






 本文详细介绍了在Linux环境下搭建Hadoop集群的步骤,包括关闭防火墙和SELinux,配置免密登录,同步配置文件,设置环境变量,以及配置Hadoop相关XML文件。同时,文章还列举了可能出现的问题及解决方案,如防火墙未关闭、配置文件路径不一致等,并提供了问题排查和解决方法。
本文详细介绍了在Linux环境下搭建Hadoop集群的步骤,包括关闭防火墙和SELinux,配置免密登录,同步配置文件,设置环境变量,以及配置Hadoop相关XML文件。同时,文章还列举了可能出现的问题及解决方案,如防火墙未关闭、配置文件路径不一致等,并提供了问题排查和解决方法。
思路:
1.准备3台虚拟机(静态IP,IP映射,主机名称,防火墙关闭,普通用户创建 等等)
2.安装JDK,配置环境变量
3.安装Hadoop,配置环境变量
4.配置免密登录
5.编写同步脚本,配置集群
(前三步已完成)
搭建集群步骤
1.首先要关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld

2.还要关闭SELinux
SELinux是Linux历史上最杰出的安全子系统。
SELinux的作用:
- SELinux 使用被认为是最强大的访问控制方式。
- SELinux 赋予了用户或进程最小的访问权限。也就是说,每个用户或进程仅 被赋予了完成相关任务所必须的一组有限的权限。通过赋予最小访问权限, 可以防止对其他用户或进程产生不利的影响。
- SELinux 管理过程中,每个进程都有自己的运行区域,各个进程只运行在自 己的区域内,无法访问其他进程和文件,除非被授予了特殊权限。
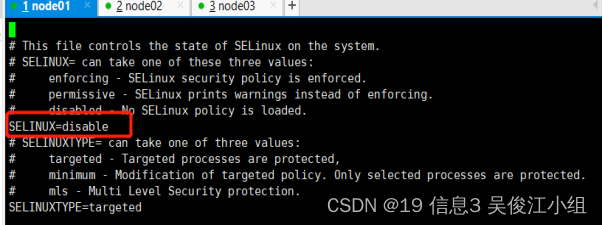
- SELinux关闭:
打开/etc/selinux/config文件 把SELinux的值设置为disabled
3.再有就是免密登录
主节点登陆到从节点中这时候可以免密
免密步骤:
- 每台机器都生成密钥:运行命令ssh-keygen -t rsa输入命令后需要三次回撤
- 检查生成情况 less /root/.ssh/id_rsa.pub (root用户下)
- Copy三台机器的密钥到第一台机器上ssh-copy-id node01
- 检查copy情况 less /root/.ssh/authorized_keys
- 将node01的认证复制到另外两台机器上
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
完成免密:使用ssh命令访问某个机器
一.创建安装目录
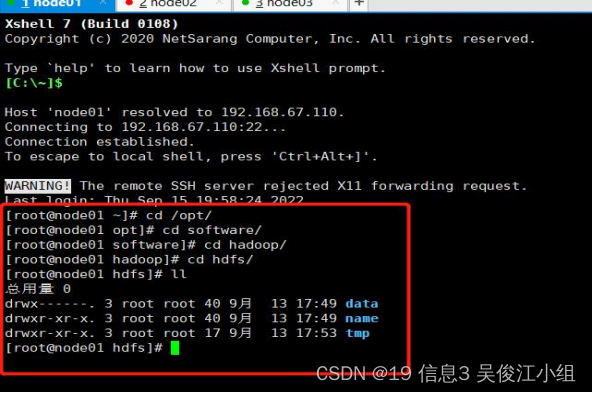
二.在hadoop目录上传文件(cd /opt/software/hadoop/)
首先安装插件— yum -y install lrzsz
rz上传hadoop-2.9.2.tar.gz
三.压缩文件
tar -xvzf hadoop-2.9.2.tar.gz

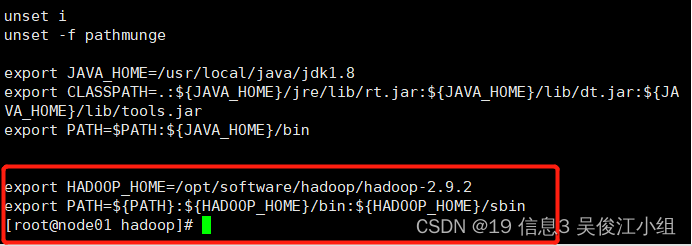
四.配置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
五.测试Hadoop是否安装成功
① 刷新—source /etc/profile
② hadoop version
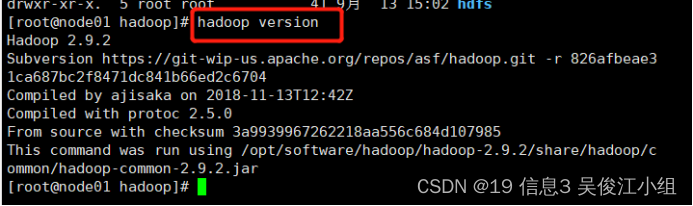
Hadoop的配置文件一共分为两类:一类是默认的配置文件,一类是自定义的配置文件,大部分配置我们都可以采用默认配置文件,只有当用户想要修改默认的配置值的时候,才需要去修改自定义配置文件,更改对应的配置值即可。
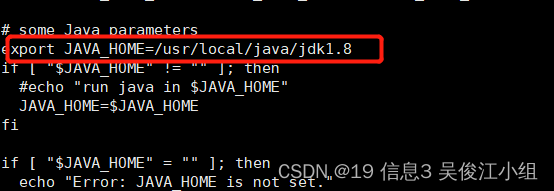
六.配置hadoop-env.sh(无需新增,修改里面的JAVAHOME值和HADOOPCONF_DIR的值)
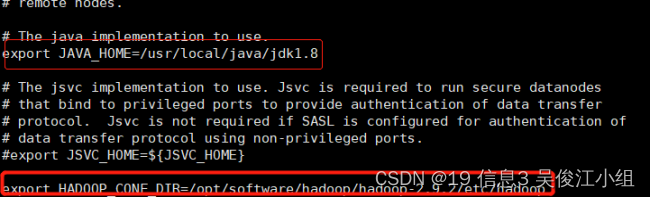
七.配置yarn-env.sh(新增JAVA_HOME值)
在export JAVAHOME=/home/y/libexec/jdk1.6.0/这行下添加JAVAHOME配置
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/路径下
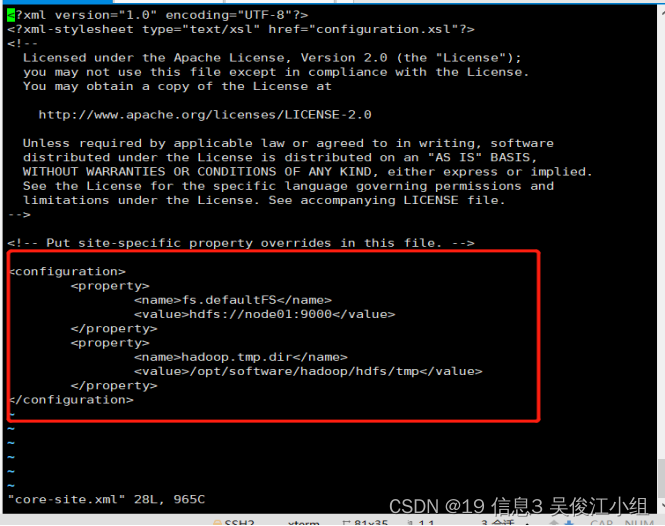
八.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hdfs/tmp</value>
</property>
</configuration>
九.配置hdfs- site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
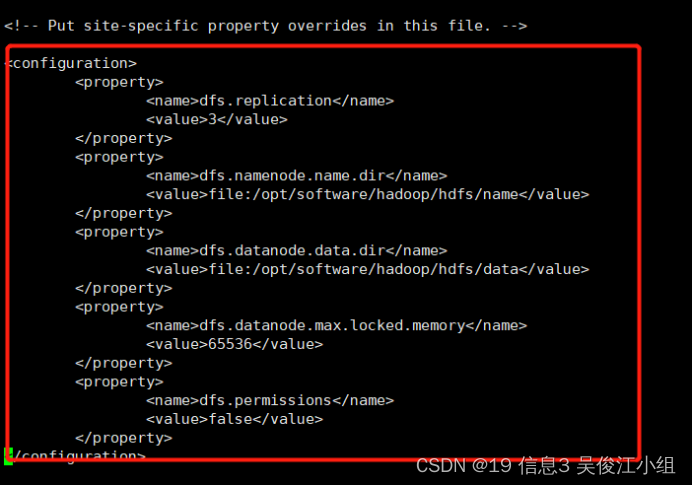
十.配置mapred-site.xml
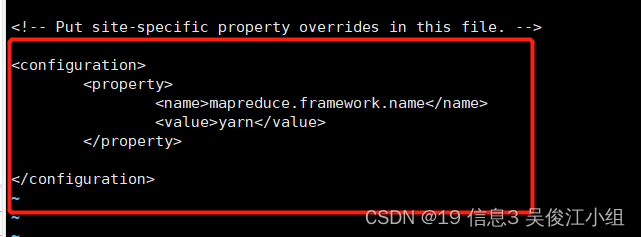
十一.配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
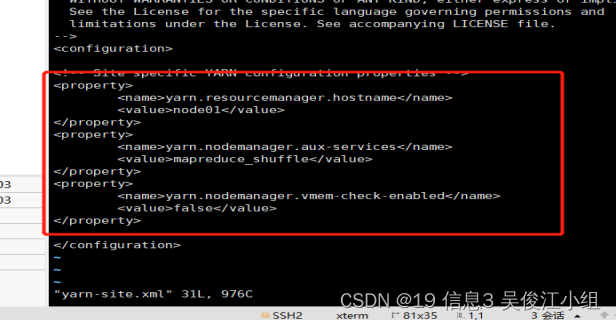
十二.配置3台机器主机名—slaves 此配置表示三台机器都作为DataNode
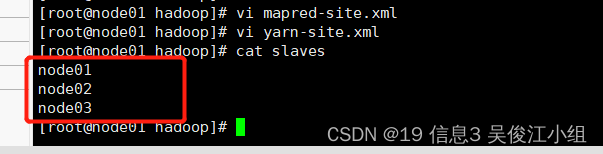
十三.同步配置信息
在node02和node03上创建/opt/software目录
十四.把node01上的配置同步到node02和node03同步命令:
scp -r hadoop/ node02:$PWD
scp -r hadoop/ node03:$PWD
十五.之前只在node01上配置了hadoop环境变量,现在需要在node02和node03上添加hadoop环境变量
在node02和node03机器的/etc/profile环境变量中添加hadoop配置
vi /etc/profile
十六.配置以后要加载配置文件,让配置文件生效
source /etc/profile
十七.启动集群
要先格式化—hdfs namenode -format
然后启动—start-dfs.sh(只需在node01上启动即可)
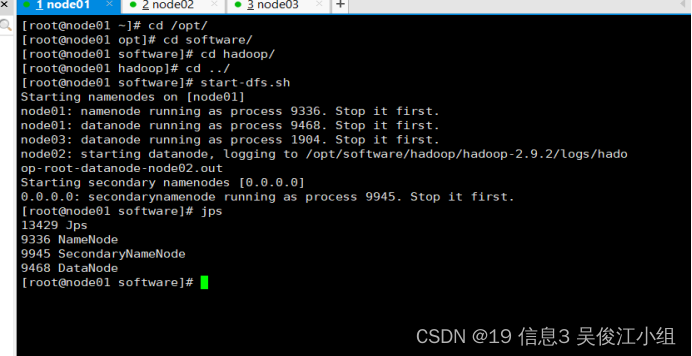
十八.查看启动情况
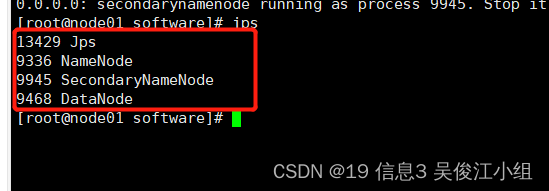
node02和node03上各有1个进程
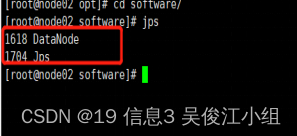
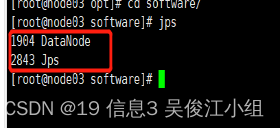
十九.访问网页
http://192.168.67.110:50070/
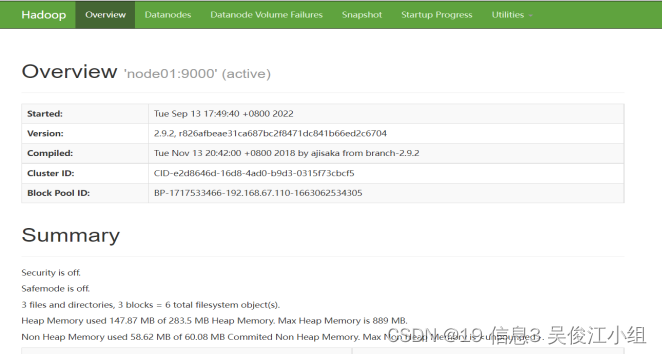
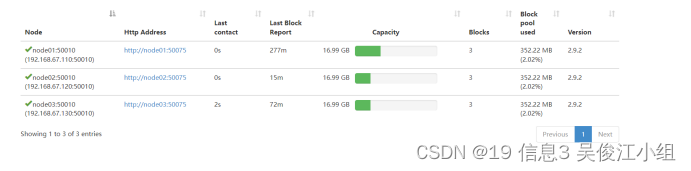
二十.上传文件测试
①创建目录:hdfs dfs -mkdir /test


②创建hdfs文件—上传hadoop-2.9.2.tar.gz

③检查datanode

常见问题总结
1.网络配置:确认好VMware生成好的网关地址
虚拟机关闭时在VMware页面点击编辑进入虚拟网络编辑器选择NAT模式点NAT设置然后进入网关IP
接着确认VmNet8网卡已经设置好了IP地址
把IP地址设置为192.168.67.110
网关和之前看到网关地址必须保持一致192.168.67.2
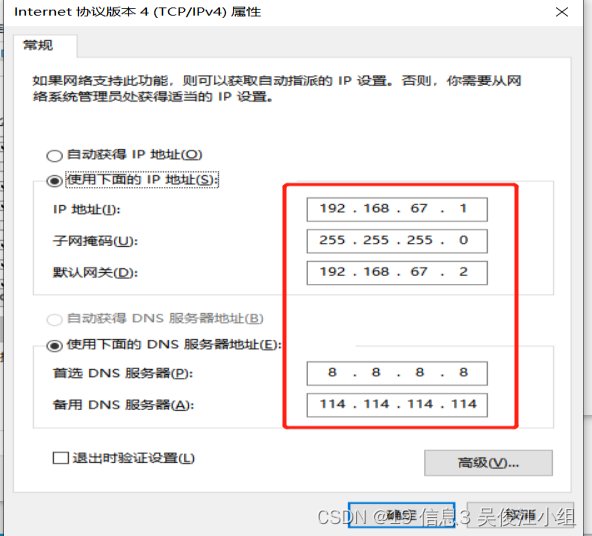
- ip地址时要正确修改vi /etc/sysconfig/network-scripts/ifcfg-ens33(ens33这一块要根据自己的虚拟机编辑)
2.识别不到主机名称要检查hosts文件—vi /etc/hosts里是否添加
192.168.67.110 node01 node01 hadoop.com
192.168.67.120 node02 node02 hadoop.com
192.168.67.130 node03 node03 hadoop.com
在windows里的hosts文件里也需要添加保存
C:\Windows\System32\drivers\etc\hosts
192.168.67.110 node01
192.168.67.120 node02
192.168.67.130 node03
注意:中间是否有空格。
3.HDFS完全分布式集群搭建以后,通过start-dfs.sh命令启动集群失败,很大一个原因就是服务器防火墙未关闭的原因。可以通过satemctl stop firewalld命令关闭防火墙然后再重新启动。
4.jps 发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在 Linux 的根目录下/tmp 目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
5.集群启动不了:使用hdfs namenode -format格式化也没用
第一种可能是配置的文件路径不一致导致出错 首先要删除掉配置错的文件,统一配置到一个路径下重新配置。
第二种是因为关机等原因系统删除了tmp文件中的name,使得namenode不能启动。
解决办法1:如果secondarynamenode安装在了另一台机器,可以使用secondarynamenode恢复:
第一步删除 namenode主节点的metadata配置目录:rm -fr /data/dfs/name
第二步重启集群,
第三步使用hdfs namenode -format
解决办法2:使用hdfs namenode -format格式化namenode所在的机器
6.同步配置信息时使用scp命令进行同步
把第一台机器(node01)上的配置同步到另外两台(node02和node03)
同步的时候如果一台机器需要输入密码这时报错是因为这台机器免密登录没有设置成功
解决方法:在需要输入密码这台机器中再一次操作免密登录。
7.如果节点上的 datanode没有启动 成这个问题的原因可能是使用hdfs namenode -format格式化时格式化了多次造成的
解决方法:停止集群—stop-dfs.sh
删除所有节点在hdfs中配置的data目录下面的所有数据;
重新格式化—hdfs namenode -format
重新启动集群—start-dfs.sh
查看进程—jps
8.启动集群访问网页时连接不了这时可以查看在前面添加的 hosts文件,是否添加错误。
9.上传文件测试时在DataNode节点某个机器的基本单位显示的是0原因是没关闭防火墙去关闭防火墙重新启动即可。
10.jps不生效
原因:全局变量hadoop version没有生效
解决办法:需要source /etc/profile

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









