







聚类分析案例 - 顾客数据聚类分析
-
已知:客户性别、年龄、年收入、消费指数
-
需求:对客户进行分析,找到业务突破口,寻找黄金客户
1 通过聚类分析进行用户分群
import pandas as pd
dataset = pd.read_csv('data/customers.csv')
dataset.head()
考虑最后两列作为分群依据
X = dataset.iloc[:, [3, 4]].values#全部行,第四第五列 Annual Income (k$) 和 Spending Score (1-100)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 5, init = 'k-means++', random_state = 42)#k=5
y_kmeans = kmeans.fit_predict(X)
#K-means与K-means++:
#原始K-means算法最开始随机选取数据集中K个点作为聚类中心,
#而K-means++按照如下的思想选取K个聚类中心:
#假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。
#在选取第一个聚类中心(n=1)时同样通过随机的方法。
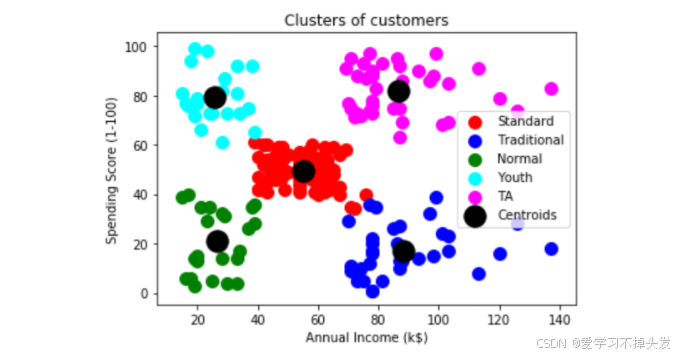
画图展示聚类结果
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Standard')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Traditional')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Normal')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 100, c = 'cyan', label = 'Youth')
plt.scatter(X[y_kmeans == 4, 0], X[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'TA')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'black', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
2 评估聚类个数
import matplotlib.pyplot as plt
wcss = []
for i in range(1, 11): #循环使用不同k测试结果
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_) #inertia簇内误差平方和
plt.plot(range(1, 11), wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
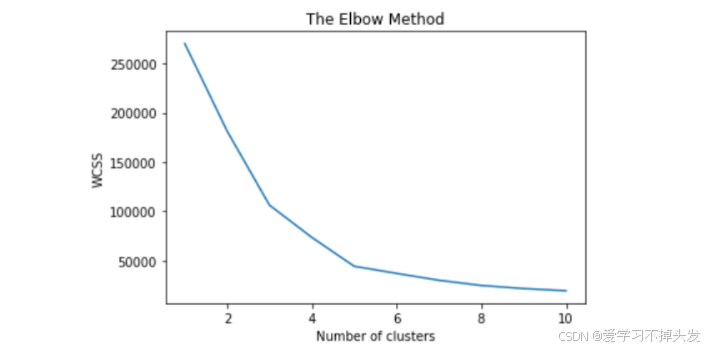
结论 5个分群比较好
3 聚类时要注意的问题
K均值(K-Means)是聚类中最常用的方法之一,它基于点与点距离的相似度来计算最佳类别归属。
K均值在应用之前一定要注意两种数据异常:
- 1)数据的异常值。数据中的异常值能明显改变不同点之间的距离相似度,并且这种影响是非常显著的。因此基于距离相似度的判别模式下,异常值的处理必不可少。
- 2)数据的异常量纲。不同的维度和变量之间,如果存在数值规模或量纲的差异,那么在做距离之前需要先将变量归一化或标准化。例如,跳出率的数值分布区间是[0,1],订单金额可能是[0,10000000],而订单数量则是[0,1000]。如果没有归一化或标准化操作,那么相似度将主要受到订单金额的影响。
数据量过大的时候不适合使用k-means
- K-Means在算法稳定性、效率和准确率(相对于真实标签的判别)上表现非常好,并且在应对大量数据时依然如此。它的算法时间复杂度上界为O(n * k * t),其中n是样本量、k是划分的聚类数、t是迭代次数。
- 当聚类数和迭代次数不变时,K均值的算法消耗时间只跟样本量有关,因此会呈线性增长趋势。
当真正面对海量数据时,使用K均值算法将面临严重的结果延迟,尤其是当K均值被用做实时性或准实时性的数据预处理、分析和建模时,这种瓶颈效应尤为明显。

















 3563
3563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









