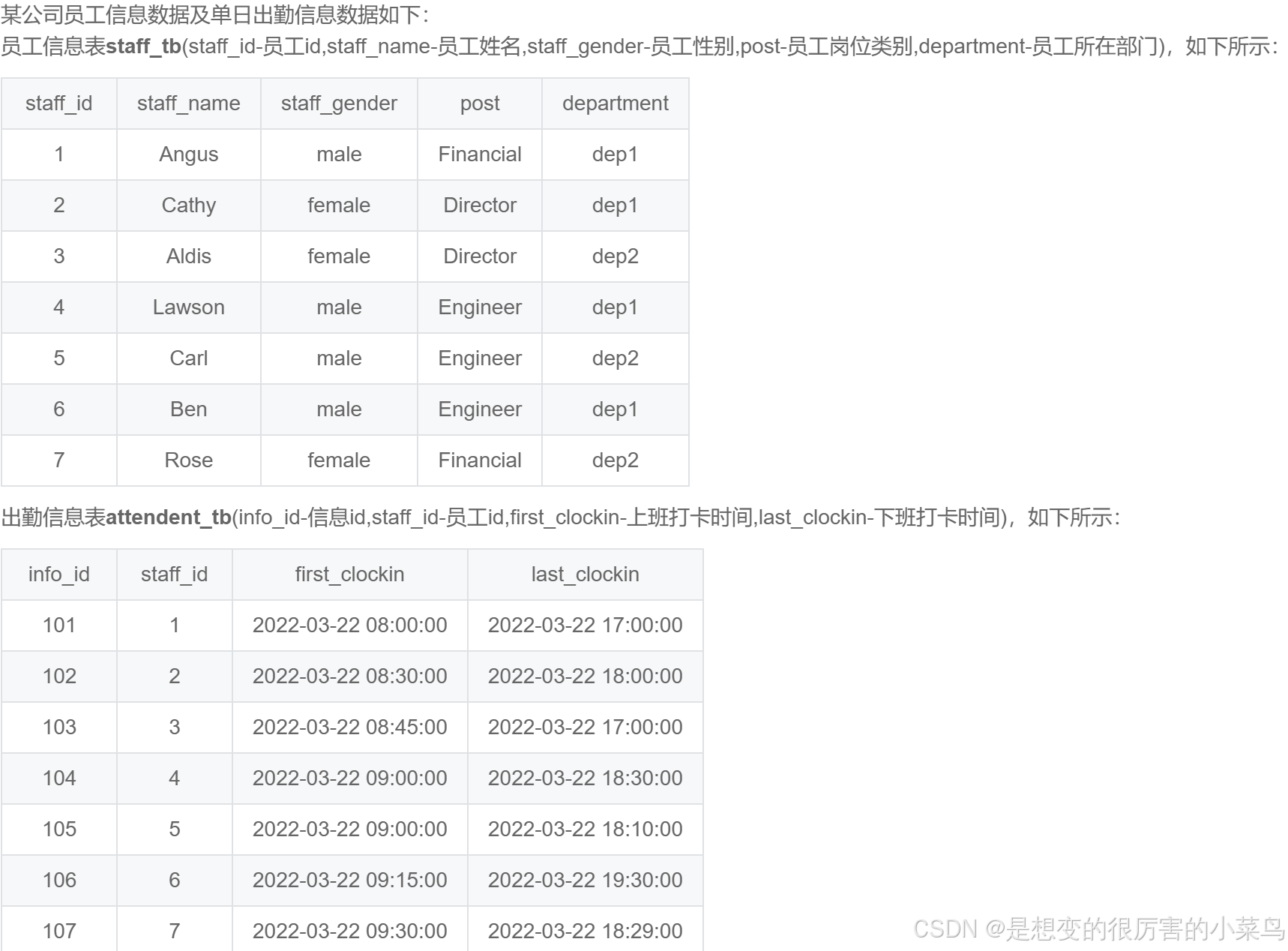

WITH T0 AS(
SELECT
staff_tb.staff_id,post,
TIMESTAMPDIFF(minute,first_clockin,last_clockin) / 60 as worktime
FROM staff_tb JOIN attendent_tb
ON staff_tb.staff_id = attendent_tb.staff_id
)
SELECT post,
ROUND(SUM(worktime)/COUNT(STAFF_ID ),3) AS work_hours
FROM T0
-- 为了避免 有一位员工没有打卡 为NULL 但确有人头,题目提示(注:如员工未打卡该字段数据会存储为NULL,那么不计入在内。)
-- 需要事先排除 NULL 记录
WHERE worktime IS NOT NULL
GROUP BY post
ORDER BY work_hours DESC;
-- 采用以上代码一直出问题,原因在于
# staff_id post worktime
# 1 Financial None
# 有一位员工没有打卡 为NULL 但确有人头,题目提示(注:如员工未打卡该字段数据会存储为NULL,那么不计入在内。)
# 所以,最好使用 AVGSELECT
post,
# ROUND(SUM(TIMESTAMPDIFF(SECOND, first_clockin, last_clockin) / 3600) / COUNT(1), 3) AS work_hours
ROUND(AVG(TIMESTAMPDIFF(SECOND, first_clockin, last_clockin) / 3600), 3) AS work_hours
FROM staff_tb
LEFT JOIN attendent_tb ON staff_tb.staff_id = attendent_tb.staff_id
GROUP BY post
ORDER BY work_hours DESC;
-- 平均工作时长(以小时为单位输出并保留三位小数)
# first_clockin last_clockin
# 2022-03-22 08:00:00 2022-03-22 17:00:00
-- TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND),使用起来比datediff函数更加灵活。
-- 对于比较的两个时间,时间小的放在前面,时间大的放在后面。
-- 因 以小时为单位输出并保留三位小数,diff后得到的是秒,1h=3600s 要/3600
-- 求work_hours的2种方法
-- 1.求和/count
-- ROUND(SUM(TIMESTAMPDIFF(SECOND, first_clockin, last_clockin) / 3600) / COUNT(1), 3) AS work_hours,
-- 2. AVG 推荐
-- ROUND(AVG(TIMESTAMPDIFF(SECOND, first_clockin, last_clockin) / 3600), 3) AS avg_work_hours
SQL50 查询连续登陆的用户
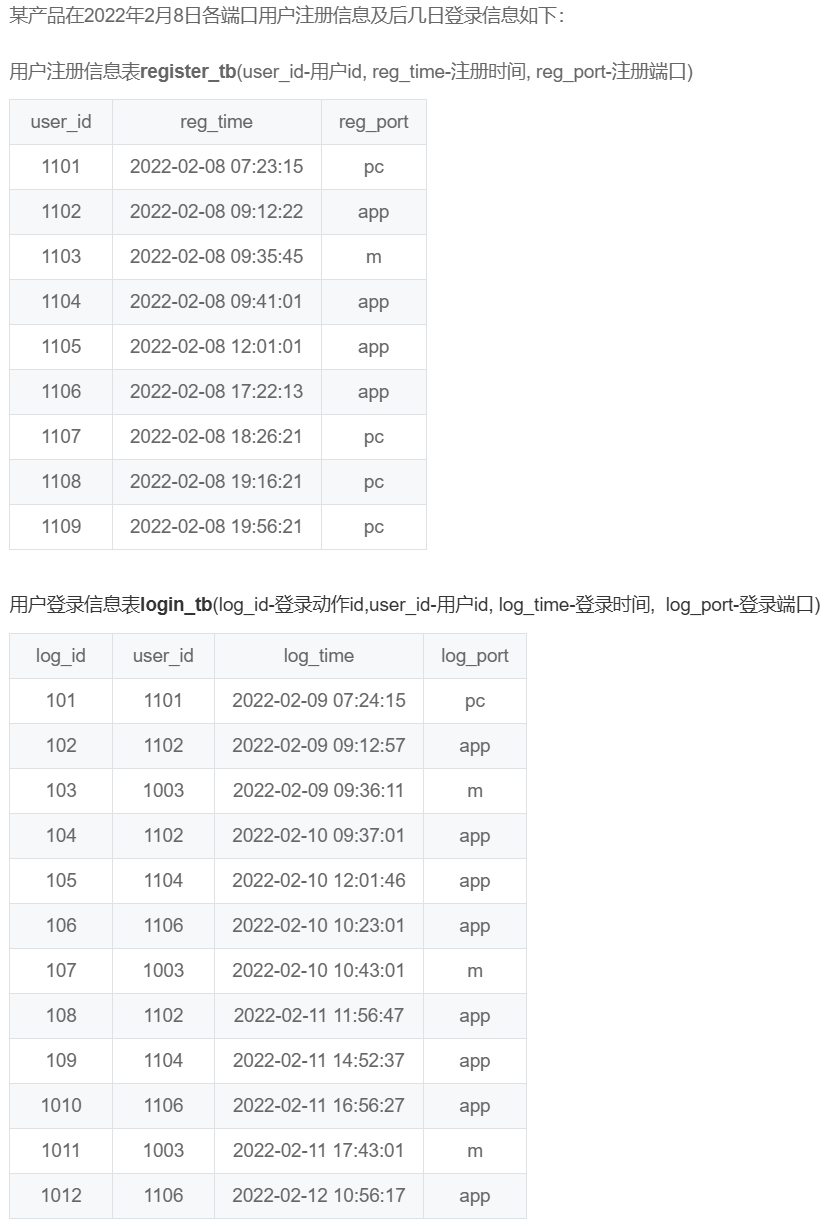

WITH T0 AS(
SELECT
register_tb.user_id,
date(log_time) log_date
FROM register_tb JOIN login_tb
ON register_tb.user_id = login_tb.user_id
),
T1 AS(
SELECT
*,
LEAD(user_id,1) OVER(PARTITION BY user_id ORDER BY log_date) AS next_user_id
FROM T0 )
SELECT
DISTINCT user_id
FROM T1
WHERE user_id = next_user_id
GROUP BY user_id
HAVING COUNT(*)>=2

















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









