




 本文介绍了一种使用浏览器控制和爬虫技术抓取BOSS直聘上杭州市BI岗位信息的方法,包括获取岗位页面数量、遍历区域获取详情链接,并处理验证需求。作者还分享了如何通过企业微信聊天机器人实现自动暂停爬取并提示用户验证的操作。
本文介绍了一种使用浏览器控制和爬虫技术抓取BOSS直聘上杭州市BI岗位信息的方法,包括获取岗位页面数量、遍历区域获取详情链接,并处理验证需求。作者还分享了如何通过企业微信聊天机器人实现自动暂停爬取并提示用户验证的操作。
最新Boss直聘爬虫系统(在跟~)
BOSS直聘爬虫经常会限制IP,我们采取控制浏览器的方法获取源码爬取
例子:以爬取 杭州市 “BI“岗位为例
需要源码的关注公众号: “麻不辣清汤”

- 确定爬取的配置文件
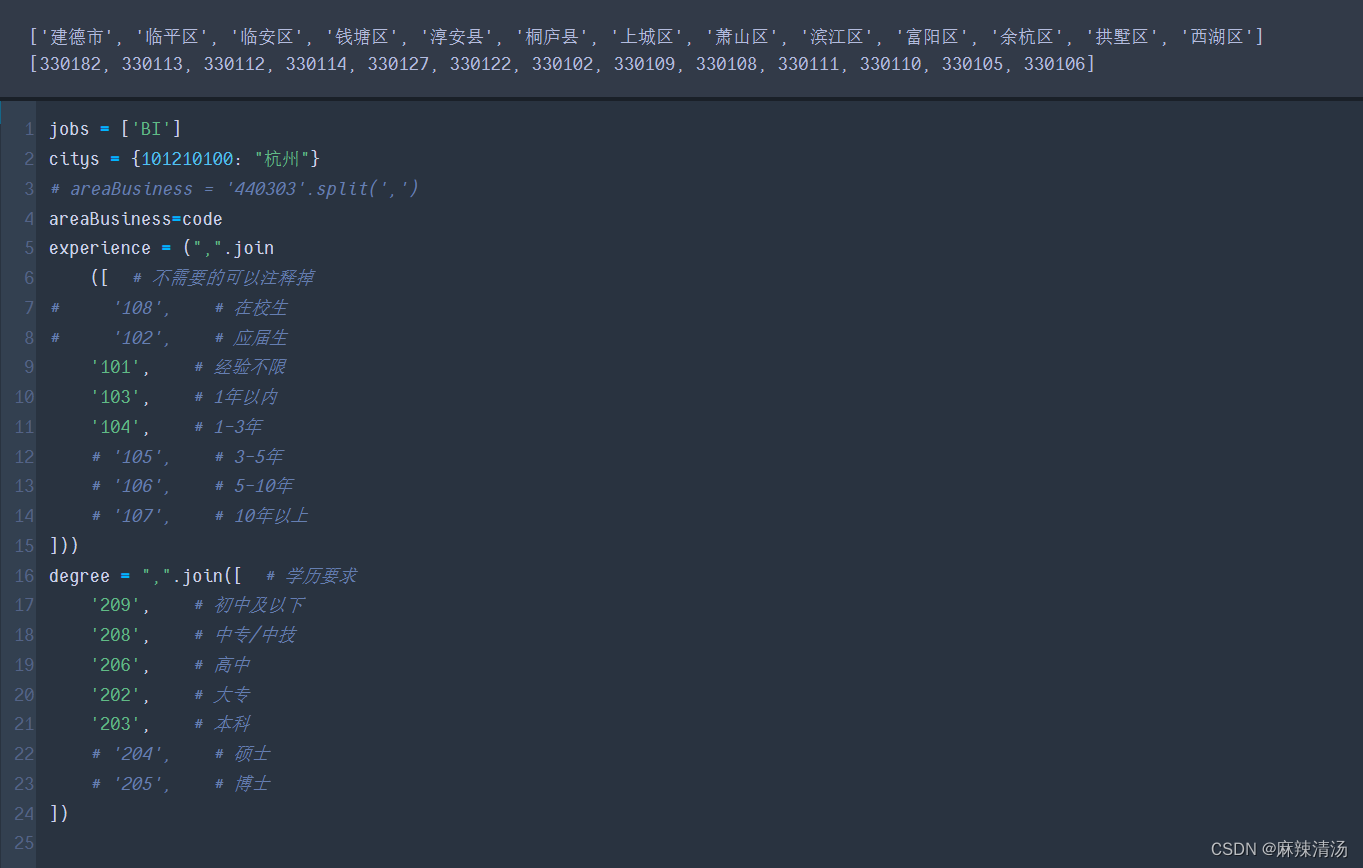
- 获取每个区域存在岗位页码的数量。方便后面遍历爬取
- 可以看到有些地区是没有BI岗位的,最多的岗位区域是330110,余杭区

功能2:获取所有岗位详情的链接,存在本地
根据上述获取到的每个地区存在的最多页面,遍历的时候使用这个值作为最终遍历数。
岗位详情链接=[]
page_start=1
page_end=2
for area in areaBusiness:
page_start = 1
# 获取页码值,如果没有匹配的行,则默认为None
page_values = 对应页码表[对应页码表['城市'] == area]['页码'].values
page_end = page_values[0] if len(page_values) > 0 else None
if page_end is None:
continue
for i in range(page_start,int(page_end)+1):
print(area, i)
url = f'https://www.zhipin.com/web/geek/job?query={jobs[0]}&city={城市代码}&areaBusiness={code}&experience={experience}°ree={degree}'
# 使用 Playwright 同步 API
'获取源代码'
boss.get(url)
WebDriverWait(boss, 10).until(EC.visibility_of_element_located((By.CLASS_NAME, "options-pages")))
time.sleep(0.5)
boss_text = boss.page_source
soup = BeautifulSoup(boss_text, 'html.parser')
# 找到类名为"options-pages"的<div>标签
options_pages_div = soup.find('div', class_="options-pages")
# 在这个<div>内部找到所有的<a>标签
a_tags = options_pages_div.find_all('a') if options_pages_div else []
# 从找到的<a>标签中提取文本,忽略空白和非数字内容
numbers = [tag.text.strip() for tag in a_tags if tag.text.strip().isdigit()]
# 获取最后一个数字,如果存在的话
last_number = numbers[-1] if numbers else None
job_card_left_elements = soup.find_all(class_='job-card-left')
for element in job_card_left_elements:
href = element['href']
full_link = 'https://www.zhipin.com' + href
岗位详情链接.append(full_link)
df=pd.DataFrame({
'Name':岗位详情链接})f
文件名='岗位详情链接_BI_杭州.xlsx'
df.to_excel(f"{文件名}")
功能三:遇到需要验证,自动暂停爬取,提示需要手动验证

BOSS直聘会对任何频繁用户进行验证
我们通过控制企业微信的聊天机器人来提示用户需要验证,验证完成之后再进行爬取,基本上不到1000条数据会有提示。
具体链接到:https://blog.youkuaiyun.com/weixin_52001949/article/details/137915839?spm=1001.2014.3001.5502
for i in 岗位详情链接["Name"][s:e]:
count=count+1
print(f"开始爬取{count}")
# 打开网页
url =f'{i}'
boss.get(url)
time.sleep(random.uniform(10,20))
#遇到需要验证的话执行qywx_message提示函数。 if("点击进行验证" in boss.page_source or "您暂时无法继续访问" in boss.page_source):
print("报错")
count_end=count
qywx_message()
input()
boss.get(url)
time.sleep(random.uniform(10,20))
detail_code = boss.page_source
'执行爬取'
df = pd.concat([df, start_paqu(detail_code)], axis=0)
df.to_excel(f"{文件名}_爬取到{s}-{e}.xlsx")
else:
detail_code = boss.page_source
df = pd.concat([df, start_paqu(detail_code)], axis=0)
df.to_excel(f"{文件名}_爬取到{s}-{e}.xlsx")


















 3976
3976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









