







前言
存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性:
- 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器
- 容量足够大:容量能够存储计算机所需的全部数据
- 价格足够便宜:价格低廉,所有类型的计算机都能配备
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构:
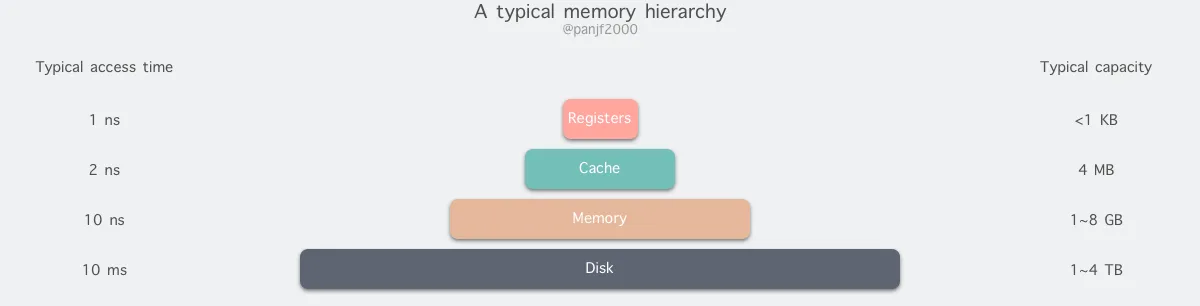
从顶至底,现代计算机里的存储器类型分别有:寄存器、高速缓存、主存和磁盘,这些存储器的速度逐级递减而容量逐级递增 存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理 第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式 第三层则是主存,也即主内存,通常称作随机访问存储器(Random Access Memory, RAM)。是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质 至于磁盘则是图中离用户最远的一层了,读写速度相差内存上百倍;另一方面自然针对磁盘操作的优化也非常多,如 零拷贝 、 direct I/O 、 异步 I/O 等等,这些优化的目的都是为了提高系统的吞吐量;另外操作系统内核中也有 磁盘高速缓存区 、 PageCache 、 TLB 等,可以有效的减少磁盘的访问次数 现实情况中,大部分系统在由小变大的过程中,最先出现瓶颈的就是 I/O ,尤其是在现代网络应用从 CPU 密集型转向了 I/O 密集型的大背景下, I/O 越发成为大多数应用的性能瓶颈 传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和用户进程地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力 这篇文章就从文件传输场景以及零拷贝技术深究 Linux I/O 的发展过程、优化手段以及实际应用。
需要了解的词
- DMA
DMA,全称Direct Memory Access,即直接存储器访问,是为了避免CPU在磁盘操作时承担过多的中断负载而设计的;在磁盘操作中,CPU可将总线控制权交给DMA控制器,由DMA输出读写命令,直接控制RAM与I/O接口进行DMA传输,无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,使得CPU的效率大大提高 - MMU
Memory Management Unit—内存管理单元,主要实现: - 竞争访问保护管理需求:需要严格的访问保护,动态管理哪些内存页/段或区,为哪些应用程序所用。这属于资源的竞争访问管理需求
- 高效的翻译转换管理需求:需要实现快速高效的映射翻译转换,否则系统的运行效率将会低下
- 高效的虚实内存交换需求:需要在实际的虚拟内存与物理内存进行内存页/段交换过程中快速高效
- Page Cache
为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用页缓存(Page Cache)机制来对文件中的数据进行缓存
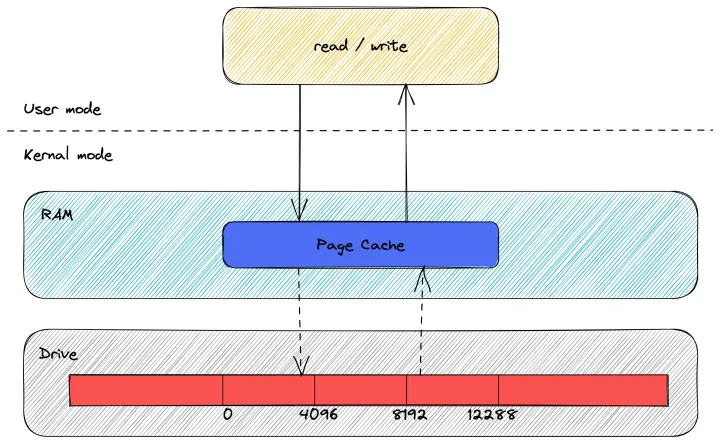
此外,由于读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,有进程读取到它了,收益就非常大
- 虚拟内存
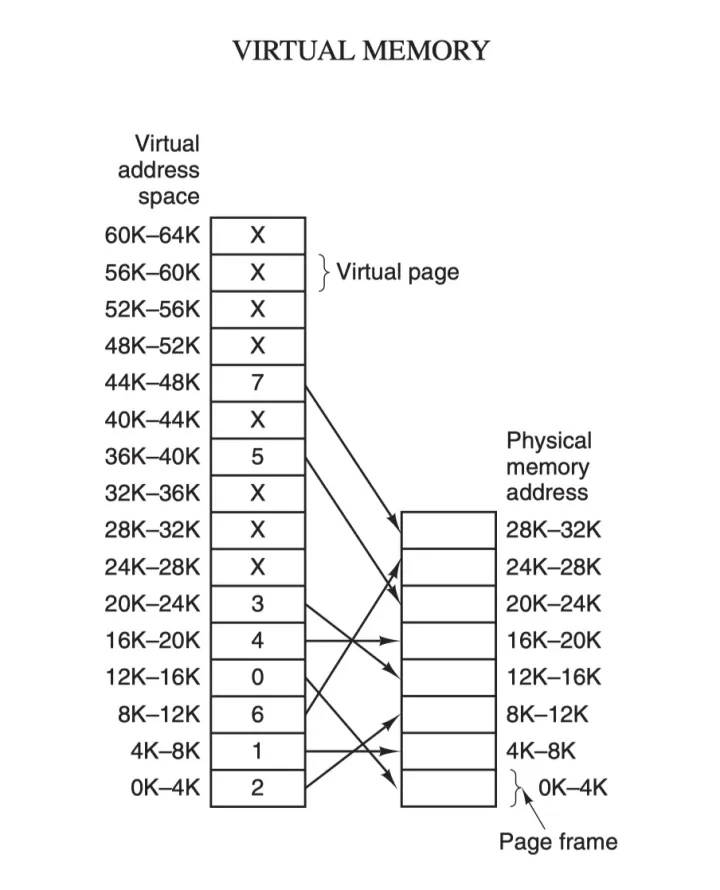
在计算机领域有一句如同摩西十诫般神圣的哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决",从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一
虚拟内存为每个进程提供了一个一致的、私有且连续完整的内存空间;所有现代操作系统都使用虚拟内存,使用虚拟地址取代物理地址,主要有以下几点好处: - 多个虚拟内存可以指向同一个物理地址
- 虚拟内存空间可以远远大于物理内存空间
- 应用层面可管理连续的内存空间,减少出错
利用上述的第一条特性可以优化,可以把内核空间和用户空间的虚拟地址映射到同一个物理地址,这样在 I/O 操作时就不需要来回复制了
- NFS文件系统
网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS;NFS允许一个系统在网络上与它人共享目录和文件,通过使用NFS,用户和程序可以象访问本地文件 一样访问远端系统上的文件 - Copy-on-write
写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源
为什么要有DMA
在没有 DMA 技术前,I/O 的过程是这样的:
- CPU 发出对应的指令给磁盘控制器,然后返回
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个中断;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据一次一个字节地读进自己的寄存器,然后再把寄存器里的数据写入到内存,而在数据传输的期间 CPU 是被阻塞的状态,无法执行其他任务
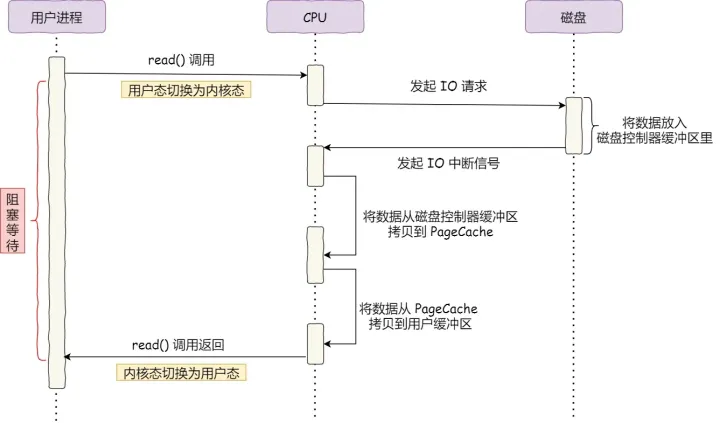
整个数据的传输过程,都要需要 CPU 亲自参与拷贝数据,而且这时CPU是被阻塞的;简单的搬运几个字符数据那没问题,但是如果我们用千兆网卡或者硬盘传输大量数据的时候,都用 CPU 来搬运的话,肯定忙不过来 计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(Direct Memory Access) 技术 简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务 具体流程如下图:
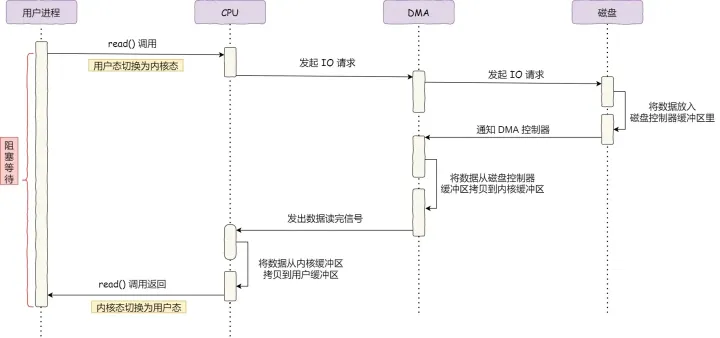
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,释放CPU
- DMA 进一步将 I/O 请求发送给磁盘
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 依然可以执行其它事务
- 当 DMA 读取了足够多的数据&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6203
6203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









