







一.什么是索引
1.使用select查询数据库中的数据时的步骤
首先,先遍历要查询的整个表,然后将表中的列带入到sql语句中的判断条件中看是否成立,如果条件成立这行数据会被保留,如果不成立会跳过。
这样的查询在表中的数据很多的时候,查询的成本太大了,因为数据库是将数据保存在硬盘上的,每读取一个数据,都需要读取硬盘。
2.索引
索引属于是针对查询操作引入的优化手段,可以通过索引来加快查询的速度,避免针对表的遍历。
使用索引也是有代价的:
占用更多的空间,生成索引,是需要一系列数据结构,以及一系列额外的数据,来存储到硬盘空间的。
可能会降低插入修改删除的速度。因为当我们在做这些操作的时候不光需要对表中的数据进行修改,同时也需要对数据所在的这一列的索引进行修改。
二.索引的操作
1.查看索引
show index from 表名;
2.创建索引 (危险操作)
create index 索引名字 on 表名(列名);(主键 unique 外键的列mysql会自动为其生成索引)
一个数据表可以具有多个索引,但是一个索引只能表中一个列,当对表中的一个列创建了索引后,在对这个列进行查询的时候速度会非常的快。
为什么是危险操作:
因为在创建索引的时候需要对现有的数据进行大规模的重新整理,如果在创建索引时,操作的对象是一个空表,那么不会产生任何问题,但是如果此时这个表具有很多的数据,就狠容易导致mysql数据挂掉。
一般来说,表索引的生成,一般是在设计表的时候,和表一起诞生的,一旦表中有了数据,在想修改索引,就要慎重了。

3.删除索引(危险操作)
drop index 索引名 on 表名;
三.索引的原理
索引也是通过一定数据结构实现的,数据库中引入的是一个改进的树形结构,B+树(N叉搜索树)。
1.B-树
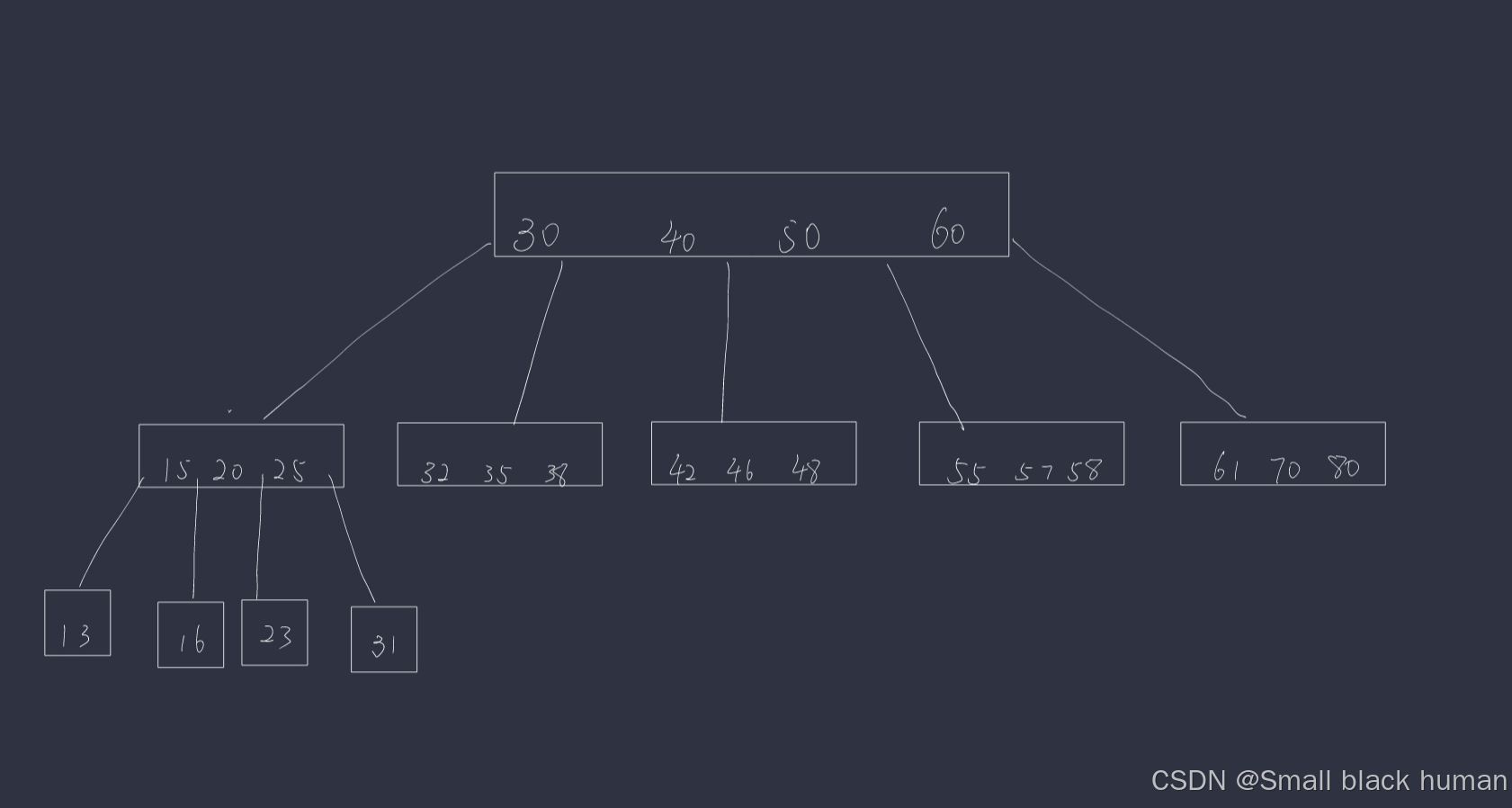
由于每个节点是在一个硬盘的区域中存储的,一次读取硬盘就读取出了整个节点(多个key)在进行几次比较(比较的效率是远远大于读取硬盘的效率的 读一次硬盘相当于进行了一万次比较)。
理论上一个B树的节点可以保存N个key但是也不是无限保存的,如果一个节点上的key过多会触发节点 的分裂,当删除导致节点上的key过少时会出发节点的合并。
2.B+树
下面的例子是典型的B+树,但是在进入数据库的时候会做不同程度上的优化。
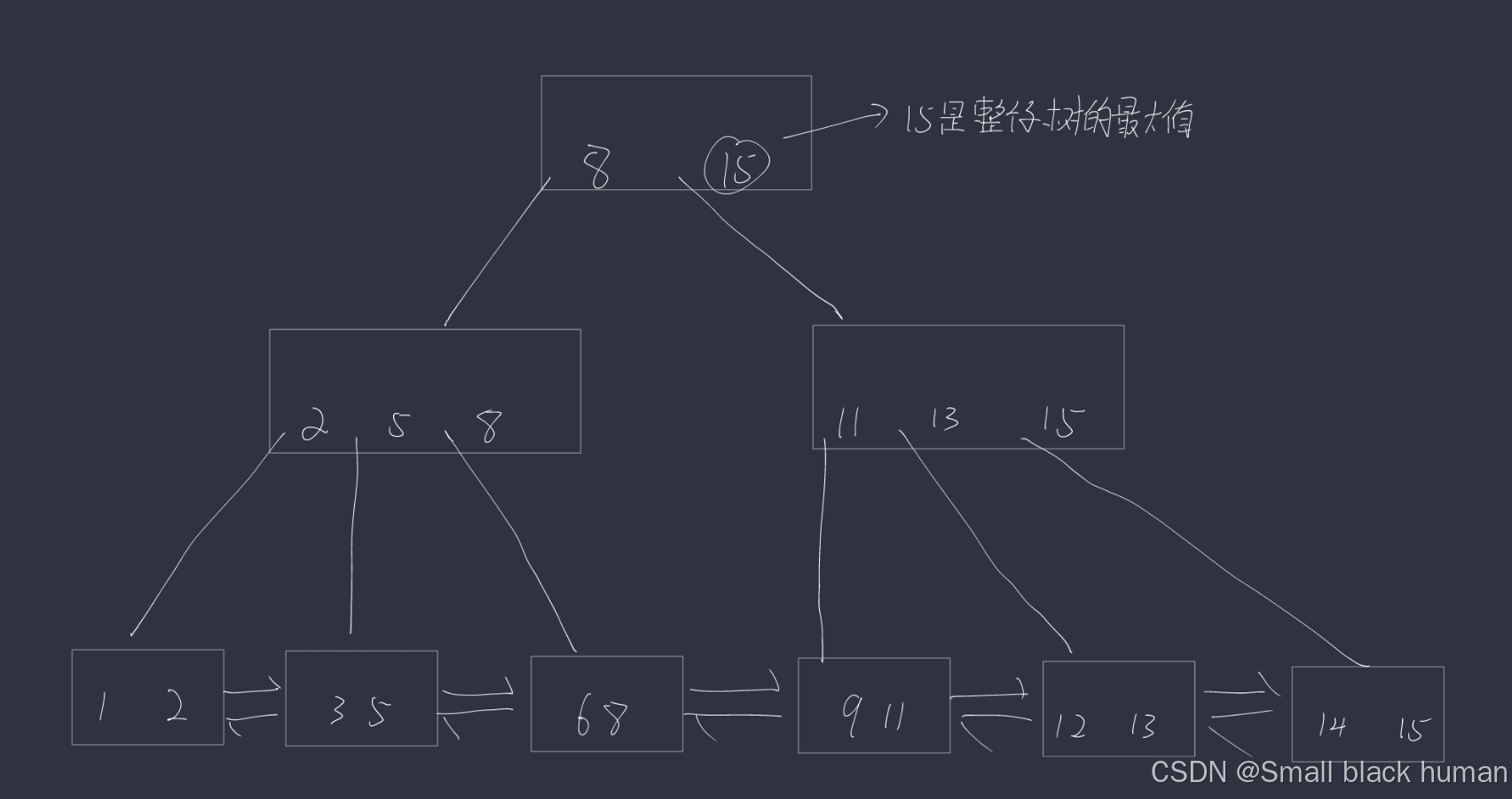
一个节点上有N个key,可以划分出N个区间, 每个节点上N个key最后一个就相当于当前子树的最大值,父节点上的每一个key都会以最大值的身份在子节点的对应区间中存在(key可能重复)。
叶子节点这一层,包含了整个树的数据全集。B+树会使用链表这样的结构将叶子节点串起来,此时可以非常方便的完成数据集合的遍历,并且也很方便的从数据集合中按照范围取出一个子集。
B+树的特点:
是一个N叉树 树的高度是有限的 可以降低io次数
非常擅长范围查询
所有查询最终都是要落到叶子节点上的 查询和查询之间的时间开销是稳定的,不会出现一次查询特别快一次查询特别慢的情况。
由于叶子节点是全集,会把行数据存储在叶子节点上,非叶子节点只是存储一个用来排序的key(比如id),数据库是按行组织数据的,创建索引的时候,是针对列进行创建的。
mysql索引的实现,也是有一些变数的,不是只有B+树这一种情况,MySQL内部有一个模块,叫存储引擎,是专门负债将数据库中的数据存储到硬盘上的,存储引擎的实现是提供了很多版本的,innodb是当前mysql数据库中常用的版本,是基于B+树实现的。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









