







Tomas Mikolov 等人在论文 Efficient Estimation of Word Representations in Vector Space 中提出了 CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model) 这两种用于训练词向量(word embeddings)的模型,并在 word2vec 工具中实现。两者都是基于上下文信息来学习词汇的向量表示,原理相似,具体的方法有所不同。
根据论文中这张图很容易看出两者区别,CBOW 是根据上下文预测中间词(多对一),Skip-gram 是根据中间词预测上下文(一对一)。后面解释一对一的意思。
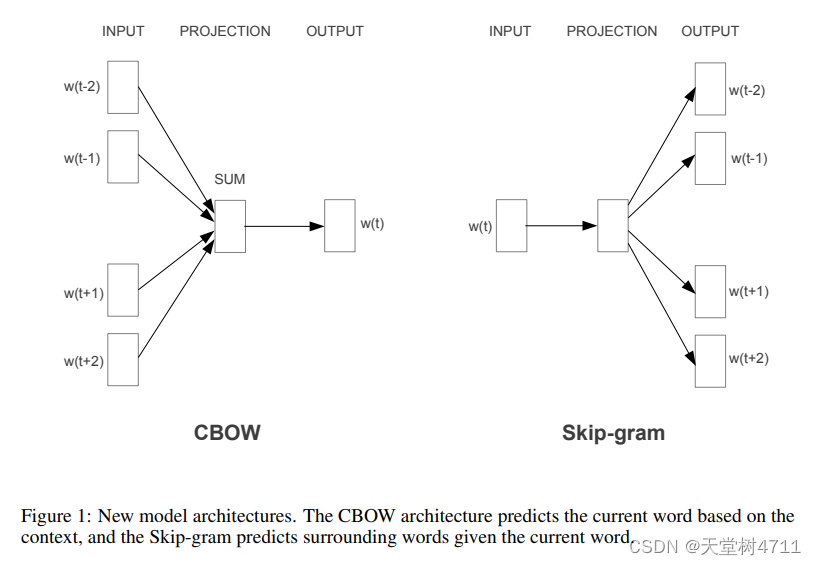
但是不理解为什么 skip-gram 可以只根据一个词就预测前后文,所以去查了源码的实现方式。
COBW + Hierarchical Softmax (hs)
//train the cbow architecture
// in -> hidden
cw = 0;
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c]; // 上下文词汇
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size]; // 词向量求和
cw++;
}
if (cw) {
for (c = 0; c < layer1_size; c++) neu1[c] /= cw; // 取平均
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];
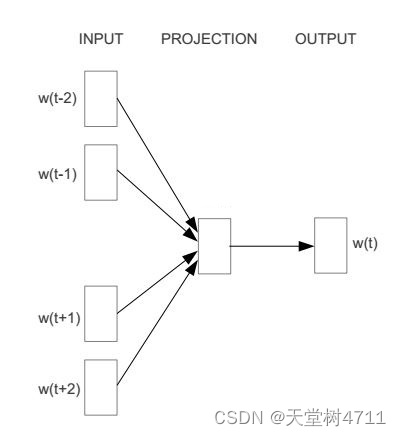
} CBOW 的原理与根据论文理解的一样:对于每个中心词 ,将窗口 window 内的上下文词
的词向量求和并取平均,再使用取平均后的词向量去预测中心词的词向量,同时计算误差和更新权重。注意上下文词向量求和取平均的过程是简单粗暴的,不考虑这些词之间的顺序。
Skip-gram + Hierarchical Softmax (hs)
//train skip-gram
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c]; // 上下文词汇
if (last_word == -1) continue;
l1 = last_word * layer1_size; // 上下文词汇的向量位置
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
// HIERARCHICAL SOFTMAX
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1];
}skip-gram 的实现过程是根据上下文的每一个词预测中心词,这似乎与图片描述相反,事实上也是这样,skip-gram 对于每个中心词 ,遍历其窗口 window 内的每个上下文词
,不包括中心词自己。对于每一个上下文词
,计算该词的词向量(在隐藏层中的向量)与中心词词向量(在输出层中的向量)的点积,同时计算误差并更新权重。
所以 skip-gram 实际上是在计算上下文每一个词与中心词的权重关系,并根据上下文预测中心词,如下图所示。这与原理并不矛盾,论文中没有介绍这一点,不过Tomas Mikolo 给出的解释是对于同一个句子来说,上下文和中心词的词对方向改变并不会影响这个句子的权重更新。这样做只是为了有效缓存,提高训练速度。
The different order does not change the updates you do for the whole sentence, just changes the order. The motivation was to use cache memory more efficiently, and have faster training.
论文中是这么介绍 skip-gram 的:不是根据上下文预测当前单词,而是利用上下文中的另一个单词对当前单词最大限度地进行分类。
The second architecture is similar to CBOW, but instead of predicting the current word based on the context, it tries to maximize classification of a word based on another word in the same sentence.
所以说 CBOW 是 “上下文词求和取平均做预测” 的 “多对一” 的过程,而 skip-gram 是 “ 中心词对每一个上下文词做预测” 的 “一对一” 的过程。这也正是 CBOW 比 skip-gram 训练快,而 skip-gram 对低频词训练效果更好的原因。

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









