







 本文详细解析了Self-Attention机制,包括其计算过程和多头Self-Attention的应用。同时,介绍了Position Encoding在Transformer模型中的作用,以及Decoder层的结构和Loss函数的计算。文中还探讨了训练技巧,如平滑操作对模型泛化能力的影响。
本文详细解析了Self-Attention机制,包括其计算过程和多头Self-Attention的应用。同时,介绍了Position Encoding在Transformer模型中的作用,以及Decoder层的结构和Loss函数的计算。文中还探讨了训练技巧,如平滑操作对模型泛化能力的影响。
个人理解笔记,并不是全面讲解
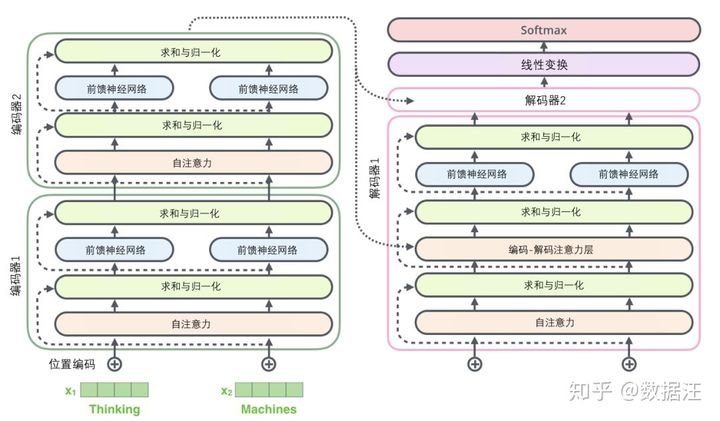
Self-Attention
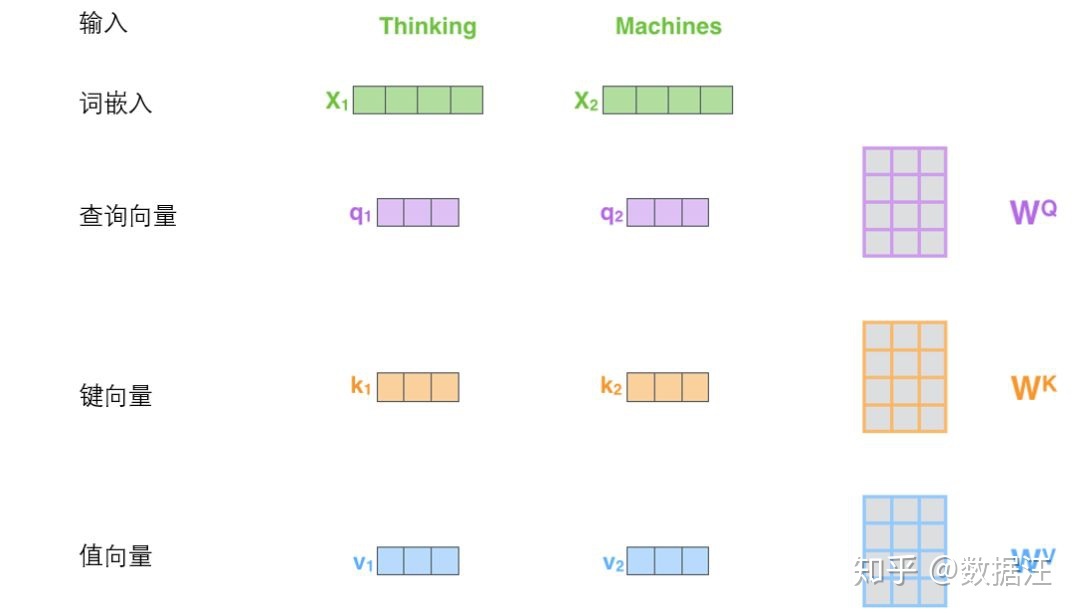
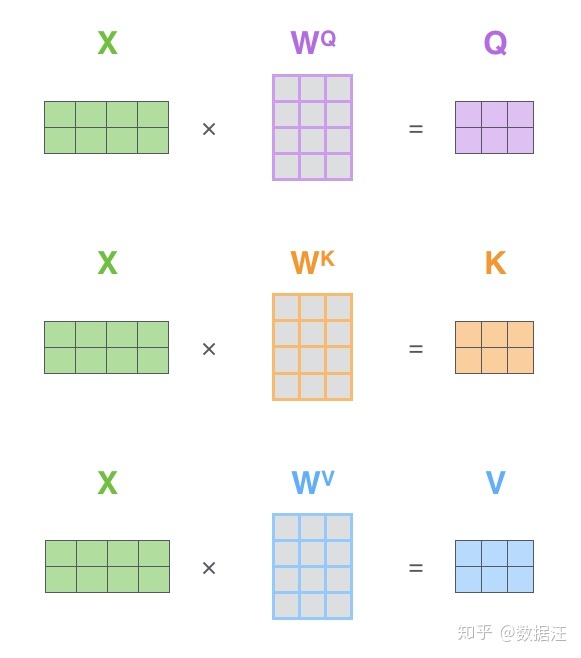
- 首先随机初始化Wq,Wk,Wv (个人认为W列对应神经元个数,行是单词的词嵌入长度)
- X(这里是好多个单词摆放成一个矩阵)乘W(qkv三个矩阵)得到对应的权重q,k,v(X每一行是一个0词)
- dk是键向量的维度
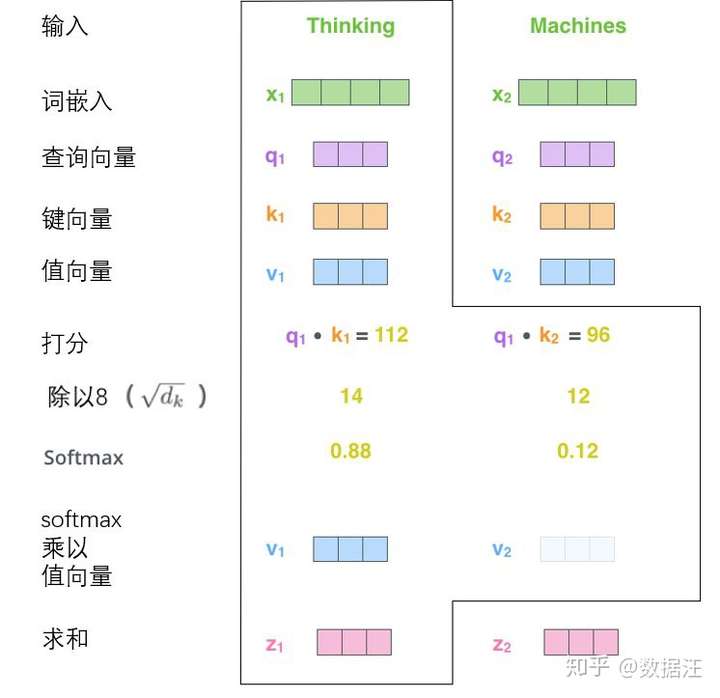
- 当前一个单词(X的每一行(这里单词按行堆叠)),(当前单词的)q与(与其他单词的)ki(这些k由其他单词x乘Wk得到)分别多次点积除以sqrt(dk)再softmax归一化后得到一个值(个人记作Si(每一个ki对应一个Si,也对应一个vi))
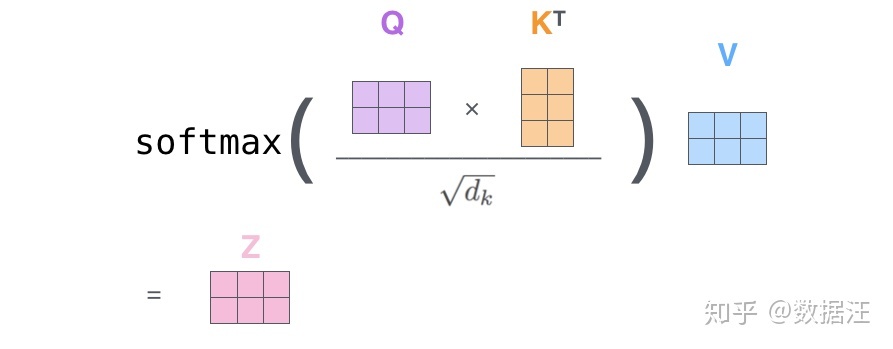
-
接下来就是
当 前 z = ∑ i S i ∗ v i ( v i 是 向 量 , 所 以 最 后 的 z 也 是 向 量 ) 当前z=\sum_{i}S_i*v_i(v_i是向量,所以最后的z也是向量) 当前z=i∑Si∗vi(vi是向量,所以最后的z也是向量)- 每个单词的z堆叠起来就是Z(上图粉色方块所示,每一行一个单词的z)
多头Self-Attention
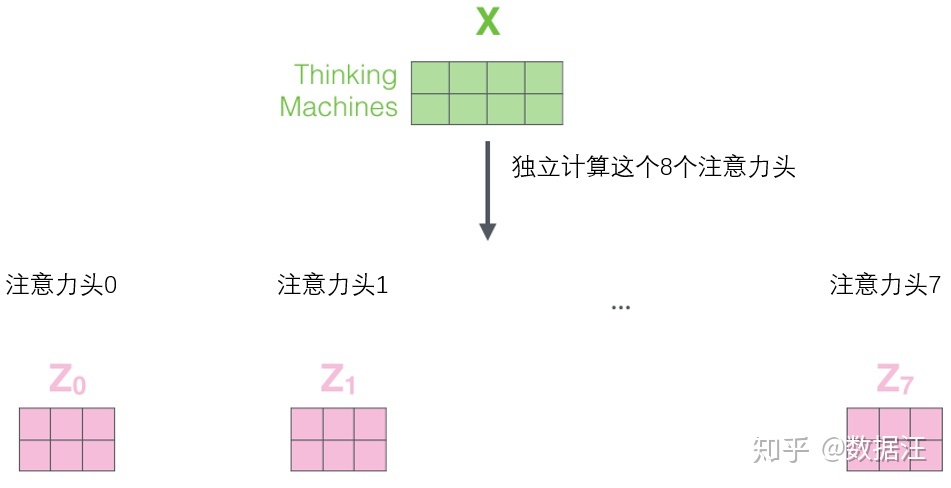
- 一个头就形成一个Z,多个头就记作Zi
- 直接拼接,乘一个Wo矩阵(学习得来)
Position Encoding
在下图中,每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。
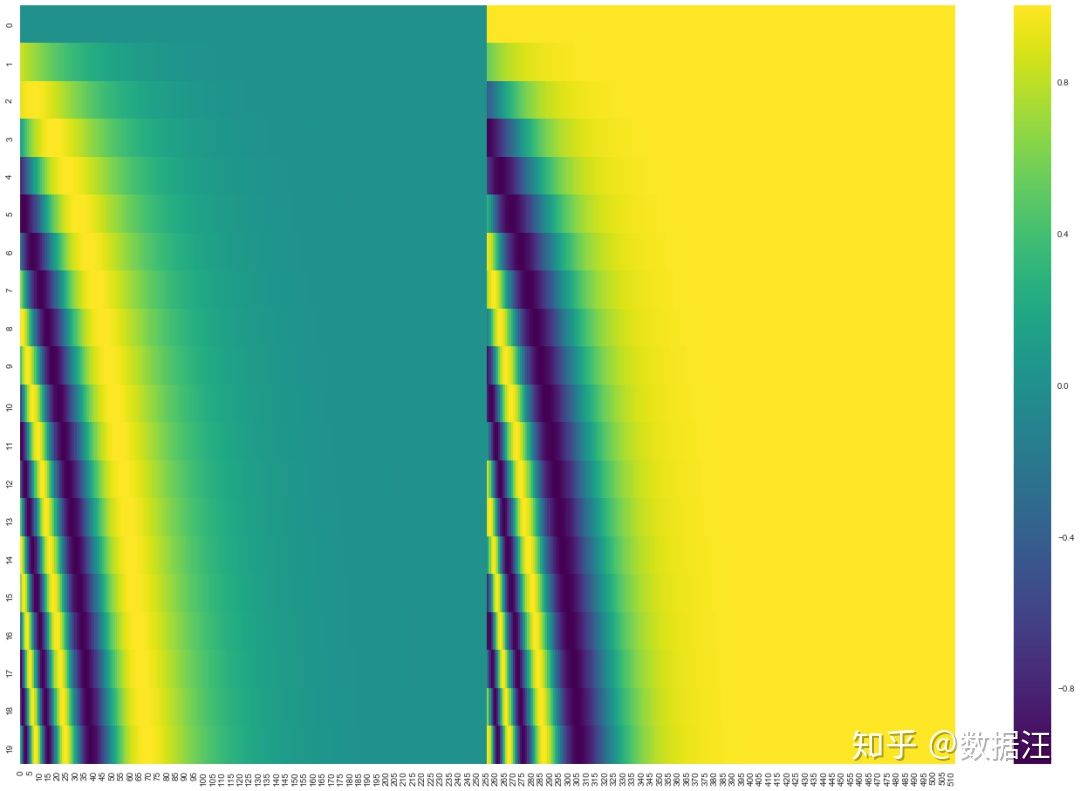
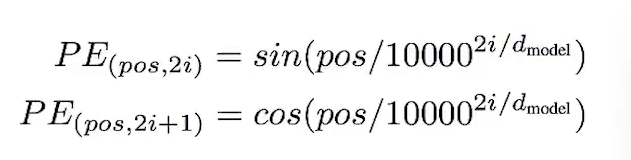
20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
Layer Normalization
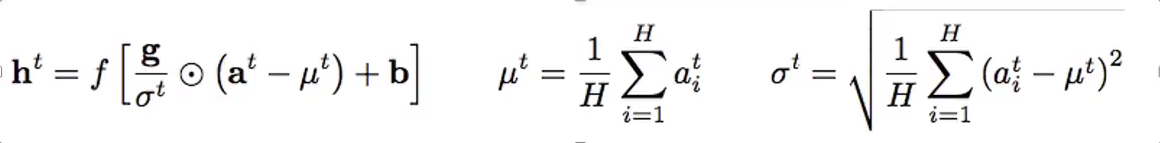
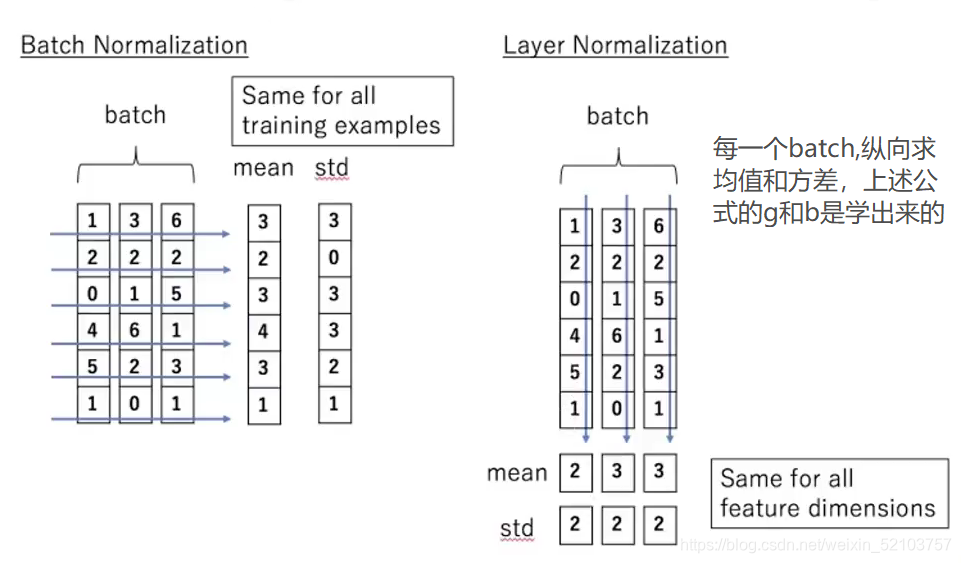
残差神经网络模块
- X和Z元素求和
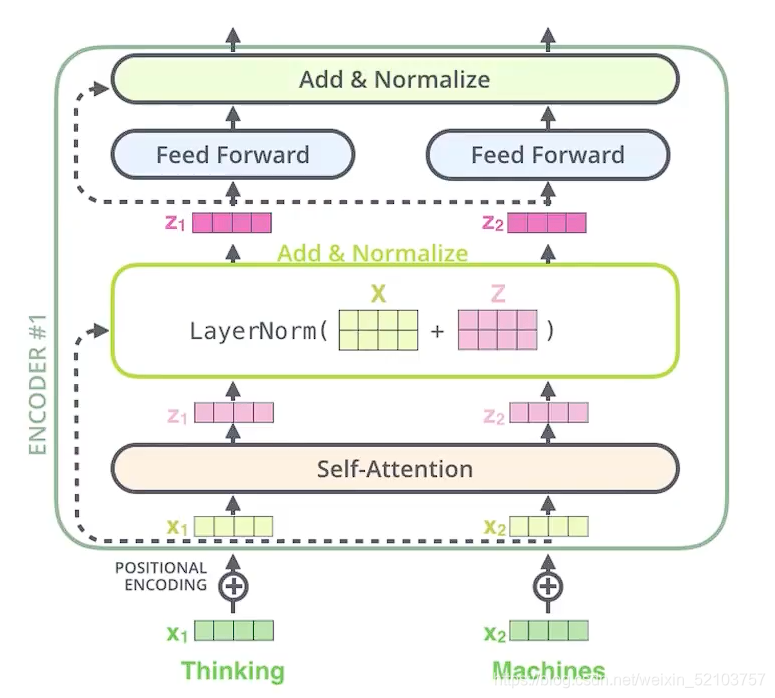
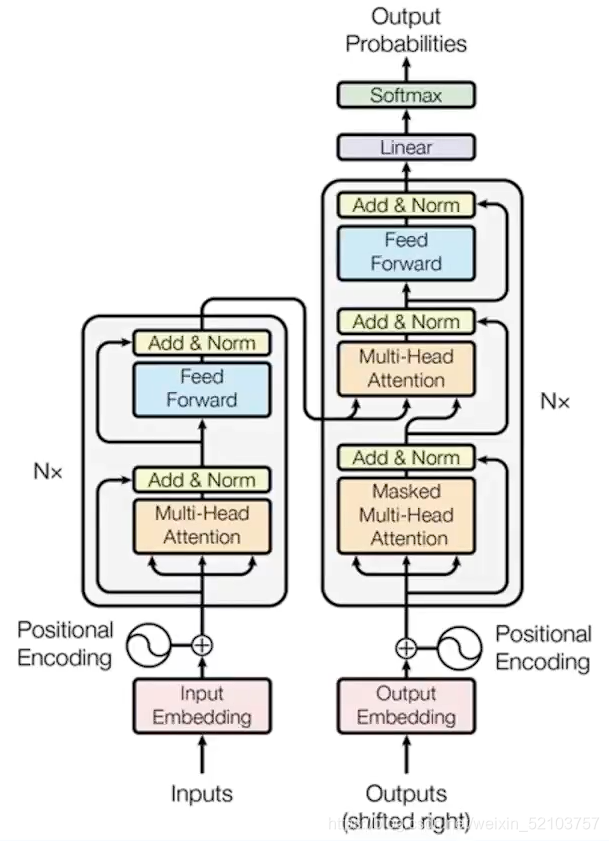
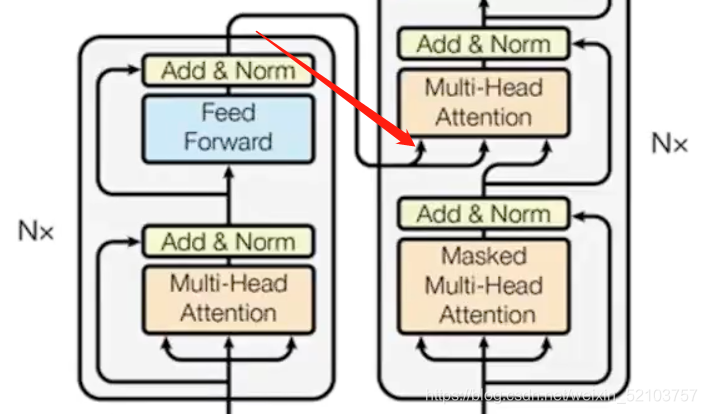
Decoder

- 当前时间点decoder需要有上一个decoder的输出(第一次的输入应该是有一个类似于<BOS>的向量)这是mask注意力层的
- 接着进入另一个自注意力层,这个层需要有从encoder的输出Z来得到(换言之: 顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 )
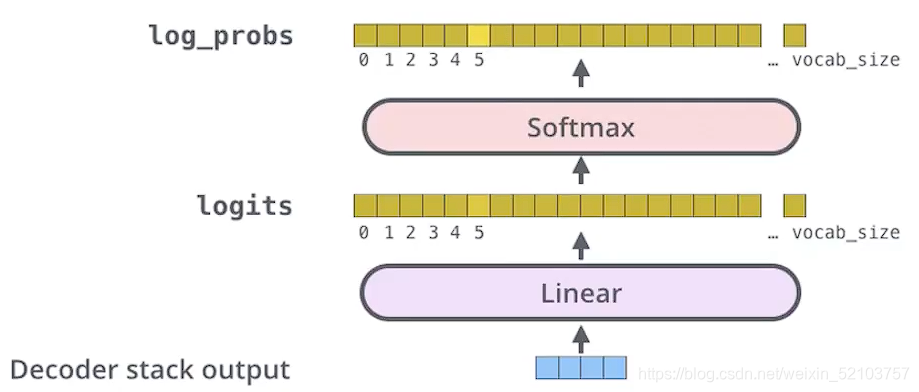
Loss
最后的输出是词库大小的向量,每个元素值[0, 1]
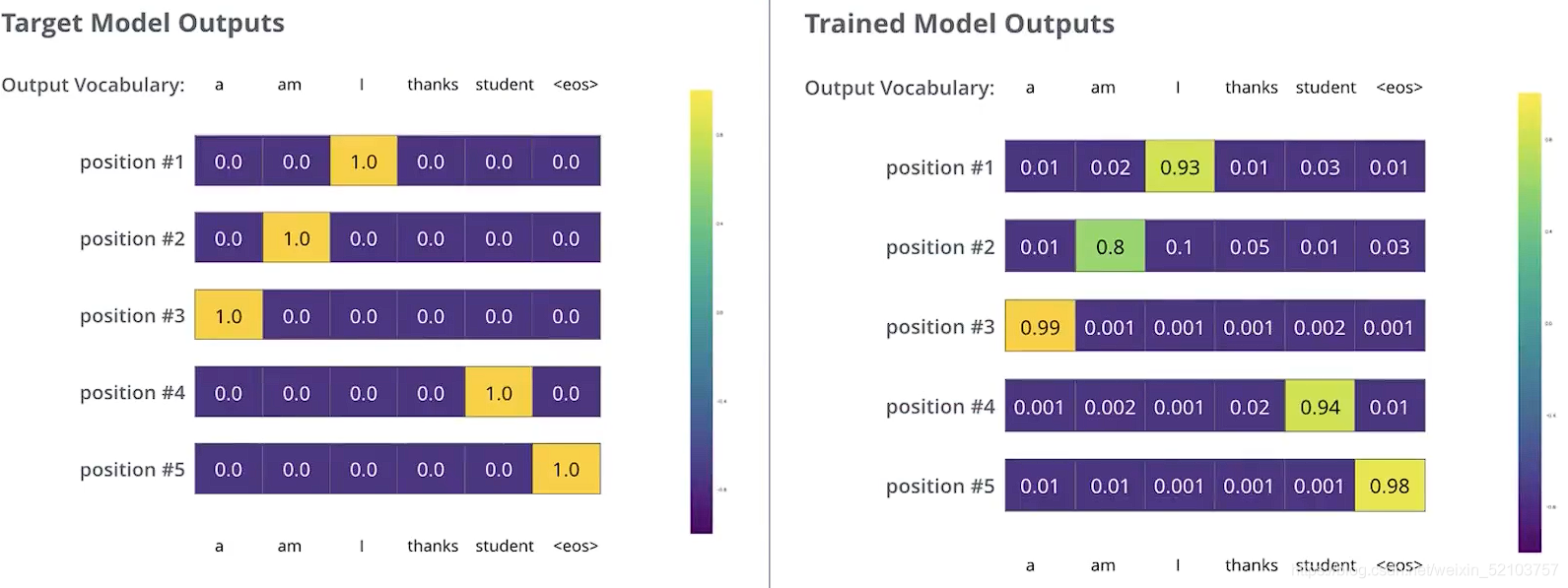
- 每个概率分布被一个以词表大小(例子里是6)为宽度的向量所代表。
- 第一个概率分布在与“i”关联的单元格有最高的概率
- 第二个概率分布在与“am”关联的单元格有最高的概率
- 以此类推,第五个输出的分布表示“<EOS>”关联的单元格有最高的概率
- 交叉熵orKL散度
训练技巧

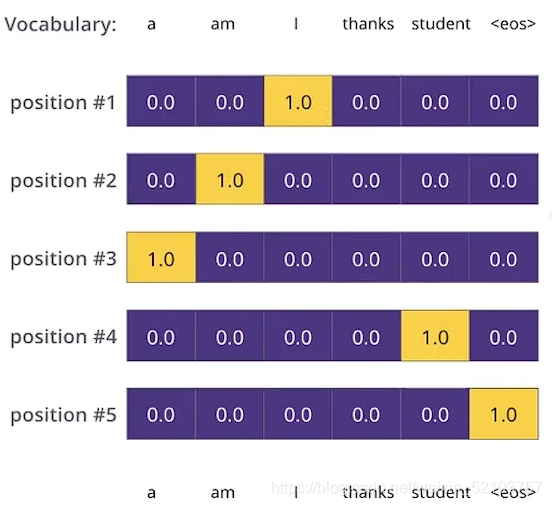
这是理论output,但是平滑操作之后,举例第一行的1会变成1-ε,然后ε再平分给该向量的其他元素,这样”说话不会太决绝“,”你可以预测出其他,但是我告诉你这个最大的最好“,实际上泛化效果会好



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











