







 该文介绍了如何下载和处理人脸口罩数据集,包括按比例获取正负样本,对数据集进行重命名以形成连续序列,调整正负样本的像素大小以优化模型训练,以及创建txt文件用于后续的模型训练。最后,文章提到了使用opencv_traincascade.exe进行模型训练的过程。
该文介绍了如何下载和处理人脸口罩数据集,包括按比例获取正负样本,对数据集进行重命名以形成连续序列,调整正负样本的像素大小以优化模型训练,以及创建txt文件用于后续的模型训练。最后,文章提到了使用opencv_traincascade.exe进行模型训练的过程。
一、人脸口罩数据集下载处理
(一)人脸口罩数据集下载
下载人脸口罩数据集的目的是利用OpenCV进行模型训练,这里采用口罩数据集的正负比列为1:3,即500张戴口罩的人脸图片和1500张不戴口罩的人脸图片。
链接:百度网盘 请输入提取码
提取码:n2um
解压之后,将压缩包中的mask文件自行选择文件夹放置,以便之后的操作。
(二)人脸口罩数据集的处理
1、将数据集重命名为连续序列
因为数据集中的图片序列是不连续的,因此这里需要编程将数据集的正负样本重命名为连续序列,以便像素调整。
重命名正样本序列Python代码:
#对数据集重命名
#coding:utf-8
import os
path = "D:\\facemask\\mask\\have_mask" #人脸口罩数据集正样本的路径
filelist = os.listdir(path)
count=1000 #开始文件名1000.jpg
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count)+filetype)
os.rename(Olddir,Newdir)
count+=1命名之后,正样本序列如下:

重命名负样本序列Python代码:
#对数据集重命名
#coding:utf-8
import os
path = "D:\\facemask\\mask\\no_mask" #人脸口罩数据集的路径
filelist = os.listdir(path)
count=10000 #开始文件名1000.jpg
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count)+filetype)
os.rename(Olddir,Newdir)
count+=1重命名之后,负样本序列如下:

2、正负样本数据集像素处理
正样本数据集的像素最佳设为20x20,这样的模型训练精度更高;负样本数据集像素不低于50x50,这样处理可以加快模型训练的速度。
修改正样本数据集像素为20x20Python代码:
#修改正样本像素
import pandas as pd
import cv2
for n in range(1000,1606):#代表正数据集中开始和结束照片的数字
path='D:\\facemask\\mask\\have_mask\\'+str(n)+'.jpg'
# 读取图片
img = cv2.imread(path)
img=cv2.resize(img,(20,20)) #修改样本像素为20x20
cv2.imwrite('D:\\facemask\\mask\\have_mask\\' + str(n) + '.jpg', img)
n += 1
修改像素之后,序列如下:
修改负样本数据集像素为80x80Python代码:
#修改负样本像素
import pandas as pd
import cv2
for n in range(10000,11790):#代表负样本数据集中开始和结束照片的数字
path='D:\\facemask\\mask\\no_mask\\'+str(n)+'.jpg'
# 读取图片
img = cv2.imread(path)
img=cv2.resize(img,(80,80)) #修改样本像素为80*80
cv2.imwrite('D:\\facemask\\mask\\no_mask\\' + str(n) + '.jpg', img)
n += 1
修改像素之后,序列如下:

3、创建正负样本数据集路径的txt文件
(1)创建正样本数据集txt文件
win+R打开窗口输入cmd,进入命令提示符界面,进入have_mask文件夹
输入命令创建路径文件
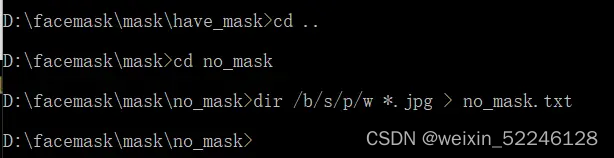
dir /b/s/p/w *.jpg > have_mask.txt

have_mask.txt文件位置在正样本数据集文件夹中
(2)创建负样本数据集txt文件(方法同正样本数据集一样)
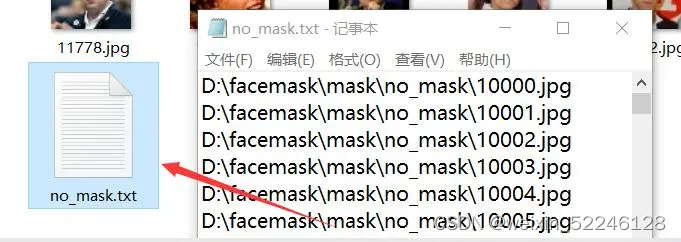
然后将have_mask.txt和no_mask.txt文件放到mask目录下

(三)、算法实现
- 创建xml文件夹存放训练好的模型
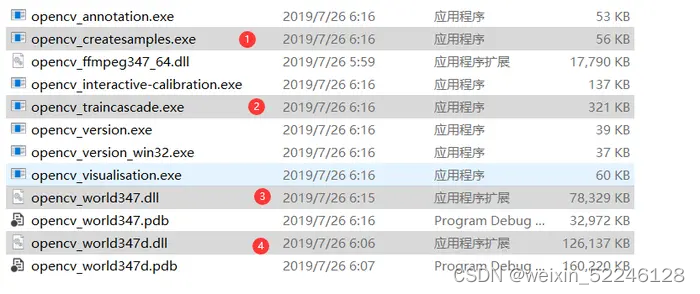
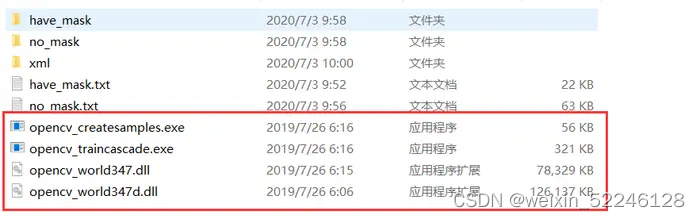
 将OpenCV安装路径 \opencv\build\x64\vc14\bin下的opencv_createsamples.exe可执行文件和opencv_traincascade.exe可执行文件及另外两个下图文件复制到数据集同级目录,如下所示:
将OpenCV安装路径 \opencv\build\x64\vc14\bin下的opencv_createsamples.exe可执行文件和opencv_traincascade.exe可执行文件及另外两个下图文件复制到数据集同级目录,如下所示:
2. 对正负样本txt文档进行预处理
正负样本需要生成 .vec格式的文档进行模型训练,因此需要通过对txt文档进行预处理,向have_mask.txt文件中末尾加入 1 0 0 20 20。
正样本处理Python代码:
#正样本文件预处理 没行目录结尾加入 1 0 0 20 20
#coding:utf-8
import os
#Houzui="_Apple"
Houzui=r" 1 0 0 20 20" #后缀
filelist = open('D:\\facemask\\mask\\have_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzui+'\n'
print(file)
filelist.write(file)
负样本处理Python代码:
#负样本文件预处理 没行目录结尾加入 1 0 0 60 60
#coding:utf-8
import os
#Houzui="_Apple"
Houzui=r" 1 0 0 80 80" #后缀
filelist = open('D:\\facemask\\mask\\no_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzui+'\n'
print(file)
filelist.write(file)
这个处理不会自动覆盖之前的文件内容,所以需要手动将之前的内容剪切出来 ,保存为have_mask1.txt文件,have_mask.txt文件中只保留末尾为1 0 0 20 20的内容,如下:
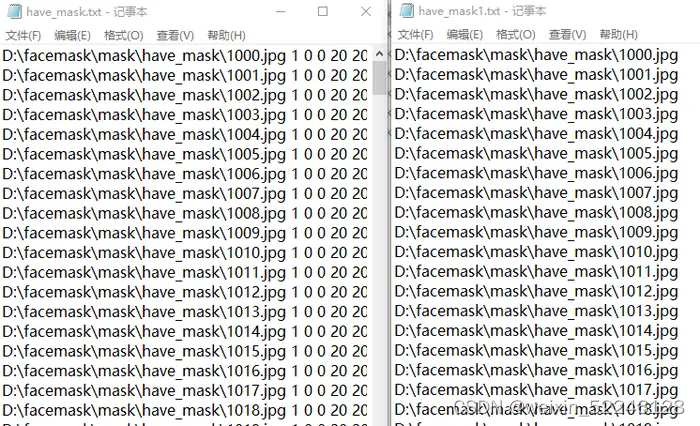
同理,对no_mask.txt文件执行同样的操作手动将之前的内容剪切出来 ,保存为no_mask1.txt文件,no_mask.txt文件中只保留末尾为1 0 0 80 80的内容,如下:
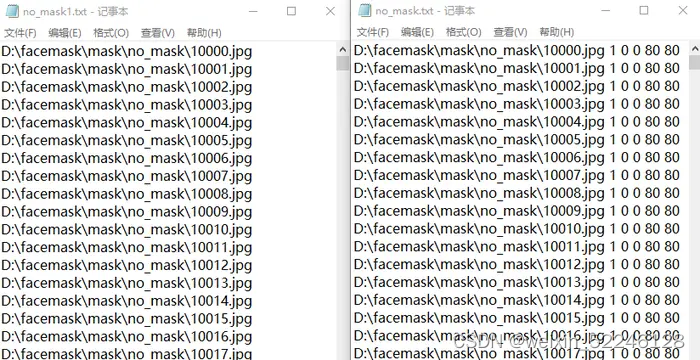
3.生成正样本havemask.vec文件和nomask.vec文件
这里操作在cmd终端中进行,进入mask文件夹下,输入以下内容:
生成正样本havemask.vec文件:
opencv_createsamples.exe -vec havemask.vec -info have_mask.txt -num 410 -w 20 -h 20

生成负样本nomask.vec文件:
opencv_createsamples.exe -vec nomask.vec -info no_mask.txt -num 1688 -w 80 -h 80
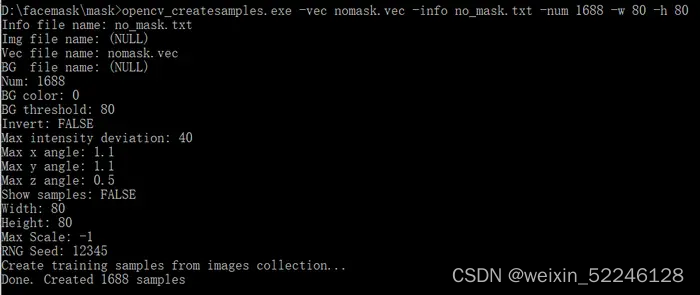
上述命令内容阐述:
info:样本说明文件
vec:样本描述文件名和路径
num:样本个数,这里为410个样本
w h:样本尺寸,这里为20x20
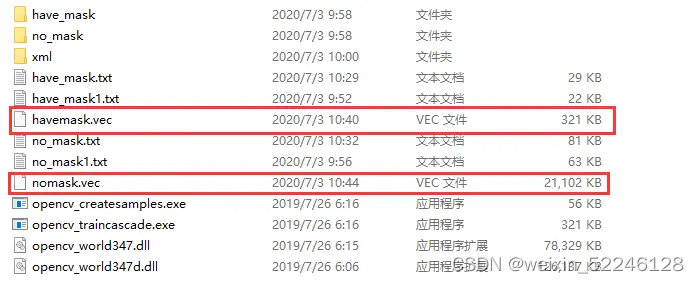
生成文件如下:
(四)、算法优化
训练模型
(1)在mask目录下创建txt文件,写入以下内容:
opencv_traincascade.exe -data xml -vec havemask.vec -bg no_mask.txt -numPos 350 -numNeg 400 -numStages 20 -w 20 -h 20 -mode ALL pause
(2)将创建的txt文件命名为traincascade.bat
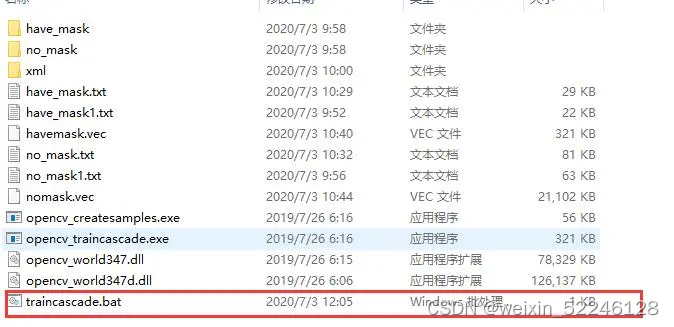
(3)删的have_mask.txt和no_mask,txt,然后将have_mask1.txt和no_mask1.txt改为have_mask.txt和no_mask.txt
(4)打开traincascade.bat,开始训练人脸口罩数据集模型
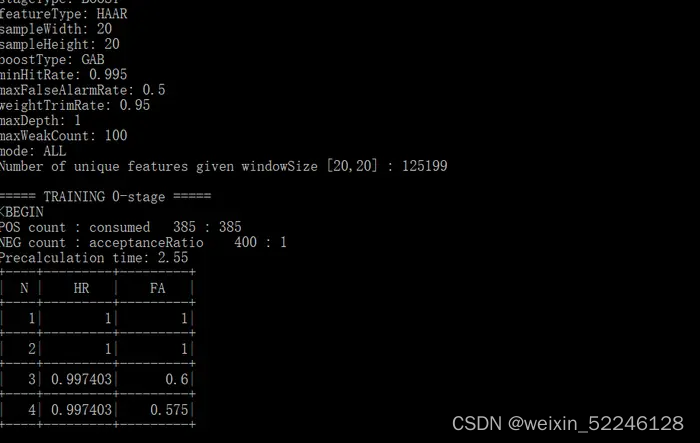
在这里训练模型的时间会很长,耐心等待…
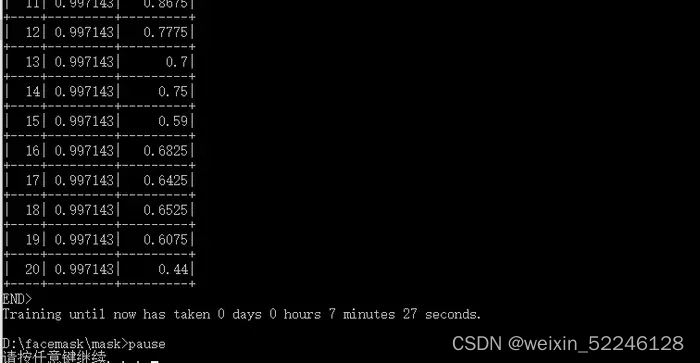
训练结束
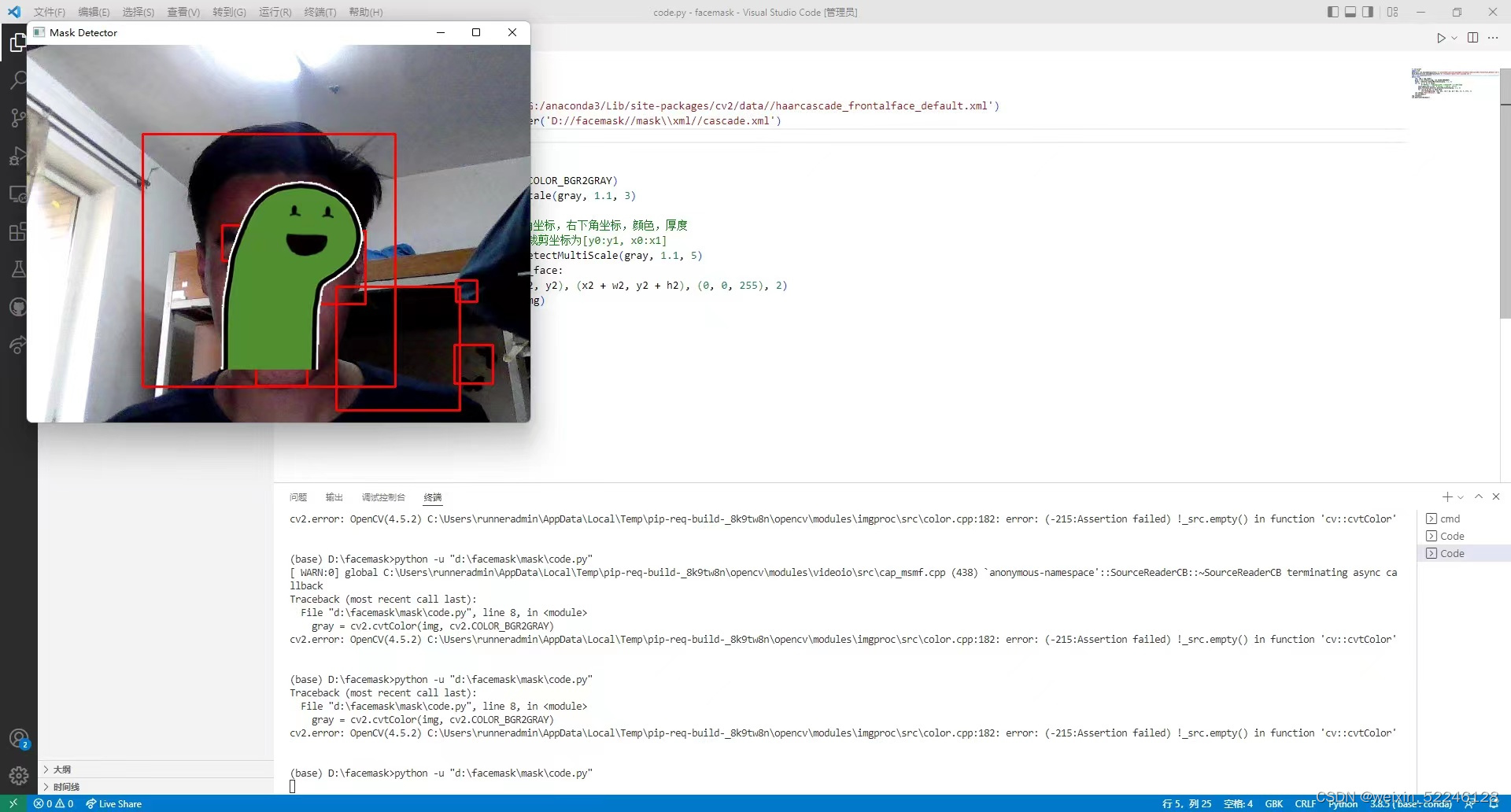
(五)、成果展示
运行结果:
未佩戴口罩不会做标记:
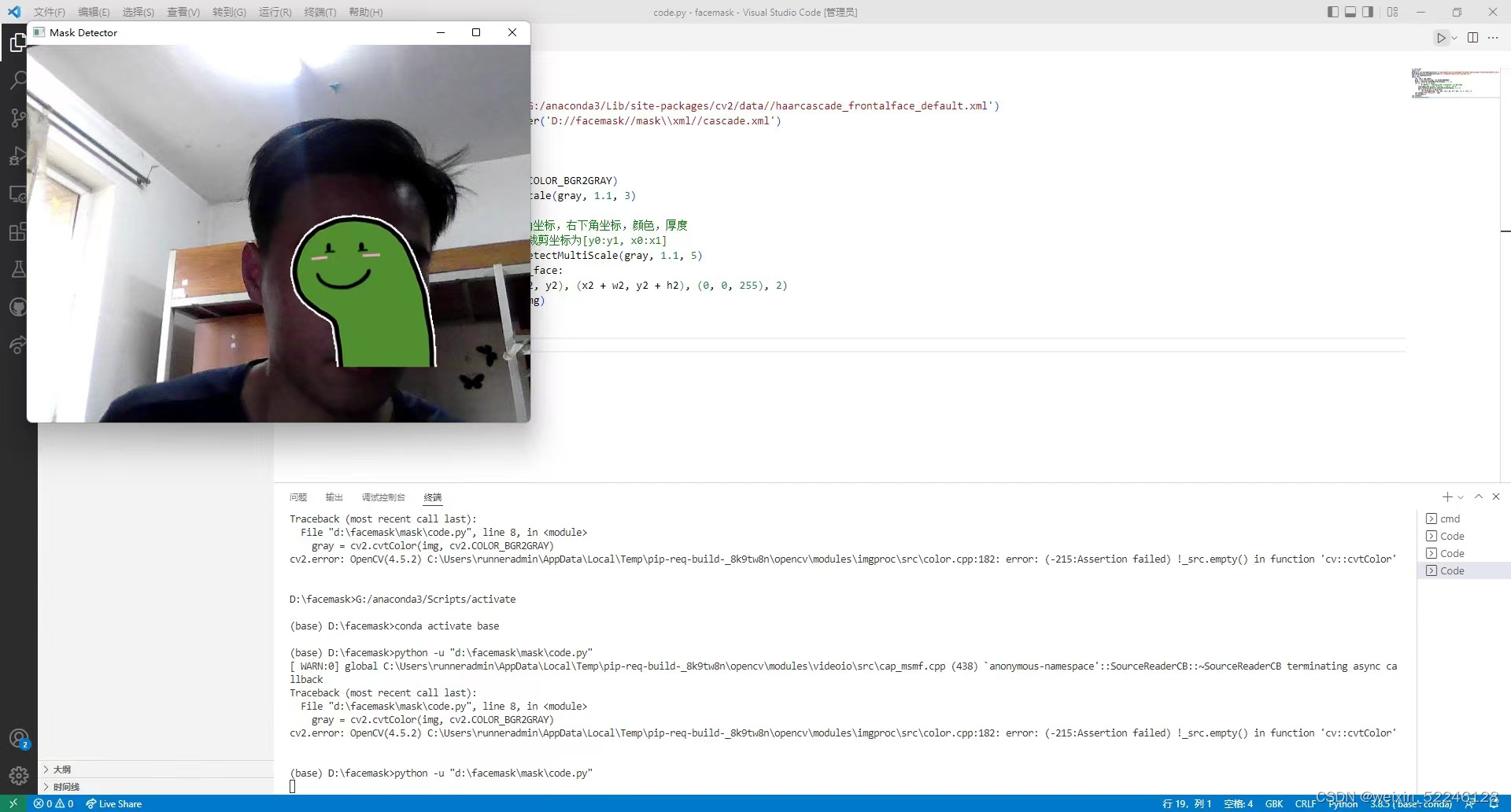
而佩戴口罩会做出标记

















 3344
3344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









