






简介
本章节主要介绍FFT原理,以及Xilinx的FFT IP使用说明做详细介绍。
FFT介绍
FFT主要是将时域信号转换成频域信号,转换后的信号更方便分析。首先,FFT是离散傅立叶变换 (DFT) 的快速算法,那么说到FFT,我们自然要先讲清楚傅立叶变换。先来看看傅立叶变换是从哪里来的?
傅立叶原理表明:任何连续测量的时序或信号,都可以表示为不同频率的正弦波信号的无限叠加。而根据该原理创立的傅立叶变换算法利用直接测量到的原始信号,以累加方式来计算该信号中不同正弦波信号的频率、振幅和相位。当然,这是从数学的角度去看傅立叶变换。
那么从物理的角度去看待傅立叶变换,它其实是帮助我们改变从传统的时间域分析信号的方法转到从频率域分析问题的思维,下面的一幅立体图形可以帮助我们更好得理解这种角度的转换

所以,最前面的时域信号在经过傅立叶变换的分解之后,变为了不同正弦波信号的叠加,我们再去分析这些正弦波的频率,可以将一个信号变换到频域。有些信号在时域上是很难看出什么特征的,但是如果变换到频域之后,就很容易看出特征了。这就是很多信号分析采用FFT变换的原因。另外,FFT可以将一个信号的频谱提取出来,这在频谱分析方面也是经常用的。
傅立叶变换提供给我们这种换一个角度看问题的工具,看问题的角度不同了,问题也许就迎刃而解!
FFT IP说明
通过VIVADO打开FFT IP,如下图所示:

congfiguration界面
该界面主要设置生成FFT的基础信息,如下图所示:

1、输入数据通道数,一般单通道即可;
2、输入数据转换成FFT的数据长度,这里FFT的长度决定了精度,例如波形采样率不变的情况下,FFT的点数越多那么频域的精度越高;
3、系统输入数据时钟频率;
4、FFT内部结构,内部逻辑资源由高到低,计算时延由低到高,可以根据设计需要选择。不同的选择可以得出处理一帧数据所需要的时间,详情在latency窗口有显示,如选择Radix-4模式的时延如下:

上图表示Radix-4在256个有效FFT转换模式下时延是7.809us。
四种模式下吞吐量和资源消耗量如图:

implementation界面
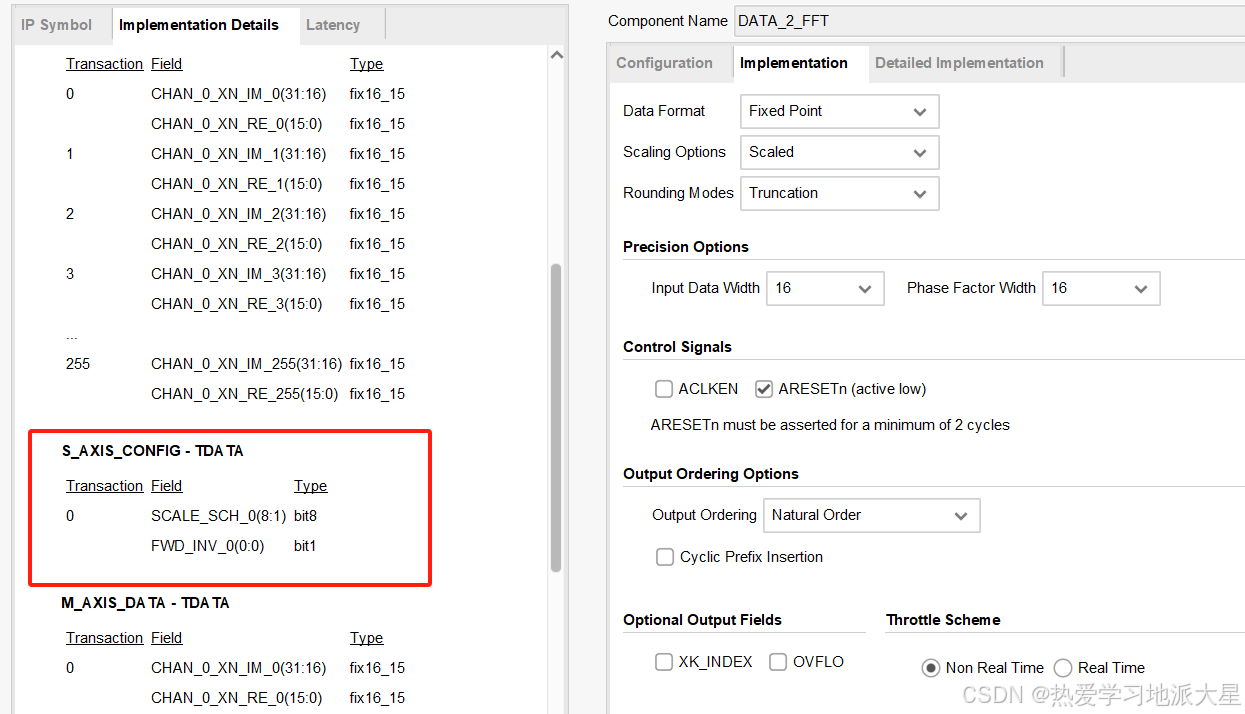
该界面对接口信息特征做配置

1、定点数据或者浮点数据输入,FPGA不论是ADC采样或者滤波都是16进制定点,这里一般选择定点输入;
2、对输出的数据进行等比例缩放设置;
Unscaled:正如其名,对 FFT IP 中的数据不应用任何缩放。这会导致输出中出现位增长。在此情况下,输出精度将包含整数部分,LSB 中的增长将被截断或舍入。此时,输出精度为“Fix(C_INPUT_WIDTH + C_NFFT_MAX + 1, C_INPUT_WIDTH - 1)”,其中,给定的“C_NFFT_MAX”为 log2(maximum FFT point size)。
Scaled:通过在每个 FFT 阶段中对位元执行右移,从而使 FFT IP 的输出缩小。每个阶段的相移量是使用 scaling_sch 来设置的,并使用 FFT IP 上的“配置接口 (Configuration interface)”来提供此相移量。为每个阶段提供足够的缩放时请务必谨慎,否则,可能会发生溢出,导致数据卷绕。一旦发生溢出,则可能导致无法继续在应用中使用这些数据。(PG109) 描述了 Vivado 中的 FFT IP、C/Mex 模型和 System Generator 中的 FFT IP 块的缩放调度字段的宽度和格式。
Block Floating point (BFP):在此模式下,核会自动判定缩放值,它会以最佳方式使用可用动态范围,并避免溢出。输出精度与输入精度相同,即 Fix((C_INPUT_WIDTH,C_INPUT_WIDTH - 1)。核所应用的位元右移总数的输出结果为“m_axis_data_tuser”接口和“m_axis_status_tdata”接口上的指数值 (blk_exp)。缩放因子计算方式为 (2^blk_exp)。由于该核自动计算缩放值,它会使用附加资源,从而导致资源计数比“scaled”模式下的资源数更高。
关于SCALE_SCH,最核心的点是不保证数据溢出的前提下,尽可能保持数据的精度,缩放不够数据溢出会发生错误,缩放过多,则数据过小,会降低精度。
PG109(关于FFT IP的datasheet) 还描述了适用于每种 FFT 架构类型的保守缩放调度方法。此缩放调度可避免所有数据类型出现溢出。
关于SCALE由输入信号S_AXIS_CONFING做配置,结构如下:
FWD_INV的取值:
| 数值 | 含义 |
|---|---|
| FWD_INV = 1 | FFT |
| FWD_INV = 0 | IFFT |
SCALE_SCH位宽:
对于基-2架构,宽度为2* NFFT,如对于128长度,宽度为2*log2(128)=14,其中,NFFT=log2(N),这是因为对于基-2FFT算法,会有log2(N)级蝶形运算,每一级都需要有缩放。
对于流水线架构或基-4架构,宽度为2* ceil(NFFT/2),如对于1024长度,2* ceil(NFFT/2)=2* ceil(log2(1024)/2)=10,其中ceil是向上取整。本设计选用256个点做FFT,带入公式计算长度为8bit。
SCALE_SCH取值:
官方取值定义如下:

如果变换长度N不是4的幂次方时,最后一组只包含一个基2阶,只能用00或者01表示
参照数据手册的说明,下面举例说明scaled的设置方法:
设 N=512: 由于变换长度N不是4的幂次方,最后一组只包含一个基2阶,只能用00或者01表示, 设scaled的位宽是8位: XX(阶3) XX(阶2) XX(阶1) XX(阶0)
a、设置 scaled=8'b 00 11 11 11 ----- 赋值合理,表示压缩 2^(3+3+3)=2^9=512 倍 ;
b、设置 scaled=8'b 11 11 11 11 ----- 赋值不合理,最高阶只能是00或者01,不能是11;
设 N=1024: 由于变换长度N是4的幂次方,对最高阶的赋值没有要求,设scaled的位宽是10位:XX(阶4)XX(阶3) XX(阶2) XX(阶1) XX(阶0)
a、设置 scaled=10'b 11 00 11 10 00----- 赋值合理,表示压缩 2^(3+0+3+2+0)=2^8=256倍,但是不提倡这种赋值方式,N点最好压缩N倍,所以1024个点最好压缩1024倍。
b、设置 scaled=10'b10 10 10 10 10 ----- 赋值合理,表示压缩 2^(2+2+2+2+2)=2^10=1024倍 。
对scaled进行赋值之后,IP核的输出结果可进行移位还原为真实值,这样就可以将输出结果放到MATALB等数学工具中,对自己的输出结果进行直观的图示验证。
根据手册描述一般情况下SCALING配置如下:

3、收敛四舍五入或者截断(truncation);
4、输入数据位宽,这里只用输入I,Q(虚部和实部)一路的位宽,不需要输入组合起来的位宽。在Fixed Point模式下,输入数据位宽与相位因子位宽相等。由s_axis_data_tdata接口输入,假设两者位宽都为16位,则MSB[31:16]为相位因子,LSB[15:0]为输入数据。
相位因子即虚部。大多数情况下我们处理的数据都为实数,所以在高位补0即可。如果做IFFT或其他需要虚部的情况,则可将实部和虚部分别输入。
5、时钟使能跟复位信号,复位信号拉低最少要保持两个时钟周期。
6、输出的频谱数据还要做fftshift,这个跟fft算法流程有关系,这里设置为顺序输出;
7、Optional Output Fields: 输出的索引信号和overflow信号,勾选后这些信息会跟频谱数据一起输出,可以直观在仿真波形中查看自己的scaled是否设置合理,如果设置的数值不够大,ovflo会溢出显示为高电平。
8、选择性能和数据定时之间的折衷要求。实时模式通常提供更小、更快的设计,但对何时必须提供和使用数据有严格的限制;非实时模式没有这样的限制,但设计可能更大、更慢。一般选non real time即可。
Detailed implemetation界面
如下图所示:

1、memory选择内部BRAM还是逻辑资源,默认BRAM即可;
2、优化性能,如果无特殊要求的默认设置即可。
实际用例
仿真代码
通过DDS产生一个时钟频率为100M,频率为20M的正弦波信号,然后经过FFT转换,FFT的点数为256,代码激励如下:
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2024/09/03 17:26:05
// Design Name:
// Module Name: fft_tb
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module fft_tb(
);
reg sys_clk;
reg sys_rst_n;
reg aresetn;
wire[15:0] DDS_TDATA;
wire DDS_TVALID;
reg s_axis_config_tvalid;
reg DDS_TLAST;
reg[15:0] DDS_cnt;
reg[31:0] fft_tdata;
reg fft_tvalid;
reg fft_tlast;
wire m_axis_data_tvalid;
wire m_axis_data_tlast;
wire[31:0] m_axis_data_tdata;
always #5 sys_clk = ~sys_clk;
initial begin
sys_clk = 'd0;
sys_rst_n = 'd0;
aresetn = 'd0;
s_axis_config_tvalid = 'd0;
#2000;
sys_rst_n = 'd1;
#2000;
repeat(1)@(posedge sys_clk);
s_axis_config_tvalid = 'd1;
#6000;
repeat(1)@(posedge sys_clk);
aresetn = 'd1;
end
always@(posedge sys_clk or negedge sys_rst_n)begin
if(sys_rst_n == 'D0)begin
fft_tdata <= 'd0;
fft_tvalid <= 'd0;
fft_tlast <= 'd0;
DDS_cnt <= 'd0;
end
else if(DDS_TVALID == 'd1)begin
if(DDS_cnt == 'd255)begin
DDS_cnt <= 'd256;
fft_tlast <= 'd1;
fft_tvalid <= 'd1;
fft_tdata <= DDS_TDATA;
end
else if(DDS_cnt < 'd255) begin
DDS_cnt <= DDS_cnt + 'd1;
fft_tlast <= 'd0;
fft_tvalid <= 'd1;
fft_tdata <= DDS_TDATA;
end
else begin
fft_tdata <= 'd0;
fft_tvalid <= 'd0;
fft_tlast <= 'd0;
end
end
end
dds_compiler_test dds_compiler_0_INST(
.aclk(sys_clk),
.aresetn(aresetn),
.m_axis_data_tvalid(DDS_TVALID),
.m_axis_data_tdata(DDS_TDATA)
);
fft_test fft_test_inst(
.aclk(sys_clk),
.aresetn(sys_rst_n),
.s_axis_config_tdata({7'd0,8'haa,1'd1}),scal:10,10,10,10;
.s_axis_config_tvalid(s_axis_config_tvalid),
.s_axis_config_tready(),
.s_axis_data_tdata({16'd0,fft_tdata}),
.s_axis_data_tvalid(fft_tvalid),
.s_axis_data_tready(),
.s_axis_data_tlast(fft_tlast),
.m_axis_data_tdata(m_axis_data_tdata),
.m_axis_data_tuser(),
.m_axis_data_tvalid(m_axis_data_tvalid),
.m_axis_data_tready(1'b1),
.m_axis_data_tlast(m_axis_data_tlast),
.m_axis_status_tdata(),
.m_axis_status_tvalid(),
.m_axis_status_tready(1'b1),
.event_frame_started(),
.event_tlast_unexpected(),
.event_tlast_missing(),
.event_fft_overflow(),
.event_status_channel_halt(),
.event_data_in_channel_halt(),
.event_data_out_channel_halt()
);
amp_data amp_data(
.sys_clk(sys_clk),
.sys_rst_n(sys_rst_n),
.s_axis_data_tvalid(m_axis_data_tvalid),
.s_axis_data_tlast(m_axis_data_tlast),
.s_axis_data_tdata(m_axis_data_tdata),
.m_axis_data_tvalid(),
.m_axis_data_tlast(),
.m_axis_data_tdata()
);
endmodule
amp_data的功能计算公式如下:
驱动代码
amp_data的驱动代码如下:
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/12/19 20:04:03
// Design Name:
// Module Name: amp_data
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module amp_data(
input sys_clk,
input sys_rst_n,
input s_axis_data_tvalid,
input s_axis_data_tlast,
input[31:0] s_axis_data_tdata,
output m_axis_data_tvalid,
output m_axis_data_tlast,
output [15:0] m_axis_data_tdata
);
wire[31:0] s_axis_fft_tdata_i;
wire[31:0] s_axis_fft_tdata_q;
reg s_axis_data_tvalid_r1;
reg s_axis_data_tvalid_r2;
reg s_axis_data_tvalid_r3;
reg s_axis_data_tvalid_r4;
reg s_axis_data_tlast_r1;
reg s_axis_data_tlast_r2;
reg s_axis_data_tlast_r3;
reg s_axis_data_tlast_r4;
reg[39:0] m_axis_fft_tdata_reg;
wire[31:0] m_axis_data_tdata_i;
reg m_axis_data_tvalid_i;
reg m_axis_data_tlast_i;
assign m_axis_data_tdata_i = m_axis_fft_tdata_reg[31:0];
always @(posedge sys_clk)begin
s_axis_data_tvalid_r1 <= s_axis_data_tvalid;
s_axis_data_tvalid_r2 <= s_axis_data_tvalid_r1;
s_axis_data_tvalid_r3 <= s_axis_data_tvalid_r2;
s_axis_data_tvalid_r4 <= s_axis_data_tvalid_r3;
m_axis_data_tvalid_i <= s_axis_data_tvalid_r4;
s_axis_data_tlast_r1 <= s_axis_data_tlast;
s_axis_data_tlast_r2 <= s_axis_data_tlast_r1;
s_axis_data_tlast_r3 <= s_axis_data_tlast_r2;
s_axis_data_tlast_r4 <= s_axis_data_tlast_r3;
m_axis_data_tlast_i <= s_axis_data_tlast_r4;
end
always @(posedge sys_clk or negedge sys_rst_n)begin
if(sys_rst_n == 'd0)begin
m_axis_fft_tdata_reg <= 'd0;
end
else begin
m_axis_fft_tdata_reg <= s_axis_fft_tdata_i + s_axis_fft_tdata_q;
end
end
amp_mult amp_mult_inst0(
.CLK(sys_clk),
.A(s_axis_data_tdata[15:0]),
.B(s_axis_data_tdata[15:0]),
.P(s_axis_fft_tdata_i)
);
amp_mult amp_mult_inst1(
.CLK(sys_clk),
.A(s_axis_data_tdata[31:16]),
.B(s_axis_data_tdata[31:16]),
.P(s_axis_fft_tdata_q)
);
cordic_squart_root cordic_squart_root_inst(
.aclk(sys_clk),
.aresetn(sys_rst_n),
.s_axis_cartesian_tvalid(m_axis_data_tvalid_i),
.s_axis_cartesian_tlast(m_axis_data_tlast_i),
.s_axis_cartesian_tdata(m_axis_data_tdata_i),
.m_axis_dout_tvalid(m_axis_data_tvalid),
.m_axis_dout_tlast(m_axis_data_tlast),
.m_axis_dout_tdata(m_axis_data_tdata)
);
endmodule
仿真分析
代码仿真结果如下:
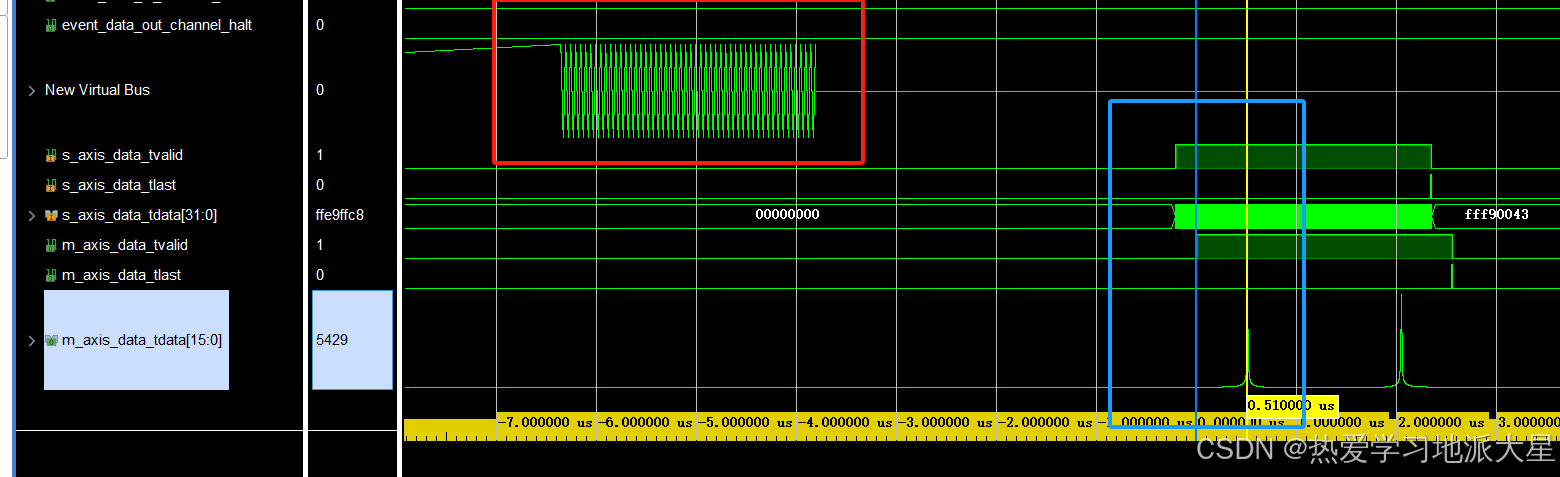
上图中红色的是20MHz正弦波输入,蓝色是经过运算后的FFT数据,数据最大值是51个时钟周期,本次设计工作时钟是100MHz,正弦波是20MHz,FFT的点数是256,那么理论FFT的点数计算公式如下:
计算结果FFT的点数为51,与上面仿真结果一致,验证无误。


















 9149
9149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









