






摘要

通过摘要可以获取到SRAM的设计、采用的电路、实验结果等关键信息,分别在摘要高亮部分。
背景
SRAM发展所遇到的问题:
- 在数字CIM中,MAC操作主要通过加法树或者外围(CIM-P)中通过顺序累加的内存乘法进行。但是采用加法树会导致大量的硬件开销,CIM-P设计会显著降低并行性。典型的SRAM数字设计中,一次只能访问一行,导致每个事件步长只能触发一个突出前神经元。
- 另一个挑战是如何确保在每个时间步长只有一个脉冲信号进入SRAM中,大多是采用的方法是在SRAM阵列中增加额外的组件,对稳定性和功耗产生不利的影响。
转置SRAM用于片上学习
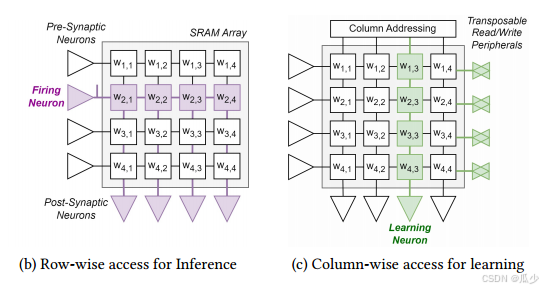
为了确保SNN对不同的环境具有良好的适应性,在片上进行SNN的学习是一种常见的实现方式,运行SNN在部署后进行训练。实现片上学习的前提是能够访问SRAM中的突触权重。在推理阶段,需要对存储器行进行读取,在训练阶段,要将权重存入到SRAM中,则需要对SRAM的列进行操作。图1中的b、c分别对应推理和训练阶段对SRAM阵列的操作。具有在行和列两个方向上访问能力的SRAM被称为可转置SRAM。
作者贡献:
- 设计多端口SRAM增强突触前神经元的并行性,用于存储权重,每个单元设计多个解耦读端口
- 设计一种新的多端口判优电路,将脉冲信号输入到指定端口中
- 设置可以转置 读/写 访问,方便在线学习
ESAM
传统CIM-P在执行MAC操作时逐个读取存储器,本文设计一个多端口电路来对阵列进行同时访问,并设计一个判优电路来实现编码以及一个一次能够处理多个访问的神经元。多端口的功能简化了在片上学习的转置操作。
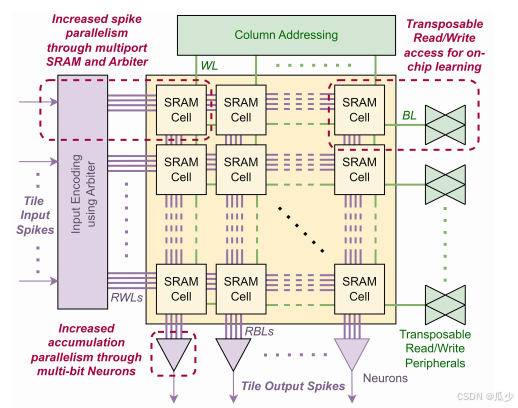
图2:本文提出Macro整体架构,绿色部分表示转置读写输出端,推理阶段读取数据在紫色部分实现
如图二所示,每个Tile包括Arbiter(判优电路)、SRAM单元和神经元阵列。多个Tile级联可以组成一个完整的神经网络,在每个Tile之间,脉冲信号以二进制的形式进行并行传输,从而消除了解码和路由的需求。 每个Tile具体流程如下:Arbiter电路在每个周期可以处理p个脉冲信号,从而激活相应的RWL字线,每个SRAM cell的输出结果在RBL位线上传递,最后到达神经元。在神经元中这些输出并行相加,是否产生膜电位的变化。绿色部分为转置字线和位线支持对SRAM阵列的读写操作,减少了更新一列权重所需要操作的次数,从而提高片上训练的效率。
转置多端口SRAM单元设计
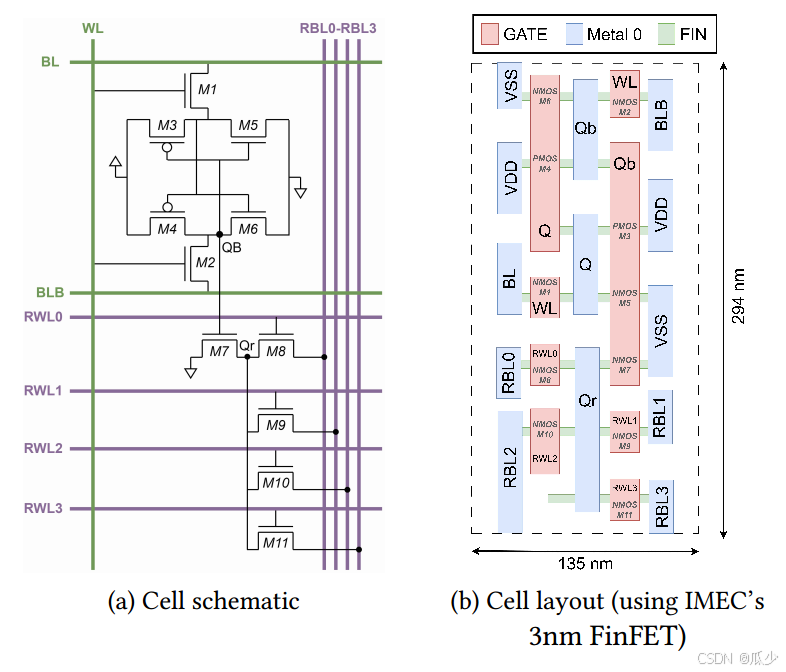
图3:five-Read and one-Write(1RW+4R)SRAM cell 设计和布局布线
图三展示了本文提出的一读写+四读的SRAM单元,与传统6T SRAM不同的是,WL是垂直的,BL是水平的,从而支持按列读/写访问。M7控制是否访问该SRAM单元中的信息,M8-M11控制Qr是否输出到对应的读位线(RBL)中 。在执行读操作,当相应的WL被驱动时,QB接入晶体管,M7导通,根据QB、RWLx的不同,RBLx上的电压要么保持为0,要么释放Vss。
M7与它的Gate连接到SRAM cell,形成一个解耦端口,最大限度的降低了增加端口对神经元胞体稳定性造成的影响,还能使接到RBLx上的电压缩放到比VDD更低的值,而对电池的稳定性可以忽略不记,这样做虽然会省电,但将会造成充电速度下降。同时作者还设计了1RW+1R, 1RW+2R和1RW+3R的SRAM单元。
采用传统的基于电压差分检测放大器,使用四倍的行复位匹配SRAM的行间距对转置端口BL/BLB进行检测。对于RBL0-3单端读取,采用级联的基于逆变的感测放大器来匹配SRAM列的间距,比传统传感器给出读出结果速度会稍慢。
Arbiter 电路设计
该电路设计主要是为了提高CIM整体结构的并行性。输入为脉冲向量R,图四(a)展示了电路整体结构,由4个级联的一个端口Arbiter组成。一个端口的Arbiter主要是实现优先级编码,优先级编码主要在图四(b)中体现出来,由一串相同的基于逻辑的子块组成,如图四(c)所示。优先级编码首先接受向量R最左边的“1”,创建一个 one-hot 向量G。信号s[n-1]组织选择右侧的请求。若R向量中没有任何脉冲,将noR设为“1” 。向量R'与R相同,只是所选的脉冲信号被屏蔽。这些为授予的脉冲信号R',以级联的方式传递给后续的A日Arbiter电路中,将系统扩展到多个端口,在单个时钟周期内生成多个G-vector。
原则上,优先级编码器可以单独用作仲裁器,如图4所示。然而,对于bb0 128行的完整SRAM阵列,这会导致优先级编码器内部的关键路径过长,如图4(b)中红色部分突出显示。为了减轻这种情况,在实践中,1端口仲裁器不是作为一个单一的优先级编码器实现的,而是通过在树结构中组合多个较短的优先级编码器。多个较短的基本优先级编码器处理实际的请求向量𝑅,而更高级别的优先级编码器依次在这些基本优先级编码器之间进行仲裁。注意,基本和高级优先级编码器仍然使用图4(b)所示的相同结构。以8.0%的面积开销为代价,这将128宽的4端口仲裁器的关键路径从>1100𝑝𝑠减少到<800𝑝𝑠。
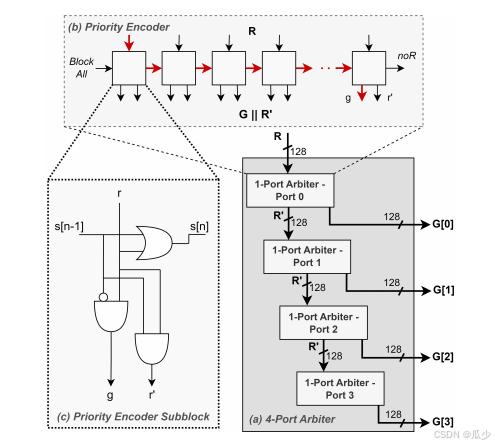
图四:基于4个级联1端口仲裁器的基于逻辑的4端口仲裁器
神经元设计
本文测试设计到时间静态分类任务,选择了集成-激活(IF)神经元。神经元从SRAM整列的p多端口接受数据 ("1","0")。对于每个RBL,使用一个有效标签来指示在每个时钟周期中实际使用到的端口,避免未使用的端口被错误的读取为“1”并添加到膜电位中。有效的BL线上的脉冲被解码为{+1/-1}并相加,然后存储到m-bit Vmem 寄存器当中。当一个Tile中所有的输入脉冲都通过Arbiter电路时,R empty设置为“1”,开始比较阈值电压Vth和膜电位Vmem。若Vmem>=Vth,则神经元的输出寄存器 r 设置为“1”。同时Vmem复位为“0”,再次累计脉冲。如果神经元输出脉冲 r 被批准,g 设置为“1”,将 r 重置为“0”。
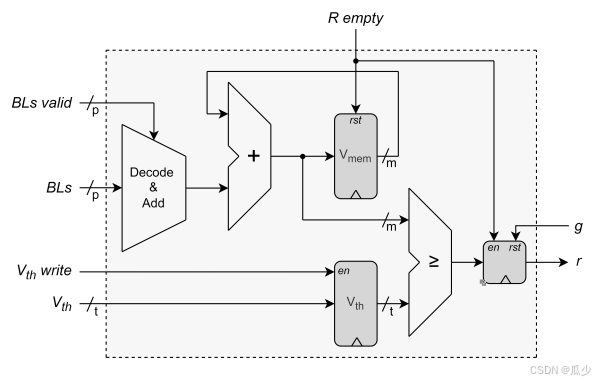
图5:本文所提出的神经元设计
实验结果
参数设置
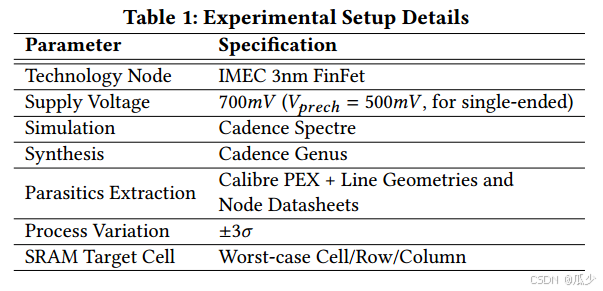
为了改进SRAM写操作,使用了负BL (NBL)辅助技术,它在互补位线上产生一个较低的电压(Vwd<V𝑆𝑆),以迫使单元达到所需的状态。并且所有的SRAM阵列大小行列设置都<=128。

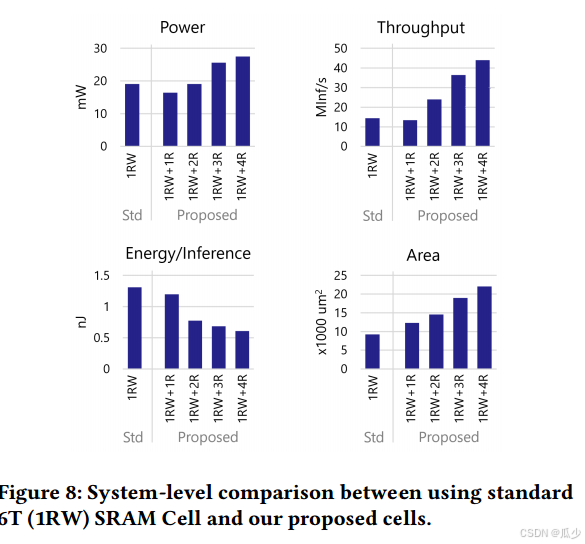
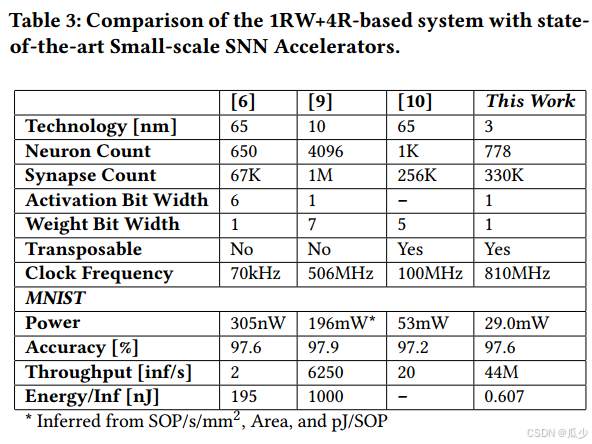


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









