






Machine learning algorithms
1.分类
-监督学习(supervised learning) -无监督学习(unsupervised learning) 强化学习(reinforcement learning) 前两者是最主要的
2. 监督学习
定义:学习x到y或输入到输出映射的算法 关键特征:提供学习算法实例以供学习,包括正确答案(给定输入x的正确标签y),通过查看输入x和所需输出标签y的正确对,学习算法最终只接受输入无需输出标签,并给出输出合理准确的预测
分类:
(1)回归(regression algorithm) 从无数可能数字中预测一个数字(房价预测)
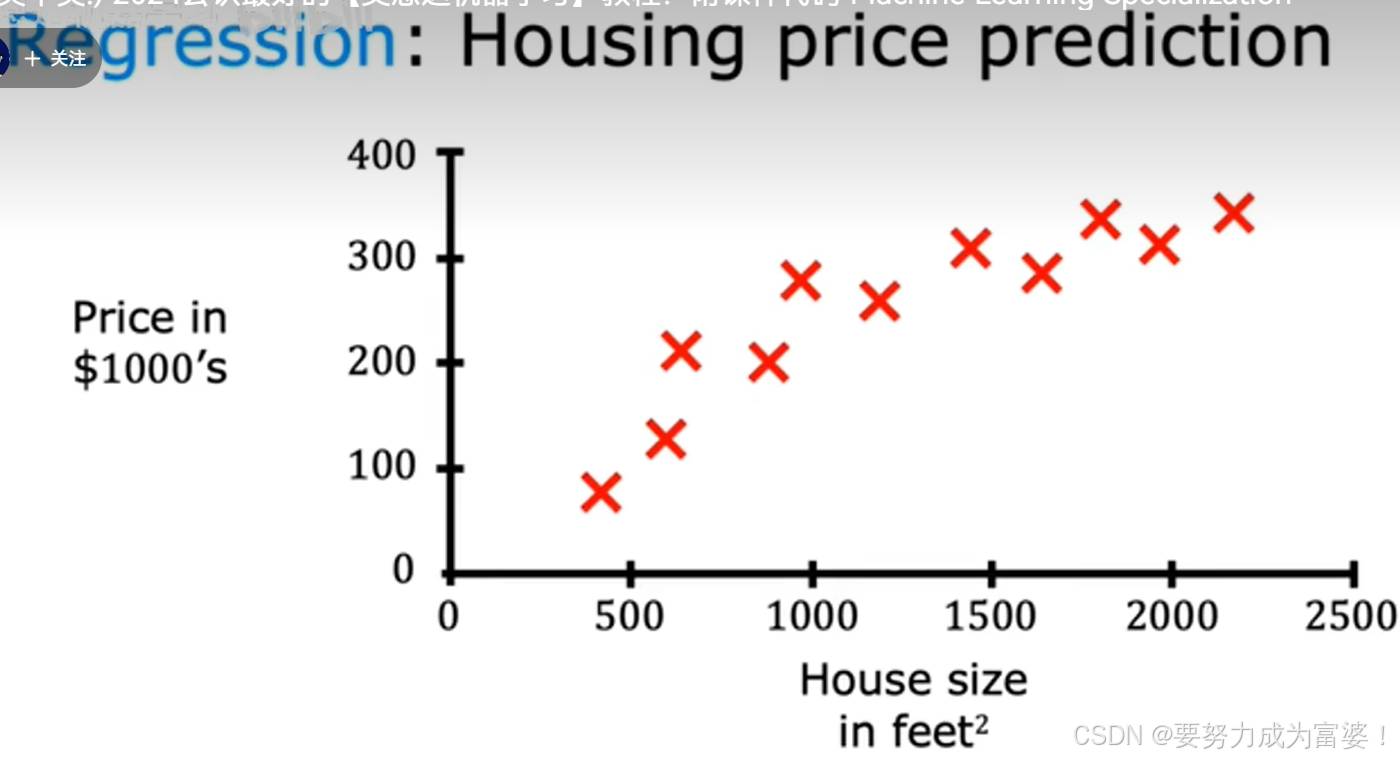
-
(2)分类(classification algorithm) 预测类别,不一定是数字(预测肿瘤恶性/良性)

二者不同之处,分类预测小的有限的一套可能输出类别
3.无监督学习
定义:数据仅带有输入x而没有输出标签y,并且算法要找出数据中的结构
-
聚类算法(clustering algorithm)
获取没有标签的数据并自动将它们分组到集群中(Google news) 相似数据点组合在一起
-
异常检测(anomaly dection)
检测异常事件(金融系统欺诈检测等)
-
降维(dimensionality reduction)
将大数据集压缩成小数据集,同时丢失尽可能少的信息
4.线性回归模型(Linear Regression Model)
基本概念和标准符号:
-
训练集:用于训练模型的数据集
-
x-输入变量/特征/输入特征
y-输出变量/目标变量
m-训练示例的总数
(x,y)单个训练示例
(x(i),y(i))第i个训练示例
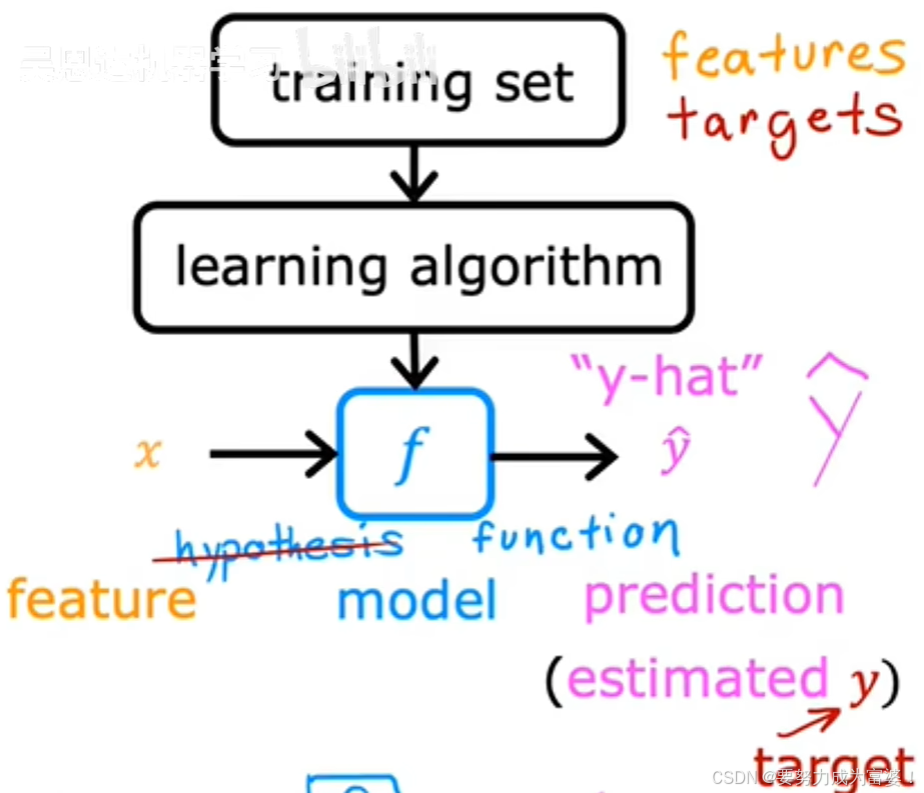
线性回归(也叫单变量线性回归)
-
具有一个变量的线性回归
-
fw,b(x)=wx+b 线性回归模型
w,b:参数/系数/权重(w就是直线的斜率,b就是截距)
成本函数(cost function/Squared error cost function平方误差成本函数)
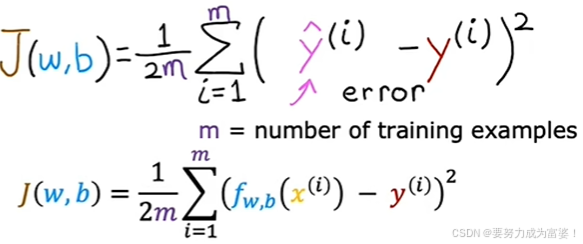
注意:×2是为了计算更简洁
-
目标:为了衡量w和b的选择与训练数据的拟合程度
-
用处:衡量模型预测与y实际真实值之间的差异
-
目标:选择尽可能使成本函数小的W!

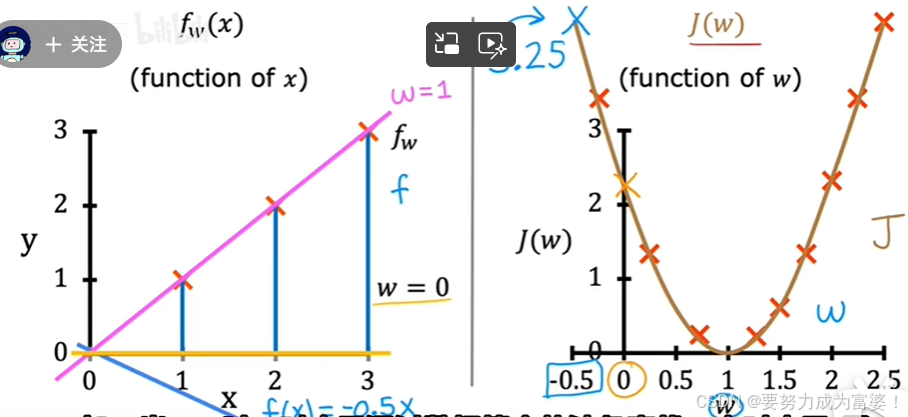
-
发现:只有一个参数W时,成本函数呈U形曲线;有两个参数W,b时,成本函数从二维变成了三维(碗状),J最小的时候就是最小椭圆的中心
梯度下降的算法可以用于训练线性回归模型
5.梯度下降
不仅用于线性回归,也用于神经网络模型,也成为深度学习模型

错误的是1324,先算出w再代入tmp_b,算出来的值不准确
ɑ是学习率,控制更新模型参数w和b时的步骤大小,后面一部分在机器学习中认为是导数
d J(W)/dw就是w-J函数图像的切线的斜率
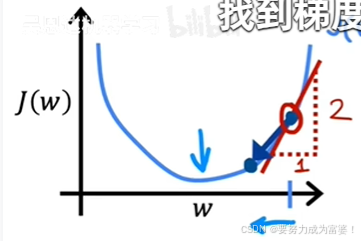
右侧部分,斜率大于0,ɑ大于0,w在减小,左移,直到找到J最小的地方。 左侧部分,斜率小于0,ɑ大于0,w在增大,右移,直到找到J最小的地方。
6.学习率
ɑ如果过小,需要大量迭代才能收敛,速度比较慢
ɑ如果过大,可能会超过最小值,跳到j更大的地方。大交叉可能无法收敛,甚至会发散。
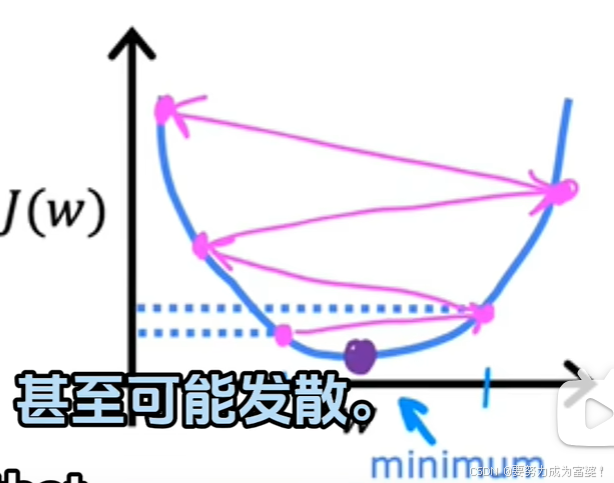
梯度下降可以到达局部最小值的学习率(不是全局最小值!)。梯度下降可以最小化任何成本函数,
越靠经局部最小值,导数会变小,更新步骤也会变小
7.线性回归中的梯度下降
线性回归模型,成本函数,梯度下降(把J(w,b)代入偏导数里面,再把f=wx+b代入,分别对w/b求导,就可以得到图右下的结果)

当使用线性回归的平方误差成本函数时,只有单一的全局最小值(形状是碗形,也就是凸函数convex function)
凸函数就是碗形函数,除了单个全局最小值(对数据拟合的比较好),没有其他局部最小值。
梯度下降被称为批量梯度下降(Batch gradient descent):梯度下降每一步会查看所有训练集

















 2885
2885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









