




 本文深入解析Transformer模型,探讨其encoder和decoder结构,以及为何通过WQ,WK,WV矩阵转换q,k,v向量。解释多头注意力机制如何增强模型理解句子的能力,包括缩放点积注意力和位置编码的作用。
本文深入解析Transformer模型,探讨其encoder和decoder结构,以及为何通过WQ,WK,WV矩阵转换q,k,v向量。解释多头注意力机制如何增强模型理解句子的能力,包括缩放点积注意力和位置编码的作用。
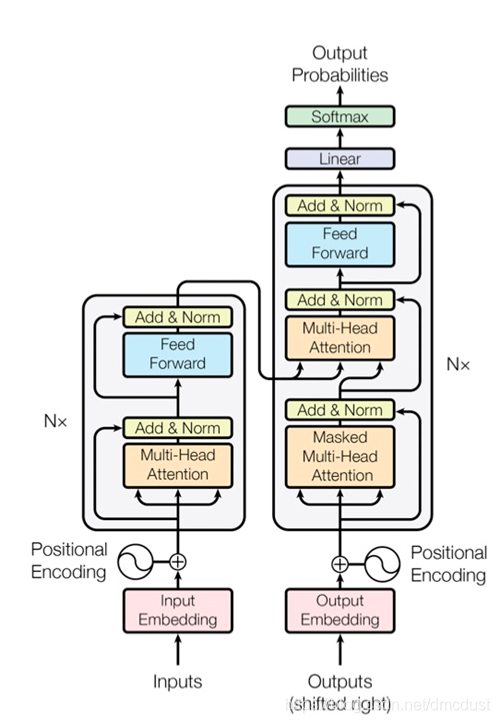
左边encoder ,右边是decoder

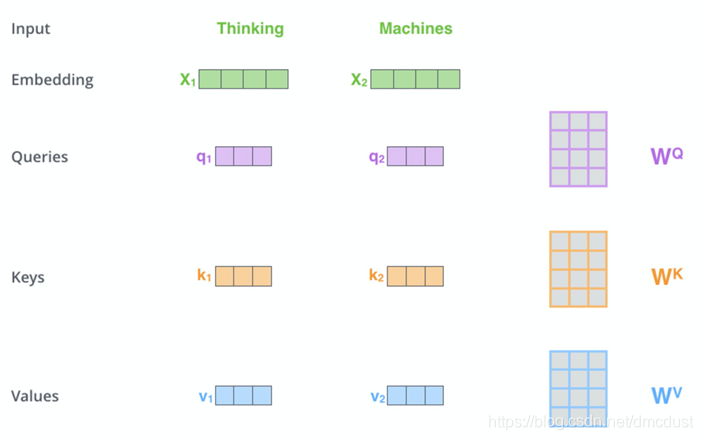
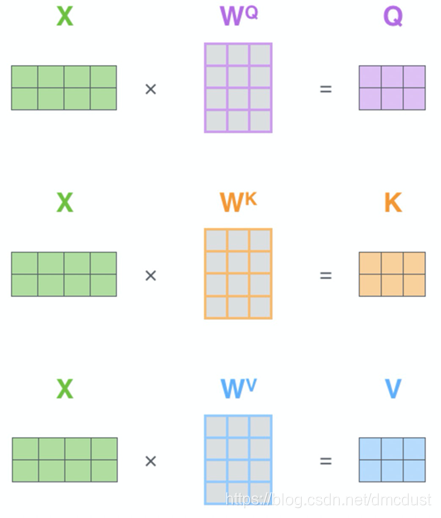
图中是4维 ,论文中是512,x 乘 WQ,WK,WV(随机初始化)得到 q (64维),k,v。
为何要乘 WQ,WK,WV 而不直接使用qkv
首先增加参数可以增加学习能力,如果没经过 WQ,WK,WV,则qkv一般就固定的值,后面q 乘 k的时候,两个相似度大的向量会得到很大的值
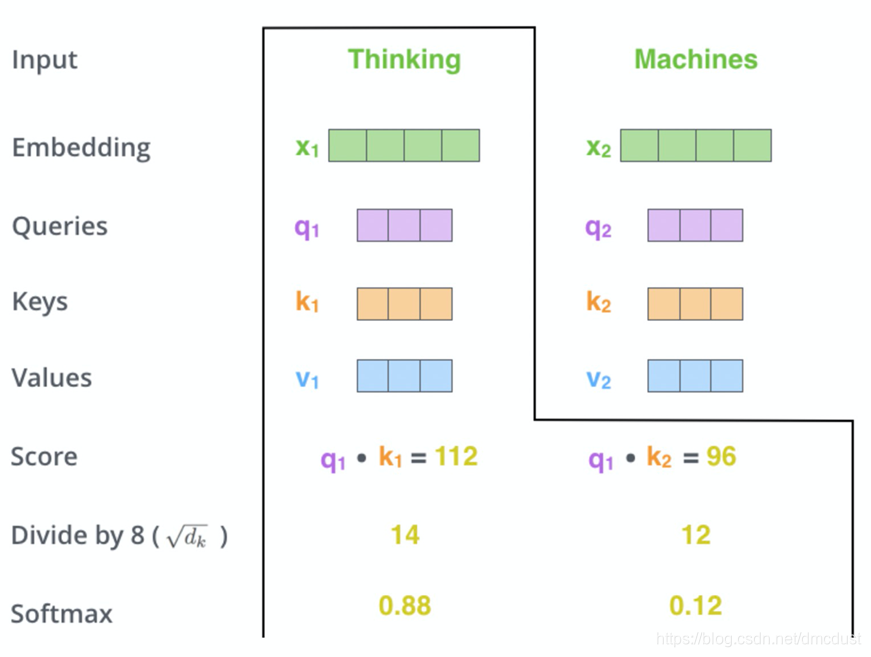
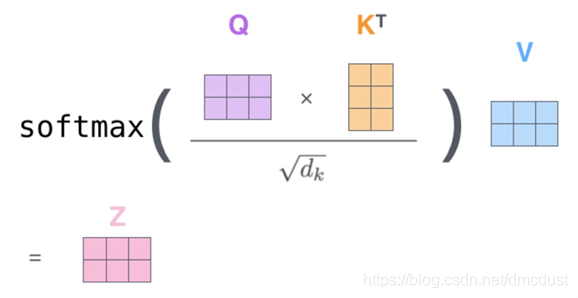
算thinking ,q1 成所有的 k , 要 ÷ dk 缩放, softmax 的值在乘 v
为何要缩放,对softmax影响太大,在softmax函数中x太大,函数的梯度趋于0,影响反向梯度计算。
transformer 的encoder 中不共享参数
下图是句子级别的计算
Multi-headed
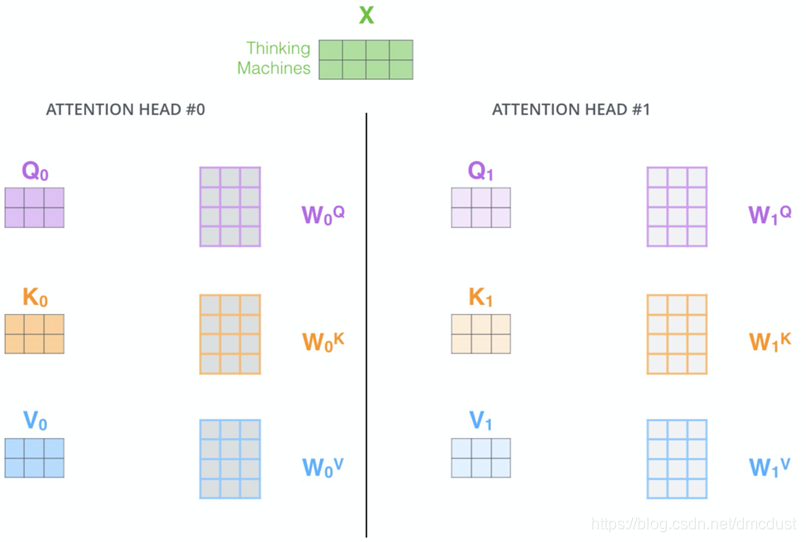
用多头注意力,因为随机处置话的QKV矩阵不同,所以每一头注意力关注句子不同的点(感觉和CNN的通道一样的)
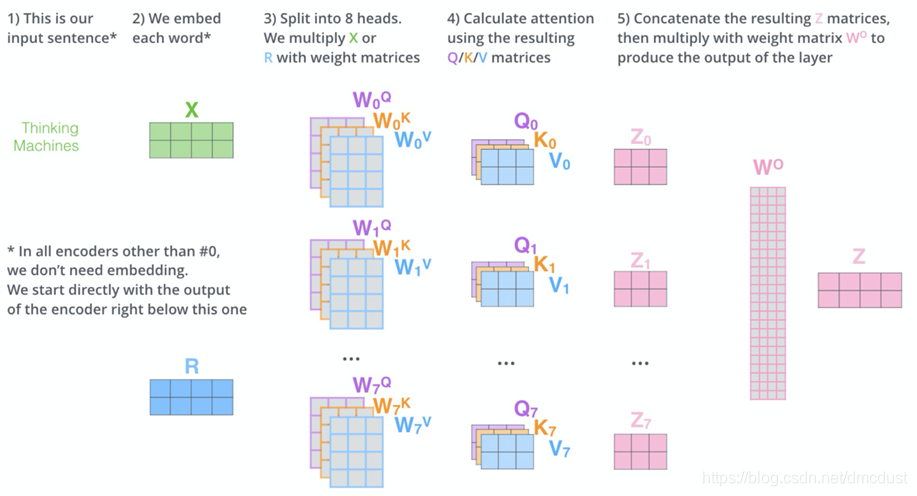
x 复制成8份 ,分别对应自己的QKV,得到八中情况的Z ,拼接后乘 W0 又变回 和输入一样维度的Z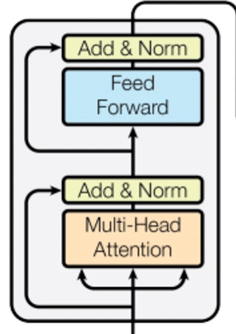
多头注意力后要layer norm与bitch norm 略有不同,但也是归一化,避免梯度消失
Feed Forward 两层 中间有relu ,最大的作用增加模型的非线性能力(实验对比 ,这里很重要)
再就是用了残差,层数过多,避免梯度消失,保留更多的特征
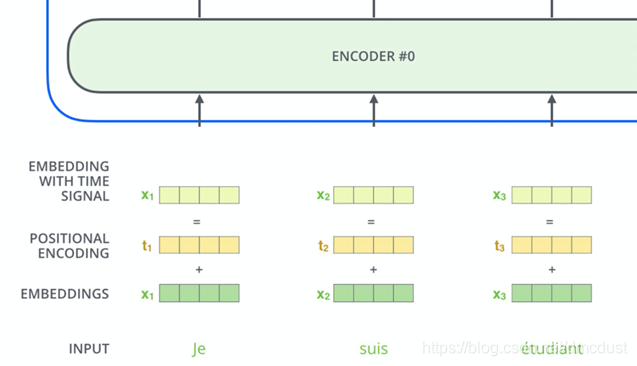
transformer 是双向结构,要加入位置信息表征顺序 ,这里直接和token embedding 向量相加
这里得到位置的函数使用的是正余弦的,具有周期性


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









